 騰訊AI推出“絕悟”完全體
騰訊AI推出“絕悟”完全體
說起 MOBA 類手游,想必大家都能想到王者榮耀。它近日又有了新動作。11 月 28 日騰訊宣布,旗下騰訊 AI Lab 與王者榮耀聯合研發的策略協作型 AI “絕悟” 推出升級版本 “絕悟 “完全體。 目前,“絕悟 “背后采用的創新算法突破了 AI 的英雄上限,英雄池數量也從 40 個增至 100 + 個。創新算法能夠讓 AI 完全掌握所有英雄的所有技能,同時應對高達 10 的 15 次方的英雄組合數變化,幾乎覆蓋人類玩家能夠選出的組合。另一技術亮點則是優化了禁選英雄(BanPick,簡稱 BP)博弈策略,能綜合自身技能與對手情況等多重因素派出最優英雄組合。 相關研究已被 AI 頂級會議 NeurIPS 2020 與頂級期刊 TNNLS 收錄,兩篇論文的一作均為騰訊的 Deheng Ye(葉德珩)。
同時,“絕悟” 完全體版本已在王者榮耀 App 限時開放。各榮耀玩家可以上線與之對戰,體驗時間為 11 月 14 日至 30 日,絕悟在 20 個關卡的能力不斷提升,最強的 20 級于 11 月 28 日開放,接受 5v5 組隊挑戰。
AI 策略:紅方 AI 鎧大局觀出色,繞后蹲草叢扭轉戰局 積少成多,自古英雄出少年
王者榮耀中,最吸引人的稱號是:“全能高手”。想要獲得它卻很難,你需要在五個職業中(對抗路、中路、發育路、游走、打野)都擁有 4 個紫色熟練度英雄。但因為練習時間與精力限制,很少有人能精通所有英雄。 而 “絕悟”技術團隊一年內讓 AI 掌握的英雄數從 1 個增加到 100 + 個,完全解禁英雄池,此版本因此得名 “絕悟完全體”。 那么 “絕悟完全體” 是怎樣做到的呢? 我們知道,從零學會單個陣容易如反掌,但面對多英雄組合時就難如登天。在對戰中,因為地圖龐大且信息不完備,不同的 10 個英雄組合應該有不同的策略規劃、技能應用、路徑探索及團隊協作方式,這將使決策難度幾何級增加。并且,多英雄組合也帶來了 “災難性遺忘” 問題,這使得模型容易邊學邊忘,是長期困擾開發者的大難題。
為了應對上述問題,技術團隊先引入 “老師分身” 模型,讓每個 AI 老師在單個陣容上訓練至精通,再引入一個 AI 學生模仿學習所有的 AI 老師,最終讓 “絕悟” 掌握了所有英雄的所有技能,成為一代宗師。 同時,團隊還制定了長期目標,就是要讓 “絕悟” 學會所有英雄的技能,且每個英雄都能達到頂尖水平。為此他們在技術上做了三項重點突破: 首先團隊構建了一個最佳神經網絡模型,讓模型適配 MOBA 類任務、表達能力強、還能對英雄操作精細建模。模型綜合了大量 AI 方法的優勢,具體而言: 1. 在時序信息上引入長短時記憶網絡(LSTM)優化部分可觀測問題; 2. 在圖像信息上選擇卷積神經網絡(CNN)編碼空間特征; 3. 用注意力(Attention)方法強化目標選擇; 4. 用動作過濾(Action Mask)方法提升探索效率; 5. 用分層動作設計加快訓練速度; 6. 用多頭值估計(Multi-Head Value)方法降低估計方差等。
圖 | 網絡架構 其次,團隊借用圍棋的思路,采用了 CSPL(Curriculum Self-Play Learning,課程自對弈學習),能夠有效拓寬英雄池,讓 “絕悟 “掌握所有英雄技能。 CSPL 是一種讓 AI 從易到難的漸進式學習方法,具體有以下幾個步驟: 1.“老師分身” 模型:挑選多組覆蓋全部英雄池的陣容,在小模型下用強化學習訓練,得到多組 “老師分身” 模型; 2.遷移模型:蒸餾,把第一步得到的多個模型的能力遷移到同一個大模型中; 3.隨機陣容的強化訓練:在蒸餾后的大模型里,隨機挑選陣容繼續強化訓練和微調。通過多種傳統和新穎技術方法的結合,實現了在大的英雄池訓練,同時還能不斷擴展的目標。
圖 | CSPL 流程圖。任務由易到難,模型從簡單到復雜,知識逐層深入。 實驗結果表明,使用 CSPL 方法擴展英雄池有明顯優勢,能夠在非常有效地減少訓練時間,同時保持良好的效果。
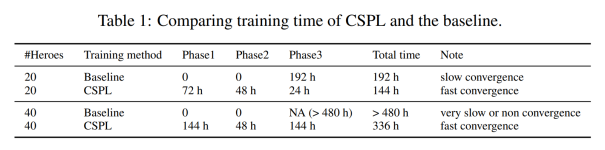
圖 | 實驗結果 最后,團隊還搭建了大規模訓練平臺 —— 騰訊開悟(aiarena.tencent.com)。該平臺依托項目積累的算法經驗、脫敏數據及騰訊云的算力資源,為訓練所需的大規模運算保駕護航。目前,開悟平臺于今年 8 月對 18 所高校開放,未來希望為更多科研人員提供技術與資源支持,深化課題研究。 排兵布陣,致人而不致于人
作為團隊的大腦,教練在整個比賽中都起到了非常重要的作用。無論是在 BP 環節(禁選英雄)的選擇,還是陣容的壓制上面,稍有不慎就為給對手帶來先天優勢,造成 “致于人” 的局面。因此,“絕悟” 要取得勝利就必須找到一個能排兵布陣的 AI 教練。
目前,簡單的做法是選擇貪心策略,即選擇當前勝率最高的英雄。這針對單個英雄而言或許可以,但王者榮耀有上百個英雄,任意英雄間都有或促進或克制的關系,只按勝率選擇很容易被對手針對,更需要綜合考慮敵我雙方、已選和未選英雄的相關信息,最大化己方優勢,最小化敵方優勢。 受到圍棋 AI 算法(Alpha Go)的啟發,團隊使用蒙特卡洛樹搜索(MCTS)和神經網絡結合的自動 BP 模型來解決這一問題。 MCTS 方法包括了選擇、擴張、模擬和反向傳播四個步驟,會不斷迭代搜索,估算出可選英雄的長期價值。在這其中模擬部分最耗時,所以團隊用估值神經網絡替代該環節,加快了搜索速度,這樣能夠又快又準地選出具備最大長期價值的英雄。要提到的是,圍棋等棋牌類游戲結束就能確定勝負,但 BP 結束只到確定陣容,還未對戰,所以勝負未分。因此團隊利用絕悟自對弈產生的超過 3000 萬條對局數據訓練出一個陣容勝率預測器,用來預測陣容的勝率。勝率預測器得到的陣容勝率又被用來監督訓練估值網絡。
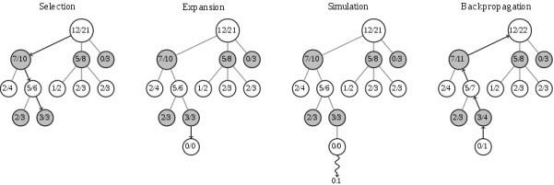
圖 | 蒙特卡洛搜索樹 除了常見的單輪 BP,AI 教練還學會了王者榮耀 KPL 賽場上常見的多輪 BP 賽制,該模式下不能選重復英雄,對選人策略要求更高。為此,團隊引入多輪長周期判定機制,在 BO3/BO5 賽制中可以全局統籌、綜合判斷,做出最優 BP 選擇。訓練后的 BP 模型在對陣基于貪心策略的基準方法時,能達到近 70% 勝率,對陣按位置隨機陣容的勝率更接近 90%。 至此,強兵加軍師的組合,使得 “絕悟” 成為了不折不扣的一代宗師。
除了上述的 RL(強化學習)算法外,團隊還開發了 SL(監督學習)算法,針對大局觀和微操策略同時建模,讓絕悟同時擁有優秀的長期規劃和即時操作,達到了非職業玩家的頂尖水平。
相關技術成果曾在 2018 年 12 月公開亮相對戰人類玩家。其實,團隊對于監督學習的研發一直在持續進行中。今年 11 月 14 日起開放的絕悟第 1 到 19 級,就有多個關卡由監督學習訓練而成。
從研究方法上看,監督學習對于 AI 智能體的研發有很高的價值。 1.“更像人”:通過挖掘人類數據預測未來的監督學習是通常是研發游戲 AI 的第一步,并在眾多視頻游戲上取得較好效果。比如在明星大亂斗等復雜電子游戲中,純監督學習能也學到達到人類高手玩家水平的 AI 智能體。 2. 多種深度學習的結合:監督學習能復用為強化學習的策略網絡,如 AlphaGo 就是監督學習結合強化學習。 3. 節約訓練時間:同時適當地插入監督學習可以縮短強化學習探索時間,比如 DeepMind 的星際爭霸 AI AlphaStar 就用監督學習做強化訓練的隱含狀態。
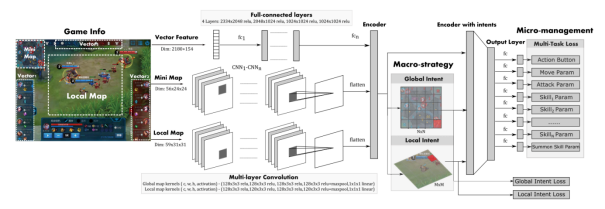
圖 | 網絡架構 應用上述諸多優點,“絕悟 “可以實現一系列效果:訓練快,在 16 張 GPU 卡上只需幾天,而強化學習則需幾個月;拓展能力強,能完成全英雄池訓練;使用真實玩家的脫敏數據,配合有效采樣,產出的 AI 行為上會更接近人類。 隨著 AI 在游戲世界的發展,它們在數據的記憶和處理方面的優勢能夠進一步體現出來。那么如何利用 AI 來強化自己的隊伍,或許是當下游戲教練需要思索的問題。 -End-
原文標題:登上NeurIPS 2020:騰訊AI聯合王者榮耀推出“絕悟”完全體
文章出處:【微信公眾號:DeepTech深科技】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
神經網絡
+關注
關注
42文章
4772瀏覽量
100824 -
AI
+關注
關注
87文章
30979瀏覽量
269252
原文標題:登上NeurIPS 2020:騰訊AI聯合王者榮耀推出“絕悟”完全體
文章出處:【微信號:deeptechchina,微信公眾號:deeptechchina】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論