 研究證明:商業語音識別系統的錯誤率非常高
研究證明:商業語音識別系統的錯誤率非常高
某些語音識別系統(ASR)的準確性可能要比之前假定的差很多。”這是最近約翰·霍普金斯大學、波蘭波茲南工業大學、弗羅茨瓦夫科技大學以及初創公司Avaya的研究人員一項正在進行的研究主要發現。
這項研究對內部創建的數據集上的商業語音識別模型進行了基準測試。共同作者聲稱,詞錯誤率(Word Error Rate, WER)(一種常見的語音識別性能指標)要顯著高于最佳報告結果,這可能表明自然語言處理(NLP)領域存在更多待克服的問題。
據了解,目前ASR已廣泛應用于諸多場景中,如電話會議、電子郵件、智能設備等。ASR模型的綜合基準中,標準語料庫的WER僅有2%~3%,而正是這一統計數據遭到了上述作者的質疑。他們聲稱,大多數ASR的交互場景都是在“類似于聊天機器人”的背景下進行的,說話人往往因為意識到跟他們的交互對象是聊天機器人,因此通常會將命令簡化成結構緊湊的簡短詞語,而非正常的自然對話。作者基于來自1595個供應商和1261個客戶的50個呼叫中心對話數據集對幾套ASR系統進行了評估。其通常時間長達8.5個小時,其中2.2個小時是對話。通過測試,作者發現ASR系統的錯誤率基本在15%以下,這與基準測試中的2%相悖。
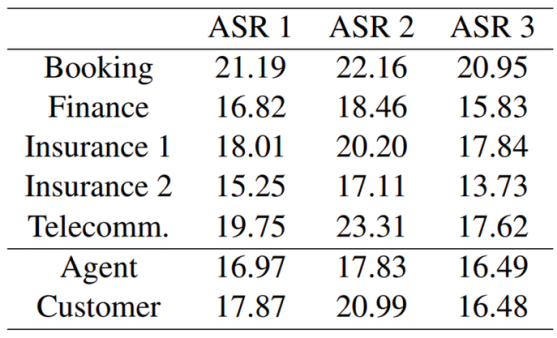
而基于保險、通信、預定等金融行業的語料庫中,作者發現其WER的測試結果高達23.31%。其中,預定和通信的錯誤率最高,可能是因為對話涉及特定的日期、時間、訂單金額、地點、產品和公司名稱等。但在所有領域的測試中,其錯誤率均高于13.73%。
研究人員將這一問題歸結為領域適應性問題——基準測試使用了單一性語料,例如Librispeech(1000小時英語有聲讀物錄音)、WSJ(新聞口述的談話)和Switchboard(電話交談),這些都可能太過簡單而無法真正挑戰ASR系統的可靠性。
而且,盡管他們試圖刻意模仿真實、自發的對話,但本質上還是受約束的,比如需要配音演員,就某一合適主題進行腳本/半腳本對話,而且正是由于配音演員的存在,幾乎都不需要考慮因性別、母語因素而產生的發音問題。
作為一種補救措施,研究人員建議ASR和NLP社區收集和注釋音頻數據集,使其更好地與ASR系統的實際應用場景保持一致,他們還呼吁建立更具包容性的聲學模型,更廣泛的方言語料庫,這些改變將會促進音頻信號處理的技術改進。
因此,這些問題并非無法克服。“學界和工業界應該深思熟慮,考慮可以創建高質量的測試數據集。我們認為,對ASR準確性的過于樂觀會損害NLP領域下游應用程序的開發。”研究人員最后表示。
責編AJX
-
軟件
+關注
關注
69文章
4970瀏覽量
87711 -
語音識別
+關注
關注
38文章
1742瀏覽量
112717 -
ASR
+關注
關注
2文章
43瀏覽量
18754
發布評論請先 登錄
相關推薦
【「嵌入式系統設計與實現」閱讀體驗】+ 基于語音識別的智能杯墊
OpenAI攻克Sora視頻創建錯誤率高難題
標貝數據標注案例分享:車載語音系統數據標注

九芯電子熱水器語音識別芯片IC方案,解放雙手,高識別率

RFID識別系統
九芯電子熱水器語音識別芯片IC方案,解放雙手,高識別率
物聯網系統智能控制產品的語音識別方案_離線語音識別芯片分析

什么是離線語音識別芯片?與在線語音識別的區別
基于FPGA的指紋識別系統設計
多目標智能識別系統
基于OpenCV的人臉識別系統設計
基于GIS的SAR多目標智能識別系統
車載語音識別系統語音數據采集標注案例





 工商網監
工商網監
評論