") 機(jī)器學(xué)習(xí)算法中的知識分類
機(jī)器學(xué)習(xí)算法中的知識分類
Datawhale干貨譯者:張峰,Datawhale成員
本文將介紹機(jī)器學(xué)習(xí)算法中非常重要的知識—分類(classification),即找一個函數(shù)判斷輸入數(shù)據(jù)所屬的類別,可以是二類別問題(是/不是),也可以是多類別問題(在多個類別中判斷輸入數(shù)據(jù)具體屬于哪一個類別)。與回歸問題(regression)相比,分類問題的輸出不再是連續(xù)值,而是離散值,用來指定其屬于哪個類別。分類問題在現(xiàn)實中應(yīng)用非常廣泛,比如垃圾郵件識別,手寫數(shù)字識別,人臉識別,語音識別等。
一、指定閾值
邏輯回歸返回的是概率。你可以“原樣”使用返回的概率(例如,用戶點擊此廣告的概率為 0.00023),也可以將返回的概率轉(zhuǎn)換成二元值(例如,這封電子郵件是垃圾郵件)。
如果某個邏輯回歸模型對某封電子郵件進(jìn)行預(yù)測時返回的概率為 0.9995,則表示該模型預(yù)測這封郵件非常可能是垃圾郵件。相反,在同一個邏輯回歸模型中預(yù)測分?jǐn)?shù)為 0.0003 的另一封電子郵件很可能不是垃圾郵件。可如果某封電子郵件的預(yù)測分?jǐn)?shù)為 0.6 呢?為了將邏輯回歸值映射到二元類別,你必須指定分類閾值(也稱為判定閾值)。如果值高于該閾值,則表示“垃圾郵件”;如果值低于該閾值,則表示“非垃圾郵件”。人們往往會認(rèn)為分類閾值應(yīng)始終為 0.5,但閾值取決于具體問題,因此你必須對其進(jìn)行調(diào)整。
我們將在后面的部分中詳細(xì)介紹可用于對分類模型的預(yù)測進(jìn)行評估的指標(biāo),以及更改分類閾值對這些預(yù)測的影響。
注意:
“調(diào)整”邏輯回歸的閾值不同于調(diào)整學(xué)習(xí)速率等超參數(shù)。在選擇閾值時,需要評估你將因犯錯而承擔(dān)多大的后果。例如,將非垃圾郵件誤標(biāo)記為垃圾郵件會非常糟糕。不過,雖然將垃圾郵件誤標(biāo)記為非垃圾郵件會令人不快,但應(yīng)該不會讓你丟掉工作。
二、陽性與陰性以及正類別與負(fù)類別
在本部分,我們將定義用于評估分類模型指標(biāo)的主要組成部分先。不妨,我們從一則寓言故事開始:
“
伊索寓言:狼來了(精簡版)有一位牧童要照看鎮(zhèn)上的羊群,但是他開始厭煩這份工作。為了找點樂子,他大喊道:“狼來了!”其實根本一頭狼也沒有出現(xiàn)。村民們迅速跑來保護(hù)羊群,但他們發(fā)現(xiàn)這個牧童是在開玩笑后非常生氣。(這樣的情形重復(fù)出現(xiàn)了很多次。)
一天晚上,牧童看到真的有一頭狼靠近羊群,他大聲喊道:“狼來了!”村民們不想再被他捉弄,都待在家里不出來。這頭饑餓的狼對羊群大開殺戒,美美飽餐了一頓。這下子,整個鎮(zhèn)子都揭不開鍋了。恐慌也隨之而來。
”
我們做出以下定義:
“狼來了”是正類別。
“沒有狼”是負(fù)類別。
我們可以使用一個 2x2的混淆矩陣來總結(jié)我們的“狼預(yù)測”模型,該矩陣描述了所有可能出現(xiàn)的結(jié)果(共四種):

真正例是指模型將正類別樣本正確地預(yù)測為正類別。同樣,真負(fù)例是指模型將負(fù)類別樣本正確地預(yù)測為負(fù)類別。
假正例是指模型將負(fù)類別樣本錯誤地預(yù)測為正類別,而假負(fù)例是指模型將正類別樣本錯誤地預(yù)測為負(fù)類別。
在后面的部分中,我們將介紹如何使用從這四種結(jié)果中衍生出的指標(biāo)來評估分類模型。
三、準(zhǔn)確率
準(zhǔn)確率是一個用于評估分類模型的指標(biāo)。通俗來說,準(zhǔn)確率是指我們的模型預(yù)測正確的結(jié)果所占的比例。正式點說,準(zhǔn)確率的定義如下:
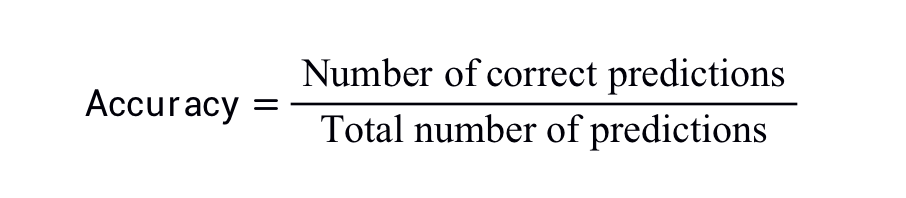
對于二元分類,也可以根據(jù)正類別和負(fù)類別按如下方式計算準(zhǔn)確率:
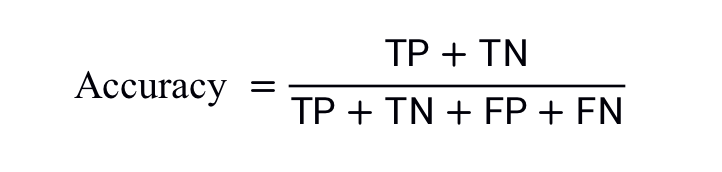
其中,TP = 真正例,TN = 真負(fù)例,F(xiàn)P = 假正例,F(xiàn)N = 假負(fù)例。讓我們來試著計算一下以下模型的準(zhǔn)確率,該模型將 100 個腫瘤分為惡性 (正類別)或良性(負(fù)類別):
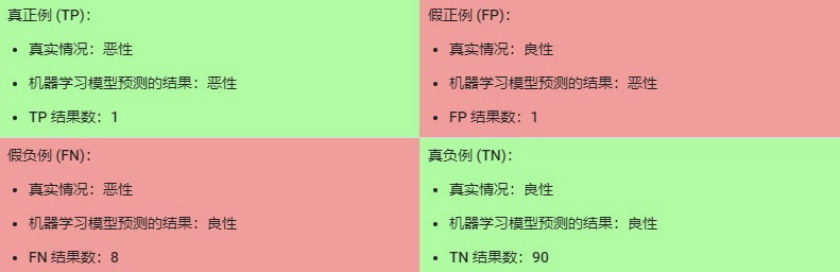
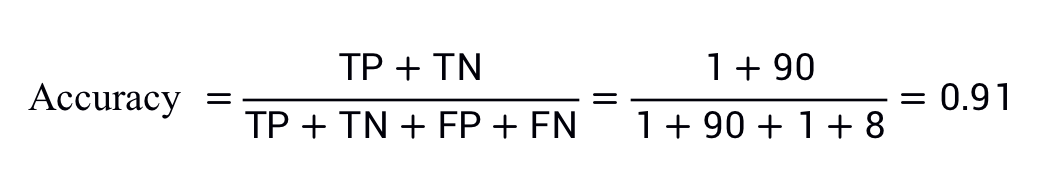
準(zhǔn)確率為 0.91,即 91%(總共 100 個樣本中有 91 個預(yù)測正確)。這表示我們的腫瘤分類器在識別惡性腫瘤方面表現(xiàn)得非常出色,對吧?
實際上,只要我們仔細(xì)分析一下正類別和負(fù)類別,就可以更好地了解我們模型的效果。
在 100 個腫瘤樣本中,91 個為良性(90 個 TN 和 1 個 FP),9 個為惡性(1 個 TP 和 8 個 FN)。
在 91 個良性腫瘤中,該模型將 90 個正確識別為良性。這很好。不過,在 9 個惡性腫瘤中,該模型僅將 1 個正確識別為惡性。這是多么可怕的結(jié)果!9 個惡性腫瘤中有 8 個未被診斷出來!
雖然 91% 的準(zhǔn)確率可能乍一看還不錯,但如果另一個腫瘤分類器模型總是預(yù)測良性,那么這個模型使用我們的樣本進(jìn)行預(yù)測也會實現(xiàn)相同的準(zhǔn)確率(100 個中有 91 個預(yù)測正確)。換言之,我們的模型與那些沒有預(yù)測能力來區(qū)分惡性腫瘤和良性腫瘤的模型差不多。
當(dāng)你使用分類不平衡的數(shù)據(jù)集(比如正類別標(biāo)簽和負(fù)類別標(biāo)簽的數(shù)量之間存在明顯差異)時,單單準(zhǔn)確率一項并不能反映全面情況。
在下一部分中,我們將介紹兩個能夠更好地評估分類不平衡問題的指標(biāo):精確率和召回率。
學(xué)習(xí)理解
在以下哪種情況下,高的準(zhǔn)確率值表示機(jī)器學(xué)習(xí)模型表現(xiàn)出色?
一只造價昂貴的機(jī)器雞每天要穿過一條交通繁忙的道路一千次。某個機(jī)器學(xué)習(xí)模型評估交通模式,預(yù)測這只雞何時可以安全穿過街道,準(zhǔn)確率為 99.99%。
一種致命但可治愈的疾病影響著 0.01% 的人群。某個機(jī)器學(xué)習(xí)模型使用其癥狀作為特征,預(yù)測這種疾病的準(zhǔn)確率為 99.99%。
在 roulette 游戲中,一只球會落在旋轉(zhuǎn)輪上,并且最終落入 38 個槽的其中一個內(nèi)。某個機(jī)器學(xué)習(xí)模型可以使用視覺特征(球的旋轉(zhuǎn)方式、球落下時旋轉(zhuǎn)輪所在的位置、球在旋轉(zhuǎn)輪上方的高度)預(yù)測球會落入哪個槽中,準(zhǔn)確率為 4%。
四、精確率和召回率
4.1 精確率
精確率指標(biāo)嘗試回答以下問題:在被識別為正類別的樣本中,確實為正類別的比例是多少?
精確率的定義如下:

注意:如果模型的預(yù)測結(jié)果中沒有假正例,則模型的精確率為 1.0。
讓我們來計算一下上一部分中用于分析腫瘤的機(jī)器學(xué)習(xí)模型的精確率:


該模型的精確率為 0.5,也就是說,該模型在預(yù)測惡性腫瘤方面的正確率是 50%。
4.2 召回率
召回率嘗試回答以下問題:在所有正類別樣本中,被正確識別為正類別的比例是多少?
從數(shù)學(xué)上講,召回率的定義如下:
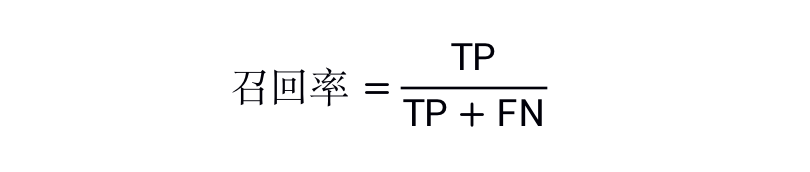
注意:如果模型的預(yù)測結(jié)果中沒有假負(fù)例,則模型的召回率為 1.0。
讓我們來計算一下腫瘤分類器的召回率:


該模型的召回率是 0.11,也就是說,該模型能夠正確識別出所有惡性腫瘤的百分比是 11%。
4.3 精確率和召回率:一場拔河比賽
要全面評估模型的有效性,必須同時檢查精確率和召回率。遺憾的是,精確率和召回率往往是此消彼長的情況。也就是說,提高精確率通常會降低召回率值,反之亦然。請觀察下圖來了解這一概念,該圖顯示了電子郵件分類模型做出的 30 項預(yù)測。分類閾值右側(cè)的被歸類為“垃圾郵件”,左側(cè)的則被歸類為“非垃圾郵件”。
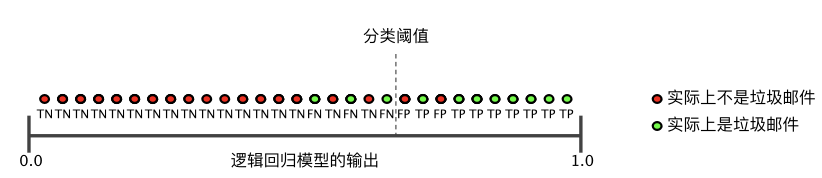
圖 1. 將電子郵件歸類為垃圾郵件或非垃圾郵件
我們根據(jù)圖 1 所示的結(jié)果來計算精確率和召回率值:

精確率指的是被標(biāo)記為垃圾郵件的電子郵件中正確分類的電子郵件所占的百分比,即圖 1 中閾值線右側(cè)的綠點所占的百分比:

召回率指的是實際垃圾郵件中正確分類的電子郵件所占的百分比,即圖 1 中閾值線右側(cè)的綠點所占的百分比:

圖 2 顯示了提高分類閾值產(chǎn)生的效果。
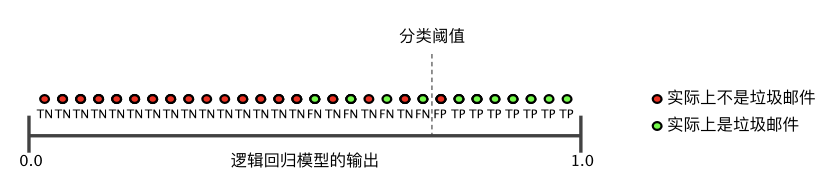
圖2. 提高分類閾值
假正例數(shù)量會減少,但假負(fù)例數(shù)量會相應(yīng)地增加。結(jié)果,精確率有所提高,而召回率則有所降低:

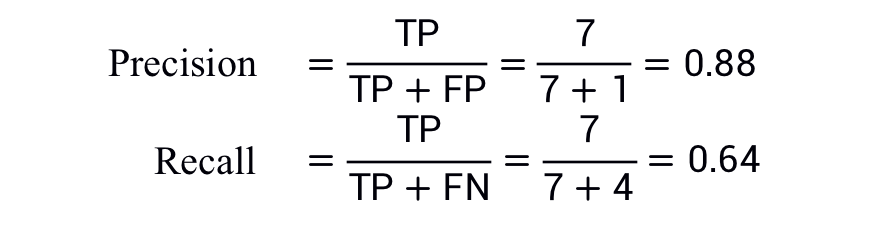
相反,圖 3 顯示了降低分類閾值(從圖 1 中的初始位置開始)產(chǎn)生的效果。
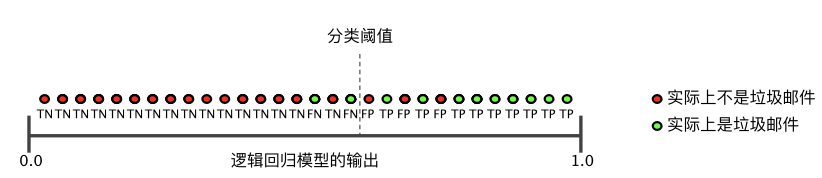
圖 3.降低分類閾值
假正例數(shù)量會增加,而假負(fù)例數(shù)量會減少。結(jié)果這一次,精確率有所降低,而召回率則有所提高:

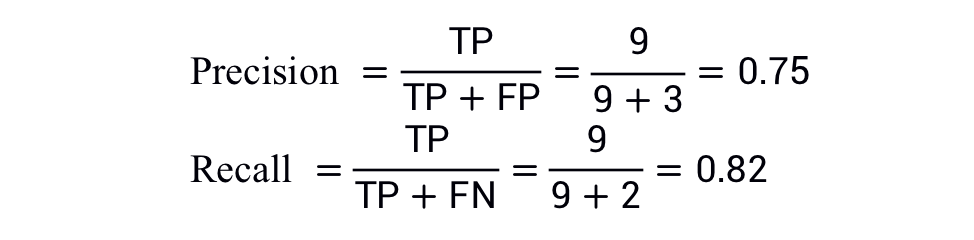
我們已根據(jù)精確率和召回率指標(biāo)制定了各種指標(biāo)。有關(guān)示例,請參閱 F1 值。
學(xué)習(xí)理解
讓我們以一種將電子郵件分為“垃圾郵件”或“非垃圾郵件”這兩種類別的分類模型為例。如果提高分類閾值,精確率會怎樣?
可能會提高。
一定會提高。
一定會降低。
可能會降低。
讓我們以一種將電子郵件分為“垃圾郵件”或“非垃圾郵件”這兩種類別的分類模型為例。如果提高分類閾值,召回率會怎樣?
始終下降或保持不變。
始終保持不變。
一定會提高。
以兩個模型(A 和 B)為例,這兩個模型分別對同一數(shù)據(jù)集進(jìn)行評估。以下哪一項陳述屬實?
如果模型 A 的精確率優(yōu)于模型 B,則模型 A 更好。
如果模型 A 的精確率和召回率均優(yōu)于模型 B,則模型 A 可能更好。
如果模型 A 的召回率優(yōu)于模型 B,則模型 A 更好。
五、ROC 和 AUC
5.1 ROC 曲線
ROC 曲線(接收者操作特征曲線)是一種顯示分類模型在所有分類閾值下的效果圖表。該曲線繪制了以下兩個參數(shù):
真正例率
假正例率
真正例率(TPR) 是召回率的同義詞,因此定義如下:

假正例率(FPR) 的定義如下:
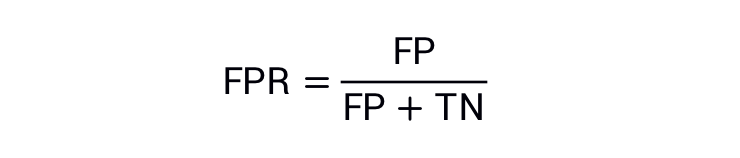
ROC 曲線用于繪制采用不同分類閾值時的 TPR 與 FPR。降低分類閾值會導(dǎo)致將更多樣本歸為正類別,從而增加假正例和真正例的個數(shù)。下圖顯示了一個典型的 ROC 曲線。
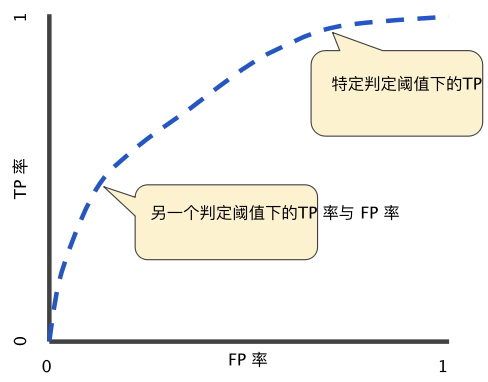
圖 4. 不同分類閾值下的 TP 率與 FP 率
為了計算 ROC 曲線上的點,我們可以使用不同的分類閾值多次評估邏輯回歸模型,但這樣做效率非常低。幸運(yùn)的是,有一種基于排序的高效算法可以為我們提供此類信息,這種算法稱為曲線下面積。
5.2 曲線下面積:ROC 曲線下面積
曲線下面積表示“ROC 曲線下面積”。也就是說,曲線下面積測量的是從 (0,0) 到 (1,1) 之間整個 ROC 曲線以下的整個二維面積(參考積分學(xué))。
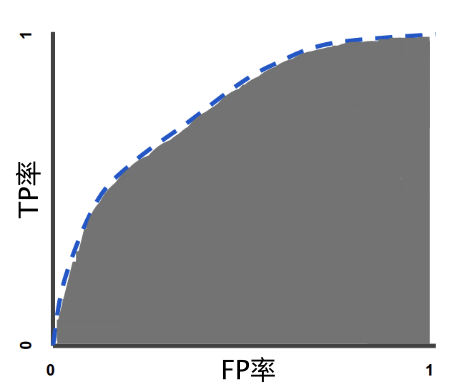
圖 5. 曲線下面積(ROC 曲線下面積)
曲線下面積對所有可能的分類閾值的效果進(jìn)行綜合衡量。曲線下面積的一種解讀方式是看作模型將某個隨機(jī)正類別樣本排列在某個隨機(jī)負(fù)類別樣本之上的概率。以下面的樣本為例,邏輯回歸預(yù)測從左到右以升序排列:

圖 6. 預(yù)測按邏輯回歸分?jǐn)?shù)以升序排列
曲線下面積表示隨機(jī)正類別(綠色)樣本位于隨機(jī)負(fù)類別(紅色)樣本右側(cè)的概率。
曲線下面積的取值范圍為 0-1。預(yù)測結(jié)果 100% 錯誤的模型的曲線下面積為 0.0;而預(yù)測結(jié)果 100% 正確的模型的曲線下面積為 1.0。
曲線下面積因以下兩個原因而比較實用:
曲線下面積的尺度不變。它測量預(yù)測的排名情況,而不是測量其絕對值。
曲線下面積的分類閾值不變。它測量模型預(yù)測的質(zhì)量,而不考慮所選的分類閾值。
不過,這兩個原因都有各自的局限性,這可能會導(dǎo)致曲線下面積在某些用例中不太實用:
并非總是希望尺度不變。例如,有時我們非常需要被良好校準(zhǔn)的概率輸出,而曲線下面積無法告訴我們這一結(jié)果。
并非總是希望分類閾值不變。在假負(fù)例與假正例的代價存在較大差異的情況下,盡量減少一種類型的分類錯誤可能至關(guān)重要。例如,在進(jìn)行垃圾郵件檢測時,你可能希望優(yōu)先考慮盡量減少假正例(即使這會導(dǎo)致假負(fù)例大幅增加)。對于此類優(yōu)化,曲線下面積并非一個實用的指標(biāo)。
學(xué)習(xí)理解
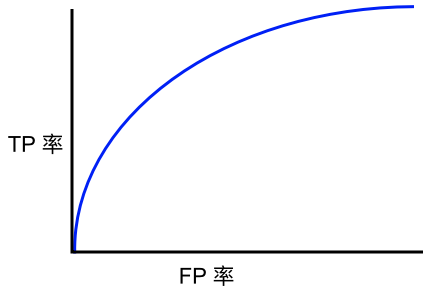
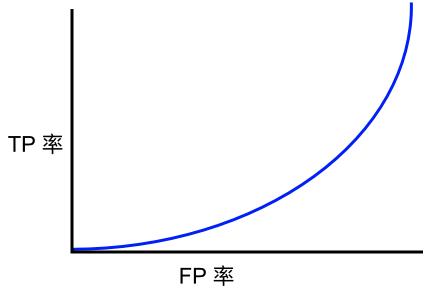
以下哪條 ROC 曲線可產(chǎn)生大于 0.5 的 AUC 值?



將給定模型的所有預(yù)測結(jié)果都乘以 2.0(例如,如果模型預(yù)測的結(jié)果為 0.4,我們將其乘以 2.0 得到 0.8),會使按 AUC 衡量的模型效果產(chǎn)生何種變化?
這會使 AUC 變得更好,因為預(yù)測值之間相差都很大。
沒有變化。AUC 只關(guān)注相對預(yù)測分?jǐn)?shù)。
這會使 AUC 變得很糟糕,因為預(yù)測值現(xiàn)在相差太大。
六、預(yù)測偏差
邏輯回歸預(yù)測應(yīng)當(dāng)無偏差。即:

預(yù)測偏差指的是這兩個平均值之間的差值。即:
預(yù)測偏差=預(yù)測平均值?數(shù)據(jù)集中相應(yīng)標(biāo)簽的平均值
注意:“預(yù)測偏差”與偏差(“wx + b”中的“b”)不是一回事。
如果出現(xiàn)非常高的非零預(yù)測偏差,則說明模型某處存在錯誤,因為這表明模型對正類別標(biāo)簽的出現(xiàn)頻率預(yù)測有誤。
例如,假設(shè)我們知道,所有電子郵件中平均有 1% 的郵件是垃圾郵件。如果我們對某一封給定電子郵件一無所知,則預(yù)測它是垃圾郵件的可能性為 1%。同樣,一個出色的垃圾郵件模型應(yīng)該預(yù)測到電子郵件平均有 1% 的可能性是垃圾郵件。(換言之,如果我們計算單個電子郵件是垃圾郵件的預(yù)測可能性的平均值,則結(jié)果應(yīng)該是 1%。)然而,如果該模型預(yù)測電子郵件是垃圾郵件的平均可能性為 20%,那么我們可以得出結(jié)論,該模型出現(xiàn)了預(yù)測偏差。
造成預(yù)測偏差的可能原因包括:
特征集不完整
數(shù)據(jù)集混亂
模型實現(xiàn)流水線中有錯誤
訓(xùn)練樣本有偏差
正則化過強(qiáng)
你可能會通過對學(xué)習(xí)模型進(jìn)行后期處理來糾正預(yù)測偏差,即通過添加校準(zhǔn)層來調(diào)整模型的輸出,從而減小預(yù)測偏差。例如,如果你的模型存在 3% 以上的偏差,則可以添加一個校準(zhǔn)層,將平均預(yù)測偏差降低 3%。但是,添加校準(zhǔn)層并非良策,具體原因如下:
你修復(fù)的是癥狀,而不是原因。
你建立了一個更脆弱的系統(tǒng),并且必須持續(xù)更新。
使用校準(zhǔn)層來修復(fù)模型的所有錯誤。
如果可能的話,請避免添加校準(zhǔn)層。使用校準(zhǔn)層的項目往往會對其產(chǎn)生依賴
最終,維護(hù)校準(zhǔn)層可能會令人苦不堪言。
注意:出色模型的偏差通常接近于零。即便如此,預(yù)測偏差低并不能證明你的模型比較出色。特別糟糕的模型的預(yù)測偏差也有可能為零。例如,只能預(yù)測所有樣本平均值的模型是糟糕的模型,盡管其預(yù)測偏差為零。
七、分桶偏差和預(yù)測偏差
邏輯回歸可預(yù)測 0 到 1 之間的值。不過,所有帶標(biāo)簽樣本都正好是 0(例如,0 表示“非垃圾郵件”)或 1(例如,1 表示“垃圾郵件”)。因此,在檢查預(yù)測偏差時,你無法僅根據(jù)一個樣本準(zhǔn)確地確定預(yù)測偏差;你必須在“一大桶”樣本中檢查預(yù)測偏差。也就是說,只有將足夠的樣本組合在一起以便能夠比較預(yù)測值(例如 0.392)與觀察值(例如 0.394),邏輯回歸的預(yù)測偏差才有意義。
你可以通過以下方式構(gòu)建桶:
以線性方式分解目標(biāo)預(yù)測。
構(gòu)建分位數(shù)。
請查看以下某個特定模型的校準(zhǔn)曲線。每個點表示包含 1000 個值的分桶。兩個軸具有以下含義:
x 軸表示模型針對該桶預(yù)測的平均值。
y 軸表示該桶的數(shù)據(jù)集中的實際平均值。
兩個軸均采用對數(shù)尺度。
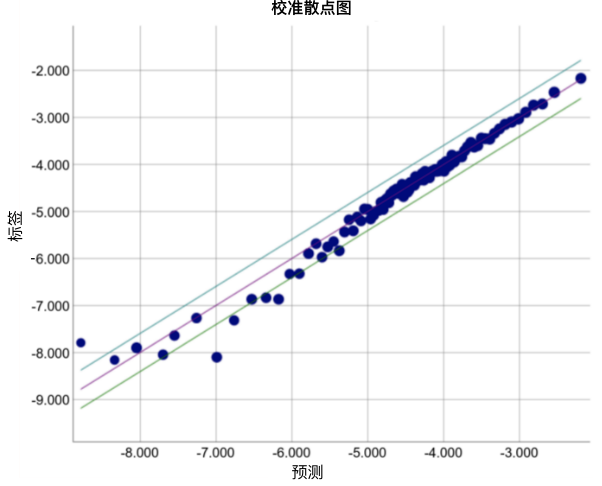
圖 7. 預(yù)測偏差曲線
為什么只有模型的某些部分所做的預(yù)測如此糟糕?以下是幾種可能性:
訓(xùn)練集不能充分表示數(shù)據(jù)空間的某些子集。
數(shù)據(jù)集的某些子集比其他子集更混亂。
該模型過于正則化。(不妨減小 lamdba的值。)
原文標(biāo)題:機(jī)器學(xué)習(xí)算法中分類知識總結(jié)!
文章出處:【微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
函數(shù)
+關(guān)注
關(guān)注
3文章
4331瀏覽量
62622 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8418瀏覽量
132646
原文標(biāo)題:機(jī)器學(xué)習(xí)算法中分類知識總結(jié)!
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
《具身智能機(jī)器人系統(tǒng)》第1-6章閱讀心得之具身智能機(jī)器人系統(tǒng)背景知識與基礎(chǔ)模塊
NPU與機(jī)器學(xué)習(xí)算法的關(guān)系
【每天學(xué)點AI】KNN算法:簡單有效的機(jī)器學(xué)習(xí)分類器
【「時間序列與機(jī)器學(xué)習(xí)」閱讀體驗】+ 鳥瞰這本書
【「時間序列與機(jī)器學(xué)習(xí)」閱讀體驗】+ 簡單建議
FPGA在人工智能中的應(yīng)用有哪些?
利用Matlab函數(shù)實現(xiàn)深度學(xué)習(xí)算法
機(jī)器學(xué)習(xí)中的數(shù)據(jù)分割方法
深度學(xué)習(xí)中的時間序列分類方法
機(jī)器學(xué)習(xí)算法原理詳解
機(jī)器學(xué)習(xí)在數(shù)據(jù)分析中的應(yīng)用
機(jī)器學(xué)習(xí)的經(jīng)典算法與應(yīng)用

名單公布!【書籍評測活動NO.35】如何用「時間序列與機(jī)器學(xué)習(xí)」解鎖未來?
基于神經(jīng)網(wǎng)絡(luò)的呼吸音分類算法
深度學(xué)習(xí)與度量學(xué)習(xí)融合的綜述





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論