 新一代AI/ML加速器新型內存解決方案——HBM2E內存接口
新一代AI/ML加速器新型內存解決方案——HBM2E內存接口
近年來,隨著內存帶寬逐漸成為影響人工智能持續增長的關鍵焦點領域之一,以高帶寬內存(HBM、HBM2、HBM2E)和GDDR開始逐漸顯露頭角,成為搭配新一代AI/ML加速器和專用芯片的新型內存解決方案。
人工智能/機器學習(AI/ML)在全球范圍內的迅速興起,正推動著制造業、交通、醫療、教育和金融等各個領域的驚人發展。從2012年到2019年,人工智能訓練能力增長了30萬倍,平均每3.43個月翻一番,就是最有力的證明。支持這一發展速度需要的遠不止摩爾定律,人工智能計算機硬件和軟件的各個方面都需要不斷的快速改進。
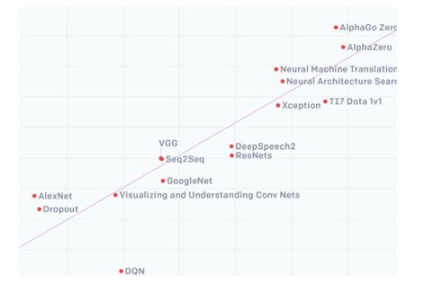
2012-2019年,人工智能訓練能力增長30萬倍(圖片來源:openai.com)
而中國作為全球人工智能發展最快的國家之一,正備受矚目。根據德勤最新發布的統計預測數據顯示,2020年全球人工智能市場規模將達到6800億元人民幣,復合增長率(CAGR)達26%。而中國人工智能市場的表現尤為突出,2019年末已經達到了510億元人民幣的市場規模,人工智能企業超過2600家。預計到2020年,中國AI市場規模將達到710億元人民幣,五年間(2015-2020)的復合增長率高達44.5%。
近年來,中國正在積極推動人工智能與實體經濟的融合,從而實現產業的優化升級。2017年7月,國務院印發了《新一代人工智能發展規劃》,這一規劃與2015年5月發布的《中國制造2025》共同構成了中國人工智能戰略的核心。這份具有里程碑意義的規劃,對人工智能發展進行了戰略性部署,力爭到2030年把中國建設成為世界主要人工智能創新中心。此外,2020年還是中國的新基建元年,而人工智能作為一大重點板塊,勢必成為新基建的核心支撐。
內存帶寬將是影響AI發展的關鍵因素
“內存帶寬將成為人工智能持續增長的關鍵焦點領域之一。”Rambus IP核產品營銷高級總監 Frank Ferro日前在接受《電子工程專輯》采訪時表示,以先進的駕駛員輔助系統(ADAS)為例,L3級及更高級別系統的復雜數據處理需要超過200GB/s的內存帶寬。這些高帶寬是復雜AI/ML算法的基本需求,自駕過程中需要這些算法快速執行大量計算并安全地執行實時決策。而在L5級,如果車輛要能夠獨立地對交通標志和信號的動態環境做出反應,以便準確地預測汽車、卡車、自行車和行人的移動,將需要超過500GB/s的內存帶寬。

不同ADAS級別對存儲帶寬的要求(圖片來源:anandtech.com)
鑒于此,高帶寬內存(HBM、HBM2、HBM2E)和GDDR開始逐漸顯露頭角,成為搭配新一代AI/ML加速器和專用芯片的新型內存解決方案。他說過去幾年內,HBM、HMC、PAM4等標準在市場上展開了激烈的競爭,但從目前的發展態勢來看,還是HBM占據了更多的市場份額。不過他同時也坦承,由于汽車安全等級要求很高,考慮到HBM本身采用的是復雜的2.5D架構,再結合DRAM設備,所以目前為止在汽車市場上并沒有得到突破性的應用,相比之下,GDDR反而會是比較好的解決方案。
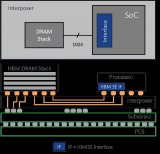
高帶寬內存(HBM)于2013年推出,是一種高性能3D堆棧SDRAM構架。與前一代產品一樣,HBM2為每個堆棧包含最多8個內存芯片,同時將管腳傳輸速率翻倍,達到2Gbps。HBM2實現每個封裝256GB/s的內存帶寬(DRAM堆棧),采用HBM2規格,每個封裝支持高達8GB的容量。
2018年末,JEDEC宣布推出HBM2E規范,以支持增加的帶寬和容量。當傳輸速率上升到每管腳3.6Gbps時,HBM2E可以實現每堆棧461GB/s的內存帶寬。此外,HBM2E支持12個DRAM的堆棧,內存容量高達每堆棧24GB。

單一DRAM堆棧的HBM2E內存系統(圖片來源:Rambus)
HBM2E提供了達成巨大內存帶寬的能力。連接到一個處理器的四塊HBM2E內存堆棧將提供超過1.8TB/s的帶寬。通過3D堆疊內存,可以以極小的空間實現高帶寬和高容量需求。進一步,通過保持相對較低的數據傳輸速率,并使內存靠近處理器,總體系統功率得以維持在較低水位。
坦率的說,采用HBM的設計的代價是增加復雜性和成本,因此Frank Ferro并不建議在人工智能推理應用中使用HBM技術。然而,對于人工智能訓練應用,HBM2E的優點使其成為一個更好的選擇。它的性能非常出色,所增加的采用和制造成本可以透過節省的電路板空間和電力相互的緩解。在物理空間日益受限的數據中心環境中,HBM2E緊湊的體系結構提供了切實的好處。它的低功率意味著它的熱負荷較低,在這種環境中,冷卻成本通常是幾個最大的運營成本之一。官方數據顯示,Rambus IP系統以及IP產品在實驗室經過了非常嚴苛的環境測試,確保從零下50到125攝氏度范圍內均能夠正常運行。
同時,Frank Ferro也不認為在芯片上采取分布式內存的方法會給HBM2E和GDDR長期的發展帶來影響。原因在于盡管SRAM的速度和延遲性都高于DRAM,但在固定的芯片面積上能安裝的SRAM數量卻非常少,很多情況下為了滿足人工智能訓練的需求,一部分SRAM設備不得不裝在芯片之外,這就是問題所在。但總體來說,這兩種方案屬于從不同角度出發解決同一個問題,兩者之間是互補而非相互阻礙。
創紀錄的性能
針對高帶寬和低延遲進行了優化,Rambus HBM2E內存接口解決方案實現了創紀錄的4Gbps性能。該解決方案由完全集成且經過驗證的PHY和內存控制器IP組成,搭配SK Hynix 3.6Gbps運行速度的HBM2E DRAM,在物理層面實現了完整的集成互聯,可以從單個HBM2E設備提供460GB/s的帶寬,這也被Frank Ferro視作其HBM2E 產品的核心差異化優勢之一。這意味著,除了提供完整的內存子系統、硬核PHY和時序收斂外,用戶額外需要的系統級支持、工具套件和技術服務也都包含在內,集成難度和設計時間得以大幅度下降。
Rambus HBM2E 4Gbps發送端眼圖(圖片來源:Rambus)
從2017年正式投產HBM解決方案以來,Rambus目前已經擁有第三代PHY和第二代內存控制器IP,全球范圍內的成功案例項目超過50個。除了4Gbps HBM2E外,Rambus在其他不同工藝節點的產品還包括采用Global Foundries 12nm/14nm工藝的HBM2,速度為2.0 Gbps/s;采用Global Foundries 12LP+和三星14nm/11nm工藝的HBM2E產品。
不可否認,4.0Gbps是一個全新的行業標桿。在這一過程中,Rambus與SK hynix和Alchip展開了合作,采用臺積電N7工藝和CoWoS?先進封裝技術,實現了HBM2E 2.5D系統在硅中驗證Rambus HBM2E PHY和內存控制器IP。Alchip與Rambus的工程團隊共同設計,負責中介層和封裝基板的設計。
“在我們提供的完整參考設計框架中,最重要的一點就是如何更好地對中介層進行完整的設計和表征化處理,以確保信號完整性。此外,我們還協助用戶對每個信號通道進行仿真分析,通過Lab Station工具對內存子系統進行最優化設計,并提供在SI高速信號完整性和電源完整性方面的經驗等等。”Frank Ferro說Rambus的初衷,不僅僅只是扮演IP供應商的角色,更是希望在系統層面降低用戶設計難度。
信號完整性之所以如此重要,是因為HBM作為高速內存接口,在與中介層互聯的過程中包括至少上千條不同的數據鏈路,必須要確保所有鏈路的物理空間得到良好的控制,整個信號的完整性也必須得到驗證。因此,Rambus的做法如果從表征化層面來講,不但需要對整個中介層的材料做出非常精細的選擇,還要考慮漸進層的厚度以及整個電磁反射相關的物理參數,并在此基礎上進行完整的分析和仿真,以實現信號一致性的處理。
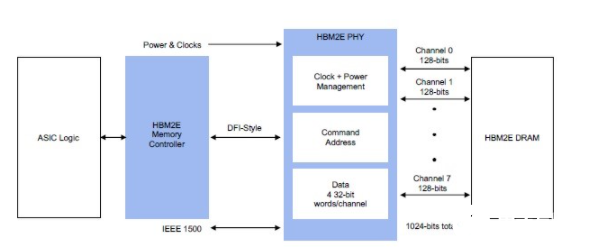
HBM2E內存接口子系統示例
燧原科技是Frank Ferro在發布會上提及的中國合作伙伴。在此次合作中,燧原科技為自己下一代人工智能訓練芯片選擇了Rambus HBM2 PHY和內存控制器IP,可實現2Tb/s的性能。而在今年4月和5月,長鑫存儲、兆易創新兩家公司還分別和Rambus簽署了DRAM(動態隨機存取存儲)與RRAM(電阻式隨機存取存儲器,也可寫作ReRAM)技術專利授權。
Rambus大中華區總經理 Raymond Su表示,通過對IP控制器公司Northwest Logic和Verimatrix安全IP業務部門的收購,Rambus實現了在內存IP層面提供一站式采購和“turn key”服務的目標。接下來,在中國市場,公司將緊密地與云廠商、OEM和ODM合作,推動整個內存產業生態系統的建設。
編輯:hfy
-
DRAM
+關注
關注
40文章
2315瀏覽量
183521 -
信號完整性
+關注
關注
68文章
1408瀏覽量
95494 -
AI
+關注
關注
87文章
30919瀏覽量
269170 -
人工智能
+關注
關注
1791文章
47294瀏覽量
238578 -
adas
+關注
關注
309文章
2184瀏覽量
208662
發布評論請先 登錄
相關推薦
英偉達加速認證三星AI內存芯片
三星電子HBM3E內存獲英偉達認證,加速AI GPU市場布局
HBM上車?HBM2E被用于自動駕駛汽車
SK海力士攜手Waymo提供第三代高帶寬存儲器(HBM2E)技術
下一代高功能新一代AI加速器(DRP-AI3):10x在高級AI系統高級AI中更快的嵌入處理

集成32GB HBM2e內存,AMD Alveo V80加速卡助力傳感器處理、存儲壓縮等

美光HBM3E解決方案,高帶寬內存助力AI未來發展
SK海力士加速HBM4E內存研發,預計2026年面市
什么是HBM3E內存?Rambus HBM3E/3內存控制器內核
美光科技開始量產HBM3E高帶寬內存解決方案
美光量產行業領先的HBM3E解決方案,加速人工智能發展

美光開始量產行業領先的 HBM3E 解決方案,加速人工智能發展






 工商網監
工商網監
評論