 wordNet詞向量和詞義
wordNet詞向量和詞義
review: Word2vec: More details
How do we have usable meaning in a computer?

wordNet的問題:?
1. 詞語跟詞語之間存在一定的語境差別 2. 有些單詞的新含義缺少 3. 需要主觀調整 4. 無法計算單詞相似度 word2vec
步驟:
1. 尋找大量的文本 2. 固定詞匯表中的每個單詞都有一個向量表示 3. 文本中的每一個位置t,均存在中心詞c和上下詞o 4. 使用c和o的詞向量相似性來計算給定c和o的概率 5.不斷調整詞向量來最大化這個概率
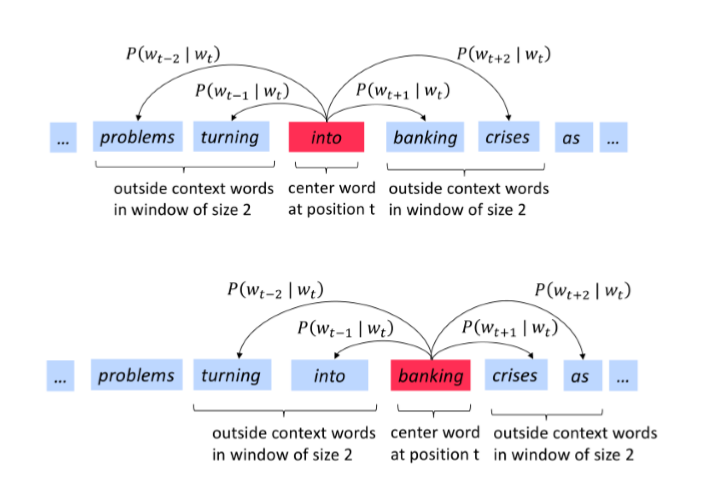
word2vec的一些參數:
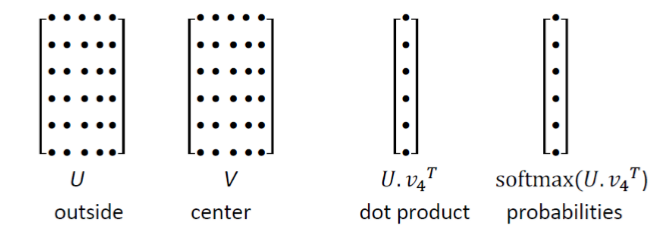
1. U的每一行都是一個單詞的詞向量,點乘之后通過softmax可以得到概率分布,從而得到上下文分布。但是該分布和你在上下文哪個位置是無關的, 2. We want a model that gives a reasonably high probability estimate to all words that occur in the context (fairly often)----我們希望給出一個合理的高概率估計 3. 去除一些停用詞 更細的細節
為什么每個單詞都需要訓練兩個詞向量
1. 更容易優化,最后都取平均值 2. 可以每個單詞只??個向量
兩個模型變體
1. Skip-grams (SG)輸?中?詞并預測上下?中的單詞 2. Continuous Bag of Words (CBOW)輸?上下?中的單詞并預測中?詞 之前?直使?softmax(簡單但代價很?的訓練?法)
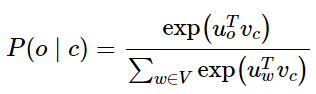
接下來使?負采樣?法加快訓練速率 The skip-gram model with negative sampling (HW2)
原始的論文中skip-gram模型是最大化的,這里給出:
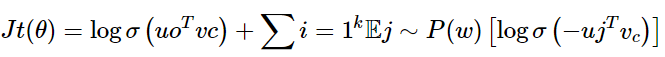
課程中的公式:
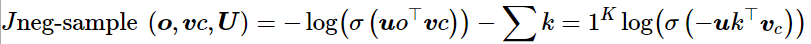
我們希望中?詞與真實上下?單詞的向量點積更?,中?詞與隨機單詞的點積更?
k是我們負采樣的樣本數?
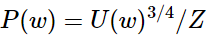
這里的0.75次方是選擇的比較好的,沒有科學依據
But why not capture co-occurrence counts directly?共現矩陣
共現矩陣 X
1. 兩個方法:windows vs. full document 2. Window :與word2vec類似,在每個單詞周圍都使?Window,包括語法(POS)和語義信息 3. Word-document 共現矩陣的基本假設是在同?篇?章中出現的單詞更有可能相互關聯。假設單詞i出現在?章 中j,則矩陣元素$X_{ij}$加?,當我們處理完數據庫中的所有?章后,就得到了矩陣 X,其??為 |V|*M,其中|V|為詞匯量,而M為文章數,這?構建單詞?章co-occurrencematrix的?法也是經典的Latent Semantic Analysis所采?的。{>>潛在語義分析<<} ?
利?某個定?窗?中單詞與單詞同時出現的次數來產?window-based (word-word) co-occurrence matrix
let me to tell you a example: 句子
1. I like deep learning. 2. I like NLP. 3. I enjoy flying. 則我們可以得到如下的word-word co-occurrence matrix:
使?共現次數衡量單詞的相似性,但是會隨著詞匯量的增加?增?矩陣的??,并且需要很多空間來存儲這??維矩陣,后續的分類模型也會由于矩陣的稀疏性?存在稀疏性問題,使得效果不佳。我們需要 對這?矩陣進?降維,獲得低維(25-1000)的稠密向量 how to reduce the dimensionality?
方法一: SVD分解
方法二: Ramped windows that count closer words more----將window傾斜向能統計更接近的單詞中
方法三: 采用person相關系數
glove
兩種方法:
1. 基于計數:使?整個矩陣的全局統計數據來直接估計:
優點
1. 訓練快速 2. 統計數據?效利?
缺點
1. 主要?于捕捉單詞相似性 2. 對?量數據給予?例失調的重視 2. 轉換計數:定義概率分布并試圖預測單詞
優點
1. 提?其他任務的性能 2. 能捕獲除了單詞相似性以外的復雜的模式
缺點
1. 與語料庫??有關的量表 2. 統計數據的低效使?(采樣是對統計數據的低效使?) Encoding meaning in vector differences
采用共現矩陣的思想對meaning進行編碼
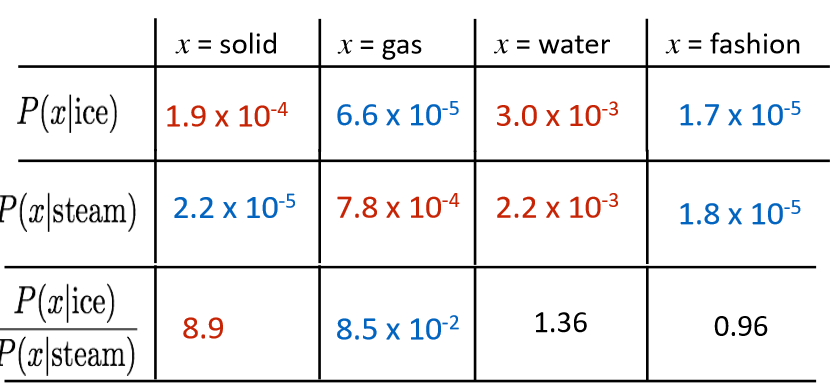
為什么采用比值有用?這里摘抄至網上: 假如我們想區分ice(固體)和stream(蒸汽),它們之間的關系可通過與不同單詞x的共線矩陣相似性比值來秒速,比如p(solid | ice)和p(solid | stream)相比,雖然它們之間的值都很小,不能透露有效消息,但是它們的比值卻很大,所以相比之下,solid更常見的用來表示ice而不是stream
我們如何評判在線性表達下的共現矩陣相似度
1. log-bilinear 模型:
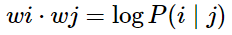
2. 向量差異:
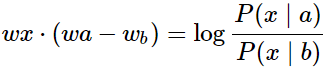
公式推導部分來啦,非常非常重要的目標函數優化 基于對于以上概率比值的觀察,我們假設模型的函數有如下形式:
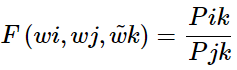
其中,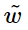 代表了context vector, 如上例中的solid, gas, water, fashion等。
代表了context vector, 如上例中的solid, gas, water, fashion等。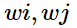 則是我們要比較的兩個詞匯, 如上例中的ice,steam。 ? F的可選的形式過多,我們希望有所限定。首先我們希望的是F能有效的在單詞向量空間內表示概率比值,由于向顯空問是線性率間,一個自然的假設是 F 是關于同顯 的差的形式:
則是我們要比較的兩個詞匯, 如上例中的ice,steam。 ? F的可選的形式過多,我們希望有所限定。首先我們希望的是F能有效的在單詞向量空間內表示概率比值,由于向顯空問是線性率間,一個自然的假設是 F 是關于同顯 的差的形式:
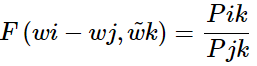
或:
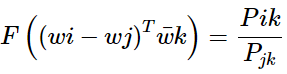
在此,作者又對其進行了對稱性分析,即對于word-word co-occurrence,將向量劃分為center word還是context word的選擇是不重要的,即我們在交換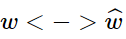 與
與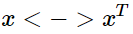 的時候該式仍然成立。如何保證這種對稱性呢? ? ? 我們分兩步來進行, 首先要求滿足
的時候該式仍然成立。如何保證這種對稱性呢? ? ? 我們分兩步來進行, 首先要求滿足
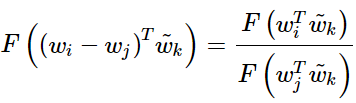
該方程的解為 F=exp(參考上面的評價方法)同時與
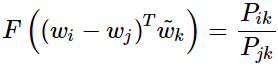
相比較有
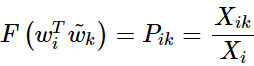
所以,
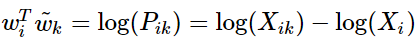
注意其中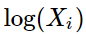 破壞了交換
破壞了交換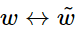 與
與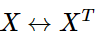 時的對稱性, 但是這一項并不依賴于 k?所以我們可以將其融合進關于
時的對稱性, 但是這一項并不依賴于 k?所以我們可以將其融合進關于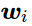 的bias項
的bias項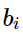 第二部就是為了平衡對稱性, 我們再加入關于
第二部就是為了平衡對稱性, 我們再加入關于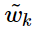 的bias項
的bias項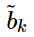 我們就可以得到
我們就可以得到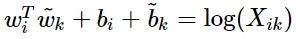 的形式。另一方面作者注宣到模型的一個缺點是對于所有的co-occurence的權重是一樣的,即使是那些較少發 生的co-occurrence。作者認為這些可能是噪聲聲,所以他加入了前面的
的形式。另一方面作者注宣到模型的一個缺點是對于所有的co-occurence的權重是一樣的,即使是那些較少發 生的co-occurrence。作者認為這些可能是噪聲聲,所以他加入了前面的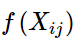 項來做weighted least squares regression模型,即為
項來做weighted least squares regression模型,即為
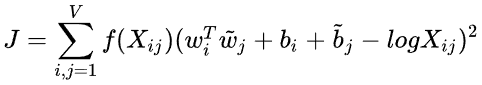
的形式。 其中權重項 f 需滿足一下條件:
f(0)=0,因為要求 是有限的。 
較少發生的co-occurrence所占比重較小。
對于較多發生的co-occurrence, f(x)也不能過大。
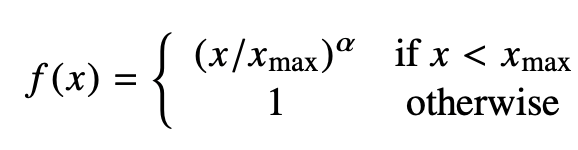
優點
訓練快速
可以擴展到?型語料庫
即使是?語料庫和?向量,性能也很好
How to evaluate word vectors?
與NLP的?般評估相關:內在與外在
內在
對特定/中間?任務進?評估
計算速度快
有助于理解這個系統
不清楚是否真的有?,除?與實際任務建?了相關性
外在
對真實任務的評估
計算精確度可能需要很?時間
不清楚?系統是問題所在,是交互問題,還是其他?系統
如果?另?個?系統替換?個?系統可以提?精確度
Intrinsic word vector evaluation
詞向量類?a:b = c:?,類似于之前的男人對國王,求女人對?
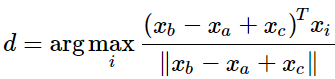
英文解釋: This metric has an intuitive interpretation. Ideally, we want xb?xa = xd ?xc (For instance, queen – king = actress – actor). This implies that we want xb?xa + xc = xd. Thus we identify the vector xd which maximizes the normalized dot-product between the two word vectors (i.e. cosine similarity).
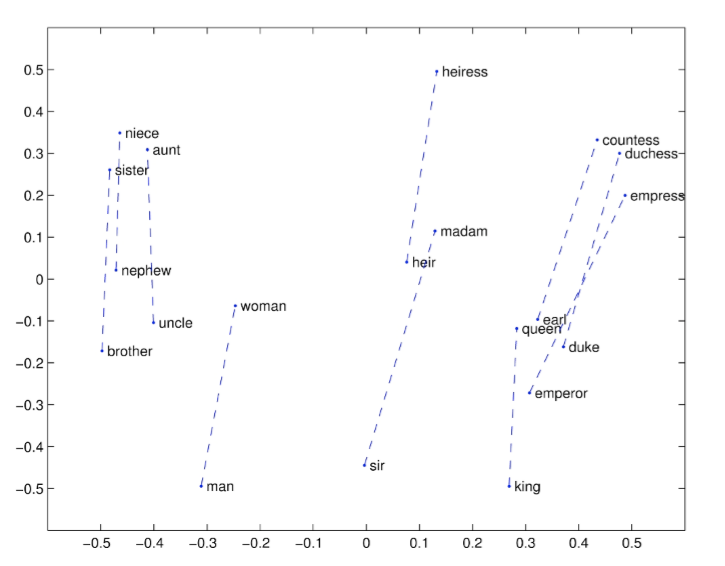
一些結果舉例子:
結論
1. 300是?個很好的詞向量維度 2. 不對稱上下?(只使?單側的單詞)不是很好,但是這在下游任務重可能不同 3. window size 設為 8 對 Glove向量來說?較好 4. window size設為2的時候實際上有效的,并且對于句法分析是更好的,因為句法效果?常局部 5. 當詞向量的維度不斷變大的時候,詞向量的效果不會一直變差,并且會保持平穩 6. glove的訓練時間越長越好 7. 數據集越大越好,盡量使用百科類數據集合 8. 使用余弦相似度 Another intrinsic word vector evaluation
the problem:Most words have lots of meanings!(一詞多義問題)? Especially common words ? Especially words that have existed for a long time
method1: Improving Word Representations Via Global Context And Multiple Word Prototypes (Huang et al. 2012) -------將常?詞的所有上下?進?聚類,通過該詞得到?些清晰的簇,從?將這個常?詞分解為多個單詞,例如 bank_1, bank_2, bank_3

method2: Linear Algebraic Structure of Word Senses, with Applications to Polysemy (Arora, …, Ma, …, TACL 2018)
Different senses of a word reside in a linear superposition (weighted sum) in standard word embeddings like word2vec -----------采用加權和的形式進行處理
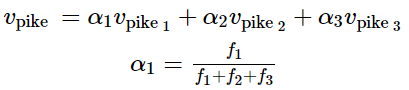
令人驚訝的是,這個加權均值的效果非常好
Training for extrinsic tasks
到目前我們學的為止,我們的目標是內在任務,強調開發一個特別優秀的word embedding。接下來我們討論如何處理外部任務
Problem Formulation
Most NLP extrinsic tasks can be formulated as classi?cation tasks. For instance, given a sentence, we can classify the sentence to have positive, negative or neutral sentiment. Similarly, in named-entity recognition (NER), given a context and a central word, we want to classify the central word to be one of many classes. ------許多nlp的task都可以歸類為分類任務
for example:我們有一個句子: Jim bought 300 shares of Acme Corp. in 2006,我們的目標是得到一個結果:[Jim]Person bought 300 shares of [Acme Corp.]Organization in [2006]Time.
對于這類問題,我們通常從以下形式的訓練集合開始:
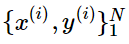
其中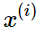 是一個d維度的詞向量,
是一個d維度的詞向量,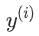 是一個C維度的one-hot向量,表示我們wished label(情感詞語,其他詞語,命名主體詞語,買賣決策,等) ? 在機器學習里面,對于上面問題,我們通常固定輸入和輸出的形式,然后采用一些優化算法訓練權重。但在nlp里面,我們需要在訓練外部任務的時候,對輸入的詞向量進行再次訓練 ?Retraining Word Vectors?
是一個C維度的one-hot向量,表示我們wished label(情感詞語,其他詞語,命名主體詞語,買賣決策,等) ? 在機器學習里面,對于上面問題,我們通常固定輸入和輸出的形式,然后采用一些優化算法訓練權重。但在nlp里面,我們需要在訓練外部任務的時候,對輸入的詞向量進行再次訓練 ?Retraining Word Vectors?
我們預訓練的詞向量在外部評估中的表現仍然有提高的可能,然而,如果我們選擇重新訓練,我們會存在很大的風險------可能效果會比之前差得多
If we retrain word vectors using the extrinsic task, we need to ensure that the training set is large enough to cover most words from the vocabulary. -----因為word2vec和glove會產生一些語義接近的單詞,并且這些單詞位于同一個單詞空間。如果我們在一個小的數據集上預訓練,這些單詞可能在向量空間中移動,這會導致我們的結果更差
舉例子: 這兩個例子可以清楚明白的看到,訓練集合如果過于小,我們的分類結果非常差
結論:如果訓練數據集合太小,就不應該對單詞向量進行再訓練。如果培訓集很大,再培訓可以提高性能Softmax Classi?cation and Regularization
softmax的訓練
1. 函數形式:
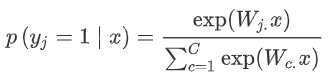
2. 上個式子,是我們計算x是j的概率,我們采用交叉熵損失函數:
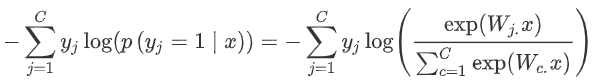
3. 對上面損失函數優化,因為我們$y_j$為1,其他類別就是0,也就是說,對于單個詞語我們的損失函數簡化為:
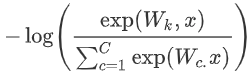
4. 上式損失函數只是一個單詞的,但是我們需要使用的訓練集不止一個dancing,假設我們有N個單詞,將損失函數擴展:
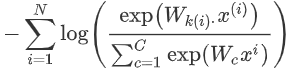
5. 為了防止過擬合,我們需要加入一個懲罰項:
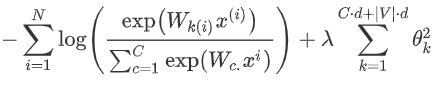
為什么懲罰項的參數是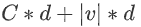 ? ? 我們需要同時訓練模型的權值w和詞向量x。對于權值來將,我們需要一個d維度向量的輸入和一個C維度向量輸出,所以是C*d;對于詞向量來說,我們詞匯表有v個詞匯,每個詞匯的維度是d維,所以是|v|*d ? ????6. 如果我們調整好 λ 這個超參數的值,這會降低損失函數出現很大值的參數的可能性因為懲罰項的存在,同時,這個也能提高模型的泛化能力 ?Window Classi?cation
? ? 我們需要同時訓練模型的權值w和詞向量x。對于權值來將,我們需要一個d維度向量的輸入和一個C維度向量輸出,所以是C*d;對于詞向量來說,我們詞匯表有v個詞匯,每個詞匯的維度是d維,所以是|v|*d ? ????6. 如果我們調整好 λ 這個超參數的值,這會降低損失函數出現很大值的參數的可能性因為懲罰項的存在,同時,這個也能提高模型的泛化能力 ?Window Classi?cation
我們通常的輸入不是一個單詞

更多的情況,我們模型的輸入是一個單詞序列(取決于你的問題的情況,確認窗口的大小),一般來講,較窄的窗口會在句法測試中會存在更好的性能,而更寬的窗口在語義測試中表現更好
敲公式敲累了,偷個懶,這里就是在softmax里面我們擴展到你窗口大小就行
本文推薦閱讀論文:
Improving Distributional Similarity with Lessons Learned from Word Embeddings
Evaluation methods for unsupervised word embeddings
責任編輯:xj
原文標題:【CS224N筆記】詞向量和詞義
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
向量
+關注
關注
0文章
55瀏覽量
11680 -
WordNet
+關注
關注
0文章
4瀏覽量
7496
原文標題:【CS224N筆記】詞向量和詞義
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

HLK-V20支持用戶修改喚醒詞和命令詞 海凌科語音定制后臺系統上線

nlp自然語言處理模型有哪些
大模型應用之路:從提示詞到通用人工智能(AGI)
【大語言模型:原理與工程實踐】大語言模型的基礎技術
搭載英偉達GPU,全球領先的向量數據庫公司Zilliz發布Milvus2.4向量數據庫
什么是中斷向量偏移,為什么要做中斷向量偏移?





 工商網監
工商網監
評論