 飛槳框架高層API 十行代碼搞定深度學習
飛槳框架高層API 十行代碼搞定深度學習
向往深度學習技術,可是深度學習框架太難學怎么辦?百度傾心打造飛槳框架高層 API,零基礎也能輕松上手深度學習,一起來看看吧?另:文末有福利,一定要看完呦~
高層 API,What
深度學習作為人工智能時代的核心技術,近年來無論學術、還是工業領域,均發揮著愈加重要的作用。然而,深度學習理論太難學,開發過程太復雜,又將許多人拒之于深度學習的門外。
為了簡化深度學習的學習過程、降低深度學習的開發難度,百度飛槳框架歷經近一年的打磨,不斷地優化深度學習 API,并針對開發者的使用場景進行封裝,在飛槳框架的最新版本中,推出了高低融合、科學統一的飛槳全新 API 體系。
飛槳框架將 API 分為兩種,基礎 API 和高層 API。用制作披薩舉例,一般有兩種方法:一種是我們準備好面粉、牛奶、火腿等食材,精心加工后,就能制作出美味的披薩;而第二種則是我們買商家預烤制的披薩餅,以及調好的餡料,直接加熱就可以吃到披薩了。
那么這兩種方法有什么區別呢?采用方法一,自己準備食材,可以隨心所欲的搭配料理,制作醬料,從而滿足我們的不同口味,但是,這更適合「老司機」,如果是新人朋友,很有可能翻車;而方法二,用商家預烤制的披薩餅與餡料,直接加熱就可以非常快速的完成披薩的制作,而且味道會有保障;但是,相比于方法一,我們會少一些口味的選擇。
用框架來類比,基礎 API 對應方法一,高層 API 對應方法二。使用基礎 API,我們可以隨心所欲的搭建自己的深度學習模型,不會受到任何限制;而使用方法二,我們可以很快的實現模型,但是可能會少一些自主性。
但是,與制作披薩不同的是,飛槳框架可以做到真正的「魚與熊掌」可以兼得。因為高層 API 本身不是一個獨立的體系,它完全可以和基礎 API 互相配合使用,做到高低融合,使用起來會更加便捷。使我們在開發過程中,既可以享受到基礎 API 的強大,又可以兼顧高層 API 的快捷。
高層 API,All
飛槳框架高層 API 的全景圖如下:
從圖中可以看出,飛槳框架高層 API 由五個模塊組成,分別是數據加載、模型組建、模型訓練、模型可視化和高階用法。針對不同的使用場景,飛槳框架提供了不同高層 API,從而降低開發難度,讓每個人都能輕松上手深度學習。
我們先通過一個深度學習中經典的手寫數字分類任務,來簡單了解飛槳高層 API。然后再詳細的介紹每個模塊中所包含的 API。
importpaddle
frompaddle.vision.transforms importCompose, Normalize
frompaddle.vision.datasets importMNIST
importpaddle.nn asnn
# 數據預處理,這里用到了歸一化
transform = Compose([Normalize(mean=[ 127.5],
std=[ 127.5],
data_format= ‘CHW’)])
# 數據加載,在訓練集上應用數據預處理的操作
train_dataset = paddle.vision.datasets.MNIST(mode= ‘train’, transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode= ‘test’, transform=transform)
# 模型組網
mnist = nn.Sequential(
nn.Flatten,
nn.Linear( 784, 512),
nn.ReLU,
nn.Dropout( 0.2),
nn.Linear( 512, 10))
# 模型封裝,用 Model 類封裝
model = paddle.Model(mnist)
# 模型配置:為模型訓練做準備,設置優化器,損失函數和精度計算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters),
loss=nn.CrossEntropyLoss,
metrics=paddle.metric.Accuracy)
# 模型訓練,
model.fit(train_dataset,
epochs= 10,
batch_size= 64,
verbose= 1)
# 模型評估,
model.evaluate(test_dataset, verbose= 1)
# 模型保存,
model.save( ‘model_path’)
從示例可以看出,在數據預處理、數據加載、模型組網、模型訓練、模型評估、模型保存等場景,高層 API 均可以通過 1~3 行代碼實現。相比傳統方法動輒幾十行的代碼量,高層 API 只需要十來行代碼,就能輕松完成一個 MNIST 分類器的實現。以極少的代碼就能達到與基礎 API 同樣的效果,大幅降低了深度學習的學習門檻。
如果是初次學習深度學習框架,使用飛槳高層 API,可以「凡爾賽」說出「好煩哦,飛槳高層 API 怎么這么快就完成開發了,我還想多寫幾行代碼呢!」
高層 API,How
接下來以 CV 任務為例,簡單介紹飛槳高層 API 在不同場景下的使用方法。
本示例的完整代碼可以在 AI Studio 上獲取,無需準備任何軟硬件環境即可直接在線運行代碼,相當方便哦:https://aistudio.baidu.com/aistudio/projectdetail/1243085
一、數據預處理與數據加載
對于數據加載,在一些典型的任務中,我們完全可以使用飛槳框架內置的數據集,完成數據的加載。飛槳框架將常用的數據集作為領域 API,集成在 paddle.vision.datasets 目錄中,包含了 CV 領域中常見的 MNIST、Cifar、Flowers 等數據集。
而在數據預處理場景中,飛槳框架提供了 20 多種常見的圖像預處理 API,方便我們快速實現數據增強,如實現圖像的色調、對比度、飽和度、大小等各種數字圖像處理的方法。圖像預處理 API 集成在 paddle.vision.transforms 目錄中,使用起來非常方便。只需要先創建一個數據預處理的 transform,在其中存入需要進行的數據預處理方法,然后在數據加載的過程中,將 transform 作為參數傳入即可。
此外,如果我們需要加載自己的數據集,使用飛槳框架標準數據定義與數據加載 API paddle.io.Dataset 與 paddle.io.DataLoader,就可以「一鍵」完成數據集的定義與數據的加載。這里通過一個案例來展示如何利用 Dataset 定義數據集,示例如下:
frompaddle.io importDataset
classMyDataset(Dataset):
“”“
步驟一:繼承 paddle.io.Dataset 類
”“”
def__init__(self):
“”“
步驟二:實現構造函數,定義數據讀取方式,劃分訓練和測試數據集
”“”
super(MyDataset, self).__init__
self.data = [
[ ‘traindata1’, ‘label1’],
[ ‘traindata2’, ‘label2’],
[ ‘traindata3’, ‘label3’],
[ ‘traindata4’, ‘label4’],
]
def__getitem__(self, index):
“”“
步驟三:實現__getitem__方法,定義指定 index 時如何獲取數據,并返回單條數據(訓練數據,對應的標簽)
”“”
data = self.data[index][ 0]
label = self.data[index][ 1]
returndata, label
def__len__(self):
“”“
步驟四:實現__len__方法,返回數據集總數目
”“”
returnlen(self.data)
# 測試定義的數據集
train_dataset = MyDataset
print( ‘=============train dataset=============’)
fordata, label intrain_dataset:
print(data, label)
只需要按照上述規范的四個步驟,我們就實現了一個自己的數據集。然后,將 train_dataset 作為參數,傳入到 DataLoader 中,即可獲得一個數據加載器,完成訓練數據的加載。
【Tips:對于數據集的定義,飛槳框架同時支持 map-style 和 iterable-style 兩種類型的數據集定義,只需要分別繼承 paddle.io.Dataset 和 paddle.io.IterableDataset 即可。】
二、網絡構建
在網絡構建模塊,飛槳高層 API 與基礎 API 保持一致,統一使用 paddle.nn 下的 API 進行組網。paddle.nn 目錄下包含了所有與模型組網相關的 API,如卷積相關的 Conv1D、Conv2D、Conv3D,循環神經網絡相關的 RNN、LSTM、GRU 等。
對于組網方式,飛槳框架支持 Sequential 或 SubClass 進行模型組建。Sequential 可以幫助我們快速的組建線性的網絡結構,而 SubClass 支持更豐富靈活的網絡結構。我們可以根據實際的使用場景,來選擇最合適的組網方式。如針對順序的線性網絡結構可以直接使用 Sequential ,而如果是一些比較復雜的網絡結構,我們使用 SubClass 的方式來進行模型的組建,在 __init__ 構造函數中進行 Layer 的聲明,在 forward 中使用聲明的 Layer 變量進行前向計算。
下面就來分別看一下 Sequential 與 SubClass 的實例。
1、Sequential
對于線性的網絡模型,我們只需要按網絡模型的結構順序,一層一層的加到 Sequential 后面即可,具體實現如下:
# Sequential 形式組網
mnist = nn.Sequential(
nn.Flatten,
nn.Linear(784, 512),
nn.ReLU,
nn.Dropout(0.2),
nn.Linear(512, 10)
)
2、SubClass
使用 SubClass 進行組網的實現如下:
# SubClass 方式組網
classMnist( nn. Layer):
def__init__( self) :
super(Mnist, self).__init_ _
self.flatten = nn.Flatten
self.linear_1 = nn.Linear( 784, 512)
self.linear_2 = nn.Linear( 512, 10)
self.relu = nn.ReLU
self.dropout = nn.Dropout( 0. 2)
defforward( self, inputs) :
y = self.flatten(inputs)
y = self.linear_1(y)
y = self.relu(y)
y = self.dropout(y)
y = self.linear_2(y)
returny
?
上述的 SubClass 組網的結果與 Sequential 組網的結果完全一致,可以明顯看出,使用 SubClass 組網會比使用 Sequential 更復雜一些。不過,這帶來的是網絡模型結構的靈活性。我們可以設計不同的網絡模型結構來應對不同的場景。
3、飛槳框架內置模型
除了自定義模型結構外,飛槳框架還「貼心」的內置了許多模型,真正的一行代碼實現深度學習模型。目前,飛槳框架內置的模型都是 CV 領域領域的模型,都在 paddle.vision.models 目錄下,包含了常見的 vgg 系列、resnet 系列等模型。使用方式如下:
import paddle
from paddle.vision.models import resnet18
# 方式一: 一行代碼直接使用
resnetresnet = resnet18
# 方式二: 作為主干網絡進行二次開發
classFaceNet( paddle. nn. Layer):
def__init__( self, num_keypoints= 15, pretrained=False) :
super(FaceNet, self).__init_ _
self.backbone = resnet18(pretrained)
self.outLayer1 = paddle.nn.Linear( 1000, 512)
self.outLayer2 = paddle.nn.Linear( 512, num_keypoints* 2)
defforward( self, inputs) :
out = self.backbone(inputs)
out = self.outLayer1(out)
out = self.outLayer2(out)
returnout
三、模型可視化
在我們完成模型的構建后,有時還需要可視化模型的網絡結構與參數,只要我們用 Model 進行模型的封裝后,然后調用 model.summary 即可實現網絡模型的可視化,具體如下:
mnist = nn.Sequential(
nn.Flatten,
nn.Linear(784, 512),
nn.ReLU,
nn.Dropout(0.2),
nn.Linear(512, 10))
# 模型封裝,用 Model 類封裝
model = paddle.Model(mnist)
model.summary
其輸出如下:
---------------------------------------------------------------------------
Layer ( type) Input Shape Output Shape Param #
===========================================================================
Flatten -795[[32, 1, 28, 28]][ 32, 784] 0
Linear -5[[32, 784]][ 32, 512] 401, 920
ReLU -3[[32, 512]][ 32, 512] 0
Dropout -3[[32, 512]][ 32, 512] 0
Linear -6[[32, 512]][ 32, 10] 5, 130
===========================================================================
Total params: 407, 050
Trainable params: 407, 050
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.10
Forward/backward pass size (MB): 0.57
Params size (MB): 1.55
Estimated Total Size (MB): 2.22
---------------------------------------------------------------------------
{ ‘total_params’: 407050, ‘trainable_params’: 407050}
?
Model.summary 不僅會給出每一層網絡的形狀,還會給出每層網絡的參數量與模型的總參數量,非常方便直觀的就可以看到模型的全部信息。
四、模型訓練
1、使用高層 API 在全部數據集上進行訓練
過去常常困擾深度學習開發者的一個問題是,模型訓練的代碼過于復雜,常常要寫好多步驟,才能使程序運行起來,冗長的代碼使許多開發者望而卻步。
現在,飛槳高層 API 將訓練、評估與預測 API 都進行了封裝,直接使用 Model.prepare、Model.fit、Model.evaluate、Model.predict就可以完成模型的訓練、評估與預測。
對比傳統框架動輒一大塊的訓練代碼。使用飛槳高層 API,可以在 3-5 行內,完成模型的訓練,極大的簡化了開發的代碼量,對初學者開發者非常友好。具體代碼如下:
# 將網絡結構用 Model 類封裝成為模型
model = paddle.Model(mnist)
# 為模型訓練做準備,設置優化器,損失函數和精度計算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters),
loss=paddle.nn.CrossEntropyLoss,
metrics=paddle.metric.Accuracy)
# 啟動模型訓練,指定訓練數據集,設置訓練輪次,設置每次數據集計算的批次大小,設置日志格式
model.fit(train_dataset,
epochs=10,
batch_size=64,
verbose=1)
# 啟動模型評估,指定數據集,設置日志格式
model.evaluate(test_dataset, verbose=1)
# 啟動模型測試,指定測試集
Model.predict(test_dataset)
2、使用高層 API 在一個批次的數據集上訓練、驗證與測試
有時我們需要對數據按 batch 進行取樣,然后完成模型的訓練與驗證,這時,可以使用 train_batch、eval_batch、predict_batch 完成一個批次上的訓練、驗證與測試,具體如下:
# 模型封裝,用 Model 類封裝
model = paddle.Model(mnist)
# 模型配置:為模型訓練做準備,設置優化器,損失函數和精度計算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters),
loss=nn.CrossEntropyLoss,
metrics=paddle.metric.Accuracy)
# 構建訓練集數據加載器
train_loader = paddle.io.DataLoader(train_dataset, batch_size= 64, shuffle= True)
# 使用 train_batch 完成訓練
forbatch_id, data inenumerate(train_loader):
model.train_batch([data[ 0]],[data[ 1]])
# 構建測試集數據加載器
test_loader = paddle.io.DataLoader(test_dataset, places=paddle.CPUPlace, batch_size= 64, shuffle= True)
# 使用 eval_batch 完成驗證
forbatch_id, data inenumerate(test_loader):
model.eval_batch([data[ 0]],[data[ 1]])
# 使用 predict_batch 完成預測
forbatch_id, data inenumerate(test_loader):
model.predict_batch([data[ 0]])
五、高階用法
除此之外,飛槳高層 API 還支持一些高階的玩法,如自定義 Loss、自定義 Metric、自定義 Callback 等等。
自定義 Loss 是指有時我們會遇到特定任務的 Loss 計算方式在框架既有的 Loss 接口中不存在,或算法不符合自己的需求,那么期望能夠自己來進行 Loss 的自定義。
自定義 Metric 和自定義 Loss 的場景一樣,如果遇到一些想要做個性化實現的操作時,我們也可以來通過框架完成自定義的評估計算方法。
自定義 Callback 則是可以幫助我們收集訓練時的一些參數以及數據,由于 Model.fit封裝了訓練過程,如果我們需要保存訓練時的 loss、metric 等信息,則需要通過 callback 參數收集這部分信息。
更多更豐富的玩法,可以掃描關注文末的二維碼獲取~
高層 API,Next
上文以 CV 任務為例,介紹了飛槳框架高層 API 的使用指南。后續,飛槳框架還計劃推出 NLP 領域專用的數據預處理模塊,如對數據進行 padding、獲取數據集詞表等;在組網方面,也會實現 NLP 領域中組網專用的 API,如組網相關的 sequence_mask,評估指標相關的 BLEU 等;最后,針對 NLP 領域中的神器 transformer,我們也會對其進行特定的優化;待這些功能上線后,我們會第一時間告訴大家,敬請期待吧~
高層 API,Where
看完前面飛槳高層 API 的使用介紹,是不是有種躍躍欲試的沖動呀?
體驗方式一:在線體驗
無需準備任何軟硬件環境,直接訪問以下地址,即可在線跑代碼看效果:https://aistudio.baidu.com/aistudio/projectdetail/1243085
體驗方式二:本地體驗
如果你還想在自己本地電腦上體驗,那需要確保本地電腦上已成功安裝飛槳開源框架 2.0。
下面介紹飛槳開源框架 2.0 的安裝方法,可以參考下面的命令,直接使用 pip 安裝。安裝后,就可以開始使用高層 API 啦。
# CPU 版
$ pip3 install paddlepaddle== 2.0.0rc0 -i https: //mirror.baidu.com/pypi/simple
# GPU 版
$ pip3 install paddlepaddle_gpu== 2.0.0rc0 -i https: //mirror.baidu.com/pypi/simple
高層 API,You
-
框架
+關注
關注
0文章
403瀏覽量
17489 -
代碼
+關注
關注
30文章
4788瀏覽量
68617 -
深度學習
+關注
關注
73文章
5503瀏覽量
121170 -
飛槳
+關注
關注
0文章
33瀏覽量
2290
發布評論請先 登錄
相關推薦
芯盾時代入選《API安全技術應用指南(2024版)》API安全十大代表性廠商
卷積神經網絡的實現工具與框架
在Ubuntu 24.04 LTS上安裝飛槳PaddleX
凌智電子加入飛槳技術伙伴計劃,攜手PaddleX為視覺模組產品賦能添“智”

NVIDIA推出全新深度學習框架fVDB
PyTorch深度學習開發環境搭建指南
深度學習常用的Python庫
TensorFlow與PyTorch深度學習框架的比較與選擇
百度發布文心大模型4.0 Turbo與飛槳框架3.0,引領AI技術新篇章
百度文心大模型4.0 Turbo,正式發布 用戶規模已達3億
訊飛星火Lite API開放免費永久,星火Pro/Max API價格0.2元
工大高科與科大訊飛簽訂戰略合作框架協議
NVIDIA宣布推出基于Omniverse Cloud API構建的全新軟件框架
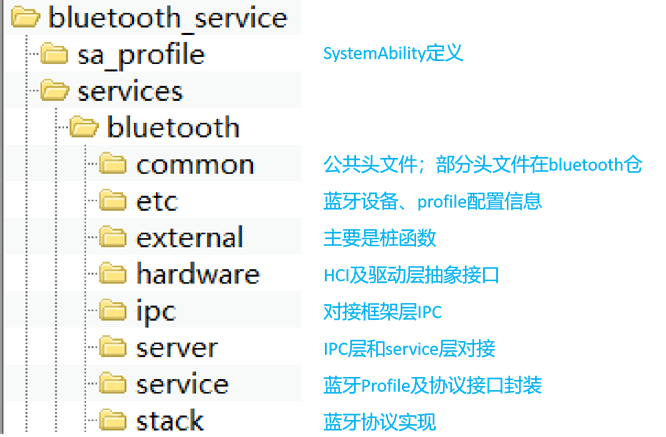
【鴻蒙】OpenHarmony 4.0藍牙代碼結構簡析





 工商網監
工商網監
評論