 四足機器人可穿越各種復雜的環境 無需攝像頭、激光雷達等設備
四足機器人可穿越各種復雜的環境 無需攝像頭、激光雷達等設備
近日,瑞士 ANYbotics 公司打造的 ANYmal 機器人登上了新一期的《Science Robotics》封面,這款機器人的控制器可以使其穿越各種復雜的環境,包括溪流、草地、雪地、碎石坡等,而且不靠攝像頭、激光雷達等常見設備——平衡系統不需要任何外界信息的輸入,控制模型也不包含人類輸入的規則。
腿式運動擴展了機器人的應用范圍,但在地球上一些最具挑戰性的環境中,大部分腿式機器人依然無能為力。
多年來,瑞士 ANYbotics 公司的團隊一直在試圖解決這個問題,他們的最新研究成果——《Learning quadrupedal locomotion over challenging terrain》登上了新一期《Science Robotics》的封面。
在這篇論文中,他們提出了一種穩健的控制器,可以部署到 ANYbotics 旗下多種機器人中。有了新型控制器的加持,這些機器人可以輕松翻越溪流、草地、雪地、碎石坡等富有挑戰的場景。
我們可以看到,這些機器人可以輕松走過小溪:

行走在林間,即使是草木叢生的不平坦地面:

在下坡的雪地上行走:

從有水流過的臺階爬下去:

在這樣復雜的環境中行走,對于人或動物來說有時也會顯得磕磕絆絆,要打造能如履平地的機器人,難度自不必說了。
「傳統的」控制方法已經不夠用了
在不平坦的地形上,常規腿式運動方法方法使得控制架構越來越復雜。許多情況都要依賴復雜的狀態機來協調運動原語和反射控制器的執行。為了觸發狀態之間的轉換或反射的執行,許多系統都明確地預估狀態,例如地面接觸和滑行移動。這種預估通常是基于經驗設置的,并且在存在諸如泥土、雪地或植被等未建模因素的情況下可能會變得不穩定。還有一些在腳部使用接觸式傳感器的系統,在野外條件下也會變得不可靠。
總體而言,隨著考慮更多場景,用于在崎嶇等特殊地形上進行腿式運動的常規系統的復雜性不斷升級。在開發和維護方面變得非常困難,并且也容易出現控制器設計無法實現的情況(角落情況)。
近來無模型強化學習(RL)已經成為腿式機器人運動控制器開發中的一種替代方法。強化學習方向的觀點是調整控制器以優化給定的獎勵函數。優化是通過執行控制器本身獲取的數據來執行的,這會隨著經驗的增加而改進。強化學習已經用于簡化運動控制器的設計,自動化設計過程的各個部分以及學習之前的方法無法設計的行為。
但是,將強化學習用于腿式運動在很大程度上僅限于實驗中的環境和條件。此前的研究實現了運動和恢復行為的端到端學習,但僅限于在實驗室的平坦地面上進行。其他研究也開發了用于腿式運動的強化學習技術,但同樣是在實驗的環境中,主要集中在平坦或帶有中等紋理的表面上。
ANYbotics 的研究者提出了一種穩健的控制器,用于在充滿挑戰的地形上進行盲四足運動。該控制器僅使用聯合編碼器和慣性測量單元的本體感受(proprioceptive)度量,這是腿式機器人上最耐用最可靠的傳感器。控制器的操作如下圖所示。

該控制器被用于 ANYmal 四足機器人的兩代版本中。四足機器人在泥土、沙子、瓦礫、茂密的植被、雪地、水中和其他越野地形中安全地小跑。
研究人員介紹說,這個控制器由一種神經網絡策略驅動,在模擬環境中進行訓練。雖然沒有任何現實世界的數據和精確的地形模型,該控制器仍然能克服野外的各種不規則地形。研究人員還強調說,「我們的系統可以穿越視頻所示的所有地形,而且一次都沒有摔倒。」
此外,這項研究中提到的方法并沒有用到攝像頭、激光雷達或接觸式傳感器信息,只依賴本體感受傳感器信號(proprioceptive sensor signal)來提高控制策略在不同地形中的適應性和穩健性。
先模擬,再實戰
相比之下,對于有足機器人,我們對于波士頓動力旗下的產品更加了解一些,不過來自蘇黎世理工的 ANYmal 其實一樣能力強大。基于學習的運動控制器使四足 ANYmal 機器人能夠穿越充滿挑戰的自然環境。
與此前的一些無模型強化學習腿式運動方法一樣,研究人員先在模擬環境中訓練了控制器,隨后將訓練結果遷移到現實世界中。通常,首先需要在虛擬環境中對物理條件進行建模,進而參數隨機化。
蘇黎世理工的研究人員發現,這種方法對于更加崎嶇的地形效果不佳,因此研究人員引入了一些其他方法。首先在模型上,新方法沒有使用在機器人當前狀態的快照上運行的多層感知器(MLP),而是使用了序列模型,特別是感受狀態的時間卷積網絡(TCN)。新方法沒有使用顯式的接觸和滑動預估模塊,相反的 TCN 會根據需求從本體感受歷史中隱式地推理出接觸和滑動事件。

實現優化結果的第二個關鍵在于特權學習(privileged learning),研究人員發現直接通過強化學習訓練出的越野運動策略并不成功:控制信號稀疏,并且所輸出的網絡無法在合理的時間內學習出正確的運動。新的模型在訓練中分為兩個階段,首先訓練教師策略,該策略可訪問特權信息——真實情況(ground-truth)及機器人接觸的情況,隨后教師指導純本體感受的學生控制器學習,后者僅使用機器人本身可用的傳感器信息。
這種特權學習會在模擬環境中啟用,但最終學習到的策略可以在模擬環境,以及真實的物理環境中部署。
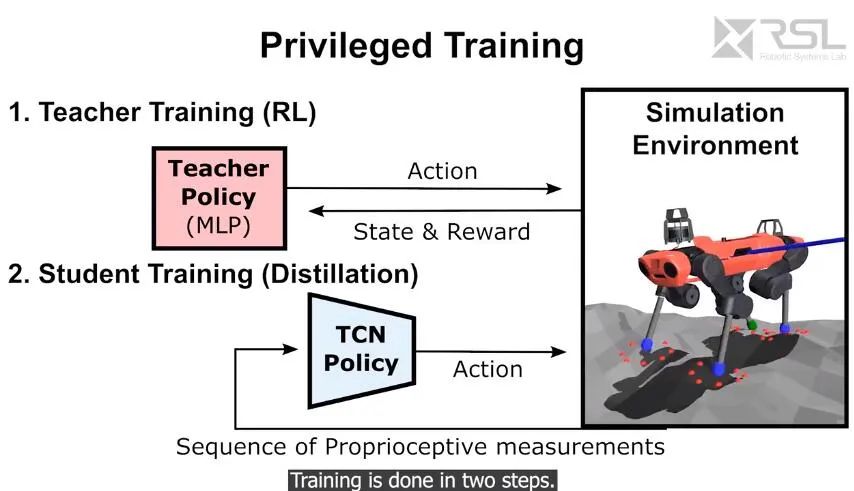
第三個概念對于實現其魯棒性很重要。該教程根據控制器在訓練過程不同階段的表現,對不同地形進行自適應。本質上,控制器會經歷各種合成地形的考驗,同時變得更具魯棒性。研究者評估了參數化地形的可通行性,并使用了粒子濾波來維持中等難度地形參數的分布,以適應神經網絡的學習。訓練環境的挑戰性逐漸增加,促使了這種敏捷性與彈性兼具的全方位控制器的誕生。
借助腿式運動控制器,機器人可以穿越一些現有方法無法到達的復雜地形。該控制器擁有在零樣本環境中的泛化能力,即使遇見訓練過程中未見過的條件,仍然具備魯棒性。
研究者在模擬訓練中只使用了剛性地貌和一組由程序生成的地形剖面,比如山丘和臺階。然而,當控制器被部署在四足機器人上時,它能夠成功應對可變化地形(比如泥土、苔蘚、雪地)、動態立足點(比如在雜亂室內環境踩到滾動板、田野中的碎片)和地面障礙物(厚植被、碎石、涌出的水)。
從研究結果來看,不需要進行艱苦的建模過程,以及危險且高成本的實地測試,物理世界的極度復雜性也可以被克服。這一方法或許會引領未來腿式機器人的發展。
更適合復雜環境,更適用于真實世界
在四足機器人領域里,名頭更響的波士頓動力 Spot 已在今年開賣了,目前全球已賣出約 300 臺,不過人們在使用 Spot 的時候會遭遇一些「翻車」情況。

對于面向工業場景的用戶來說,穩定性至關重要,在這方面不知 ANYmal 的機器人是否更加強大。在今年 6 月,這家公司的機器人也已向用戶交付了自家的四足機器人 Anymal C。
ANYmal 機器人由 ANYbotics 公司打造。ANYbotics 成立于 2016 年,是瑞士蘇黎世聯邦理工學院的衍生公司,致力于開發工業應用的移動機器人技術。該公司表示,其自動腿式機器人的設計目的是解決客戶在具有挑戰性的環境中遇到的問題。該公司已經在多個應用中進行過 ANYmal 機器人的成功測試,如在北海上進行的首例離岸機器人測試。
ANYbotics 的團隊表示,他們從事腿式機器人的研究已經超過 10 年,如今又根據工業需求重新對 ANYmal 機器人進行了設計。他們的研究核心是設計出強大的扭矩可控制動器,使得機器人能夠爬上陡峭的樓梯,可靠地承受各種環境變化帶來的壓力。
在過去的十年中,ANYmal 系列機器人也經歷了一系列的更新換代和技術革新,從最初的 ANYmal Alph 到 ANYmal Beth、ANYmal B 再到如今的 ANYmal C。經過數次迭代,ANYmal 變得越發強大。
論文鏈接:https://robotics.sciencemag.org/content/5/47/eabc5986
文章轉自“機器之心”
責任編輯:PSY
原文標題:不用攝像頭和激光雷達,四足機器人「憑感覺」越野
文章出處:【微信公眾號:中科院長春光機所】歡迎添加關注!文章轉載請注明出處。
-
控制器
+關注
關注
112文章
16427瀏覽量
178901 -
機器人
+關注
關注
211文章
28597瀏覽量
207832 -
瑞士
+關注
關注
0文章
14瀏覽量
10772 -
四足機器人
+關注
關注
1文章
92瀏覽量
15233
原文標題:不用攝像頭和激光雷達,四足機器人「憑感覺」越野
文章出處:【微信號:cas-ciomp,微信公眾號:中科院長春光機所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI驅動的人形機器人,成為激光雷達產業的下一個爆發點
京瓷發布全球首款“攝像頭-激光雷達”融合傳感器
四足機器人的結構、控制及運動控制
米爾瑞芯微RK3576實測輕松搞定三屏八攝像頭
激光雷達+攝像頭融合傳感器,有沒有搞頭?

禾賽拒絕“激光雷達無用論”

禾賽科技推出面向機器人領域的迷你3D激光雷達
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人的基礎模塊
禾賽科技12月激光雷達交付量突破10萬臺
《具身智能機器人系統》第1-6章閱讀心得之具身智能機器人系統背景知識與基礎模塊
認識機器人與CW32四足機器人控制項目
在NVIDIA Isaac Lab中訓練四足機器人運動
森思泰克全新推出96線激光雷達和192線激光雷達產品






 工商網監
工商網監
評論