 如何定義網絡架構或結構加速視覺系統的優化
如何定義網絡架構或結構加速視覺系統的優化
當人們討論深度神經網絡(DNN)、深度學習和嵌入式視覺時,通常會先討論如何定義網絡架構或結構。不久之前,我們還只能支持線性網絡,在輸入和輸出級之間的層數非常有限。相比之下,今天的網絡技術,如谷歌的TensorFlow,支持多個輸入、多個輸出以及每級多個層。
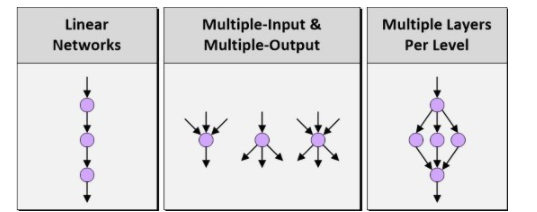
圖1:線性網絡、多輸入&多輸出以及每級多個層
TensorFlow的強大令人難以置信,但人工定義TensorFlow架構類似于用匯編語言編寫一個復雜的軟件。因此Bonsai等公司開始研究提升抽象等級,幫助更多的開發人員在他們的工作中融合更加豐富的智能模型。一旦定義好網絡結構,下一步就是訓練這種結構,并用32位浮點系數(“加權”)產生一個新的版本。假設我們在創建某類嵌入式視覺圖像處理應用,這個過程——可能會用到數十萬甚至數百萬幅分類照片——可以在高層進行描述,如圖2所示。
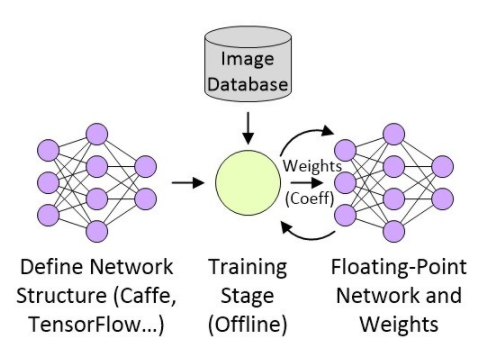
圖2:創建嵌入式視覺圖像處理應用
網絡經過訓練之后,下一步就是準備部署網絡了,這與目標平臺有關。假設這是一個性能受限的、具有功耗意識的部署平臺,那么浮點網絡需要被轉換為定點網絡,如圖3所示(雖然16位定點實現很常見,但低至8位定點的實現也有大量成功的案例)。
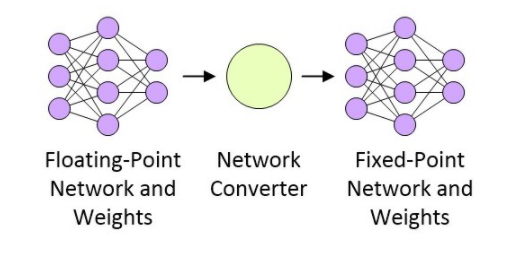
圖3:浮點網絡轉換為定點網絡
CEVA正在做一些非常有意思的研發工作,包括一種網絡產生器。這種網絡產生器采用基于Caffe或TenserFlow(任何形式)的網絡浮點表示法,并將其轉換為小型快速高能效的定點網絡,目標應用是CEVA-XM4智能視覺處理器。
投入實際使用之前的最后一步是將網絡部署進目標系統,目標系統可以是MCU、FPGA或基于SoC的系統,且可作為目標檢測和識別系統的一部分。
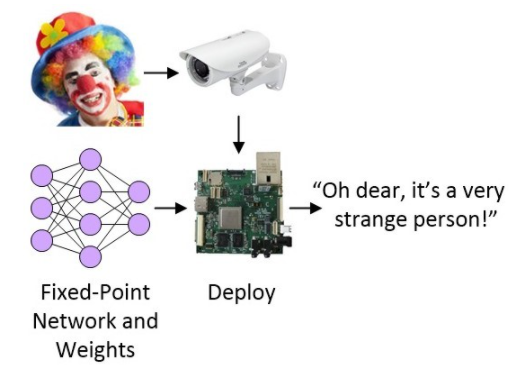
圖4:將網絡部署進目標系統
目前為止情況一切都很好,但是……
還有巨大的改進空間
與大多數事情一樣,如果只是隨便說說,那么上面的描述聽起來也不錯。然而,在一線搭建實際系統的開發人員知道,還有許多事情要考慮。
就拿第一步訓練網絡所用到的圖像來說,用什么設備來捕獲這些圖像?在物理范疇,我們可能會討論鏡頭、圖像傳感器和模擬前端(AFE)等東西。在此之上,我們必須考慮圖像處理管線(可以用軟件函數實現,或使用硬件加速器)中采用的所有算法,比如增益控制、白平衡、噪聲抑制和銳化、顏色空間轉換、插值、壓縮……等等。
當然,所有這一切也適合用于捕獲和處理圖像的任何后端攝像系統,這些圖像最后饋入人工神經網絡,實現檢測、識別、分類和其它用途。
越來越多的公司將攝像機和智能視覺技術集成進產品中,系統的圖像質量和精度是體現其價值的核心。除了鏡頭和傳感器等物理組件,一個典型的圖像處理管線可能會達到10級,每級可能有大約25個調整參數。在光學、傳感器、處理器和算法組合之間優化這些系統需要付出很大的努力,而且每個產品和衍生品都要完成這一辛苦的工作,因此可能會限制待評估的替代配置的數量。
為了解決這一問題,Algolux公司以其機器學習解算器為基礎設計了一種最優化的平臺架構,名為CRISP-ML(運算型可重配置圖像信號平臺)。這種架構可以根據標準圖像測試卡、加有標簽的訓練圖像和關鍵性能指示器(KPI)目標調整成像和計算機視覺算法,在規定的成像條件下取得理想的圖像質量、視覺精度、功耗和性能目標。這種方案可以極大地減少優化一個新視覺系統所需的時間和成本,將專家資源留給價值更高的任務。
當我第一次聽到這一切時,第一反應就是Algolux的員工正在使用基因算法玩“魔術”。不過,Algolux公司首席技術官Paul Green表示,他們其實并沒有使用基因算法,而是使用“有指導性的隨機搜索與基于微積分的搜索的一種組合”。哇,這才真正激起了我的興趣——“真是個壞小子!”。我期望在不遠的將來能夠學習到更多的內容,并寫出更多的報道來。
編輯:hfy
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100766 -
圖像傳感器
+關注
關注
68文章
1902瀏覽量
129551 -
嵌入式視覺
+關注
關注
8文章
117瀏覽量
59147 -
視覺處理器
+關注
關注
0文章
54瀏覽量
17114 -
深度學習
+關注
關注
73文章
5503瀏覽量
121162
發布評論請先 登錄
相關推薦
安森美機器視覺系統解決方案
機器視覺系統如何選擇圖像傳感器
CCD機器視覺系統的工作原理和特性
機器視覺系統與運動控制系統的區別
機器視覺系統的工作原理和應用領域

機器視覺系統五個模塊介紹

機器視覺系統的組成部分

海伯森攜其最新技術成果亮相武漢VisionCon視覺系統設計技術會議

視覺系統所使用的相機種類介紹

機器視覺系統和人工智能有什么區別
機器視覺系統中常用攝像機的分類

視覺傳感器的定義、結構和原理、作用及應用






 工商網監
工商網監
評論