 半監督學習最基礎的3個概念
半監督學習最基礎的3個概念
導讀
今天給大家介紹半監督學習中的3個最基礎的概念:一致性正則化,熵最小化和偽標簽,并介紹了兩個經典的半監督學習方法。
沒看一的點這里哈:半監督學習入門基礎(一)
半監督學習 (SSL) 是一種非常有趣的方法,用來解決機器學習中缺少標簽數據的問題。SSL利用未標記的數據和標記的數據集來學習任務。SSL的目標是得到比單獨使用標記數據訓練的監督學習模型更好的結果。這是關于半監督學習的系列文章的第2部分,詳細介紹了一些基本的SSL技術。
一致性正則化,熵最小化,偽標簽
SSL的流行方法是在訓練期間往典型的監督學習中添加一個新的損失項。通常使用三個概念來實現半監督學習,即一致性正則化、熵最小化和偽標簽。在進一步討論之前,讓我們先理解這些概念。
一致性正則化強制數據點的實際擾動不應顯著改變預測器的輸出。簡單地說,模型應該為輸入及其實際擾動變量給出一致的輸出。我們人類對于小的干擾是相當魯棒的。例如,給圖像添加小的噪聲(例如改變一些像素值)對我們來說是察覺不到的。機器學習模型也應該對這種擾動具有魯棒性。這通常通過最小化對原始輸入的預測與對該輸入的擾動版本的預測之間的差異來實現。
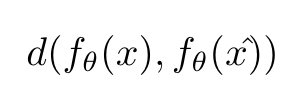
模型對輸入x及其擾動x^的一致性度量
d(.,.) 可以是均方誤差或KL散度或任何其他距離度量。
一致性正則化是利用未標記數據找到數據集所在的平滑流形的一種方法。這種方法的例子包括π模型、Temporal Ensembling,Mean Teacher,Virtual Adversarial Training等。
熵最小化鼓勵對未標記數據進行更有信心的預測,即預測應該具有低熵,而與ground truth無關(因為ground truth對于未標記數據是未知的)。讓我們從數學上理解下這個。
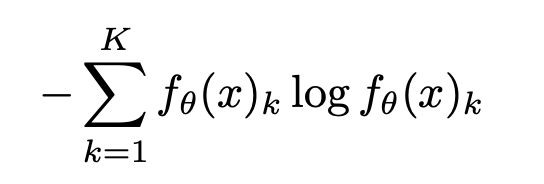
熵的計算
這里,K是類別的數量,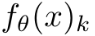 是模型對x預測是否屬于類別k的置信度。
是模型對x預測是否屬于類別k的置信度。
此外,輸入示例中所有類的置信度之和應該為1。這意味著,當某個類的預測值接近1,而其他所有類的預測值接近0時,熵將最小化。因此,這個目標鼓勵模型給出高可信度的預測。
理想情況下,熵的最小化將阻止決策邊界通過附近的數據點,否則它將被迫產生一個低可信的預測。請參閱下圖以更好地理解此概念。
由不同的半監督學習方法生成的決策邊界
偽標簽是實現半監督學習最簡單的方法。一個模型一開始在有標記的數據集上進行訓練,然后用來對沒有標記的數據進行預測。它從未標記的數據集中選擇那些具有高置信度(高于預定義的閾值)的樣本,并將其預測視為偽標簽。然后將這個偽標簽數據集添加到標記數據集,然后在擴展的標記數據集上再次訓練模型。這些步驟可以執行多次。這和自訓練很相關。
在現實中視覺和語言上擾動的例子
視覺:
翻轉,旋轉,裁剪,鏡像等是圖像常用的擾動。
語言
反向翻譯是語言中最常見的擾動方式。在這里,輸入被翻譯成不同的語言,然后再翻譯成相同的語言。這樣就獲得了具有相同語義屬性的新輸入。
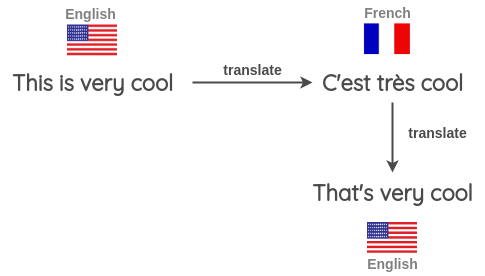
NLP中的反向翻譯
半監督學習方法
π model:
這里的目標是一致性正則化。
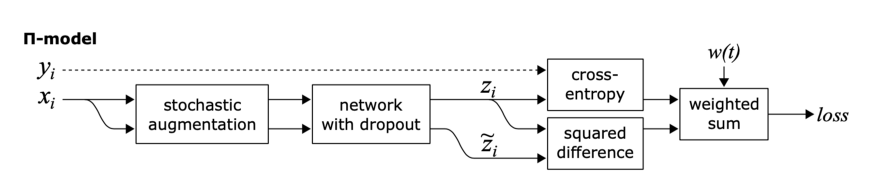
π模型鼓勵模型對兩個相同的輸入(即同一個輸入的兩個擾動變量)輸出之間的一致性。
π模型有幾個缺點,首先,訓練計算量大,因為每個epoch中單個輸入需要送到網絡中兩次。第二,訓練目標zi?是有噪聲的。
Temporal Ensembling:
這個方法的目標也是一致性正則化,但是實現方法有點不一樣。
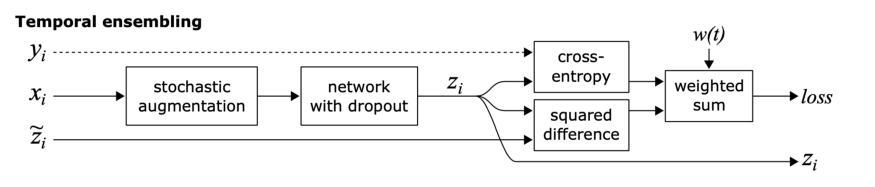
眾所周知,與單一模型相比,模型集成通常能提供更好的預測。通過在訓練期間使用單個模型在不同訓練時期的輸出來形成集成預測,這一思想得到了擴展。
簡單來說,不是比較模型的相同輸入的兩個擾動的預測(如π模型),模型的預測與之前的epoch中模型對該輸入的預測的加權平均進行比較。
這種方法克服了π模型的兩個缺點。它在每個epoch中,單個輸入只進入一次,而且訓練目標zi? 的噪聲更小,因為會進行滑動平均。
這種方法的缺點是需要存儲數據集中所有的zi? 。
英文原文:https://medium.com/analytics-vidhya/a-primer-on-semi-supervised-learning-part-2-803f45edac2
責任編輯:xj
原文標題:半監督學習入門基礎(二):最基礎的3個概念
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
SSL
+關注
關注
0文章
125瀏覽量
25740 -
半監督
+關注
關注
0文章
5瀏覽量
6326 -
機器學習
+關注
關注
66文章
8418瀏覽量
132635 -
深度學習
+關注
關注
73文章
5503瀏覽量
121162
原文標題:半監督學習入門基礎(二):最基礎的3個概念
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
自然語言處理與機器學習的關系 自然語言處理的基本概念及步驟
時空引導下的時間序列自監督學習框架

【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
三位半和四位半萬用表的區別
神經網絡如何用無監督算法訓練
深度學習中的無監督學習方法綜述
遷移學習的基本概念和實現方法
基于FPGA的類腦計算平臺 —PYNQ 集群的無監督圖像識別類腦計算系統
無監督深度學習實現單次非相干全息3D成像

CVPR'24 Highlight!跟蹤3D空間中的一切!

機器學習基礎知識全攻略
OpenAI推出Sora:AI領域的革命性突破
2024年AI領域將會有哪些新突破呢?
谷歌MIT最新研究證明:高質量數據獲取不難,大模型就是歸途






 工商網監
工商網監
評論