") 二代IPU性能超過GPU且全面支持PyTorch
二代IPU性能超過GPU且全面支持PyTorch
“不管是在今天 GPU 能夠做的事情上,還是 GPU 不能做的事情上,IPU 都有它的價(jià)值點(diǎn)和價(jià)值定位。” 日前,在英國 AI 芯片初創(chuàng)公司 Graphcore 中國區(qū)的媒體溝通會(huì)上,Graphcore 高級副總經(jīng)理兼中國區(qū)總經(jīng)理盧濤和 Graphcore 中國工程總負(fù)責(zé)人、AI 算法科學(xué)家金琛,就 Graphcore 的新產(chǎn)品性能以及該公司在中國的落地策略向 DeepTech 等媒體進(jìn)行了同步。
溝通會(huì)上,Graphcore 解讀了其于本月公布的大規(guī)模系統(tǒng)級產(chǎn)品 IPU-M2000 的應(yīng)用測試數(shù)據(jù)。公布數(shù)據(jù)顯示,在典型 CV 模型 ResNet、基于分組卷積的 ResNeXt、EfficientNet、語音模型、BERT-Large 等自然語言處理模型以及 MCMC 等傳統(tǒng)機(jī)器學(xué)習(xí)模型中,IPU-M2000 在吞吐量、訓(xùn)練時(shí)間和學(xué)習(xí)結(jié)果生成時(shí)間方面都有較好表現(xiàn)。比如,在 IPU-M2000 上 EfficientNet 的吞吐量達(dá)到 A100 的 18 倍。
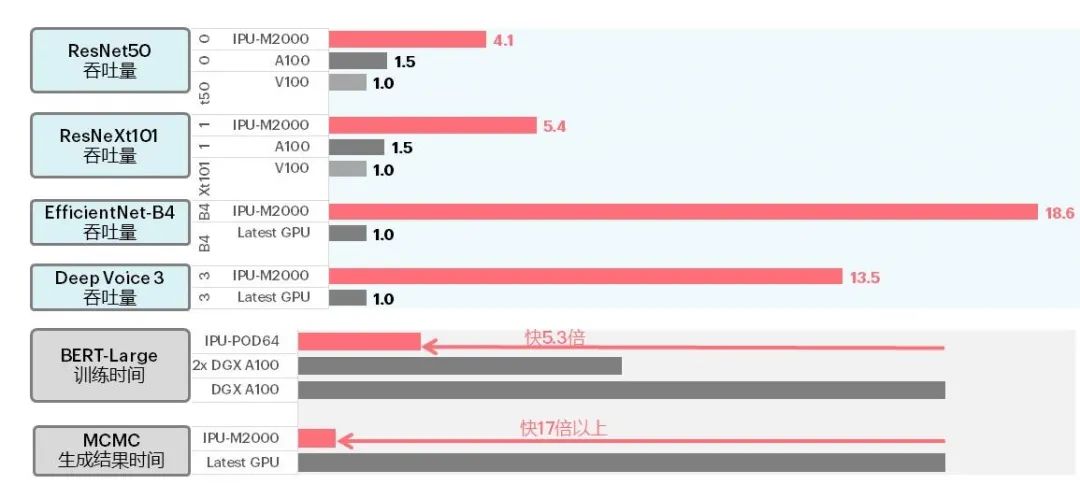
圖 | IPU-M2000 與 GPU 的吞吐量、訓(xùn)練及結(jié)果生成時(shí)間對比(來源:Graphcore)
此前,IPU-M2000 與 Graphcore 第二代 IPU 處理器 GC200 已于今年 7 月 15 日發(fā)布。據(jù)介紹,GC200 芯片基于臺積電的 7nm 工藝制造,集成 250 TFlops AI-Float 算力和 900MB 處理器內(nèi)存,相較第一代產(chǎn)品性能提升 8 倍。而對于第三代 IPU,盧濤在此次溝通會(huì)上并未透露發(fā)布的具體時(shí)間表,不過他表示下一代產(chǎn)品正在研發(fā)中,將依舊重點(diǎn)解決存儲(chǔ)問題。
支持 PyTorch、TensorFlow,在 IPU 與 GPU 間無縫銜接
另外,Graphcore 還發(fā)布了 Poplar SDK 1.4 版本和 PyTorch 的 IPU 版本。
Graphcore 對 Poplar SDK 1.4 版本在易用性和速度上進(jìn)行了優(yōu)化,能夠支持模型和數(shù)據(jù)并行,同時(shí)能夠?qū)崿F(xiàn)模型的橫向擴(kuò)展 —— 從 1 個(gè) IPU 橫向擴(kuò)展到 64 個(gè) IPU。金琛表示,下一版本的 Poplar SDK 有望實(shí)現(xiàn)橫向擴(kuò)展到 128 個(gè) IPU。
值得關(guān)注的是,除支持 Graphcore 的自研框架 PopART 外,Poplar SDK 1.4 還支持 Facebook 的 PyTorch 框架、以及 Google 的 TensorFlow 框架。
據(jù)金琛介紹,Graphcore 在 PyTorch 代碼中引入了 PopTorch 輕量級接口,通過這一接口,用戶可基于當(dāng)前的 PyTorch 模型進(jìn)行封裝,以實(shí)現(xiàn) IPU 和 CPU 之間的無障礙銜接。
對于實(shí)現(xiàn)這一功能的核心技術(shù),金琛做進(jìn)一步解釋說,Graphcore 采用 PyTorch 里的 jit.trace 機(jī)制對計(jì)算圖進(jìn)行編譯,轉(zhuǎn)化為 IPU 和 PyTorch 兼容的表達(dá)格式,最后用 Graphcore 自研框架 PopART 后端的 audiff 功能自動(dòng)生成反向圖,便可以實(shí)現(xiàn)同一個(gè)模型在不同平臺的無差別運(yùn)行。
目前,PyTorch 因其直觀易懂、靈活易用等優(yōu)勢受到開發(fā)者的廣泛喜愛和應(yīng)用。Poplar SDK 1.4 增加了對 PyTorch 的支持,策略上是希望用戶在 IPU 上也能體驗(yàn) PyTorch,讓用戶多一個(gè)轉(zhuǎn)戰(zhàn) IPU 的理由。不過目前英偉達(dá)的 GPU 已經(jīng)在 AI 計(jì)算領(lǐng)域占據(jù)大部分市場,此時(shí) IPU 能夠提供的價(jià)值、轉(zhuǎn)場到 IPU 的成本等,都是用戶所要考慮的問題。
在遷移成本上,盧濤表示,經(jīng)過幾年來對 Poplar SDK 的打磨,現(xiàn)在從 GPU 到 IPU 的軟硬件遷移難度已經(jīng)比大家認(rèn)為的小得多。
金琛補(bǔ)充道,在訓(xùn)練上,針對一個(gè)不太復(fù)雜的模型,一般一周可以遷移完成,對于復(fù)雜的模型大概需要兩周;在推理上,基本上是 1-2 天的工作量。
談及性能,盧濤表示:“IPU 在訓(xùn)練推理、語音、圖像模型處理上基本全面超越 GPU。” 不過他也坦言:“不能說 100% 超越了 GPU,因?yàn)樗惴P痛_實(shí)非常多,比如說語音有不同的語音模型、圖像也是有不同的圖像模型。”
未來:持續(xù)優(yōu)化性能,進(jìn)一步壓縮遷移成本
IPU 在機(jī)器學(xué)習(xí)性能上的明顯優(yōu)勢是不可否認(rèn)的,但前有身強(qiáng)體壯且努力奔跑的巨頭英偉達(dá),Graphcore 更是一刻也不容懈怠。盧濤在溝通會(huì)上也多次提到,“目前 Graphcore 面對的壓力最主要還是來自英偉達(dá)”。
“重壓” 之下,Graphcore 短期內(nèi)的計(jì)劃是聚焦在數(shù)據(jù)中心高性能訓(xùn)練和推理市場上,持續(xù)打磨 IPU 和軟件平臺,持續(xù)優(yōu)化性能和提高可用性。盧濤說,“只有在我們聚焦的領(lǐng)域跑得更快,Graphcore 和英偉達(dá)之間的距離才會(huì)越來越短,甚至在某些領(lǐng)域超過英偉達(dá)”。
他還表示,Graphcore 希望未來數(shù)年內(nèi),能在數(shù)據(jù)中心的 AI 訓(xùn)練、推理批量部署、以及發(fā)貨和體量上做到除英偉達(dá)以外的另一個(gè)頭部地位。
為實(shí)現(xiàn)該目標(biāo),Graphcore 也將從增加 AI 框架支持、以及模型覆蓋兩個(gè)維度著手,以期進(jìn)一步減少用戶的遷移成本。此外,除目前 AI 應(yīng)用最廣泛的互聯(lián)網(wǎng)和云計(jì)算兩個(gè)場景外,盧濤表示公司明年還將在金融、汽車、智慧醫(yī)療、智慧教育、智慧城市和政府服務(wù)等領(lǐng)域,至少突破一到兩個(gè)比較主流的領(lǐng)域。
原文標(biāo)題:二代IPU性能超過GPU、全面支持PyTorch,Graphcore接下來將聚焦數(shù)據(jù)中心的AI訓(xùn)練和推理部署
文章出處:【微信公眾號:DeepTech深科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
gpu
+關(guān)注
關(guān)注
28文章
4744瀏覽量
129018 -
AI
+關(guān)注
關(guān)注
87文章
31028瀏覽量
269381 -
IPU
+關(guān)注
關(guān)注
0文章
34瀏覽量
15576 -
pytorch
+關(guān)注
關(guān)注
2文章
808瀏覽量
13246
原文標(biāo)題:二代IPU性能超過GPU、全面支持PyTorch,Graphcore接下來將聚焦數(shù)據(jù)中心的AI訓(xùn)練和推理部署
文章出處:【微信號:deeptechchina,微信公眾號:deeptechchina】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論