") 計算機體系—存儲器芯片內(nèi)部技術(shù)與優(yōu)化
計算機體系—存儲器芯片內(nèi)部技術(shù)與優(yōu)化
本文描述在存儲器層次結(jié)構(gòu)中使用的技術(shù),特別是在構(gòu)建 Cache 和主內(nèi)存中。這些技術(shù)包括 SRAM(static randomaccess memory)、DRAM(dynamic random-access memory)和閃存(Flash)。這些中的最后一個被用作硬盤的替代品,但是由于其特性基于半導體技術(shù),因此適合在本文中進行介紹。
使用 SRAM 滿足了減少對 Cache 的訪問時間的需求。但是,當發(fā)生 Cache 未命中時,我們需要盡快從主存中移出數(shù)據(jù),這需要高帶寬的內(nèi)存。可以通過將構(gòu)成主存儲器的許多 DRAM 芯片組織到多個存儲體中,并使存儲器總線更寬,或者同時執(zhí)行這兩種操作,來實現(xiàn)這種高存儲帶寬。
為了使存儲器系統(tǒng)能夠滿足現(xiàn)代處理器的帶寬需求,在 DRAM 芯片內(nèi)部開始出現(xiàn)一些創(chuàng)新。本文介紹存儲器芯片內(nèi)部的技術(shù)以及那些創(chuàng)新的內(nèi)部結(jié)構(gòu)。
隨著突發(fā)傳輸存儲器的引入(現(xiàn)已廣泛用于閃存和 DRAM 中),存儲器的延遲主要由訪問時間和周期時間來組成。其中訪問時間是從發(fā)出讀請求至收到所需字之間的時間,周期時間是指對存儲器發(fā)出兩次不相關(guān)請求之間的最短時間。
自 1975 年以來,幾乎所有計算機都將 DRAM 用于主存儲器,將 SRAM 用于高速緩存,其中的 L1 到 L3 Cache 與 CPU 集成在處理器芯片上。PMD 必須在功率和性能之間取得平衡,并且由于它們具有更適度的存儲需求,因此 PMD 使用閃存而不是磁盤驅(qū)動器,臺式計算機也越來越遵循這一決定。
SRAM 技術(shù)
SRAM 的首字母代表靜態(tài)。DRAM 中電路的動態(tài)特性要求在讀取數(shù)據(jù)后將其寫回,因此訪問時間與周期時間之間的差異,并且需要刷新。SRAM 不需要刷新,因此訪問時間非常接近周期時間。SRAM 通常每 bit 數(shù)據(jù)需要使用六個晶體管,以防止信息在讀取時受到干擾。SRAM 僅需要最小的功率即可將電荷保持在待機模式。
在早期,大多數(shù)臺式機和服務器系統(tǒng)都將 SRAM 芯片用于其一級、二級或三級 Cache。如今,所有三個級別的 Cache 都已集成到處理器芯片中。在高端服務器芯片中,可能有多達 24 個內(nèi)核和多達 60 MiB 的 Cache。這樣的系統(tǒng)通常每個處理器芯片配置 128~256GiB 的 DRAM。大型的三級片上 Cache 的訪問時間通常是二級 Cache 的 2~8 倍。即使是這樣,L3 訪問時間通常至少比 DRAM 訪問快 5 倍。
片上 Cache SRAM 通常以與高速緩存的塊大小匹配的寬度進行組織,并且 Tag 與每個塊并行存儲。這樣可以在單個周期將整個塊讀出或?qū)懭搿.攲⑽疵泻螳@取的數(shù)據(jù)寫到 Cache 中或從 Cache 中寫回塊時,此功能特別有用。Cache 的訪問時間與緩存中的塊數(shù)成正比,而能耗取決于緩存中的位數(shù)(靜態(tài)功率)和塊數(shù)(動態(tài)功率)。組相聯(lián) Cache 會減少對內(nèi)存的初始訪問時間,因為內(nèi)存的大小較小,但是會增加命中檢測和塊選擇的時間。
DRAM 技術(shù)
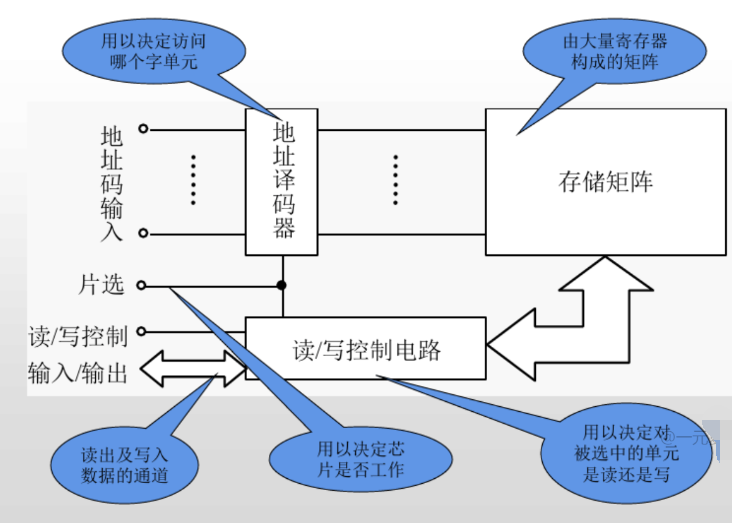
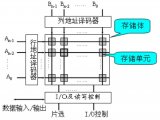
隨著早期 DRAM 容量的增長,帶有所有必需地址線的封裝的成本成為一個問題。解決方案是多路復用地址線,從而將地址引腳的數(shù)量減少一半。在行訪問選通(RAS)期間,首先發(fā)送地址的一半。緊隨其后在列訪問選通(CAS)期間發(fā)送的地址的另一半。這些名稱來自內(nèi)部芯片組織,因為存儲器是按行和列尋址的矩形矩陣進行組織的。
DRAM 的附加要求來自其首字母 D 所表示的動態(tài)特性。為了在每個芯片上存儲更多的位,DRAM 僅使用單個晶體管來存儲一個 bit。讀取時,將一行放入行緩沖區(qū),CAS 信號可以在其中選擇要從 DRAM 讀取的行的一部分。由于讀取行會破壞信息,因此在不再需要該行時必須將其寫回。這種寫回以重疊的方式發(fā)生,但是在早期的 DRAM 中,這意味著可以讀取新行之前的周期時間大于讀取一行并訪問該行的一部分的時間。
另外,為了防止由于單元中的電荷泄漏(假設未讀取或?qū)懭耄┒斐傻男畔G失,必須定期“刷新”每個位。幸運的是,只需讀取該行并將其寫回,就可以同時刷新一行中的所有位。因此,存儲系統(tǒng)中的每個 DRAM 必須在一定的時間范圍內(nèi)(例如 64 ms)訪問每一行。DRAM 控制器其中就包括用于定期刷新 DRAM 的硬件。
此要求意味著該存儲系統(tǒng)有時不可用,因為它正在發(fā)送信號告訴每個芯片刷新。刷新的時間是行激活和預充電,該預充電也將行寫回(大約需要 2/3 的時間來獲取數(shù)據(jù),因為不需要選擇列),而 DRAM 的每一行都需要這樣做。因為 DRAM 中的存儲矩陣在概念上是平方的,所以刷新中的步數(shù)通常是 DRAM 容量的平方根。DRAM 設計人員試圖將花在刷新上的時間保持在總時間的 5%以下。實際上,對于 SDRAM、DRAM 控制器(通常在處理器芯片上)試圖通過避免打開新行并在可能的情況下使用塊傳輸來優(yōu)化訪問。
根據(jù)經(jīng)驗,Amdahl 建議內(nèi)存容量應隨處理器速度線性增長,以保持系統(tǒng)平衡。因此,1000MIPS 處理器應具有 1000 MiB 的內(nèi)存。處理器設計人員依靠 DRAM 來滿足這一需求。過去,他們預計容量每三年提高四倍,即每年提高 55%。不幸的是,DRAM 的性能以非常慢的速度增長。性能提高較慢的主要原因是行訪問時間的減少較小,而行訪問時間的減少取決于諸如功率限制和單個存儲單元的充電容量(以及大小)之類的問題。
改善 DRAM 芯片內(nèi)部的內(nèi)存性能:SDRAM
盡管非常早的 DRAM 包含一個緩沖器,該緩沖器允許對單個行進行多列訪問,而無需進行新的行訪問,但它們使用了異步接口,這意味著每個列訪問和傳輸都涉及與控制器同步的開銷。在 1990 年代中期,設計人員將時鐘信號添加到 DRAM 接口,以便重復的傳輸不會承擔該開銷,從而創(chuàng)建了同步 DRAM(SDRAM)。除了減少開銷外,SDRAM 還允許添加突發(fā)傳輸模式,在這種模式下可以進行多次傳輸而無需指定新的列地址。通常,通過將 DRAM 置于突發(fā)模式,可以在不發(fā)送任何新地址的情況下進行八次或更多次 16 位傳輸。
為了克服隨著 DRAM 密度增加而從內(nèi)存獲得更多帶寬的問題,使 DRAM 變得更寬。最初,他們提供了一種四位傳輸模式。在 2017 年,DDR2、DDR3 和 DDR DRAM 擁有多達 4、8 或 16 位總線。
在 2000 年代初期,引入了進一步的創(chuàng)新:雙倍數(shù)據(jù)速率(DDR),它使 DRAM 在時鐘的上升沿和下降沿都能傳輸數(shù)據(jù),從而使峰值數(shù)據(jù)速率加倍。
最后,SDRAM 引入了 banks,以幫助進行電源管理,縮短訪問時間并允許對不同 banks 進行交錯和重疊訪問。對不同 banks 的訪問可以相互重疊,并且每個 bank 都有自己的行緩沖區(qū)。在 DRAM 中創(chuàng)建多個 banks 實際上可以將另一個段添加到該地址,該段現(xiàn)在由 banks 號、行地址和列地址組成。發(fā)送指定新 bank 的地址時,必須打開該 bank,這會導致額外的延遲。Banks 和行緩沖區(qū)的管理完全由現(xiàn)代內(nèi)存控制接口處理,因此,當后續(xù)訪問為打開的 banks 指定同一行時,訪問可以快速發(fā)生,僅發(fā)送列地址。
為了啟動新的訪問,DRAM 控制器發(fā)送一個 bank 和行號(在 SDRAM 中稱為激活,在以前稱為 RAS- 行選擇)。該命令將打開該行并將整個行讀入緩沖器。然后可以發(fā)送列地址,并且 SDRAM 可以傳輸一個或多個數(shù)據(jù)項,具體取決于它是單項請求還是突發(fā)請求。在訪問新行之前,必須對 bank 進行預充電。如果該行位于同一 bank 中,則可以看到預充電延遲;但是,如果該行在另一個 bank 中,則關(guān)閉該行并進行預充電可能會與訪問新行重疊。在同步 DRAM 中,每個命令周期都需要整數(shù)個時鐘周期。
從 1980 年到 1995 年,DRAM 按照摩爾定律進行擴展,每 18 個月將容量增加一倍(或 3 年內(nèi)增加 4 倍)。從 1990 年代中期到 2010 年,容量增長速度變慢,兩次增長之間的間隔時間約為 26 個月。從 2010 年到 2016 年,容量僅增加了一倍!下表顯示了各種 DDR SDRAM 的容量和訪問時間。從 DDR1 到 DDR3,訪問時間縮短了約 3 倍,或每年約 7%。DDR4 相比 DDR3 改善了功耗和帶寬,但是具有類似的訪問延遲。
如上表所示,DDR 是一系列標準。DDR2 通過將電壓從 2.5V 降至 1.8V 來降低 DDR1 的功耗,并提供更高的時鐘速率:266、333 和 400 MHz。DDR3 將電壓降至 1.5 V,最大時鐘速度為 800MHz。DDR4 于 2016 年初批量供貨,但預計在 2014 年將其電壓降至 1–1.2 V,最大預期的時鐘頻率為 1600 MHz。DDR5 不太可能在 2020 年或更晚之前達到量產(chǎn)。
隨著 DDR 的引入,內(nèi)存設計人員越來越關(guān)注帶寬,因為很難縮短訪問時間。較寬的 DRAM、突發(fā)傳輸和雙倍數(shù)據(jù)速率均導致內(nèi)存帶寬快速增加。DRAM 通常在稱為雙列直插式內(nèi)存模塊(DIMM)的小板上出售,該模塊包含 4~16 個 DRAM 芯片,通常將其組織為 8 字節(jié)寬(+ ECC),用于臺式機和服務器系統(tǒng)。將 DDR SDRAM 封裝為 DIMM 時,它們的峰值 DIMM 帶寬會令人困惑。因此,DIMM 名稱 PC3200 來自 200 MHz×2×8 個字節(jié),即 3200 MiB / s。為避免混淆,芯片本身被標記為每秒位數(shù)而不是時鐘速率,因此 200 MHz DDR 芯片稱為 DDR400。下表顯示了 I / O 時鐘速率、每芯片每秒的傳輸次數(shù)、芯片帶寬、芯片名稱、DIMM 帶寬和 DIMM 名稱之間的關(guān)系。
減少 SDRAM 內(nèi)的功耗
動態(tài)存儲芯片的功耗包括讀寫中使用的動態(tài)功耗和靜態(tài)或待機功耗。兩者都取決于工作電壓。在最先進的 DDR4 SDRAM 中,工作電壓已降至 1.2 V,與 DDR2 和 DDR3 SDRAM 相比,功耗大大降低。存儲體的增加還降低了功耗,因為僅讀取單個存儲體中的行。
除了這些更改之外,所有最新的 SDRAM 都支持掉電模式,通過告訴 DRAM 忽略時鐘來進入該模式。掉電模式會禁用 SDRAM,內(nèi)部自動刷新除外。
圖形數(shù)據(jù) RAM
GDRAM 或 GSDRAM(Graphics orGraphics Synchronous DRAMs)是基于 SDRAM 設計的一類特殊的 DRAM,為處理圖形處理單元的更高帶寬需求而量身定制。GDDR5 基于 DDR3,早期的 GDDRs 基于 DDR2。由于圖形處理器單元(GPU)的每個 DRAM 芯片比 CPU 需要更多的帶寬,因此 GDDR 具有幾個重要的區(qū)別:
1. GDDR 具有更寬的接口:32 位。
2. GDDR 在數(shù)據(jù)引腳上具有更高的最大時鐘速率。為了允許更高的傳輸速率而不會引起信號問題,與通常以可擴展的 DIMM 陣列排列的 DRAM 不同,GDRAM 通常直接連接到 GPU 并通過將它們焊接到板上而連接。
總的來說,這些特性使 GDDR 的運行帶寬是 DDR3 DRAM 的 2 至 5 倍。
封裝創(chuàng)新:堆疊或嵌入式 DRAM
2017 年 DRAM 中的最新創(chuàng)新是封裝創(chuàng)新,而不是電路創(chuàng)新。它將多個 DRAM 以堆疊或相鄰的方式放置在與處理器相同的封裝中。(嵌入式 DRAM 也用于指將 DRAM 放置在處理器芯片上的設計)。將 DRAM 和處理器放置在同一封裝中可降低訪問延遲(通過縮短 DRAM 和處理器之間的延遲),并可能通過允許更多連接來增加帶寬。處理器與 DRAM 之間的連接速度更快,因此一些生產(chǎn)商將其稱為高帶寬內(nèi)存(High BandwidthMemory,HBM)。
該技術(shù)的一種版本是使用焊點技術(shù)將 DRAM Die 直接放置在 CPU Die 上。假設有足夠的熱量管理,則可以以這種方式堆疊多個 DRAM。另一種方法是僅堆疊 DRAM,并使用包含連接的基板(中介層)將它們與 CPU 放在單個封裝中。已經(jīng)證明了可以堆疊多達 8 個芯片的 HBM 原型。對于特殊版本的 SDRAM,這種封裝可以包含 8 GiB 內(nèi)存,數(shù)據(jù)傳輸速率為 1 TB / s。2.5D 技術(shù)目前可用。因為必須專門制造芯片以堆疊,所以大多數(shù)早期使用很有可能會用在高端服務器芯片組中。
在某些應用程序中,可能會在內(nèi)部封裝足夠的 DRAM 以滿足應用程序的需求。例如,NvidiaGPU 正在使用 HBM 開發(fā)用作專用集群設計中的節(jié)點,并且 HBM 可能會成為高端應用的 GDDR5 的后繼產(chǎn)品。在某些情況下,可能會使用 HBM 作為主存儲器,盡管目前的成本限制和散熱問題使該技術(shù)無法用于某些嵌入式應用程序。
Flash 存儲器
Flash 是一種 EEPROM(電子可擦除可編程只讀存儲器),通常是只讀的,但可以擦除。Flash 的另一個關(guān)鍵特性是無需任何電源即可保存其內(nèi)容。我們專注于 NAND Flash,它比 NOR Flash 具有更高的密度,并且更適合于大型非易失性存儲器。缺點是訪問是順序的,并且寫入速度較慢,如下所述。
Flash 用作 PMD 中的輔助存儲,其方式與筆記本電腦或服務器中磁盤的功能相同。此外,由于大多數(shù) PMD 的 DRAM 數(shù)量有限,因此 Flash 還可以充當內(nèi)存層次結(jié)構(gòu)的一級。
Flash 使用的架構(gòu)與標準 DRAM 完全不同,并且具有不同的屬性。最重要的區(qū)別是:
1. 對 Flash 的讀取是連續(xù)的,并且是讀取整個頁面,該頁面可以是 512 字節(jié)、2 KiB 或 4 KiB。因此,NAND Flash 在從隨機地址訪問第一個字節(jié)時會有較長的延遲(約 25us),但是可以以約 40 MiB / s 的速度訪問頁面塊的其余部分。相比之下,DDR4 SDRAM 到第一個字節(jié)大約需要 40 ns 的時間,并且可以 4.8 GiB / s 的速度傳輸其余行。比較傳輸 2 KiB 內(nèi)容的時間,NAND 閃存大約需要 75μS,而 DDR SDRAM 則需要不到 500 ns,這使 Flash 慢了大約 150 倍。但是,與磁盤相比,從 Flash 讀取 2 KiB 的速度要快 300 到 500 倍。從這些數(shù)字中我們可以看到為什么閃存不是替代 DRAM 替代主存儲器的候選者,而是替代磁盤的候選者。
2. 在重寫覆蓋 Flash 之前,必須先對其擦除,然后按塊而不是單個字節(jié)或字進行擦除。此要求意味著,當必須將數(shù)據(jù)寫入 Flash 時,必須將整個塊組裝為新數(shù)據(jù),或者將要寫入的數(shù)據(jù)與塊的其余內(nèi)容合并。對于寫操作,F(xiàn)lash 的速度比 SDRAM 慢 1500 倍,是磁盤的 8 到 15 倍。
3. Flash 是非易失性的(即使不加電,它也會保留其內(nèi)容),并且在不進行讀寫時消耗的功率要少得多。
4. Flash 限制了任何給定塊的寫入次數(shù),通常至少為 100000。通過確保寫入塊在整個存儲器中的均勻分布,系統(tǒng)可以使 Flash 系統(tǒng)的壽命最大化。這種技術(shù)稱為寫均衡,由 Flash 控制器處理。
5. 高密度 NAND Flash 比 SDRAM 便宜,但比磁盤貴:Flash 大約為 2 美元 / GiB,SDRAM 為 20 美元至 40 美元 / GiB,磁盤為 0.09 美元 / GiB。在過去的五年中,F(xiàn)lash 的成本降低速度幾乎是磁盤的兩倍。
相變存儲技術(shù)(Phase-Change MemoryTechnology,PCM)
相變存儲器(PCM)幾十年來一直是活躍的研究領域。該技術(shù)通常使用一個小的加熱元件來改變塊狀襯底在其具有不同電阻特性的晶體形式和非晶形式之間的狀態(tài)。每一位對應于覆蓋襯底的二維網(wǎng)絡中的交叉點。通過感測 x 點和 y 點之間的電阻(因此稱為憶阻器)來完成讀取,通過施加電流來改變材料的相位來完成寫入。與 NAND Flash 相比,缺少有源器件(如晶體管),可降低成本并提高密度。
2017 年,美光和英特爾開始提供 Xpoint 存儲芯片,該芯片被認為是基于 PCM。預計該技術(shù)將比 NAND Flash 具有更好的寫入耐久性,并且由于消除了在寫入之前擦除頁面的需要,因此與 NANDFlash 相比的寫入性能提高了十倍。讀取延遲也比 Flash 好 2 到 3 倍。最初,它的價格預計會略高于 Flash,但是寫入性能和寫入耐久性方面的優(yōu)勢可能使其具有吸引力,尤其是對于 SSD。如果這項技術(shù)可以很好地擴展并且能夠?qū)崿F(xiàn)進一步的成本降低,那么固態(tài)磁盤技術(shù)將取代磁盤,磁盤已成為主流的非易失性主要存儲設備,已經(jīng)使用了 50 多年。
提高存儲器系統(tǒng)的可靠性
大型 Cache 和主存儲器顯著增加了在制造過程中以及在操作過程中動態(tài)發(fā)生錯誤的可能性。由電路變化引起且可重復的錯誤稱為硬錯誤或永久性故障。硬錯誤可能在制造期間發(fā)生,也可能在操作期間發(fā)生電路變化(例如,多次寫入后 Flash 單元發(fā)生故障)。所有 DRAM、Flash 和大多數(shù) SRAM 都制造有備用行,因此可以通過編程用備用行替換有缺陷的行來容納少量的制造缺陷。動態(tài)錯誤是對單元內(nèi)容的更改,而不是電路的更改,稱為軟錯誤或瞬態(tài)故障。
動態(tài)錯誤可以通過奇偶校驗位進行檢測,并可以通過使用糾錯碼(ECC)進行檢測和修復。因為指令高速 Cache 是只讀的,所以奇偶校驗就足夠了。在較大的數(shù)據(jù)高速 Cache 和主存儲器中,ECC 用于檢測和糾正錯誤。奇偶校驗僅需要開銷的一小部分就可以檢測到一系列位中的單個錯誤。由于奇偶校驗不會檢測到多位錯誤,因此必須限制由奇偶校驗位保護的位數(shù)。每 8 個數(shù)據(jù)位一個奇偶校驗位是一種典型的比率。ECC 可以檢測兩個錯誤并糾正單個錯誤,每 64 個數(shù)據(jù)位的開銷為 8 位。
在非常大的系統(tǒng)中,多個錯誤以及單個存儲芯片完全故障的可能性變得十分明顯。為了解決此問題,IBM 引入了 Chipkill,許多大型系統(tǒng)(例如 IBM 和 SUN 服務器以及 Google 集群)都使用了這項技術(shù)。Chipkill 本質(zhì)上與磁盤使用的 RAID 方法類似,其分散數(shù)據(jù)和 ECC 信息,在單個存儲器芯片完全失效時,可以從其余存儲器芯片中重構(gòu)丟失數(shù)據(jù)。根據(jù) IBM 的分析,假設有 10000 個的服務器(每個處理器 4 GiB 存儲器),在三年的運行中產(chǎn)生無法恢復的錯誤數(shù)目如下所示:
僅奇偶校驗:大約 90000 個,或者說每 17 分鐘發(fā)生一次不可恢復的(或無法檢測到的)故障。
僅適用于 ECC:大約 3500 個,或者說每 7.5 小時大約有一個未檢測到或無法恢復的故障。
Chipkill:每 2 個月大約發(fā)生一次未被發(fā)現(xiàn)或無法恢復的故障。
解決此問題的另一種方法是在錯誤率與 Chipkill 相同的情況下找到可以保護的最大服務器數(shù)量(每個服務器具有 4 GiB 存儲器)。采用奇偶校驗,即使是只有一個處理器的服務器,其不可恢復的錯誤率也將高于具有 10000 個服務器的、受 Chipkill 保護的系統(tǒng)。對于 ECC,具有 17 個服務器的系統(tǒng)的故障率將與具有 10000 個服務器、受 Chipkill 保護的系統(tǒng)的故障率大致相同。因此,對于倉庫級計算機,其具有 50000~10000 個服務器,需要 Chipkill 技術(shù)來保護。
審核編輯黃昊宇
-
芯片
+關(guān)注
關(guān)注
456文章
51062瀏覽量
425808 -
存儲
+關(guān)注
關(guān)注
13文章
4341瀏覽量
86030
發(fā)布評論請先 登錄
相關(guān)推薦
內(nèi)存儲器分為隨機存儲器和什么
存儲器中訪問速度最快的是什么
計算機存儲系統(tǒng)的構(gòu)成
存儲器芯片的內(nèi)部結(jié)構(gòu)及其引腳類型
高速緩沖存儲器與內(nèi)存的區(qū)別
內(nèi)部存儲器有哪些
計算機存儲器的分類及其區(qū)別
存儲器在微型計算機系統(tǒng)中的作用
DRAM在計算機中的應用
虛擬存儲器的概念和特征
存儲器的工作原理及基本結(jié)構(gòu)
存儲器的定義和分類
淺析RAM存儲器內(nèi)部結(jié)構(gòu)圖
ram內(nèi)部存儲器電路組成
智能化的計算機體系結(jié)構(gòu)設計方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論