 用 “心跳”識別假視頻,準確率高達 97%
用 “心跳”識別假視頻,準確率高達 97%
Deepfake 真是讓人又愛又恨。
眾所周知,基于深度學習模型的 Deepfake 軟件,可以制造虛假的人臉視頻或圖像。它在影視、娛樂等行業有著廣泛的應用場景。
但自 2017 年起,Deepfake 也開始被不良分子用來制造色情視頻——神奇女俠下海事件。據統計,社交網絡中的 Deepfake 視頻,96% 涉及色情內容,觀看用戶數量已超過了 1.3 億。
此外,Deepfake 也開始涉足政治領域,被用來偽造虛假政客言論,相關數據也在逐年增長。
奧巴馬發表著與自己不相關的言論
更重要的是,隨著 Deepfake 技術的不斷升級,這些偽造視頻越來越難以分辨真假,對社會穩定構成了極大的威脅。
而近日,一篇刊登在 IEEE PAMI(模式分析與機器智能匯刊)的一篇論文聲稱,有新的方法能夠識別 Deepfake 視頻,準確率高達 97.29%,而且還能夠發現制造 Deepfake 背后的生成模型。
更有意思的是,不同于常規檢測法,該論文強調其利用的是生物信號——心跳。
Deepfake“心跳”檢測法
這篇論文來自賓厄姆頓大學(Binghamton University)與英特爾(Intel)公司聯合組成的研究團隊。該團隊稱,這款 AI 工具名為 FakeCatcher,它可以通過檢測心跳在面部產生的細微差別來區分視頻真假。
我們知道,血管遍布人體全身,包括面部。當心臟跳動時會帶動全身的血液流動,流動的血液會在人臉表面產生細微的變化,而這種變化正是研究人員區分真假視頻的關鍵。
研究人員把區分這種變化的方法稱為光體積變化描計法(Photoplethysmography,簡稱 PPG)。簡單來說,就是利用光率的脈動變化,折算成電信號,從而對應成心率。
這一原理與醫學脈搏血氧儀,蘋果手表以及可穿戴健身跟蹤設備檢測運動狀態時的心跳信號類似。
該項研究的前提假設是:生物信號是區分真假人臉的重要標識。也就是說,假視頻中顯示的 “人”不會表現出與真實視頻中的人相似的心跳模式。
基于此,研究人員經過實驗發現,Deepfake 人臉無法正常還原因血液流動造成的微弱變化。
英特爾公司的資深研究科學家伊爾克 · 德米爾(Ilke Demir)介紹稱,
我們從臉部的不同部位提取幾個 PPG 信號,并觀察了這些信號在空間維度和時間維度上的一致性。
在這里空間維度指的是面部區域,時間維度指的是心跳頻率。Demir 的意思是,通過讀取 PPG 信號和增強技術,還原并放大其在面部所產生的微弱變化,以此判斷視頻的真假。
如果是 Deepfake 視頻,所產生的面部效果會非常不自然。如下圖:
具體來說,FakeCatcher 完整的檢測過程如下:1)識別關鍵的人臉區域;2)提取生物信號(PPG);3)利用信號轉換計算空間維度和時間維度的相關性,并在特征集和 PPG 映射中捕獲信號特征并訓練概率;4)根據真實性概率對視頻真假進行分類。
研究人員介紹稱,在這一過程中主要取得三個方面的進步:
通過信號轉換公式和實驗,驗證了利用生物信號的空間一致性和時間一致性檢驗視頻真假的可行性。
提出了一種新型通用的 Deepfake 檢測器。
提出了一種新的生物信號構造圖,可用于訓練神經網絡進行真實性分類。
構建了一個多樣化的人像視頻數據集,為虛假內容檢測提供了一個試驗臺。
模型精度測試結果在實驗之前,為了更加精準地評估 FakeCatcher 模型,研究人員自建一個 Deepfake 數據集,該數據集來自媒體網絡、新聞文章和研究報告等,因此,視頻在生成模型、分辨率、壓縮、照明、縱橫比、幀速率、運動、姿勢、遮擋、內容等方面的問題都是真實存在的。
該數據集包含了 142 個視頻,有 30 GB 大小。從下圖分類結果來看,FakeCatcher 對低分辨率、壓縮、運動、照明、遮擋等問題的表現都是魯棒性的。
上半部分為真實視頻,下半部分為 Deepfake 視頻
接下來,研究人員主要進行了兩項實驗驗證。一是與當前的深度學習解決方案和其他 Deepfake 檢測器進行比較。實驗結果如下:
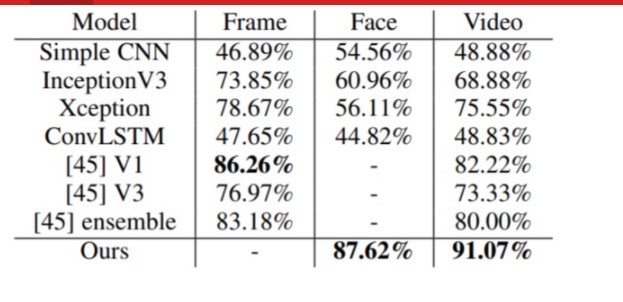
其中,Frame 和 Face 表示分段精度,可以看出 FakeCatcher 最高,達到了 87.62%;Video 表示視頻精確度。FakeCatcher 比最好的架構還要高出 8.85%。
需要說明的是,表中所有實驗都是在自建數據集 DF(60% 訓練和 40% 的測試的分割)中進行的。
二是進行交叉數據集驗證,分別包括 DF、Celeb DF、FF、FF++ 和 UADFV 數據集。
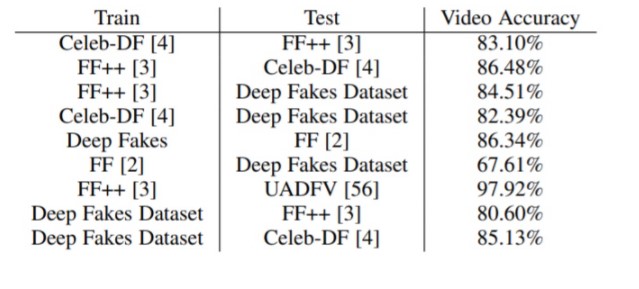
第一列為訓練數據集,第二列為測試數據集
從第 5 行和第 6 行來看,FakeCatcher 在小而多樣的數據集中的學習效果要比在大型且單一的數據集上更好。一方面是,DF 訓練和 FF 測試比反過來的測試精度高出了 18.73%。另一方面是,DF 數據集大約只有 FF 數據集的 5%。從第 3 行和第 6 行來看,可以發現從 FF 到 FF++ 增加分集,DF 的準確率提高了 16.9%。
在交叉數據集 FF++ 中,每個原始視頻包含四個合成視頻,其中每個視頻都使用不同的生成模型生成。研究人員將 FF++ 的原始視頻分割為 60% 訓練,40% 測試。然后創建這些集合的四個副本,并從每個集合中刪除特定模型生成的所有樣本。
表中第 1 列,每個集合包含三個模型的 600 個真實視頻和 1800 個假視頻,以及一個模型的 400 個真實視頻和 400 個假視頻進行測試。
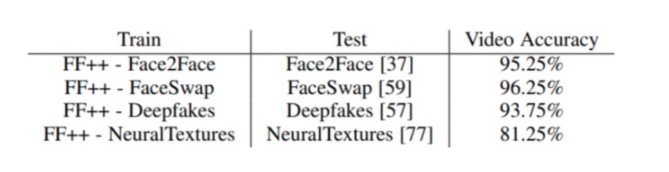
從跨模型評估結果來看,除了 NeuralTextures,其他均得到了非常精確的預測。而 NeuralTextures 本質上就是不同的生成模型。
由此,論文最后得出結論稱,基于生物信號的 Deepfake 視頻檢測器 FakeCatcher,證明了生物信號的空間維度和時間維度的一致性在 GAN-Rated 內容中并沒有得到很好的保持。
此外,通過人臉取證實驗并引入自建 DF 數據集中,對視頻片段、視頻的成對分離以及真實性分類方法進行評估,分別得到了 99.39%,96% 以及 91.07% 準確率。這些結果再次驗證了 FakeCatcher 可以高精度地檢測假內容,而不依賴視頻的生成器、內容、分辨率以及質量等指標。
責任編輯:PSY
-
視頻
+關注
關注
6文章
1949瀏覽量
72969 -
識別
+關注
關注
3文章
173瀏覽量
31978 -
心跳識別
+關注
關注
0文章
2瀏覽量
1752
發布評論請先 登錄
相關推薦
如何提升人臉門禁一體機的識別準確率?

高效安全的指紋頭,智能識別技術引領未來

微機保護裝置預警功能的準確率
隧道門禁人臉識別系統是專為隧道安全管理設計的先進技術系統

ai人工智能回答準確率高嗎
NIUSB6009 采集準確率的問題?

NRK3301識別語音芯片在智能按摩椅中的應用與體驗提升

什么是離線語音識別芯片?與在線語音識別的區別
人員跌倒識別檢測算法






 工商網監
工商網監
評論