") 傳統(tǒng)檢測(cè)、深度神經(jīng)網(wǎng)絡(luò)框架、檢測(cè)技術(shù)的物體檢測(cè)算法全概述
傳統(tǒng)檢測(cè)、深度神經(jīng)網(wǎng)絡(luò)框架、檢測(cè)技術(shù)的物體檢測(cè)算法全概述
物體檢測(cè)一向是比較熱門的研究方向,它經(jīng)歷了傳統(tǒng)的人工設(shè)計(jì)特征+淺層分類器的框架,到基于大數(shù)據(jù)和深度神經(jīng)網(wǎng)絡(luò)的End-To-End的物體檢測(cè)框架的發(fā)展,然而許多人其實(shí)并未系統(tǒng)的了解過(guò)物體檢測(cè)算法的整個(gè)發(fā)展內(nèi)容。正因如此,本次閱面科技邀請(qǐng)了資深研究員童志軍從傳統(tǒng)檢測(cè)算法核心、深度神經(jīng)網(wǎng)絡(luò)框架、檢測(cè)技術(shù)難點(diǎn)等方面來(lái)進(jìn)行干貨分享。
童志軍:閱面科技資深研究員,2012年畢業(yè)于東南大學(xué)獲碩士學(xué)位,先后加入虹軟、阿里巴巴從事圖像算法和機(jī)器學(xué)習(xí)工作,曾參與淘寶“拍立淘圖像搜索”、“3D試衣”等產(chǎn)品研發(fā),目前主要專注于深度學(xué)習(xí)的視覺(jué)檢測(cè)分類和移動(dòng)端深度學(xué)習(xí)模型壓縮技術(shù)。
在傳統(tǒng)視覺(jué)領(lǐng)域,物體檢測(cè)是一個(gè)非常熱門的研究方向。受70年代落后的技術(shù)條件和有限應(yīng)用場(chǎng)景的影響,物體檢測(cè)直到上個(gè)世紀(jì)90年代才開(kāi)始逐漸走入正軌。物體檢測(cè)對(duì)于人眼來(lái)說(shuō)并不困難,通過(guò)對(duì)圖片中不同顏色、紋理、邊緣模塊的感知很容易定位出目標(biāo)物體,但對(duì)于計(jì)算機(jī)來(lái)說(shuō),面對(duì)的是RGB像素矩陣,很難從圖像中直接得到狗和貓這樣的抽象概念并定位其位置,再加上物體姿態(tài)、光照和復(fù)雜背景混雜在一起,使得物體檢測(cè)更加困難。
檢測(cè)算法里面通常包含三個(gè)部分,第一個(gè)是檢測(cè)窗口的選擇, 第二個(gè)是特征的設(shè)計(jì),第三個(gè)是分類器的設(shè)計(jì)。隨著2001年Viola Jones提出基于Adaboost的人臉檢測(cè)方法以來(lái),物體檢測(cè)算法經(jīng)歷了傳統(tǒng)的人工設(shè)計(jì)特征+淺層分類器的框架,到基于大數(shù)據(jù)和深度神經(jīng)網(wǎng)絡(luò)的End-To-End的物體檢測(cè)框架,物體檢測(cè)一步步變得愈加成熟。
傳統(tǒng)檢測(cè)算法
在2001年,一篇基于Haar+Adaboost的檢測(cè)方法在學(xué)術(shù)界和工業(yè)界引起了非常大的轟動(dòng),它第一次把檢測(cè)做到實(shí)時(shí),并且在當(dāng)時(shí)的技術(shù)限制下,檢測(cè)性能也做的非常亮眼。縱觀2012年之前的物體檢測(cè)算法,可以歸結(jié)為三個(gè)方面的持續(xù)優(yōu)化:
檢測(cè)窗口的選擇
拿人臉檢測(cè)舉例,當(dāng)給出一張圖片時(shí),我們需要框出人臉的位置以及人臉的大小,那么最簡(jiǎn)單的方法就是暴力搜索候選框,把圖像中所有可能出現(xiàn)框的位置從左往右、從上往下遍歷一次。并且通過(guò)縮放一組圖片尺寸,得到圖像金字塔來(lái)進(jìn)行多尺度搜索。
但是這種方法往往計(jì)算量很大并且效率不高,在實(shí)際應(yīng)用中并不可取。人臉具有很強(qiáng)的先驗(yàn)知識(shí),比如人臉膚色YCbCr空間呈現(xiàn)很緊湊的高斯分布,通過(guò)膚色檢測(cè)可以去除很大一部分候選區(qū)域,僅留下極小部分的區(qū)域作為人臉檢測(cè)搜索范圍。由于膚色的提取非常快,只是利用一些顏色分布的信息,把每個(gè)像素判斷一下,整體速度提升很多。但膚色提取只是用到簡(jiǎn)單的顏色先驗(yàn),如果遇到和膚色很像的,比如黃色的桌子,很有可能被誤判成人臉的候選檢測(cè)區(qū)域。
進(jìn)一步提高精度衍生出如Selective Search或EdgeBox等proposal提取的方法,基于顏色聚類、邊緣聚類的方法來(lái)快速把不是所需物體的區(qū)域給去除,相對(duì)于膚色提取精度更高,極大地減少了后續(xù)特征提取和分類計(jì)算的時(shí)間消耗。
特征的設(shè)計(jì)
在傳統(tǒng)的檢測(cè)中,Haar由于提取速度快,能夠表達(dá)物體多種邊緣變化信息,并且可以利用積分圖快速計(jì)算,得到廣泛的應(yīng)用;LBP更多的表達(dá)物體的紋理信息,對(duì)均勻變化的光照有很好的地適應(yīng)性;HOG通過(guò)對(duì)物體邊緣使用直方圖統(tǒng)計(jì)來(lái)進(jìn)行編碼,特征表達(dá)能力更強(qiáng),在物體檢測(cè)、跟蹤、識(shí)別都有廣泛的應(yīng)用。傳統(tǒng)特征設(shè)計(jì)往往需要研究人員經(jīng)驗(yàn)驅(qū)動(dòng),更新周期往往較長(zhǎng),通過(guò)對(duì)不同的特征進(jìn)行組合調(diào)優(yōu),從不同維度描述物體可以進(jìn)一步提升檢測(cè)精度,如ACF檢測(cè),組合了20種不同的特征表達(dá)。
分類器的設(shè)計(jì)
傳統(tǒng)的分類器包含Adaboost、SVM、Decision Tree等。
Adaboost
一個(gè)弱分類器往往判斷精度不高,通過(guò)Adaboost自適應(yīng)地挑選分類精度高的弱分類器并將它們加權(quán)起來(lái),從而提升檢測(cè)性能。比如說(shuō),人臉檢測(cè)中一個(gè)候選窗口需要判斷是否為人臉,其中一些弱分類器為顏色直方圖分量(如紅黃藍(lán)三種顏色),如果黃色分量大于100,那我就認(rèn)為這塊可能是人臉的候選區(qū)域,這就是個(gè)非常簡(jiǎn)單的弱分類器。可是,單個(gè)這么弱的分類器判斷是很不準(zhǔn)的,那么我們就需要引入另外一些分量做輔助。比如再引入紅色分量大于150,將幾個(gè)條件疊加起來(lái),就組成了一個(gè)比較強(qiáng)的分類器。
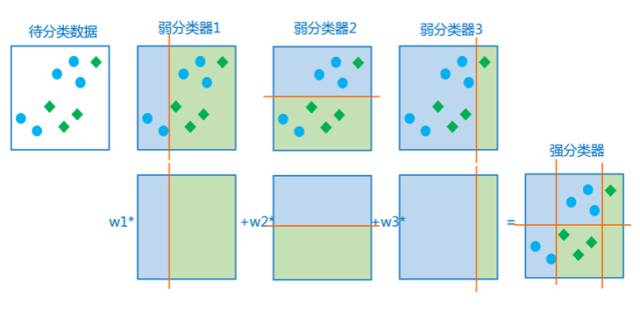
這里弱分類器的設(shè)計(jì)往往就是確定顏色判斷的閾值,為什么會(huì)選擇100呢?其實(shí)這是我們需要學(xué)習(xí)得到的閾值,學(xué)習(xí)得到,當(dāng)閾值設(shè)定為100時(shí),分類的精度是最高的。另外,為什么要選擇紅黃藍(lán)三種顏色?同樣,因?yàn)樗鼈兎诸惖木雀摺Mㄟ^(guò)不斷進(jìn)行特征挑選并學(xué)習(xí)弱分類器,最終組合提升為Adaboost強(qiáng)分類器。
SVM分類器
SVM通過(guò)最大化分類間隔得到分類平面的支持向量,在線性可分的小數(shù)據(jù)集上有不錯(cuò)的分類精度,另外通過(guò)引入核函數(shù)將低維映射到高維,從而線性可分,在檢測(cè)場(chǎng)景被廣泛使用。
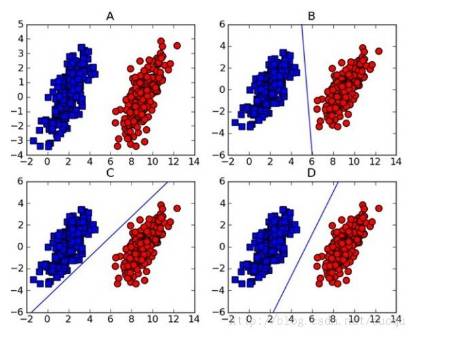
比如線性SVM分類器就是一些支持向量,將物體表示為一些特征向量,實(shí)際當(dāng)中學(xué)到的分類器就是一些系數(shù)向量,這些系數(shù)向量和特征向量做一個(gè)加權(quán)的話可以得到分類分?jǐn)?shù),對(duì)分?jǐn)?shù)進(jìn)行閾值判斷,就可以判斷是否是某一類。
Decision Tree
決策樹(shù)是一種樹(shù)形結(jié)構(gòu),其中每個(gè)內(nèi)部節(jié)點(diǎn)表示一個(gè)屬性上的測(cè)試,每個(gè)分支代表一個(gè)測(cè)試輸出,每個(gè)葉子節(jié)點(diǎn)代表一種類別。
用從樹(shù)根到樹(shù)葉的二叉樹(shù)來(lái)舉個(gè)簡(jiǎn)單例子。假如從樹(shù)根進(jìn)來(lái)有個(gè)二分類,我們需要區(qū)分它是人臉或者是非人臉,左邊是非人臉,右邊是人臉。當(dāng)我進(jìn)入第一個(gè)二叉樹(shù)分類器節(jié)點(diǎn)判斷,如果是非人臉的話直接輸出結(jié)果,如果是人臉候選的話進(jìn)入下一層再做進(jìn)一步的分類。通過(guò)學(xué)習(xí)每個(gè)節(jié)點(diǎn)的分類器來(lái)構(gòu)造決策樹(shù),最終形成一個(gè)強(qiáng)分類器。
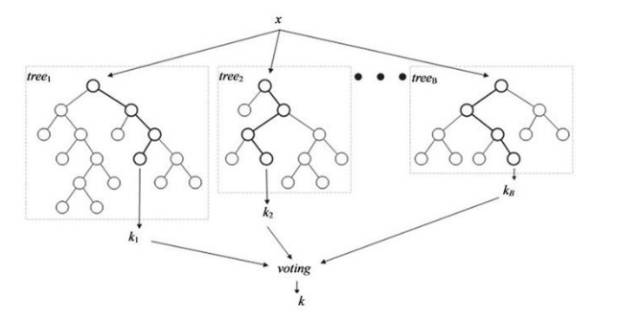
Random Forest
通過(guò)對(duì)決策樹(shù)進(jìn)行Ensemble,組合成隨機(jī)森林更好的提高分類或者回歸精度。假設(shè)剛剛提到的決策樹(shù)是一棵樹(shù),那么現(xiàn)在我想學(xué)十棵樹(shù),每個(gè)樹(shù)采用不同的輸入或者分類準(zhǔn)則,從不同維度來(lái)做分類。以十棵樹(shù)的分類結(jié)果進(jìn)行投票,8個(gè)樹(shù)認(rèn)為這個(gè)框是人臉,2個(gè)認(rèn)為是非人臉,最終輸出為人臉。投票策略可以更好地降低分類誤差,在實(shí)際場(chǎng)景中得到廣泛應(yīng)用。
從傳統(tǒng)方法到深度學(xué)習(xí)
眾所周知,檢測(cè)算法的演變分為兩個(gè)階段,一個(gè)就是基于傳統(tǒng)特征的解決方法,另外一個(gè)就是深度學(xué)習(xí)算法。在2013年之前傳統(tǒng)方法還算是主流,大家都是基于傳統(tǒng)的feature優(yōu)化檢測(cè)方法。然而,在2013年之后,,整個(gè)學(xué)術(shù)界和工業(yè)界都逐漸利用深度學(xué)習(xí)來(lái)做檢測(cè)。
實(shí)際上,這是由于深度學(xué)習(xí)在分類上超越了很多傳統(tǒng)的方法,在2012年的ImageNet上,Hinton兩個(gè)學(xué)生就曾用ConvNet獲得了冠軍。與傳統(tǒng)方法相比,深度學(xué)習(xí)在分類精度上提高很多。起先,深度學(xué)習(xí)只是在分類上有非常明顯的提升,之后也帶動(dòng)了檢測(cè)這一塊。從物體分類到物體檢測(cè),利用了深度學(xué)習(xí)比較強(qiáng)的feature的表達(dá)能力,可以進(jìn)一步提高檢測(cè)的精度。
檢測(cè)方面有兩個(gè)比較典型的公開(kāi)測(cè)試集,PASCAL VOC和COCO。從這兩個(gè)測(cè)試集上可以看到傳統(tǒng)的檢測(cè)方法和深度學(xué)習(xí)的檢測(cè)方法在精度上的差別非常的大。傳統(tǒng)的物體檢測(cè)方法因?yàn)槠涮卣鞅容^弱,所以每類都需要訓(xùn)練一個(gè)檢測(cè)器。每個(gè)檢測(cè)器都是針對(duì)特定的物體訓(xùn)練,如果有20類的話,就需要跑20次前向預(yù)測(cè),相當(dāng)于單次檢測(cè)的20倍,作為一個(gè)2C端產(chǎn)品,時(shí)間消耗和精度性能使得傳統(tǒng)方法檢測(cè)的應(yīng)用場(chǎng)景不是很多。
目前最新的檢測(cè)都是基于深度學(xué)習(xí)的方法,最開(kāi)始的RCNN,它算是深度學(xué)習(xí)應(yīng)用到檢測(cè)里的鼻祖,從起初它平均49.6的精度記錄,到如今已然提升了快40個(gè)點(diǎn)。而在傳統(tǒng)的方法中SVM-HOG,它的精度才到了31.5,和深度學(xué)習(xí)相比低了很多。

值得注意的是,傳統(tǒng)檢測(cè)方法隨著數(shù)據(jù)量增大檢測(cè)性能會(huì)趨于飽和,也就是說(shuō)隨著數(shù)據(jù)量的增大,檢測(cè)性能會(huì)逐漸提高,但到了一定程度之后數(shù)據(jù)量的提高帶來(lái)的性能增益非常少。而深度學(xué)習(xí)的方法則不同,當(dāng)符合實(shí)際場(chǎng)景分布的數(shù)據(jù)越來(lái)越多時(shí),其檢測(cè)性能會(huì)越來(lái)越好。
深度學(xué)習(xí)的物體檢測(cè)
深度學(xué)習(xí)早期的物體檢測(cè),大都使用滑動(dòng)窗口的方式進(jìn)行窗口提取,這種方式本質(zhì)是窮舉法 R-CNN。后來(lái)提出Selective Search等Proposal窗口提取算法,對(duì)于給定的圖像,不需要再使用一個(gè)滑動(dòng)窗口進(jìn)行圖像掃描,而是采用某種方式“提取”出一些候選窗口,在獲得對(duì)待檢測(cè)目標(biāo)可接受的召回率的前提下,候選窗口的數(shù)量可以控制在幾千個(gè)或者幾百個(gè)。
之后又出現(xiàn)了SPP,其主要思想是去掉了原始圖像上的crop/warp等操作,換成了在卷積特征上的空間金字塔池化層。那么為什么要引入SPP層呢?其實(shí)主要原因是CNN的全連接層要求輸入圖片是大小一致的,而實(shí)際中的輸入圖片往往大小不一,如果直接縮放到同一尺寸,很可能有的物體會(huì)充滿整個(gè)圖片,而有的物體可能只能占到圖片的一角。SPP對(duì)整圖提取固定維度的特征,首先把圖片均分成4份,每份提取相同維度的特征,再把圖片均分為16份,以此類推。可以看出,無(wú)論圖片大小如何,提取出來(lái)的維度數(shù)據(jù)都是一致的,這樣就可以統(tǒng)一送至全連接層。
實(shí)際上,盡管R-CNN 和SPP在檢測(cè)方面有了較大的進(jìn)步,但是其帶來(lái)的重復(fù)計(jì)算問(wèn)題讓人頭疼,而 Fast R-CNN 的出現(xiàn)正是為了解決這些問(wèn)題。Fast R-CNN使用一個(gè)簡(jiǎn)化的SPP層 —— RoI(Region of Interesting) Pooling層,其操作與SPP類似,同時(shí)它的訓(xùn)練和測(cè)試是不再分多步,不再需要額外的硬盤來(lái)存儲(chǔ)中間層的特征,梯度也能夠通過(guò)RoI Pooling層直接傳播。Fast R-CNN還使用SVD分解全連接層的參數(shù)矩陣,壓縮為兩個(gè)規(guī)模小很多的全連接層。
Fast R-CNN使用Selective Search來(lái)進(jìn)行區(qū)域提取,速度依然不夠快。Faster R-CNN則直接利用RPN(Region Proposal Networks)網(wǎng)絡(luò)來(lái)計(jì)算候選框。RPN以一張任意大小的圖片為輸入,輸出一批矩形區(qū)域,每個(gè)區(qū)域?qū)?yīng)一個(gè)目標(biāo)分?jǐn)?shù)和位置信息。從 R-CNN 到 Faster R-CNN,這是一個(gè)化零為整的過(guò)程,其之所以能夠成功,一方面得益于CNN強(qiáng)大的非線性建模能力,能夠?qū)W習(xí)出契合各種不同子任務(wù)的特征,另一方面也是因?yàn)槿藗冋J(rèn)識(shí)和思考檢測(cè)問(wèn)題的角度在不斷發(fā)生改變,打破舊有滑動(dòng)窗口的框架,將檢測(cè)看成一個(gè)回歸問(wèn)題,不同任務(wù)之間的耦合。
R-CNN到Faster R-CNN都是一些通用的檢測(cè)器。深度學(xué)習(xí)中還有許多特定物體檢測(cè)的方法,如Cascade CNN等,隨著技術(shù)的發(fā)展,深度學(xué)習(xí)的檢測(cè)越來(lái)越成熟。
難點(diǎn)
盡管深度學(xué)習(xí)已經(jīng)使得檢測(cè)性能提升了一大截,但其實(shí)依舊存在許多難點(diǎn)。主要難點(diǎn)就是復(fù)雜光照情況(過(guò)暗、過(guò)曝)以及非剛性物體形變(如人體、手勢(shì)的各種姿態(tài))、低分辨率和模糊圖片的檢測(cè)場(chǎng)景。
眾所周知,目前大多數(shù)檢測(cè)算法還是靜態(tài)圖的檢測(cè),而海量視頻數(shù)據(jù)已然出現(xiàn)了,未來(lái)檢測(cè)數(shù)據(jù)支持的類別肯定越來(lái)越多,涵蓋的面越來(lái)越廣,檢測(cè)技術(shù)在這方面也需要繼續(xù)發(fā)展。基于視頻時(shí)序連續(xù)性的物體檢測(cè)和像素級(jí)的實(shí)例檢測(cè)將是未來(lái)重點(diǎn)突破的方向。
聲明:部分內(nèi)容來(lái)源于網(wǎng)絡(luò),僅供讀者學(xué)術(shù)交流之目的。文章版權(quán)歸原作者所有。如有不妥,請(qǐng)聯(lián)系刪除。
責(zé)任編輯:psy
原文標(biāo)題:物體檢測(cè)算法全概述:從傳統(tǒng)檢測(cè)方法到深度神經(jīng)網(wǎng)絡(luò)框架
文章出處:【微信公眾號(hào):新機(jī)器視覺(jué)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
檢測(cè)
+關(guān)注
關(guān)注
5文章
4488瀏覽量
91472 -
分類器
+關(guān)注
關(guān)注
0文章
152瀏覽量
13182 -
物體檢測(cè)
+關(guān)注
關(guān)注
0文章
8瀏覽量
9180
原文標(biāo)題:物體檢測(cè)算法全概述:從傳統(tǒng)檢測(cè)方法到深度神經(jīng)網(wǎng)絡(luò)框架
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺(jué)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
卷積神經(jīng)網(wǎng)絡(luò)的實(shí)現(xiàn)工具與框架
卷積神經(jīng)網(wǎng)絡(luò)與傳統(tǒng)神經(jīng)網(wǎng)絡(luò)的比較
深度神經(jīng)網(wǎng)絡(luò)在雷達(dá)系統(tǒng)中的應(yīng)用
pytorch中有神經(jīng)網(wǎng)絡(luò)模型嗎
基于深度學(xué)習(xí)的小目標(biāo)檢測(cè)
深度神經(jīng)網(wǎng)絡(luò)概述及其應(yīng)用
深度神經(jīng)網(wǎng)絡(luò)與基本神經(jīng)網(wǎng)絡(luò)的區(qū)別
神經(jīng)網(wǎng)絡(luò)芯片與傳統(tǒng)芯片的區(qū)別和聯(lián)系
cnn卷積神經(jīng)網(wǎng)絡(luò)分類有哪些
卷積神經(jīng)網(wǎng)絡(luò)的基本概念和工作原理
深度神經(jīng)網(wǎng)絡(luò)模型有哪些
口罩佩戴檢測(cè)算法

安全帽佩戴檢測(cè)算法

咳嗽檢測(cè)深度神經(jīng)網(wǎng)絡(luò)算法
詳解深度學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)與卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論