") 愛奇藝深度學(xué)習(xí)平臺對TF Serving毛刺問題的優(yōu)化
愛奇藝深度學(xué)習(xí)平臺對TF Serving毛刺問題的優(yōu)化
在點擊率 CTR(Click Through Rate)預(yù)估算法的推薦場景中使用 TensorFlow Serving 熱更新較大模型時會出現(xiàn)短暫的延時毛刺,導(dǎo)致業(yè)務(wù)側(cè)超時,降低算法效果,為了解決這個問題,愛奇藝深度學(xué)習(xí)平臺團(tuán)隊經(jīng)過多個階段的優(yōu)化實踐,最后對 TF Serving 和 TensorFlow 的源碼進(jìn)行深入優(yōu)化,將模型熱更新時的毛刺現(xiàn)象解決,本文將分享 TensorFlow Serving 的優(yōu)化細(xì)節(jié),希望對大家有幫助。
背景介紹
TensorFlow Serving是谷歌開源的用來部署機(jī)器學(xué)習(xí)模型的高性能推理系統(tǒng)。它主要具備如下特點:
同時支持 gRPC 和 HTTP 接口
支持多模型,多版本
支持模型熱更新和版本切換
TensorFlow Serving
https://github.com/tensorflow/serving
愛奇藝深度學(xué)習(xí)平臺上大量的 CTR 推薦類業(yè)務(wù)使用 TensorFlow Serving 來部署線上推理服務(wù)。
CTR 類業(yè)務(wù)對線上服務(wù)的可持續(xù)性要求很高,如果模型升級時要中斷服務(wù)是不可接受的,因此 TF Serving 的模型熱更新功能對這樣的業(yè)務(wù)場景提供了很大的幫助,可以避免重啟容器來做模型升級。
但是,隨著業(yè)務(wù)對模型更新實時性的要求越來越高,我們發(fā)現(xiàn),模型熱更新時出現(xiàn)的短暫客戶端請求超時現(xiàn)象(稱之為毛刺現(xiàn)象)變成進(jìn)一步提升實時性的一個比較大的障礙。
模型更新時的毛刺現(xiàn)象
先來看一下,
什么是模型更新時的毛刺現(xiàn)象?
下面這張圖是我們在 TF Serving 代碼中增加了 Bvar(https://github.com/apache/incubator-brpc/blob/master/docs/cn/bvar.md) 來查看內(nèi)部請求的延遲情況。圖中是延遲的分位比,延遲分位值分別為 [p80, p90, p99, p999],單位是微秒。
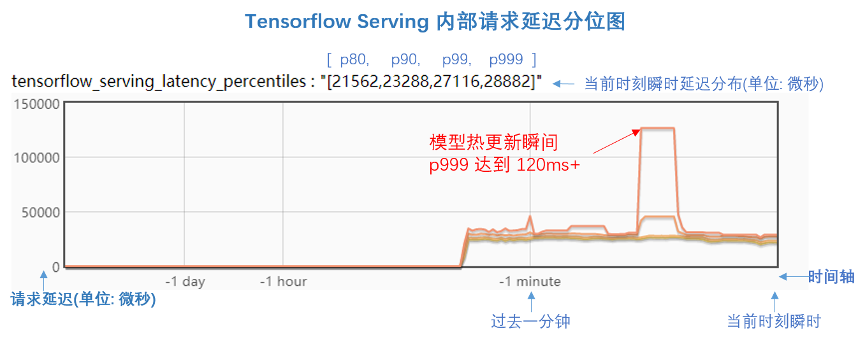
從圖中可以看到,在模型更新前后,p999的延遲都在 30ms以下。但是,在模型更新的瞬間,p999延遲突然抖動到 120ms+,持續(xù)了大概 10 秒時間,這就是毛刺現(xiàn)象,反應(yīng)到客戶端就是會產(chǎn)生請求超時失敗。
為了完全解決這個問題,愛奇藝深度學(xué)習(xí)平臺經(jīng)過多個階段的深入優(yōu)化,最后將模型更新時的毛刺現(xiàn)象解決。
TF Serving 的模型更新過程
工欲善其事必先利其器,我們先來看看 TF Serving 內(nèi)部的模型更新過程。
如上圖,Source會啟動一個線程來不斷查看模型文件,然后將發(fā)現(xiàn)的新模型構(gòu)建相應(yīng)的 Servable 數(shù)據(jù)結(jié)構(gòu)放到 Aspired Versions 的隊列中去。
DynamicManager也會啟動一個線程,來不斷查看 Aspired Versions隊列是否有需要處理的請求,根據(jù)配置的 Version Policy 來執(zhí)行模型更新策略,最后通過 SessionBundle來執(zhí)行模型的加載和卸載。
Version Policy 默認(rèn)為 AvailabilityPreservingPolicy,該 policy 的特點是當(dāng)有新的模型加入時,會保證至少有一個可服務(wù)的模型版本,當(dāng)新版本加載完成后,再卸載舊版本,這樣可以最大程度的保證模型的可服務(wù)性。
舉例子來講,如果只支持一個模型版本,當(dāng)前版本是 2,如果有新的版本 3 加入,那么會先加載版本 3,然后再卸載版本 2。
接下來,詳細(xì)看一下 TF Serving 的模型加載過程,主要分成以下幾個步驟:
創(chuàng)建一個 DirectSession
將模型的 Graph 加載到 Session 中
執(zhí)行 Graph 中的 Restore Op 來將變量從模型中讀取到內(nèi)存
執(zhí)行 Graph 中的 Init Op 做相關(guān)的模型初始化
如果配置了 Warmup,執(zhí)行 Warmup 操作,通過定義好的樣本來預(yù)熱模型
TensorFlow 的模型執(zhí)行有個非常顯著的特點是 lazy initialization,也就是如果沒有 Warmup,當(dāng) TF Serving 加載完模型,其實只是加載了 Graph 和變量,Graph 中的 OP 其實并沒有做初始化,只有當(dāng)客戶端第一次發(fā)請求過來時,才會開始初始化 OP。
問題的初步優(yōu)化
從上面的分析來看,可以看到初步的解決方案,那就是做模型的 Warmup,具體方案如下:
配置模型 Warmup,在模型目錄中增加 tf_serving_warmup_requests 文件
使用獨(dú)立線程來做模型的加載和卸載操作,配置 num_unload_threads和 num_load_threads
模型如何做 Warmup 詳細(xì)請參考 TF 的文檔 SavedModel Warmup。
https://tensorflow.google.cn/tfx/serving/saved_model_warmup
第二項優(yōu)化主要是參考美團(tuán)的文章基于 TensorFlow Serving 的深度學(xué)習(xí)在線預(yù)估。
https://tech.meituan.com/2018/10/11/tfserving-improve.html
我們來對比一下優(yōu)化前后的區(qū)別:
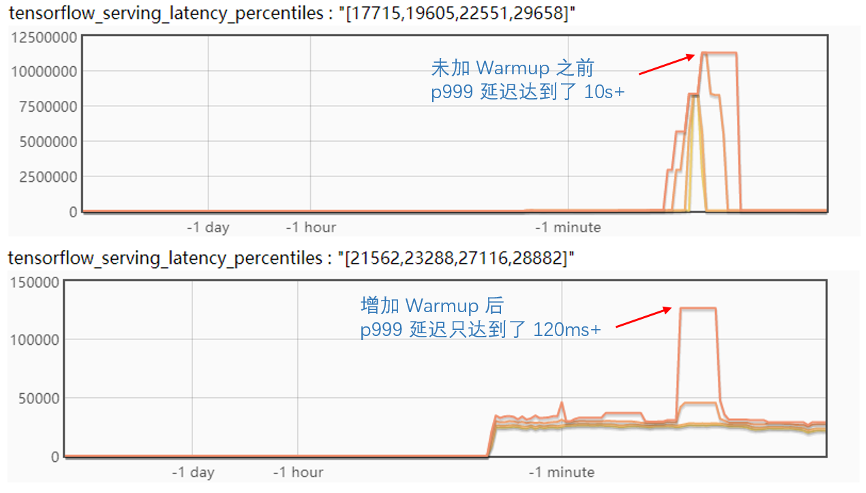
可以看到,使用上面的優(yōu)化,抖動的延遲減少了幾個數(shù)量級,效果很明顯。
問題的進(jìn)一步優(yōu)化
雖然上面的優(yōu)化將模型更新時的毛刺降低到只有 120ms+,但是這個仍然會對客戶端的請求產(chǎn)生超時現(xiàn)象,如果模型更新的頻率不高,比如一天更新一次,那么基本上是可以接受的。
但是,如果業(yè)務(wù)對模型更新的實時性到一個小時以內(nèi),甚至更高,那么就必須進(jìn)一步解決毛刺問題。我們不得不繼續(xù)思考,剩下的這個毛刺是由于什么原因產(chǎn)生的?
TF Serving 是一個計算密集型的服務(wù),對可能產(chǎn)生影響的因素,我們做了如下猜測:
計算原因:是不是新模型的初始化,包括 Warmup 的計算,影響了推理請求?
內(nèi)存原因:是不是模型更新過程中的內(nèi)存分配或釋放產(chǎn)生鎖而導(dǎo)致的?
或者兩者都有?
計算原因分析
先來分析一下計算方面的原因,如果模型加載會影響到推理請求,那么能不能將模型的加載也用獨(dú)立的線程來做?
經(jīng)過調(diào)研 TF Serving 的源碼,我們發(fā)現(xiàn)了這樣的參數(shù),原來 TF 已經(jīng)考慮到這樣的因素。
// If set, session run calls use a separate threadpool for restore and init // ops as part of loading the session-bundle. The value of this field should // correspond to the index of the tensorflow::ThreadPoolOptionProto defined as // part of session_config.session_inter_op_thread_pool. google.protobuf.Int32Value session_run_load_threadpool_index = 4;
通過配置 session_inter_op_thread_pool并設(shè)置 session_run_load_threadpool_index可以將模型的初始化放在獨(dú)立的線程。
修改配置后,并做了相關(guān)驗證,如下圖。
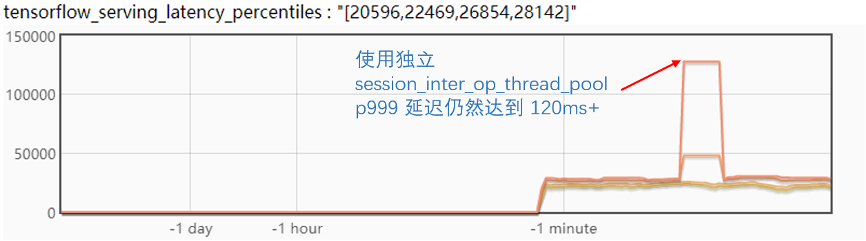
驗證的結(jié)論很遺憾,使用獨(dú)立的線程來處理模型初始化并不能緩解毛刺問題。
從而,進(jìn)一步分析了 TF Serving 的線程機(jī)制,發(fā)現(xiàn)計算部分主要集中在 TF 的 Inter 和 Intra Op 線程,在模型初始化線程獨(dú)立出來后,原來的推理請求基本不會被影響到。
另外,經(jīng)過分析還發(fā)現(xiàn),TF 在執(zhí)行 Restore Op 的時候會創(chuàng)建額外的線程池來恢復(fù)大的變量,于是嘗試將 Restore 時的線程池去掉,發(fā)現(xiàn)仍然沒有效果。
內(nèi)存原因分析
先來看一下 TF 內(nèi)存的分配機(jī)制,TF 的 GPU 顯存是通過 BFC (best-fit with coalescing) 算法來分配的,CPU 內(nèi)存分配是直接調(diào)用底層 glibc ptmalloc2 的 memory allocation。
目前平臺上 CTR 類業(yè)務(wù)基本都是 CPU 推理,因此內(nèi)存的分配和釋放都是通過 glibc ptmalloc2 來管理的。
經(jīng)過調(diào)研了解到,Linux glibc 的內(nèi)存管理也是經(jīng)過優(yōu)化的,原來的實現(xiàn)是 dlmalloc,對多線程的支持并不好,現(xiàn)在的 ptmalloc2 是優(yōu)化后支持了多線程。
如果要深入到 ptmalloc2 優(yōu)化內(nèi)存管理就比較麻煩,不過調(diào)研發(fā)現(xiàn)已經(jīng)有了開源的優(yōu)化方案,那就是谷歌的 Tcmalloc和 Facebook 的 Jemalloc。
Tcmalloc
http://goog-perftools.sourceforge.net/doc/tcmalloc.html)
Jemalloc
http://jemalloc.net/
Ptmalloc,Tcmalloc 和 Jemalloc 的優(yōu)缺點網(wǎng)上有很多分析的文章,都指出 Tcmalloc 和 Jemalloc 在多線程環(huán)境下有比較好的性能,大體從原理上來講是區(qū)分大小內(nèi)存塊的分配,各個線程有自己內(nèi)存分配區(qū)域,減少鎖競爭。
對比試驗了三個內(nèi)存分配器,實驗結(jié)果如下圖:
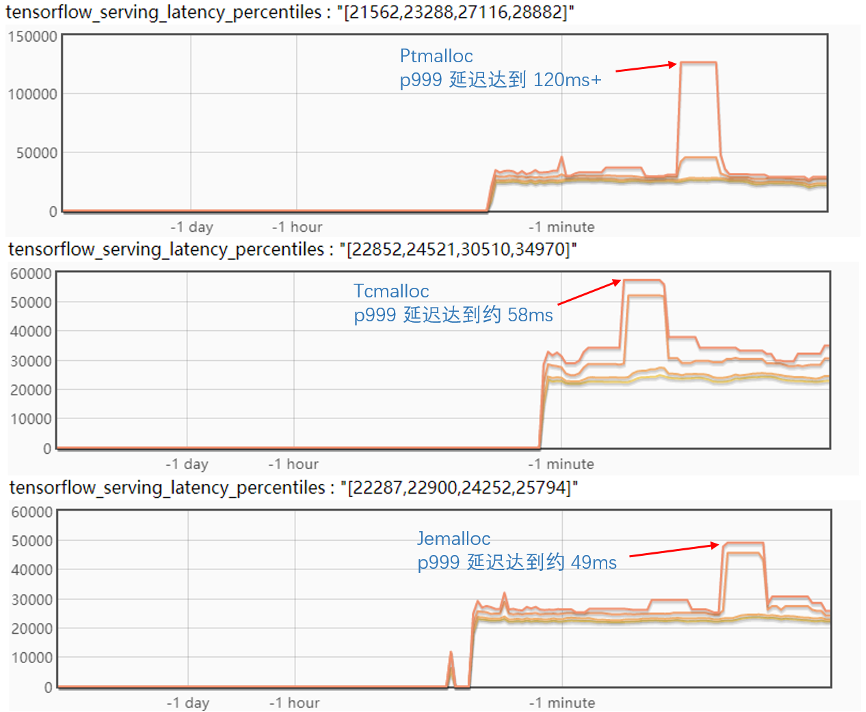
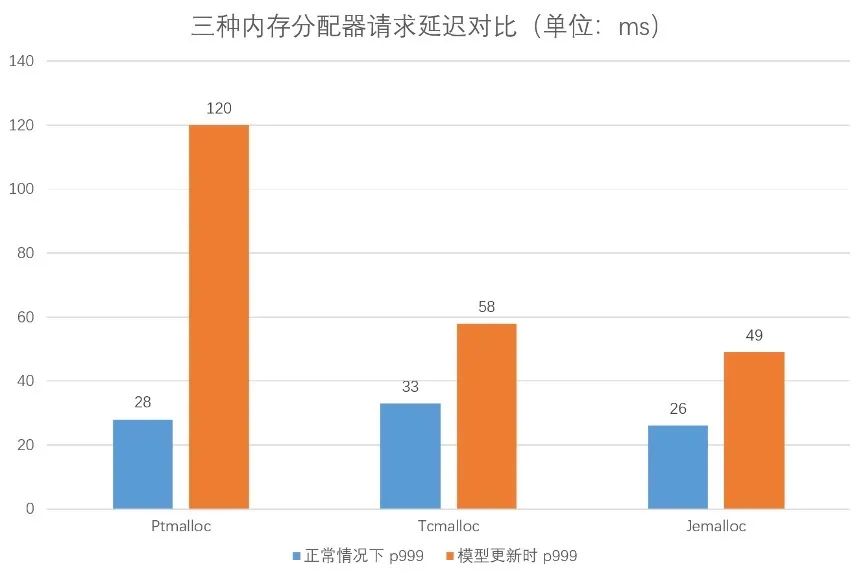
從實驗結(jié)果來看,Tcmalloc 和 Jemalloc 對毛刺都有比較好的緩解,但是 Tcmalloc 會增加正常情況下的 p999 延遲;而反觀 Jemalloc 的毛刺 p999 降到了 50ms 以下,正常情況下的 p999 比 Ptmalloc也有所優(yōu)化。
看起來 Jemalloc 是一個相對比較理想的方案,不過在進(jìn)一步的試驗中發(fā)現(xiàn),如果同時更新兩個版本,Jemalloc 的 p999 毛刺會達(dá)到近 60ms,并且更新后會有一個比較長的延遲抖動期,會持續(xù)近一分鐘時間,如下圖:
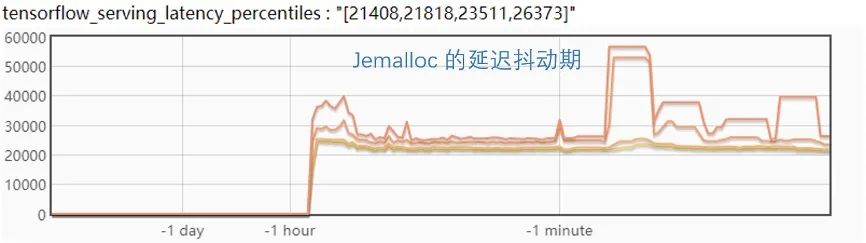
優(yōu)化到這一步,如果對這樣的延遲變化不敏感的話,基本就可以用 Jemalloc 來做為方案上線了,但對這樣的效果仍覺得不是非常理想,因此進(jìn)行了更深入的優(yōu)化。
問題的最終深入優(yōu)化
上面內(nèi)存方案的優(yōu)化效果提供了一個很好的啟示和方向,毛刺的根本原因應(yīng)該在內(nèi)存的分配和釋放競爭上,所以來進(jìn)一步分析 TF 的內(nèi)存分配。
TF 內(nèi)存分配和釋放的使用場景主要分成兩個部分:
一部分是模型 Restore 時變量本身 Tensor 的分配,這個是在加載模型時分配的,內(nèi)存的釋放是在模型被卸載的時候
一部分是 RPC 請求時網(wǎng)絡(luò)前向計算時的中間輸出Tensor 內(nèi)存分配,在請求處理結(jié)束后就被釋放
模型更新時,新模型加載時的 Restore OP 有大量的內(nèi)存被分配,舊模型被卸載時的有很多對象被析構(gòu),大量內(nèi)存被釋放。
而這個過程中,RPC 請求沒有中斷,這個時候兩者的內(nèi)存分配和釋放會產(chǎn)生沖突和競爭關(guān)系。
因此設(shè)計了內(nèi)存分配隔離方案:
將模型本身參數(shù)的內(nèi)存分配和 RPC 請求過程中的內(nèi)存分配隔離開來,讓它們的分配和釋放在不同的內(nèi)存空間。
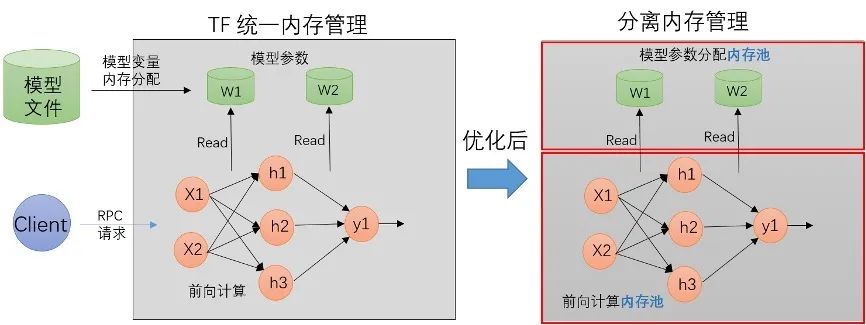
結(jié)合模型的更新,線上模型一個容器里面最多就兩個版本的模型文件,給每個模型版本各自分配了獨(dú)立的內(nèi)存池,用來做 AB 切換。
在代碼的編寫上,TF 剛好有一個現(xiàn)成的 BFC 內(nèi)存分配器,利用 BFC 做模型參數(shù)的內(nèi)存分配器,RPC 請求的內(nèi)存分配仍然使用 glibc ptmalloc2 來統(tǒng)一分配,因此最后的設(shè)計是這樣:
代碼改動主要在 TF 的源碼,主要是對 ProcessState,ThreadPoolDevice和 Allocator做了一些改動。
最后來看一下試驗效果:
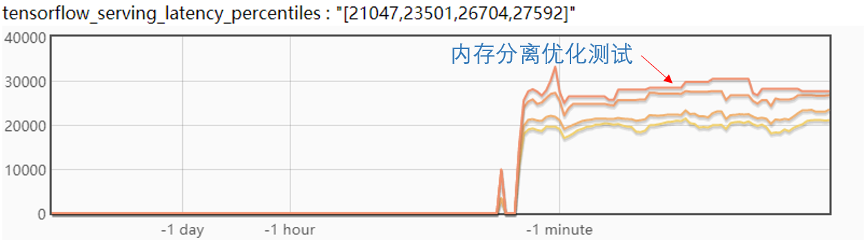
從圖中,可以看到模型更新后,延遲抖動很少,大約在 2ms,在實際的線上測試高峰期大概有 5ms 的抖動,滿足業(yè)務(wù)需求。
總結(jié)
本文介紹了愛奇藝深度學(xué)習(xí)平臺對 TF Serving 毛刺問題的優(yōu)化,主要?dú)w納如下:
配置模型 Warmup 文件來初預(yù)熱模型
使用 Jemalloc 做內(nèi)存分配優(yōu)化
TF 模型參數(shù)分配和 RPC 請求內(nèi)存分配分離
經(jīng)過實踐,每個方法都有進(jìn)一步的優(yōu)化,最后基本解決了模型熱更新過程中的毛刺問題。
— 參考文獻(xiàn) —
1. TF ServingAarchtecture
https://github.com/tensorflow/serving/blob/master/tensorflow_serving/g3doc/architecture.md
2. BVar
https://github.com/apache/incubator-brpc/blob/master/docs/cn/bvar.md
3. TF WarmUp
https://tensorflow.google.cn/tfx/serving/saved_model_warmup
4. 美團(tuán)基于 TensorFlow Serving 的深度學(xué)習(xí)在線預(yù)估
https://tech.meituan.com/2018/10/11/tfserving-improve.html
5. Google Tcmalloc
http://goog-perftools.sourceforge.net/doc/tcmalloc.html
6. Facebook Jemalloc: http://jemalloc.net/
責(zé)任編輯:xj
原文標(biāo)題:社區(qū)分享 | TensorFlow Serving 模型更新毛刺的完全優(yōu)化實踐
文章出處:【微信公眾號:TensorFlow】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
毛刺
+關(guān)注
關(guān)注
0文章
29瀏覽量
15680 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5507瀏覽量
121298 -
tensorflow
+關(guān)注
關(guān)注
13文章
329瀏覽量
60544
原文標(biāo)題:社區(qū)分享 | TensorFlow Serving 模型更新毛刺的完全優(yōu)化實踐
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
NPU在深度學(xué)習(xí)中的應(yīng)用
深度學(xué)習(xí)模型的魯棒性優(yōu)化
GPU深度學(xué)習(xí)應(yīng)用案例
AI大模型與深度學(xué)習(xí)的關(guān)系
FPGA做深度學(xué)習(xí)能走多遠(yuǎn)?
深度學(xué)習(xí)算法在嵌入式平臺上的部署
深度學(xué)習(xí)中的時間序列分類方法
深度學(xué)習(xí)與nlp的區(qū)別在哪
深度學(xué)習(xí)中的模型權(quán)重
深度學(xué)習(xí)模型訓(xùn)練過程詳解
深度學(xué)習(xí)的模型優(yōu)化與調(diào)試方法
深度學(xué)習(xí)編譯工具鏈中的核心——圖優(yōu)化
深度解析深度學(xué)習(xí)下的語義SLAM

燧原科技與愛奇藝共同探索生成式AI在泛娛樂行業(yè)的技術(shù)變革
為什么深度學(xué)習(xí)的效果更好?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論