") 英偉達(dá)發(fā)布基于Ampere架構(gòu)的GPUA100
英偉達(dá)發(fā)布基于Ampere架構(gòu)的GPUA100
據(jù)該公司CEO黃仁勛介紹,A100采用臺(tái)積電當(dāng)時(shí)最先進(jìn)的7納米工藝打造,擁有540億個(gè)晶體管,面積高達(dá)826mm2,GPU的最大功率也達(dá)到了400W。又因?yàn)橥瑫r(shí)搭載了三星HBM2顯存、第三代TensorCore和帶寬高達(dá)600GB/s的新版NVLink,英偉達(dá)的A100在多個(gè)應(yīng)用領(lǐng)域也展現(xiàn)出強(qiáng)悍的性能。
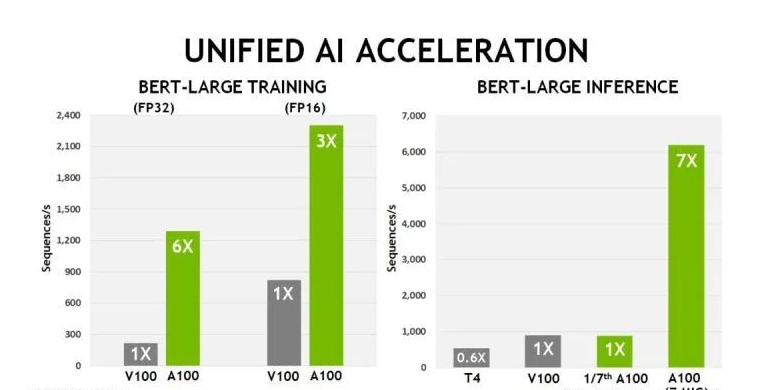
從英偉達(dá)提供的數(shù)據(jù)可以看到,如果用PyTorch框架跑AI模型,相比上一代V100芯片,A100在BERT模型的訓(xùn)練上性能提升6倍,BERT推斷時(shí)性能提升7倍。而根據(jù)MLPerf組織在十月底發(fā)布的最新推理基準(zhǔn)測(cè)試(Benchmark)MLPerfInferencev0.7結(jié)果,英偉達(dá)A100TensorCoreGPU在云端推理的基準(zhǔn)測(cè)試性能是最先進(jìn)英特爾CPU的237倍。
但英偉達(dá)不止步于此。在昨日,他們發(fā)布了面向AI超級(jí)計(jì)算的全球最強(qiáng)GPU——A10080GB;與此同時(shí),他們還帶來(lái)了一體式AI數(shù)據(jù)中心NVIDIADGXStationA100以及NVIDIAMellanox400GInfiniBand產(chǎn)品。
全球最強(qiáng)的AI超算GPU
據(jù)英偉達(dá)方面介紹,公司全新的A10080GBGPU的最大特點(diǎn)在于采用了HBM2E內(nèi)存技術(shù),能將A10040GBGPU的高帶寬內(nèi)存增加一倍至80GB,這樣的設(shè)計(jì)也讓英偉達(dá)成為業(yè)內(nèi)首個(gè)實(shí)現(xiàn)了2TB/s以上的內(nèi)存帶寬的企業(yè)。
“若想獲得HPC和AI的最新研究成果,則需要構(gòu)建最大的模型,而這需要比以往更大的內(nèi)存容量和更高的帶寬。A10080GBGPU所提供的內(nèi)存是六個(gè)月前推出的前代產(chǎn)品的兩倍,突破了每秒2TB的限制,使研究人員可以應(yīng)對(duì)全球科學(xué)及大數(shù)據(jù)方面最嚴(yán)峻的挑戰(zhàn)。”NVIDIA應(yīng)用深度學(xué)習(xí)研究副總裁BryanCatanzaro表示。
此外,第三代TensorCore核心、MIG技術(shù)、結(jié)構(gòu)化稀疏以及第三代NVLink和NVSwitch,也是全新GPU能夠獲得市場(chǎng)認(rèn)可的保證。
從英偉達(dá)提供的資料我們可以看到,該公司的第三代TensorCore核心通過(guò)全新TF32,能將上一代Volta架構(gòu)的AI吞吐量提高多達(dá)20倍;通過(guò)FP64,新核心更是能將HPC性能提高多達(dá)2.5倍;而通過(guò)INT8,新核心也可以將AI推理性能提高多達(dá)20倍,并且支持BF16數(shù)據(jù)格式。
MIG技術(shù)則能將單個(gè)獨(dú)立實(shí)例的內(nèi)存增加一倍,并可最多提供七個(gè)MIG,讓每個(gè)實(shí)例具備10GB內(nèi)存。英偉達(dá)方面表示,該技術(shù)是一種安全的硬件隔離方法,在處理各類較小的工作負(fù)載時(shí),可實(shí)現(xiàn)GPU最佳利用率。例如在如RNN-T等自動(dòng)語(yǔ)言識(shí)別模型的AI推理上,單個(gè)A10080GBMIG實(shí)例可處理更大規(guī)模的批量數(shù)據(jù),將生產(chǎn)中的推理吞吐量提高1.25倍。
至于結(jié)構(gòu)化稀疏,則可以將推理稀疏模型的速度提高2倍;包括第三代NVLink和NVSwitch在內(nèi)的新一代互連技術(shù),則可使GPU之間的帶寬增加至原來(lái)的兩倍,將數(shù)據(jù)密集型工作負(fù)載的GPU數(shù)據(jù)傳輸速度提高至每秒600gigabytes。
除了性能提升以外,基于A10040GB的多樣化功能設(shè)計(jì)的A10080GBGPU也成為需要大量數(shù)據(jù)存儲(chǔ)空間的各類應(yīng)用的理想選擇。
以DLRM等推薦系統(tǒng)模型為例,他們?yōu)锳I訓(xùn)練提供了涵蓋數(shù)十億用戶和產(chǎn)品信息的海量表單。但A10080GB可實(shí)現(xiàn)高達(dá)3倍加速,使企業(yè)可以重新快速訓(xùn)練這些模型,從而提供更加精確的推薦;在TB級(jí)零售大數(shù)據(jù)分析基準(zhǔn)上,A10080GB將其性能提高了2倍,使其成為可對(duì)最大規(guī)模數(shù)據(jù)集進(jìn)行快速分析的理想平臺(tái);對(duì)于科學(xué)應(yīng)用,A10080GB可為天氣預(yù)報(bào)和量子化學(xué)等領(lǐng)域提供巨大的加速。
“作為NVIDIAHGXAI超級(jí)計(jì)算平臺(tái)的關(guān)鍵組件,A10080GB還可訓(xùn)練如GPT-2這樣的、具有更多參數(shù)的最大模型。”英偉達(dá)方面強(qiáng)調(diào)。
下一代400GInfiniBand
在發(fā)布A10080GB的同時(shí),英偉達(dá)還帶了下一代的400GInfiniBand產(chǎn)品。在講述英偉達(dá)的新品之前,我們有必要先了解一下什么是InfiniBand。
所謂InfiniBand,是一種網(wǎng)絡(luò)通信協(xié)議,它提供了一種基于交換的架構(gòu),由處理器節(jié)點(diǎn)之間、處理器節(jié)點(diǎn)和輸入/輸出節(jié)點(diǎn)(如磁盤或存儲(chǔ))之間的點(diǎn)對(duì)點(diǎn)雙向串行鏈路構(gòu)成。每個(gè)鏈路都有一個(gè)連接到鏈路兩端的設(shè)備,這樣在每個(gè)鏈路兩端控制傳輸(發(fā)送和接收)的特性就被很好地定義和控制。而早前被英偉達(dá)收購(gòu)的Mellanox則是這個(gè)領(lǐng)域的專家。
資料顯示,Mellanox為服務(wù)器,存儲(chǔ)和超融合基礎(chǔ)設(shè)施提供包括以太網(wǎng)交換機(jī),芯片和InfiniBand智能互連解決方案在內(nèi)的大量的數(shù)據(jù)中心產(chǎn)品,其中,更以InfiniBand互連,是這些產(chǎn)品中重中之重。
據(jù)英偉達(dá)介紹,公司推出的第七代MellanoxInfiniBandNDR400Gb/s上帶來(lái)了更低的延遲,與上一代產(chǎn)品相比,新的產(chǎn)品更是實(shí)現(xiàn)了數(shù)據(jù)吞吐量的翻倍。又因?yàn)橛ミ_(dá)為這個(gè)新品帶來(lái)了網(wǎng)絡(luò)計(jì)算引擎,這就讓其能夠獲得額外的加速。
英偉達(dá)進(jìn)一步指出,作為一個(gè)面向AI超級(jí)計(jì)算的業(yè)界最強(qiáng)大的網(wǎng)絡(luò)解決方案,MellanoxNDR400GInfiniBand交換機(jī),可提供3倍的端口密度和32倍的AI加速能力。此外,它還將框式交換機(jī)系統(tǒng)的聚合雙向吞吐量提高了5倍,達(dá)到1.64petabits/s,從而使用戶能夠以更少的交換機(jī),運(yùn)行更大的工作負(fù)載。
“基于MellanoxInfiniBand架構(gòu)的邊緣交換機(jī)的雙向總吞吐量可達(dá)51.2Tb/s,實(shí)現(xiàn)了具有里程碑意義的每秒超過(guò)665億數(shù)據(jù)包的處理能力。”英偉達(dá)方面強(qiáng)調(diào)。而通過(guò)提供全球唯一的完全硬件卸載和網(wǎng)絡(luò)計(jì)算平臺(tái),NVIDIAMellanox400GInfiniBand實(shí)現(xiàn)了大幅的性能飛躍,可加快相關(guān)研究工作的進(jìn)展。
“我們的AI客戶的最重要的工作就是處理日益復(fù)雜的應(yīng)用程序,這需要更快速、更智能、更具擴(kuò)展性的網(wǎng)絡(luò)。NVIDIAMellanox400GInfiniBand的海量吞吐量和智能加速引擎使HPC、AI和超大規(guī)模云基礎(chǔ)設(shè)施能夠以更低的成本和復(fù)雜性,實(shí)現(xiàn)無(wú)與倫比的性能。”NVIDIA網(wǎng)絡(luò)高級(jí)副總裁GiladShainer表示。
從他們提供的數(shù)據(jù)我們可以看到,包括Atos、戴爾科技、富士通、浪潮、聯(lián)想和SuperMicro等公司在內(nèi)的全球領(lǐng)先的基礎(chǔ)設(shè)施制造商,計(jì)劃將Mellanox400GInfiniBand解決方案集成到他們的企業(yè)級(jí)產(chǎn)品中去。此外,包括DDN、IBMStorage以及其它存儲(chǔ)廠商在內(nèi)的領(lǐng)先的存儲(chǔ)基礎(chǔ)設(shè)施合作伙伴也將支持NDR。
全球唯一的千兆級(jí)工作組服務(wù)器
為了應(yīng)對(duì)不同開(kāi)發(fā)者對(duì)AI系統(tǒng)的需求,在推出芯片和連接解決方案的同時(shí),英偉達(dá)在2017年還推出一體式的AI數(shù)據(jù)中心NVIDIADGXStation。作為世界上首款面向AI開(kāi)發(fā)前沿的個(gè)人超級(jí)計(jì)算機(jī),開(kāi)發(fā)者只需要對(duì)其執(zhí)行簡(jiǎn)單的設(shè)置,就可以用Caffe、TensorFlow等去做深度學(xué)習(xí)訓(xùn)練、高精度圖像渲染和科學(xué)計(jì)算等傳統(tǒng)HPC應(yīng)用,避免了裝驅(qū)動(dòng)和配置環(huán)境等麻煩,這很適合高校、研究所、以及IT力量相對(duì)薄弱的企業(yè)。
昨日,英偉達(dá)今日發(fā)布了全球唯一的千兆級(jí)工作組服務(wù)器NVIDIADGXStationA100。作為開(kāi)創(chuàng)性的第二代人工智能系統(tǒng),DGXStationA100加速滿足位于全球各地的公司辦公室、研究機(jī)構(gòu)、實(shí)驗(yàn)室或家庭辦公室中辦公的團(tuán)隊(duì)對(duì)于機(jī)器學(xué)習(xí)和數(shù)據(jù)科學(xué)工作負(fù)載的強(qiáng)烈需求。而為了支持諸如BERTLarge推理等復(fù)雜的對(duì)話式AI模型,DGXStationA100比上一代DGXStation提速4倍以上。對(duì)于BERTLargeAI訓(xùn)練,其性能更是提高近3倍。
從性能來(lái)看,英偉達(dá)方面表示,DGXStationA100的AI性能可達(dá)2.5petaflops,是唯一一臺(tái)配備四個(gè)通過(guò)NVIDIANVLink完全互連的全新NVIDIAA100TensorCoreGPU的工作組服務(wù)器,可提供高達(dá)320GB的GPU內(nèi)存,能夠助力企業(yè)級(jí)數(shù)據(jù)科學(xué)和AI領(lǐng)域以最速度取得突破。
作為唯一支持NVIDIA多實(shí)例GPU(MIG)技術(shù)的工作組服務(wù)器,單一的DGXStationA100最多可提供28個(gè)獨(dú)立GPU實(shí)例以運(yùn)行并行任務(wù),并可在不影響系統(tǒng)性能的前提下支持多用戶。
為了支持更大規(guī)模的數(shù)據(jù)中心工作負(fù)載,DGXA100系統(tǒng)還將配備全新NVIDIAA10080GBGPU使每個(gè)DGXA100系統(tǒng)的GPU內(nèi)存容量增加一倍(最高可達(dá)640GB),從而確保AI團(tuán)隊(duì)能夠使用更大規(guī)模的數(shù)據(jù)集和模型來(lái)提高準(zhǔn)確性。
“全新DGXA100640GB系統(tǒng)也將集成到企業(yè)版NVIDIADGXSuperPODTM解決方案,使機(jī)構(gòu)能基于以20個(gè)DGXA100系統(tǒng)為單位的一站式AI超級(jí)計(jì)算機(jī),實(shí)現(xiàn)大規(guī)模AI模型的構(gòu)建、訓(xùn)練和部署。”英偉達(dá)方面強(qiáng)調(diào)。
該公司副總裁兼DGX系統(tǒng)總經(jīng)理CharlieBoyle則表示:“DGXStationA100將AI從數(shù)據(jù)中心引入可以在任何地方接入的服務(wù)器級(jí)系統(tǒng)。數(shù)據(jù)科學(xué)和AI研究團(tuán)隊(duì)可以使用與NVIDIADGXA100系統(tǒng)相同的軟件堆棧加速他們的工作,使其能夠輕松地從開(kāi)發(fā)走向部署。”
從英偉達(dá)提供的資料我們可以看到,配備A10080GBGPU的NVIDIADGXSuperPOD系統(tǒng)將率先安裝于英國(guó)的Cambridge-1超級(jí)計(jì)算機(jī),以加速推進(jìn)醫(yī)療保健領(lǐng)域研究,以及佛羅里達(dá)大學(xué)的全新HiPerGatorAI超級(jí)計(jì)算機(jī),該超級(jí)計(jì)算機(jī)將賦力這一“陽(yáng)光之州”開(kāi)展AI賦能的科學(xué)發(fā)現(xiàn)。
在今年發(fā)布的第二季財(cái)報(bào)上,英偉達(dá)數(shù)據(jù)中心業(yè)務(wù)首超游戲,成為公司營(yíng)收最大的業(yè)務(wù)板塊。從營(yíng)收增長(zhǎng)上看,與去年同期相比,英偉達(dá)數(shù)據(jù)中心業(yè)務(wù)業(yè)務(wù)大幅增長(zhǎng)167%,由此可以看到英偉達(dá)在這個(gè)市場(chǎng)影響力的提升以及公司對(duì)這個(gè)市場(chǎng)的信心。
考慮到公司深厚的技術(shù)積累和過(guò)去幾年收購(gòu)所做的“查漏補(bǔ)缺”,英偉達(dá)必將成為Intel在數(shù)據(jù)中心的最強(qiáng)勁挑戰(zhàn)者。
責(zé)任編輯人:CC
-
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3783瀏覽量
91247 -
Ampere
+關(guān)注
關(guān)注
1文章
67瀏覽量
4547
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦

加速拋棄英偉達(dá),微軟又發(fā)布一顆芯片 #微軟 #英偉達(dá) #半導(dǎo)體 #芯片 #電路知識(shí)
英偉達(dá)進(jìn)軍ARM架構(gòu)CPU市場(chǎng),預(yù)計(jì)2025年推出新產(chǎn)品線

英偉達(dá)Blackwell架構(gòu)揭秘:下一個(gè)AI計(jì)算里程碑?# 英偉達(dá)# 英偉達(dá)Blackwell
英偉達(dá)或取消B100轉(zhuǎn)用B200A代替






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論