 基于HMM的音頻故障診斷平臺實現軸承建模與診斷實驗
基于HMM的音頻故障診斷平臺實現軸承建模與診斷實驗
作者:陸汝華,樊曉平,楊勝躍,周芳芳
軸承是機械設備中應用最為廣泛的一種通用部件,也是最容易損壞的零件之一,它工作正常與否直接影響整臺機器的性能,因而軸承故障診斷成為重要的研究課題和目前的研究熱點。在軸承故障診斷研究中,通常是對其工作時產生的振動信號或音頻信號進行分析,以判斷軸承運行狀態。振動信號法通過安裝在軸承座或箱體適當地方的加速度傳感器獲取軸承振動信號,并對其信號進行分析與處理,進而判斷軸承是否運行正常。此方法的不足在于需要將加速度傳感器固定在待檢測的設備上,增加了成本,使用也不方便。音頻信號的采集屬于非接觸式,只需要利用麥克風作為聲音傳感器,不但使用方便而且成本低廉,具有振動信號不可代替的優勢。參考文獻研究表明,當軸承運行狀態發生變化,音頻信號特性也會隨之變化時,因而對音頻信號分析是一種有效、可行的軸承故障診斷方法。目前,基于音頻信號的軸承故障診斷方法主要有:小波分析、神經網絡和盲源分離方法等。 隱馬爾可夫模型HMM(Hidden Markov Model)是一種描述隨機過程統計特性的概率模型,能夠對多個觀察樣本進行有效融合而構成一個模型,具有較好的抗噪能力,在交通監測、圖像識別、語音識別以及基于振動信號的故障診斷等領域中都得到了較好的應用,也是目前為止最有效的語音識別方法。而Mel頻率倒譜系數MFCC(Mel Frequency CepstrumCoefficients)考慮了人耳聽覺特性,能很好地反映音頻信號特征,在語音識別、音頻分類和檢索研究領域應用十分廣泛。本文通過對音頻信號的MFCC特征提取,分別采用DHMM(Discrete HMM)和CGHMM(Continuous Gaussian MixtureHMM)兩種方法進行建模與診斷研究。DHMM方法對觀測序列進行了量化處理,運算速度快,卻降低了診斷精度。而CGHMM方法不需要量化,避免了量化帶來的數據處理誤差,提高了診斷精度,但減慢了運算速度。從總體上來看,兩種方法都具有運算速度快、診斷精度高的優點,具有很好的應用前景。
1 理論基礎
1.1 MFCC
Mel頻率倒譜系數MFCC用于信號特征提取,其計算過程如下:
(1) 確定每一幀信號的長度N及幀移,并對每一幀信號序列進行預處理(加窗、預加重等)。本文采用應用較廣的漢明窗:
ω(n)=(1-α)-αcos(2πn/N) (1)
式中,0《α《1,通常取值為0.46。
(2) 將預處理后的信號進行快速傅立葉變換(FFT),將時域信號轉換為頻域信號,再計算其模的平方得到能量譜P[k],0≤k≤N-1。
(3) 選取濾波器個數為M,并定義最低頻率接近零,最高頻率為輸入音頻信號頻率的一半,再根據mel(f)頻率與實際線性頻率f的關系mel( f )=2 595lg(1+f/700)計算出三角帶通濾波器組Hm[k],則能量譜P[k]通過三角帶通濾波器組Hm(k)后的輸出為:
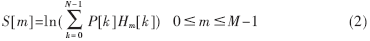
(4) 對S[m]進行離散余弦變換(DCT)即得到MFCC系數:
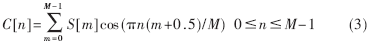
(5) 取C[1],C[2],…,C[V]作為MFCC參數,此處V是MFCC參數的維數,通常為12~16。
1.2 HMM
隱馬爾可夫模型HMM是在Markov鏈的基礎上發展起來的一種概率模型,由三個基本參數來描述。第一個參數為狀態轉移概率A={aij|1≤i,j≤N},aij=P(qt+1=Sj/qt=Si)表示從狀態Si變化到狀態Sj的轉移概率,顯然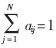 且aij≥0,其中,qt表示Markov鏈t時刻所處的狀態,N為HMM狀態數。第二個參數為觀察值概率分布B={bj(k)|1≤j≤N, 1≤k≤M},bj(k)=P(Ok/qt=Sj)表示進入狀態Sj時輸出為Ok的概率,Ok表示觀察值,M為可能的觀察值數目。根據觀察值序列的分布特點,HMM模型可分為離散DHMM和連續DHMM兩大類。同時,如果觀察值序列服從連續高斯混合密度函數分布,則為連續高斯混合密度CGHMM。最后一個參數是初始概率分布π={πi|1≤i≤N},πi=P(q1=si)表示Markov鏈從狀態Si開始的概率,顯然
且aij≥0,其中,qt表示Markov鏈t時刻所處的狀態,N為HMM狀態數。第二個參數為觀察值概率分布B={bj(k)|1≤j≤N, 1≤k≤M},bj(k)=P(Ok/qt=Sj)表示進入狀態Sj時輸出為Ok的概率,Ok表示觀察值,M為可能的觀察值數目。根據觀察值序列的分布特點,HMM模型可分為離散DHMM和連續DHMM兩大類。同時,如果觀察值序列服從連續高斯混合密度函數分布,則為連續高斯混合密度CGHMM。最后一個參數是初始概率分布π={πi|1≤i≤N},πi=P(q1=si)表示Markov鏈從狀態Si開始的概率,顯然
有了如上定義,HMM可描述為:
λ=(π,A,B) (4)
2 基于HMM的故障診斷
基于HMM的軸承故障音頻信號診斷系統框圖如圖1所示,主要包括數據采集、特征提取、HMM訓練和HMM診斷等部分。

2.1數據采集
數據采集是使用麥克風作為聲音傳感器,將軸承的音頻信號變為一定的電平信號輸入計算機,即錄制波形音頻的過程。在數據采集之前,需要按照一定規則設定好音頻信號幾個重要的采集參數:采樣頻率、位數和聲道數。本文在采樣頻率為22.05kHz、A/D轉換精度為16位、聲道數為單聲道的條件下,采用VC++中提供的函數庫,實現對軸承音頻信號的數據采集。簡單流程為:打開錄音設備、準備WAVE數據頭、準備數據塊、開始錄音、停止錄音以及關閉錄音等,詳細過程請參見參考文獻[10]。
2.2 特征提取
特征提取是指從軸承音頻信號中提取有用的統計數據,如Mel頻率倒譜特征參數(MFCC)、線性預測倒譜系數(LPCC)、感覺加權線性預測系統(PLP)等,是故障建模與識別的關鍵,直接影響到故障診斷效果。此外,特征提取還可以用差分系數近似描述音頻信號的幀間相關性,反映信號的動態特征。動態特征和靜態特征互相補充,提高了系統的診斷性能。因為MFCC參數充分利用人耳的聽覺特性,能很好地體現音頻信號的主要信息,在語音識別、音頻分類和檢索領域應用十分廣泛[8]。所以本文選用12維MFCC參數和12維一階差分MFCC進行診斷實驗。
2.3 HMM訓練
HMM訓練是指從同類故障的大量音頻信號樣本中提取統計信息,利用恰當的訓練算法對模型參數反復修正直至收斂,最后得到模型的狀態轉移概率A、觀察值概率分布B、初始概率分布π等參數。典型的訓練算法有Baum-Welch算法,但此算法是在假定只有一個觀察值訓練序列的條件下得到的。為了增加HMM故障診斷系統的穩健性和提高故障診斷的準確率,需要選取多個樣本進行訓練,以建立軸承各類故障狀態的HMM參數模型。記L個觀察值序列(即L個樣本)為O(1)、O(2)、…、O(L),每個觀察值序列的長度記為T,則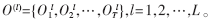 此時,基于多觀察值序列訓練的重估公式可寫為:
此時,基于多觀察值序列訓練的重估公式可寫為:
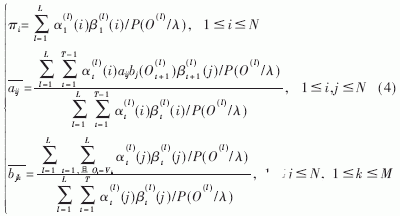
2.4 HMM診斷
訓練完成之后將模型參數存儲,此時,系統就具備了診斷的能力。診斷過程中,輸入待檢測軸承音頻信號,經過預處理、MFCC特征提取后,得到觀察值序列O={O1,O2,…,OT}。然后,對此觀察值序列進行故障檢測,當檢測到有故障發生時,再進一步進行故障診斷,判斷出音頻信號的故障類型。
(1) 故障檢測
故障檢測只需要訓練一個代表軸承正常狀態的HMM模型,記為λ0。根據前向-后向算法[8]計算出待檢信號O={O1,O2,…,OT}在正常模型λ0下的輸出概率P(O/λ0)。如果此概率P(O/λ0)大于預先確定的某一閾值,則表明軸承工作正常;否則,軸承有可能出現某種故障,需要進一步進行故障診斷。
(2) 故障診斷
同樣使用前向-后向算法,快速有效地計算出觀察值序列O={O1,O2,…,OT}在各HMM模型下的輸出概率,通常情況下,概率最大的模型即為診斷結果。為了提高系統的診斷精度,可在后處理階段輔以必要的拒識算法,比如設定適當的概率閾值,如果最大概率小于這個閾值,則診斷為其他運行狀態。
3 軸承故障診斷實驗
在VisualC++7.0環境下,自主開發了基于HMM的音頻故障診斷平臺,本文所有實驗均在此平臺上完成;診斷對象為6202CM深溝球滾動軸承,其轉速為1800r/m;采樣頻率為22.05kHz;A/D轉換精度16位;數據幀長512,幀移128。通過特征提取,將每幀信號都轉換成12維MFCC和12維一階差分MFCC,形成長度為32的觀察值序列,分別采用DHMM和CGHMM兩種方法進行了建模與診斷實驗。
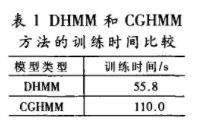
在模型訓練環節,對于正常聲音、內圈異音、外圈異音、滾動體異音以及保持架音等五種軸承狀態,各采集30組音頻數據樣本進行訓練,分別得到DHMM和CGHMM兩類模型訓練過程,兩種故障模型的平均訓練時間如表1所示。由表可以看出,由于DHMM對觀測序列進行了量化處理,計算量小,訓練速度快;而CGHMM的復雜度比較高,收斂過程長,比DHMM方法的訓練時間多出近一倍(但也在實時要求之內)。
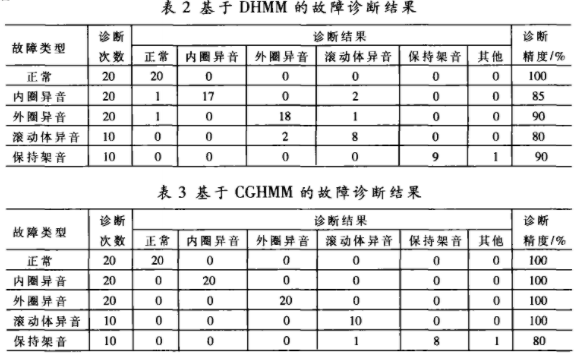
在診斷環節,另外采集了20組正常聲音、內圈異音、外圈異音以及10組滾動體異音和保持架音等五組數據分別進行了測試,得到的基于DHMM和CGHMM的故障診斷結果分別如表2和表3所示。在DHMM方法中,共80次診斷出現8次誤診,總的診斷精度接近90%,效果較良。而CGHMM方法只出現2次誤診,診斷精度達到了97.5%,明顯高于DHMM方法,更具有良好的應用前景。
本文在VC++平臺下,自主開發了一套基于HMM的軸承故障音頻診斷平臺。通過對音頻信號的MFCC特征提取,分別采用DHMM和CGHMM兩種方法進行建模與診斷研究。由于DHMM方法對觀測序列進行了量化處理,運算速度快,但降低了診斷精度。而CGHMM方法不需要量化,避免了量化帶來的數據處理誤差,提高了診斷精度,但減慢了運算速度。從總體上來看,兩種方法都具有運算速度快、診斷精度高的優點,具有很好的應用前景。
責任編輯:gt
-
傳感器
+關注
關注
2552文章
51288瀏覽量
755155 -
音頻
+關注
關注
29文章
2891瀏覽量
81710 -
頻率
+關注
關注
4文章
1517瀏覽量
59295
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論