 如何寫出讓CPU執行更快的代碼?
如何寫出讓CPU執行更快的代碼?
轉自:小林coding
前言
代碼都是由 CPU 跑起來的,我們代碼寫的好與壞就決定了 CPU 的執行效率,特別是在編寫計算密集型的程序,更要注重 CPU 的執行效率,否則將會大大影響系統性能。
CPU 內部嵌入了 CPU Cache(高速緩存),它的存儲容量很小,但是離 CPU 核心很近,所以緩存的讀寫速度是極快的,那么如果 CPU 運算時,直接從 CPU Cache 讀取數據,而不是從內存的話,運算速度就會很快。
但是,大多數人不知道 CPU Cache 的運行機制,以至于不知道如何才能夠寫出能夠配合 CPU Cache 工作機制的代碼,一旦你掌握了它,你寫代碼的時候,就有新的優化思路了。
那么,接下來我們就來看看,CPU Cache 到底是什么樣的,是如何工作的呢,又該寫出讓 CPU 執行更快的代碼呢?
正文
CPU Cache 有多快?
你可能會好奇為什么有了內存,還需要 CPU Cache?根據摩爾定律,CPU 的訪問速度每 18 個月就會翻倍,相當于每年增長 60% 左右,內存的速度當然也會不斷增長,但是增長的速度遠小于 CPU,平均每年只增長 7% 左右。于是,CPU 與內存的訪問性能的差距不斷拉大。
到現在,一次內存訪問所需時間是200~300多個時鐘周期,這意味著 CPU 和內存的訪問速度已經相差200~300多倍了。
為了彌補 CPU 與內存兩者之間的性能差異,就在 CPU 內部引入了 CPU Cache,也稱高速緩存。
CPU Cache 通常分為大小不等的三級緩存,分別是L1 Cache、L2 Cache 和 L3 Cache。
由于 CPU Cache 所使用的材料是 SRAM,價格比內存使用的 DRAM 高出很多,在當今每生產 1 MB 大小的 CPU Cache 需要 7 美金的成本,而內存只需要 0.015 美金的成本,成本方面相差了 466 倍,所以 CPU Cache 不像內存那樣動輒以 GB 計算,它的大小是以 KB 或 MB 來計算的。
在 Linux 系統中,我們可以使用下圖的方式來查看各級 CPU Cache 的大小,比如我這手上這臺服務器,離 CPU 核心最近的 L1 Cache 是 32KB,其次是 L2 Cache 是 256KB,最大的 L3 Cache 則是 3MB。

其中,L1 Cache 通常會分為「數據緩存」和「指令緩存」,這意味著數據和指令在 L1 Cache 這一層是分開緩存的,上圖中的index0也就是數據緩存,而index1則是指令緩存,它兩的大小通常是一樣的。
另外,你也會注意到,L3 Cache 比 L1 Cache 和 L2 Cache 大很多,這是因為L1 Cache 和 L2 Cache 都是每個 CPU 核心獨有的,而 L3 Cache 是多個 CPU 核心共享的。
程序執行時,會先將內存中的數據加載到共享的 L3 Cache 中,再加載到每個核心獨有的 L2 Cache,最后進入到最快的 L1 Cache,之后才會被 CPU 讀取。它們之間的層級關系,如下圖:
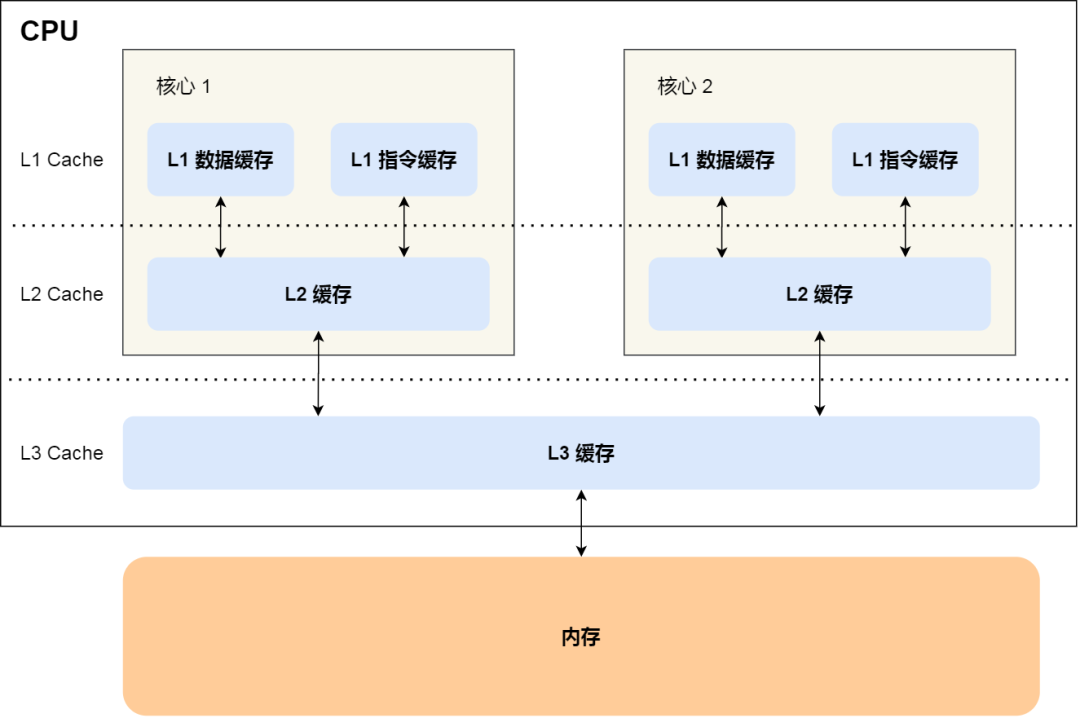
越靠近 CPU 核心的緩存其訪問速度越快,CPU 訪問 L1 Cache 只需要2~4個時鐘周期,訪問 L2 Cache 大約10~20個時鐘周期,訪問 L3 Cache 大約20~60個時鐘周期,而訪問內存速度大概在200~300個 時鐘周期之間。如下表格:
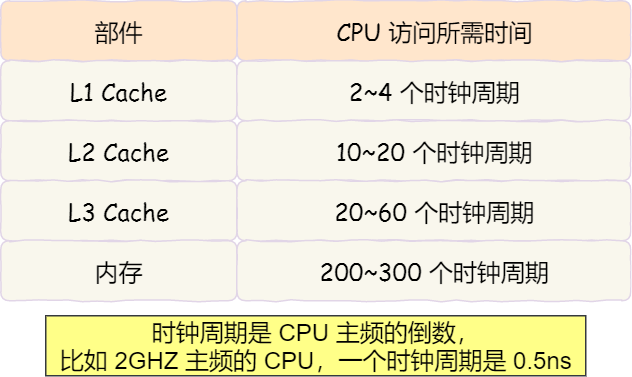
所以,CPU 從 L1 Cache 讀取數據的速度,相比從內存讀取的速度,會快100多倍。
CPU Cache 的數據結構和讀取過程是什么樣的?
CPU Cache 的數據是從內存中讀取過來的,它是以一小塊一小塊讀取數據的,而不是按照單個數組元素來讀取數據的,在 CPU Cache 中的,這樣一小塊一小塊的數據,稱為Cache Line(緩存塊)。
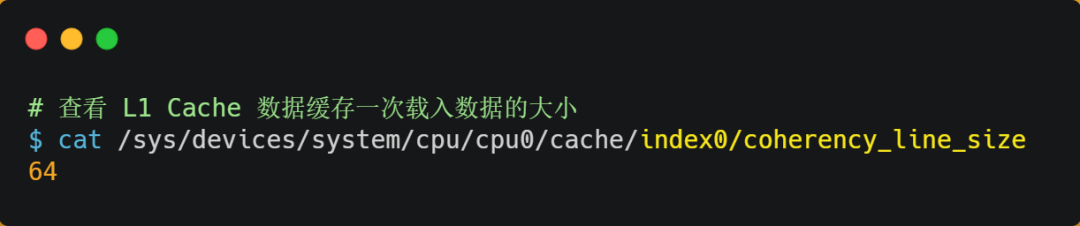
你可以在你的 Linux 系統,用下面這種方式來查看 CPU 的 Cache Line,你可以看我服務器的 L1 Cache Line 大小是 64 字節,也就意味著L1 Cache 一次載入數據的大小是 64 字節。
比如,有一個int array[100]的數組,當載入array[0]時,由于這個數組元素的大小在內存只占 4 字節,不足 64 字節,CPU 就會順序加載數組元素到array[15],意味著array[0]~array[15]數組元素都會被緩存在 CPU Cache 中了,因此當下次訪問這些數組元素時,會直接從 CPU Cache 讀取,而不用再從內存中讀取,大大提高了 CPU 讀取數據的性能。
事實上,CPU 讀取數據的時候,無論數據是否存放到 Cache 中,CPU 都是先訪問 Cache,只有當 Cache 中找不到數據時,才會去訪問內存,并把內存中的數據讀入到 Cache 中,CPU 再從 CPU Cache 讀取數據。
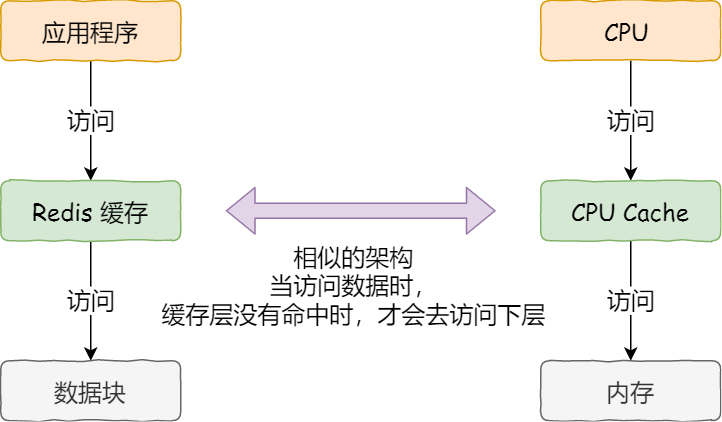
這樣的訪問機制,跟我們使用「內存作為硬盤的緩存」的邏輯是一樣的,如果內存有緩存的數據,則直接返回,否則要訪問龜速一般的硬盤。
那 CPU 怎么知道要訪問的內存數據,是否在 Cache 里?如果在的話,如何找到 Cache 對應的數據呢?我們從最簡單、基礎的直接映射 Cache(Direct Mapped Cache)說起,來看看整個 CPU Cache 的數據結構和訪問邏輯。
前面,我們提到 CPU 訪問內存數據時,是一小塊一小塊數據讀取的,具體這一小塊數據的大小,取決于coherency_line_size的值,一般 64 字節。在內存中,這一塊的數據我們稱為內存塊(Bock),讀取的時候我們要拿到數據所在內存塊的地址。
對于直接映射 Cache 采用的策略,就是把內存塊的地址始終「映射」在一個 CPU Line(緩存塊) 的地址,至于映射關系實現方式,則是使用「取模運算」,取模運算的結果就是內存塊地址對應的 CPU Line(緩存塊) 的地址。
舉個例子,內存共被劃分為 32 個內存塊,CPU Cache 共有 8 個 CPU Line,假設 CPU 想要訪問第 15 號內存塊,如果 15 號內存塊中的數據已經緩存在 CPU Line 中的話,則是一定映射在 7 號 CPU Line 中,因為15 % 8的值是 7。
機智的你肯定發現了,使用取模方式映射的話,就會出現多個內存塊對應同一個 CPU Line,比如上面的例子,除了 15 號內存塊是映射在 7 號 CPU Line 中,還有 7 號、23 號、31 號內存塊都是映射到 7 號 CPU Line 中。
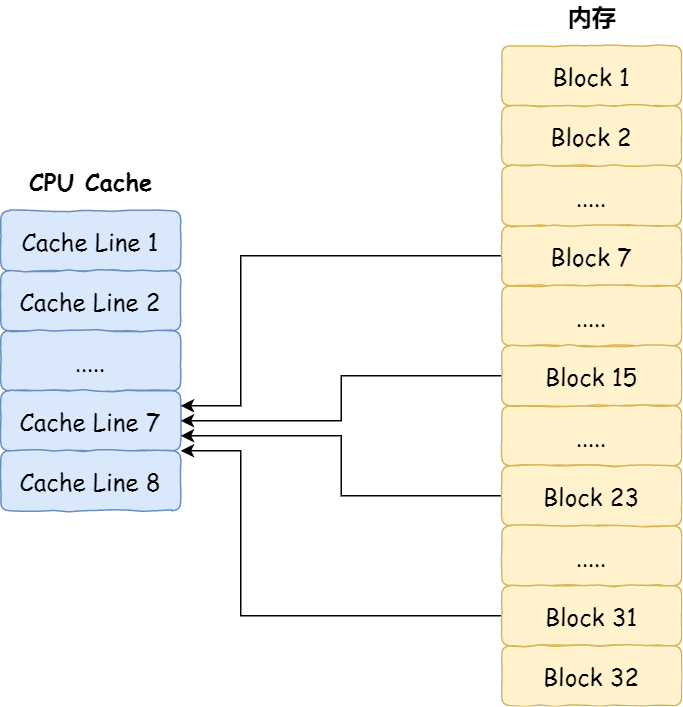
因此,為了區別不同的內存塊,在對應的 CPU Line 中我們還會存儲一個組標記(Tag)。這個組標記會記錄當前 CPU Line 中存儲的數據對應的內存塊,我們可以用這個組標記來區分不同的內存塊。
除了組標記信息外,CPU Line 還有兩個信息:
一個是,從內存加載過來的實際存放數據(Data)。
另一個是,有效位(Valid bit),它是用來標記對應的 CPU Line 中的數據是否是有效的,如果有效位是 0,無論 CPU Line 中是否有數據,CPU 都會直接訪問內存,重新加載數據。
CPU 在從 CPU Cache 讀取數據的時候,并不是讀取 CPU Line 中的整個數據塊,而是讀取 CPU 所需要的一個數據片段,這樣的數據統稱為一個字(Word)。那怎么在對應的 CPU Line 中數據塊中找到所需的字呢?答案是,需要一個偏移量(Offset)。
因此,一個內存的訪問地址,包括組標記、CPU Line 索引、偏移量這三種信息,于是 CPU 就能通過這些信息,在 CPU Cache 中找到緩存的數據。而對于 CPU Cache 里的數據結構,則是由索引 + 有效位 + 組標記 + 數據塊組成。
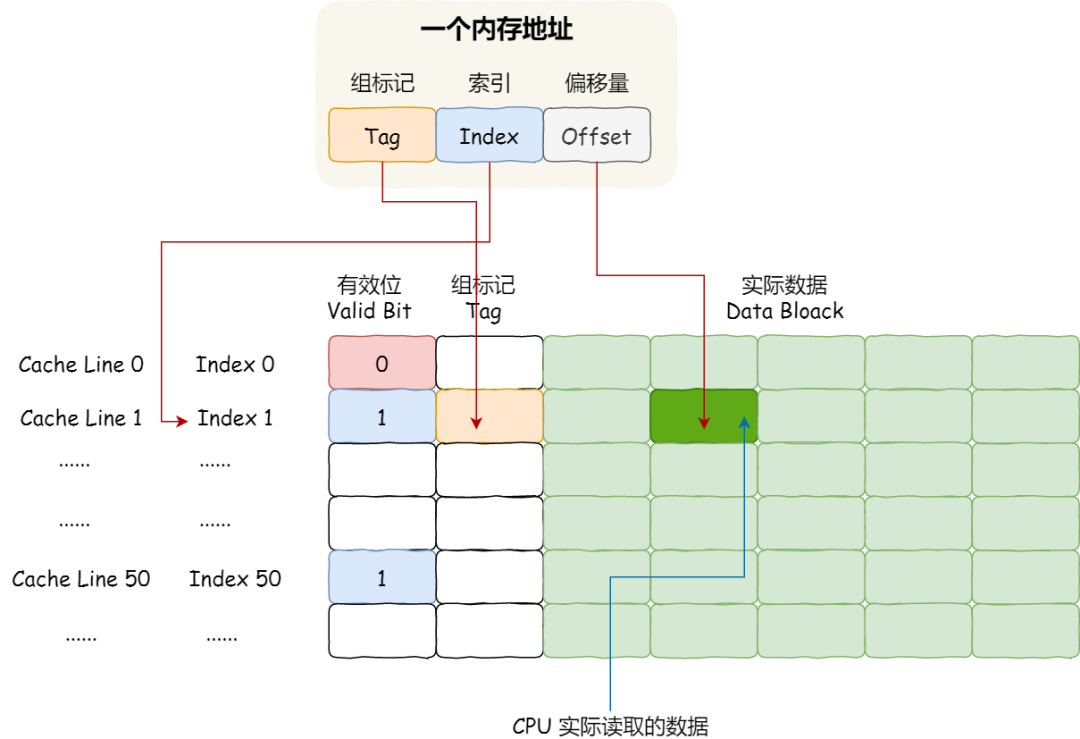
如果內存中的數據已經在 CPU Cahe 中了,那 CPU 訪問一個內存地址的時候,會經歷這 4 個步驟:
根據內存地址中索引信息,計算在 CPU Cahe 中的索引,也就是找出對應的 CPU Line 的地址;
找到對應 CPU Line 后,判斷 CPU Line 中的有效位,確認 CPU Line 中數據是否是有效的,如果是無效的,CPU 就會直接訪問內存,并重新加載數據,如果數據有效,則往下執行;
對比內存地址中組標記和 CPU Line 中的組標記,確認 CPU Line 中的數據是我們要訪問的內存數據,如果不是的話,CPU 就會直接訪問內存,并重新加載數據,如果是的話,則往下執行;
根據內存地址中偏移量信息,從 CPU Line 的數據塊中,讀取對應的字。
到這里,相信你對直接映射 Cache 有了一定認識,但其實除了直接映射 Cache 之外,還有其他通過內存地址找到 CPU Cache 中的數據的策略,比如全相連 Cache (Fully Associative Cache)、組相連 Cache (Set Associative Cache)等,這幾種策策略的數據結構都比較相似,我們理解流直接映射 Cache 的工作方式,其他的策略如果你有興趣去看,相信很快就能理解的了。
如何寫出讓 CPU 跑得更快的代碼?
我們知道 CPU 訪問內存的速度,比訪問 CPU Cache 的速度慢了 100 多倍,所以如果 CPU 所要操作的數據在 CPU Cache 中的話,這樣將會帶來很大的性能提升。訪問的數據在 CPU Cache 中的話,意味著緩存命中,緩存命中率越高的話,代碼的性能就會越好,CPU 也就跑的越快。
于是,「如何寫出讓 CPU 跑得更快的代碼?」這個問題,可以改成「如何寫出 CPU 緩存命中率高的代碼?」。
在前面我也提到, L1 Cache 通常分為「數據緩存」和「指令緩存」,這是因為 CPU 會別處理數據和指令,比如1+1=2這個運算,+就是指令,會被放在「指令緩存」中,而輸入數字1則會被放在「數據緩存」里。
因此,我們要分開來看「數據緩存」和「指令緩存」的緩存命中率。
如何提升數據緩存的命中率?
假設要遍歷二維數組,有以下兩種形式,雖然代碼執行結果是一樣,但你覺得哪種形式效率最高呢?為什么高呢?

經過測試,形式一array[i][j]執行時間比形式二array[j][i]快好幾倍。
之所以有這么大的差距,是因為二維數組array所占用的內存是連續的,比如長度N的指是2的話,那么內存中的數組元素的布局順序是這樣的:

形式一用array[i][j]訪問數組元素的順序,正是和內存中數組元素存放的順序一致。當 CPU 訪問array[0][0]時,由于該數據不在 Cache 中,于是會「順序」把跟隨其后的 3 個元素從內存中加載到 CPU Cache,這樣當 CPU 訪問后面的 3 個數組元素時,就能在 CPU Cache 中成功地找到數據,這意味著緩存命中率很高,緩存命中的數據不需要訪問內存,這便大大提高了代碼的性能。
而如果用形式二的array[j][i]來訪問,則訪問的順序就是:

你可以看到,訪問的方式跳躍式的,而不是順序的,那么如果 N 的數值很大,那么操作array[j][i]時,是沒辦法把array[j+1][i]也讀入到 CPU Cache 中的,既然array[j+1][i]沒有讀取到 CPU Cache,那么就需要從內存讀取該數據元素了。很明顯,這種不連續性、跳躍式訪問數據元素的方式,可能不能充分利用到了 CPU Cache 的特性,從而代碼的性能不高。
那訪問array[0][0]元素時,CPU 具體會一次從內存中加載多少元素到 CPU Cache 呢?這個問題,在前面我們也提到過,這跟 CPU Cache Line 有關,它表示CPU Cache 一次性能加載數據的大小,可以在 Linux 里通過coherency_line_size配置查看 它的大小,通常是 64 個字節。
也就是說,當 CPU 訪問內存數據時,如果數據不在 CPU Cache 中,則會一次性會連續加載 64 字節大小的數據到 CPU Cache,那么當訪問array[0][0]時,由于該元素不足 64 字節,于是就會往后順序讀取array[0][0]~array[0][15]到 CPU Cache 中。順序訪問的array[i][j]因為利用了這一特點,所以就會比跳躍式訪問的array[j][i]要快。
因此,遇到這種遍歷數組的情況時,按照內存布局順序訪問,將可以有效的利用 CPU Cache 帶來的好處,這樣我們代碼的性能就會得到很大的提升,
如何提升指令緩存的命中率?
提升數據的緩存命中率的方式,是按照內存布局順序訪問,那針對指令的緩存該如何提升呢?
我們以一個例子來看看,有一個元素為 0 到 100 之間隨機數字組成的一維數組:

接下來,對這個數組做兩個操作:

第一個操作,循環遍歷數組,把小于 50 的數組元素置為 0;
第二個操作,將數組排序;
那么問題來了,你覺得先遍歷再排序速度快,還是先排序再遍歷速度快呢?
在回答這個問題之前,我們先了解 CPU 的分支預測器。對于 if 條件語句,意味著此時至少可以選擇跳轉到兩段不同的指令執行,也就是 if 還是 else 中的指令。那么,如果分支預測可以預測到接下來要執行 if 里的指令,還是 else 指令的話,就可以「提前」把這些指令放在指令緩存中,這樣 CPU 可以直接從 Cache 讀取到指令,于是執行速度就會很快。
當數組中的元素是隨機的,分支預測就無法有效工作,而當數組元素都是順序的,分支預測器會動態地根據歷史命中數據對未來進行預測,這樣命中率就會很高。
因此,先排序再遍歷速度會更快,這是因為排序之后,數字是從小到大的,那么前幾次循環命中if < 50?的次數會比較多,于是分支預測就會緩存?if?里的?array[i] = 0?指令到 Cache 中,后續 CPU 執行該指令就只需要從 Cache 讀取就好了。
如果你肯定代碼中的if中的表達式判斷為true的概率比較高,我們可以使用顯示分支預測工具,比如在 C/C++ 語言中編譯器提供了likely和unlikely這兩種宏,如果if條件為ture的概率大,則可以用likely宏把if里的表達式包裹起來,反之用unlikely宏。

實際上,CPU 自身的動態分支預測已經是比較準的了,所以只有當非常確信 CPU 預測的不準,且能夠知道實際的概率情況時,才建議使用這兩種宏。
如果提升多核 CPU 的緩存命中率?
在單核 CPU,雖然只能執行一個進程,但是操作系統給每個進程分配了一個時間片,時間片用完了,就調度下一個進程,于是各個進程就按時間片交替地占用 CPU,從宏觀上看起來各個進程同時在執行。
而現代 CPU 都是多核心的,進程可能在不同 CPU 核心來回切換執行,這對 CPU Cache 不是有利的,雖然 L3 Cache 是多核心之間共享的,但是 L1 和 L2 Cache 都是每個核心獨有的,如果一個進程在不同核心來回切換,各個核心的緩存命中率就會受到影響,相反如果進程都在同一個核心上執行,那么其數據的 L1 和 L2 Cache 的緩存命中率可以得到有效提高,緩存命中率高就意味著 CPU 可以減少訪問 內存的頻率。
當有多個同時執行「計算密集型」的線程,為了防止因為切換到不同的核心,而導致緩存命中率下降的問題,我們可以把線程綁定在某一個 CPU 核心上,這樣性能可以得到非常可觀的提升。
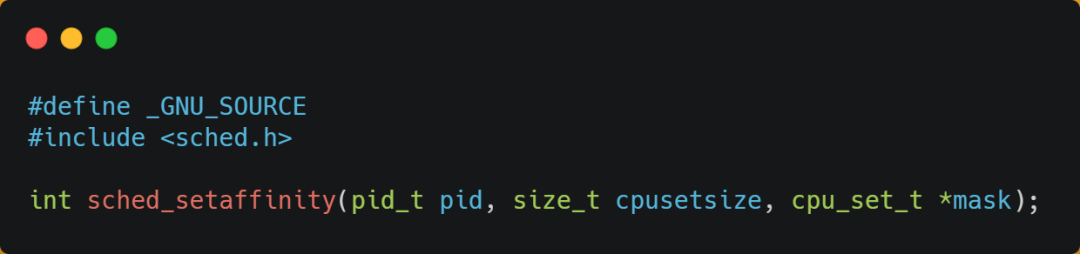
在 Linux 上提供了sched_setaffinity方法,來實現將線程綁定到某個 CPU 核心這一功能。
總結
由于隨著計算機技術的發展,CPU 與 內存的訪問速度相差越來越多,如今差距已經高達好幾百倍了,所以 CPU 內部嵌入了 CPU Cache 組件,作為內存與 CPU 之間的緩存層,CPU Cache 由于離 CPU 核心很近,所以訪問速度也是非常快的,但由于所需材料成本比較高,它不像內存動輒幾個 GB 大小,而是僅有幾十 KB 到 MB 大小。
當 CPU 訪問數據的時候,先是訪問 CPU Cache,如果緩存命中的話,則直接返回數據,就不用每次都從內存讀取速度了。因此,緩存命中率越高,代碼的性能越好。
但需要注意的是,當 CPU 訪問數據時,如果 CPU Cache 沒有緩存該數據,則會從內存讀取數據,但是并不是只讀一個數據,而是一次性讀取一塊一塊的數據存放到 CPU Cache 中,之后才會被 CPU 讀取。
內存地址映射到 CPU Cache 地址里的策略有很多種,其中比較簡單是直接映射 Cache,它巧妙的把內存地址拆分成「索引 + 組標記 + 偏移量」的方式,使得我們可以將很大的內存地址,映射到很小的 CPU Cache 地址里。
要想寫出讓 CPU 跑得更快的代碼,就需要寫出緩存命中率高的代碼,CPU L1 Cache 分為數據緩存和指令緩存,因而需要分別提高它們的緩存命中率:
對于數據緩存,我們在遍歷數據的時候,應該按照內存布局的順序操作,這是因為 CPU Cache 是根據 CPU Cache Line 批量操作數據的,所以順序地操作連續內存數據時,性能能得到有效的提升;
對于指令緩存,有規律的條件分支語句能夠讓 CPU 的分支預測器發揮作用,進一步提高執行的效率;
另外,對于多核 CPU 系統,線程可能在不同 CPU 核心來回切換,這樣各個核心的緩存命中率就會受到影響,于是要想提高進程的緩存命中率,可以考慮把線程綁定 CPU 到某一個 CPU 核心。
原文標題:面試官:如何寫出讓 CPU 跑得更快的代碼?
文章出處:【微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
cpu
+關注
關注
68文章
10871瀏覽量
211952 -
緩存
+關注
關注
1文章
240瀏覽量
26688 -
代碼
+關注
關注
30文章
4791瀏覽量
68671
原文標題:面試官:如何寫出讓 CPU 跑得更快的代碼?
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何寫出ADC的分時復用?
讓單片機代碼性能起飛的七大技巧
如何寫出穩定的單片機代碼
如同TPA6011芯片,耳機輸出端可以直接設計成兩組并聯輸出讓客戶可選擇插一個耳機或兩個耳機嗎?
為什么外設要通過接口與CPU相連
代碼整潔之道-大師眼中的整潔代碼是什么樣

cpu控制器負責什么運算
cpu控制器和運算器組成的部件有哪些
dma一直傳輸數據,cpu執行其他代碼有影響嗎?
CPU中斷程序:從硬件看什么是中斷?
服務器中的CPU核心和線程到底是什么?
為什么GPU比CPU更快?

處理器和cpu是一個東西嗎 cpu和主板的區別
如何寫出好的代碼?高質量代碼的三要素






 工商網監
工商網監
評論