") C++內(nèi)存管理詳細(xì)介紹
C++內(nèi)存管理詳細(xì)介紹
引言
說到 C++ 的內(nèi)存管理,我們可能會(huì)想到棧空間的本地變量、堆上通過 new 動(dòng)態(tài)分配的變量以及全局命名空間的變量等,這些變量的分配位置都是由系統(tǒng)來控制管理的,而調(diào)用者只需要考慮變量的生命周期相關(guān)內(nèi)容即可,而無需關(guān)心變量的具體布局。這對(duì)于普通軟件的開發(fā)已經(jīng)足夠,但對(duì)于引擎開發(fā)而言,我們必須對(duì)內(nèi)存有著更為精細(xì)的管理。
基礎(chǔ)概念
在文章的開篇,先對(duì)一些基礎(chǔ)概念進(jìn)行簡單的介紹,以便能夠更好地理解后續(xù)的內(nèi)容。
內(nèi)存布局
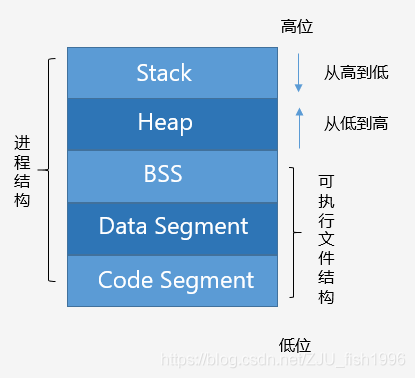
內(nèi)存分布(可執(zhí)行映像)
如圖,描述了C++程序的內(nèi)存分布。
Code Segment(代碼區(qū))
也稱Text Segment,存放可執(zhí)行程序的機(jī)器碼。
Data Segment (數(shù)據(jù)區(qū))
存放已初始化的全局和靜態(tài)變量, 常量數(shù)據(jù)(如字符串常量)。
BSS(Block started by symbol)
存放未初始化的全局和靜態(tài)變量。(默認(rèn)設(shè)為0)
Heap(堆)
從低地址向高地址增長。容量大于棧,程序中動(dòng)態(tài)分配的內(nèi)存在此區(qū)域。
Stack(棧)
從高地址向低地址增長。由編譯器自動(dòng)管理分配。程序中的局部變量、函數(shù)參數(shù)值、返回變量等存在此區(qū)域。
函數(shù)棧
如上圖所示,可執(zhí)行程序的文件包含BSS,Data Segment和Code Segment,當(dāng)可執(zhí)行程序載入內(nèi)存后,系統(tǒng)會(huì)保留一些空間,即堆區(qū)和棧區(qū)。堆區(qū)主要是動(dòng)態(tài)分配的內(nèi)存(默認(rèn)情況下),而棧區(qū)主要是函數(shù)以及局部變量等(包括main函數(shù))。一般而言,棧的空間小于堆的空間。
當(dāng)調(diào)用函數(shù)時(shí),一塊連續(xù)內(nèi)存(堆棧幀)壓入棧;函數(shù)返回時(shí),堆棧幀彈出。
堆棧幀包含如下數(shù)據(jù):
① 函數(shù)返回地址
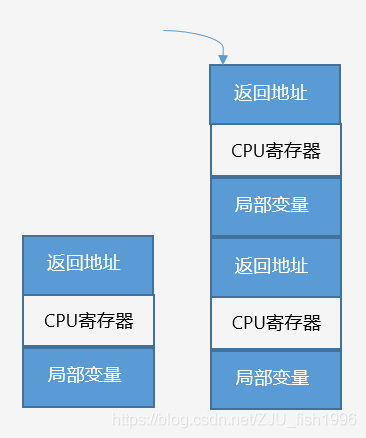
函數(shù)壓棧
全局變量
當(dāng)全局/靜態(tài)變量(如下代碼中的x和y變量)未初始化的時(shí)候,它們記錄在BSS段。
intx;
intz=5;
voidfunc()
{
staticinty;
}
intmain()
{
return0;
}
處于BSS段的變量的值默認(rèn)為0,考慮到這一點(diǎn),BSS段內(nèi)部無需存儲(chǔ)大量的零值,而只需記錄字節(jié)個(gè)數(shù)即可。
系統(tǒng)載入可執(zhí)行程序后,將BSS段的數(shù)據(jù)載入數(shù)據(jù)段(Data Segment) ,并將內(nèi)存初始化為0,再調(diào)用程序入口(main函數(shù))。
而對(duì)于已經(jīng)初始化了的全局/靜態(tài)變量而言,如以上代碼中的z變量,則一直存儲(chǔ)于數(shù)據(jù)段(Data Segment)。
內(nèi)存對(duì)齊
對(duì)于基礎(chǔ)類型,如float, double, int, char等,它們的大小和內(nèi)存占用是一致的。而對(duì)于結(jié)構(gòu)體而言,如果我們?nèi)〉闷鋝izeof的結(jié)果,會(huì)發(fā)現(xiàn)這個(gè)值有可能會(huì)大于結(jié)構(gòu)體內(nèi)所有成員大小的總和,這是由于結(jié)構(gòu)體內(nèi)部成員進(jìn)行了內(nèi)存對(duì)齊。
為什么要進(jìn)行內(nèi)存對(duì)齊
① 內(nèi)存對(duì)齊使數(shù)據(jù)讀取更高效
在硬件設(shè)計(jì)上,數(shù)據(jù)讀取的處理器只能從地址為k的倍數(shù)的內(nèi)存處開始讀取數(shù)據(jù)。這種讀取方式相當(dāng)于將內(nèi)存分為了多個(gè)"塊“,假設(shè)內(nèi)存可以從任意位置開始存放的話,數(shù)據(jù)很可能會(huì)被分散到多個(gè)“塊”中,處理分散在多個(gè)塊中的數(shù)據(jù)需要移除首尾不需要的字節(jié),再進(jìn)行合并,非常耗時(shí)。
為了提高數(shù)據(jù)讀取的效率,程序分配的內(nèi)存并不是連續(xù)存儲(chǔ)的,而是按首地址為k的倍數(shù)的方式存儲(chǔ);這樣就可以一次性讀取數(shù)據(jù),而不需要額外的操作。

讀取非對(duì)齊內(nèi)存的過程示例
② 在某些平臺(tái)下,不進(jìn)行內(nèi)存對(duì)齊會(huì)崩潰
內(nèi)存對(duì)齊的規(guī)則
定義有效對(duì)齊值(alignment)為結(jié)構(gòu)體中 最寬成員 和 編譯器/用戶指定對(duì)齊值 中較小的那個(gè)。
(1) 結(jié)構(gòu)體起始地址為有效對(duì)齊值的整數(shù)倍
(2) 結(jié)構(gòu)體總大小為有效對(duì)齊值的整數(shù)倍
(3) 結(jié)構(gòu)體第一個(gè)成員偏移值為0,之后成員的偏移值為 min(有效對(duì)齊值, 自身大小) 的整數(shù)倍
相當(dāng)于每個(gè)成員要進(jìn)行對(duì)齊,并且整個(gè)結(jié)構(gòu)體也需要進(jìn)行對(duì)齊。
示例
structA
{
inti;
charc1;
charc2;
};
intmain()
{
cout<sizeof(A)<endl;//有效對(duì)齊值為4,output:8
return0;
}
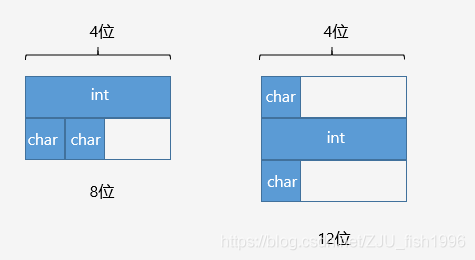
內(nèi)存排布示例
內(nèi)存碎片
程序的內(nèi)存往往不是緊湊連續(xù)排布的,而是存在著許多碎片。我們根據(jù)碎片產(chǎn)生的原因把碎片分為內(nèi)部碎片和外部碎片兩種類型:
(1) 內(nèi)部碎片:系統(tǒng)分配的內(nèi)存大于實(shí)際所需的內(nèi)存(由于對(duì)齊機(jī)制);
(2) 外部碎片:不斷分配回收不同大小的內(nèi)存,由于內(nèi)存分布散亂,較大內(nèi)存無法分配;

內(nèi)部碎片和外部碎片
為了提高內(nèi)存的利用率,我們有必要減少內(nèi)存碎片,具體的方案將在后文重點(diǎn)介紹。
繼承類布局
繼承
如果一個(gè)類繼承自另一個(gè)類,那么它自身的數(shù)據(jù)位于父類之后。
含虛函數(shù)的類
如果當(dāng)前類包含虛函數(shù),則會(huì)在類的最前端占用4個(gè)字節(jié),用于存儲(chǔ)虛表指針(vpointer),它指向一個(gè)虛函數(shù)表(vtable)。
vtable中包含當(dāng)前類的所有虛函數(shù)指針。
字節(jié)序(endianness)
大于一個(gè)字節(jié)的值被稱為多字節(jié)量,多字節(jié)量存在高位有效字節(jié)和低位有效字節(jié) (關(guān)于高位和低位,我們以十進(jìn)制的數(shù)字來舉例,對(duì)于數(shù)字482來說,4是高位,2是低位),微處理器有兩種不同的順序處理高位和低位字節(jié)的順序:
● 小端(little_endian):低位有效字節(jié)存儲(chǔ)于較低的內(nèi)存位置
● 大端(big_endian):高位有效字節(jié)存儲(chǔ)于較低的內(nèi)存位置
我們使用的PC開發(fā)機(jī)默認(rèn)是小端存儲(chǔ)。
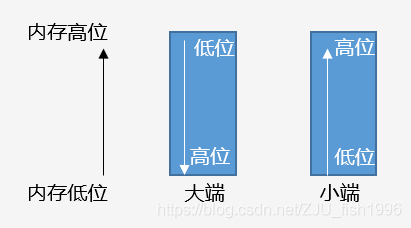
大小端排布
一般情況下,多字節(jié)量的排列順序?qū)幋a沒有影響。但如果要考慮跨平臺(tái)的一些操作,就有必要考慮到大小端的問題。如下圖,ue4引擎使用了PLATFORM_LITTLE_ENDIAN這一宏,在不同平臺(tái)下對(duì)數(shù)據(jù)做特殊處理(內(nèi)存排布交換,確保存儲(chǔ)時(shí)的結(jié)果一致)。
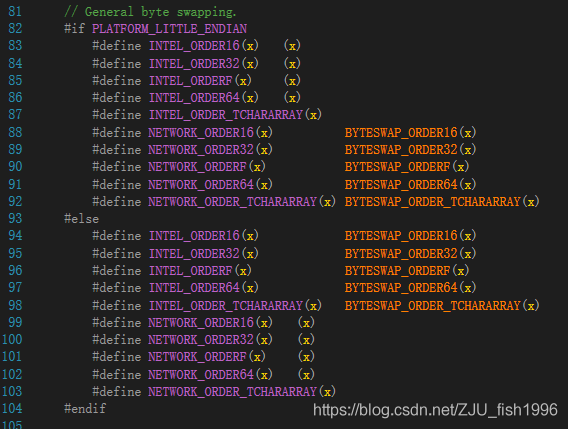
ue4針對(duì)大小端對(duì)數(shù)據(jù)做特殊處理(ByteSwap.h)
操作系統(tǒng)
對(duì)一些基礎(chǔ)概念有所了解后,我們可以來關(guān)注操作系統(tǒng)底層的一些設(shè)計(jì)。在掌握了這些特性后,我們才能更好地針對(duì)性地編寫高性能代碼。
SIMD
SIMD,即Single Instruction Multiple Data,用一個(gè)指令并行地對(duì)多個(gè)數(shù)據(jù)進(jìn)行運(yùn)算,是CPU基本指令集的擴(kuò)展。
例一
處理器的寄存器通常是32位或者64位的,而圖像的一個(gè)像素點(diǎn)可能只有8bit,如果一次只能處理一個(gè)數(shù)據(jù)比較浪費(fèi)空間;此時(shí)可以將64位寄存器拆成8個(gè)8位寄存器,就可以并行完成8個(gè)操作,提升效率。
例二
SSE指令采用128位寄存器,我們通常將4個(gè)32位浮點(diǎn)值打包到128位寄存器中,單個(gè)指令可完成4對(duì)浮點(diǎn)數(shù)的計(jì)算,這對(duì)于矩陣/向量操作非常友好(除此之外,還有Neon/FPU等寄存器)
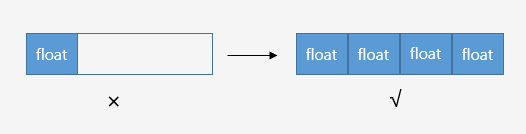
SIMD并行計(jì)算
高速緩存
一般來說CPU以超高速運(yùn)行,而內(nèi)存速度慢于CPU,硬盤速度慢于內(nèi)存。
當(dāng)我們把數(shù)據(jù)加載內(nèi)存后,要對(duì)數(shù)據(jù)進(jìn)行一定操作時(shí),會(huì)將數(shù)據(jù)從內(nèi)存載入CPU寄存器。考慮到CPU讀/寫主內(nèi)存速度較慢,處理器使用了高速的緩存(Cache),作為內(nèi)存到CPU中間的媒介。
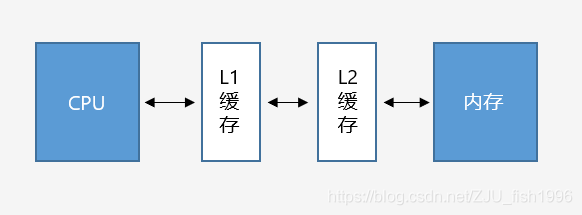
L1緩存和L2緩存
引入L1和L2緩存后,CPU和內(nèi)存之間的將無法進(jìn)行直接的數(shù)據(jù)交互,而是需要經(jīng)過兩級(jí)緩存(目前也已出現(xiàn)L3緩存)。
① CPU請(qǐng)求數(shù)據(jù):如果數(shù)據(jù)已經(jīng)在緩存中,則直接從緩存載入寄存器;如果數(shù)據(jù)不在緩存中(緩存命中失敗),則需要從內(nèi)存讀取,并將內(nèi)存載入緩存中。
② CPU寫入數(shù)據(jù):有兩種方案,(1) 寫入到緩存時(shí)同步寫入內(nèi)存(write through cache) (2) 僅寫入到緩存中,有必要時(shí)再寫入內(nèi)存(write-back)
為了提高程序性能,則需要盡可能避免緩存命中失敗。一般而言,遵循盡可能地集中連續(xù)訪問內(nèi)存,減少”跳變“訪問的原則(locality of reference)。這里其實(shí)隱含了兩個(gè)意思,一個(gè)是內(nèi)存空間上要盡可能連續(xù),另外一個(gè)是訪問時(shí)序上要盡可能連續(xù)。像節(jié)點(diǎn)式的數(shù)據(jù)結(jié)構(gòu)的遍歷就會(huì)差于內(nèi)存連續(xù)性的容器。
虛擬內(nèi)存
虛擬內(nèi)存,也就是把不連續(xù)的物理內(nèi)存塊映射到虛擬地址空間(virtual address space)。使內(nèi)存頁對(duì)于應(yīng)用程序來說看起來是連續(xù)的。一般而言,出于程序安全性和物理內(nèi)存可能不足的考慮,我們的程序都會(huì)運(yùn)行在虛擬內(nèi)存上。
這意味著,每個(gè)程序都有自己的地址空間,我們使用的內(nèi)存存在一個(gè)虛擬地址和一個(gè)物理地址,兩者之間需要進(jìn)行地址翻譯。
缺頁
在虛擬內(nèi)存中,每個(gè)程序的地址空間被劃分為多個(gè)塊,每個(gè)內(nèi)存塊被稱作頁,每個(gè)頁的包含了連續(xù)的地址,并且被映射到物理內(nèi)存。并非所有頁都在物理內(nèi)存中,當(dāng)我們?cè)L問了不在物理內(nèi)存中的頁時(shí),這一現(xiàn)象稱為缺頁,操作系統(tǒng)會(huì)從磁盤將對(duì)應(yīng)內(nèi)容裝載到物理內(nèi)存;當(dāng)內(nèi)存不足,部分頁也會(huì)寫回磁盤。
在這里,我們將CPU,高速緩存和主存視為一個(gè)整體,統(tǒng)稱為DRAM。由于DRAM與磁盤之間的讀寫也比較耗時(shí),為了提高程序性能,我們依然需要確保自己的程序具有良好的“局部性”——在任意時(shí)刻都在一個(gè)較小的活動(dòng)頁面上工作。
分頁
當(dāng)使用虛擬內(nèi)存時(shí),會(huì)通過MMU將虛擬地址映射到物理內(nèi)存,虛擬內(nèi)存的內(nèi)存塊稱為頁,而物理內(nèi)存中的內(nèi)存塊稱為頁框,兩者大小一致,DRAM和磁盤之間以頁為單位進(jìn)行交換。
簡單來說,如果想要從虛擬內(nèi)存翻譯到物理地址,首先會(huì)從一個(gè)TLB(Translation Lookaside Buffer)的設(shè)備中查找,如果找不到,在虛擬地址中也記錄了虛擬頁號(hào)和偏移量,可以先通過虛擬頁號(hào)找到頁框號(hào),再通過偏移量在對(duì)應(yīng)頁框進(jìn)行偏移,得到物理地址。為了加速這個(gè)翻譯過程,有時(shí)候還會(huì)使用多級(jí)頁表,倒排頁表等結(jié)構(gòu)。
置換算法
到目前為止,我們已經(jīng)接觸了不少和“置換”有關(guān)的內(nèi)容:例如寄存器和高速緩存之間,DRAM和磁盤之間,以及TLB的緩存等。這個(gè)問題的本質(zhì)是,我們?cè)谟邢薜目臻g內(nèi)存儲(chǔ)了一些快速查詢的結(jié)構(gòu),但是我們無法存儲(chǔ)所有的數(shù)據(jù),所以當(dāng)查詢未命中時(shí),就需要花更大的代價(jià),而所謂置換,也就是我們的快速查詢結(jié)構(gòu)是在不斷更新的,會(huì)隨著我們的操作,使得一部分?jǐn)?shù)據(jù)被裝在到快速查詢結(jié)構(gòu)中,又有另一部分?jǐn)?shù)據(jù)被卸載,相當(dāng)于完成了數(shù)據(jù)的置換。
常見的置換有如下幾種:
● 最近未使用置換(NRU)
出現(xiàn)未命中現(xiàn)象時(shí),置換最近一個(gè)周期未使用的數(shù)據(jù)。
● 先入先出置換(FIFO)
出現(xiàn)未命中現(xiàn)象時(shí),置換最早進(jìn)入的數(shù)據(jù)。
● 最近最少使用置換(LRU)
出現(xiàn)未命中現(xiàn)象時(shí),置換未使用時(shí)間最長的數(shù)據(jù)。
C++語法
位域(Bit Fields)
表示結(jié)構(gòu)體位域的定義,指定變量所占位數(shù)。它通常位于成員變量后,用 聲明符:常量表達(dá)式 表示。(參考資料)
聲明符是可選的,匿名字段可用于填充。
以下是ue4中Float16的定義:
struct
{
#ifPLATFORM_LITTLE_ENDIAN
uint16Mantissa:10;
uint16Exponent:5;
uint16Sign:1;
#else
uint16Sign:1;
uint16Exponent:5;
uint16Mantissa:10;
#endif
}Components;
new和placement new
new是C++中用于動(dòng)態(tài)內(nèi)存分配的運(yùn)算符,它主要完成了以下兩個(gè)操作:
① 調(diào)用operator new()函數(shù),動(dòng)態(tài)分配內(nèi)存。
② 在分配的動(dòng)態(tài)內(nèi)存塊上調(diào)用構(gòu)造函數(shù),以初始化相應(yīng)類型的對(duì)象,并返回首地址。
當(dāng)我們調(diào)用new時(shí),會(huì)在堆中查找一個(gè)足夠大的剩余空間,分配并返回;當(dāng)我們調(diào)用delete時(shí),則會(huì)將該內(nèi)存標(biāo)記為不再使用,而指針仍然執(zhí)行原來的內(nèi)存。
new的語法
::(optional)new(placement_params)(optional)(type)initializer(optional)
● 一般表達(dá)式
p_var=newtype(initializer);//p_var=newtype{initializer};
● 對(duì)象數(shù)組表達(dá)式
p_var=newtype[size];//分配
delete[]p_var;//釋放
● 二維數(shù)組表達(dá)式
autop=newdouble[2][2];
autop=newdouble[2][2]{{1.0,2.0},{3.0,4.0}};
● 不拋出異常的表達(dá)式
new(nothrow)Type(optional-initializer-expression-list)
默認(rèn)情況下,如果內(nèi)存分配失敗,new運(yùn)算符會(huì)選擇拋出std::bad_alloc異常,如果加入nothrow,則不拋出異常,而是返回nullptr。
● 占位符類型
我們可以使用placeholder type(如auto/decltype)指定類型:
autop=newauto('c');
● 帶位置的表達(dá)式(placement new)
可以指定在哪塊內(nèi)存上構(gòu)造類型。
它的意義在于我們可以利用placement new將內(nèi)存分配和構(gòu)造這兩個(gè)模塊分離(后續(xù)的allocator更好地踐行了這一概念),這對(duì)于編寫內(nèi)存管理的代碼非常重要,比如當(dāng)我們想要編寫內(nèi)存池的代碼時(shí),可以預(yù)申請(qǐng)一塊內(nèi)存,然后通過placement new申請(qǐng)對(duì)象,一方面可以避免頻繁調(diào)用系統(tǒng)new/delete帶來的開銷,另一方面可以自己控制內(nèi)存的分配和釋放。
預(yù)先分配的緩沖區(qū)可以是堆或者棧上的,一般按字節(jié)(char)類型來分配,這主要考慮了以下兩個(gè)原因:
① 方便控制分配的內(nèi)存大小(通過sizeof計(jì)算即可)
② 如果使用自定義類型,則會(huì)調(diào)用對(duì)應(yīng)的構(gòu)造函數(shù)。但是既然要做分配和構(gòu)造的分離,我們實(shí)際上是不期望它做任何構(gòu)造操作的,而且對(duì)于沒有默認(rèn)構(gòu)造函數(shù)的自定義類型,我們是無法預(yù)分配緩沖區(qū)的。
以下是一個(gè)使用的例子:
classA
{
private:
intdata;
public:
A(intindata)
:data(indata){}
voidprint()
{
cout<endl;
}
};
intmain()
{
constintsize=10;
charbuf[size*sizeof(A)];//內(nèi)存分配
for(size_ti=0;inew(buf+i*sizeof(A))A(i);//對(duì)象構(gòu)造
}
A*arr=(A*)buf;
for(size_ti=0;i//對(duì)象析構(gòu)
}
//棧上預(yù)分配的內(nèi)存自動(dòng)釋放
return0;
}
和數(shù)組越界訪問不一定崩潰類似,這里如果在未分配的內(nèi)存上執(zhí)行placement new,可能也不會(huì)崩潰。
● 自定義參數(shù)的表達(dá)式
當(dāng)我們調(diào)用new時(shí),實(shí)際上執(zhí)行了operator new運(yùn)算符表達(dá)式,和其它函數(shù)一樣,operator new有多種重載,如上文中的placement new,就是operator new以下形式的一個(gè)重載:

placement new的定義
新語法(C++17)還支持帶對(duì)齊的operator new:
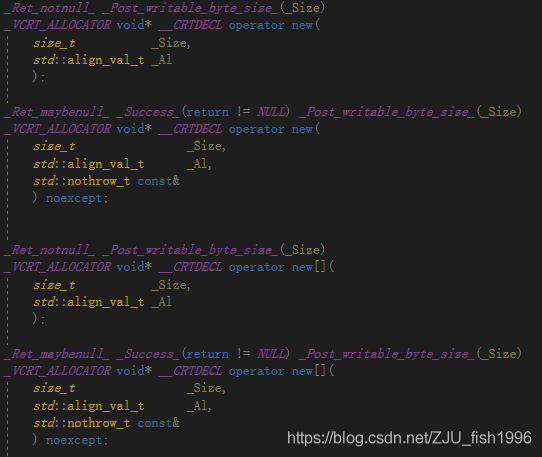
aligned new的聲明
調(diào)用示例:
autop=new(std::align_val_t{32})A;
new的重載
在C++中,我們一般說new和delete動(dòng)態(tài)分配和釋放的對(duì)象位于自由存儲(chǔ)區(qū)(free store),這是一個(gè)抽象概念。默認(rèn)情況下,C++編譯器會(huì)使用堆實(shí)現(xiàn)自由存儲(chǔ)。
前文已經(jīng)提及了new的幾種重載,包括數(shù)組,placement,align等。
如果我們想要實(shí)現(xiàn)自己的內(nèi)存分配自定義操作,我們可以有如下兩個(gè)方式:
① 編寫重載的operator new,這意味著我們的參數(shù)需要和全局operator new有差異。
② 重定義operator new,根據(jù)名字查找規(guī)則,會(huì)優(yōu)先在申請(qǐng)內(nèi)存的數(shù)據(jù)內(nèi)部/數(shù)據(jù)定義處查找new運(yùn)算符,未找到才會(huì)調(diào)用全局::operator new()。
需要注意的是,如果該全局operator new已經(jīng)實(shí)現(xiàn)為inline函數(shù),則我們不能重定義相關(guān)函數(shù),否則無法通過編譯,如下:
//Defaultplacementversionsofoperatornew.
inlinevoid*operatornew(std::size_t,void*__p)throw(){return__p;}
inlinevoid*operatornew[](std::size_t,void*__p)throw(){return__p;}
//Defaultplacementversionsofoperatordelete.
inlinevoidoperatordelete(void*,void*)throw(){}
inlinevoidoperatordelete[](void*,void*)throw(){}
但是,我們可以重寫如下nothrow的operator new:
void*operatornew(std::size_t,conststd::nothrow_t&)throw();
void*operatornew[](std::size_t,conststd::nothrow_t&)throw();
voidoperatordelete(void*,conststd::nothrow_t&)throw();
voidoperatordelete[](void*,conststd::nothrow_t&)throw();
為什么說new是低效的
① 一般來說,操作越簡單,意味著封裝了更多的實(shí)現(xiàn)細(xì)節(jié)。new作為一個(gè)通用接口,需要處理任意時(shí)間、任意位置申請(qǐng)任意大小內(nèi)存的請(qǐng)求,它在設(shè)計(jì)上就無法兼顧一些特殊場景的優(yōu)化,在管理上也會(huì)帶來一定開銷。
② 系統(tǒng)調(diào)用帶來的開銷。多數(shù)操作系統(tǒng)上,申請(qǐng)內(nèi)存會(huì)從用戶模式切換到內(nèi)核模式,當(dāng)前線程會(huì)block住,上下文切換將會(huì)消耗一定時(shí)間。
③ 分配可能是帶鎖的。這意味著分配難以并行化。
alignas和alignof
不同的編譯器一般都會(huì)有默認(rèn)的對(duì)齊量,一般都為2的冪次。
在C中,我們可以通過預(yù)編譯命令修改對(duì)齊量:
#pragmapack(n)
在內(nèi)存對(duì)齊篇已經(jīng)提及,我們最終的有效對(duì)齊量會(huì)取結(jié)構(gòu)體最寬成員 和 編譯器默認(rèn)對(duì)齊量(或我們自己定義的對(duì)齊量)中較小的那個(gè)。
C++中也提供了類似的操作:
alignas
用于指定對(duì)齊量。
可以應(yīng)用于類/結(jié)構(gòu)體/union/枚舉的聲明/定義;非位域的成員變量的定義;變量的定義(除了函數(shù)參數(shù)或異常捕獲的參數(shù));
alignas會(huì)對(duì)對(duì)齊量做檢查,對(duì)齊量不能小于默認(rèn)對(duì)齊,如下面的代碼,struct U的對(duì)齊設(shè)置是錯(cuò)誤的:
structalignas(8)S
{
//...
};
structalignas(1)U
{
Ss;
};
以下對(duì)齊設(shè)置也是錯(cuò)誤的:
structalignas(2)S{
intn;
};
此外,一些錯(cuò)誤的格式也無法通過編譯,如:
structalignas(3)S{};
例子:
//everyobjectoftypesse_twillbealignedto16-byteboundary
structalignas(16)sse_t
{
floatsse_data[4];
};
//thearray"cacheline"willbealignedto128-byteboundary
alignas(128)
charcacheline[128];
alignof operator
返回類型的std::size_t。如果是引用,則返回引用類型的對(duì)齊方式,如果是數(shù)組,則返回元素類型的對(duì)齊方式。
例子:
structFoo{
inti;
floatf;
charc;
};
structEmpty{};
structalignas(64)Empty64{};
intmain()
{
std::cout<"Alignmentof""
"
"-char:"<alignof(char)<"
"//1
"-pointer:"<alignof(int*)<"
"//8
"-classFoo:"<alignof(Foo)<"
"//4
"-emptyclass:"<alignof(Empty)<"
"//1
"-alignas(64)Empty:"<alignof(Empty64)<"
";//64
}
std::max_align_t
一般為16bytes,malloc返回的內(nèi)存地址,對(duì)齊大小不能小于max_align_t。
allocator
當(dāng)我們使用C++的容器時(shí),我們往往需要提供兩個(gè)參數(shù),一個(gè)是容器的類型,另一個(gè)是容器的分配器。其中第二個(gè)參數(shù)有默認(rèn)參數(shù),即C++自帶的分配器(allocator):
templateclassT,classAlloc=allocator>classvector;//generictemplate
我們可以實(shí)現(xiàn)自己的allocator,只需實(shí)現(xiàn)分配、構(gòu)造等相關(guān)的操作。在此之前,我們需要先對(duì)allocator的使用做一定的了解。
new操作將內(nèi)存分配和對(duì)象構(gòu)造組合在一起,而allocator的意義在于將內(nèi)存分配和構(gòu)造分離。這樣就可以分配大塊內(nèi)存,而只在真正需要時(shí)才執(zhí)行對(duì)象創(chuàng)建操作。
假設(shè)我們先申請(qǐng)n個(gè)對(duì)象,再根據(jù)情況逐一給對(duì)象賦值,如果內(nèi)存分配和對(duì)象構(gòu)造不分離可能帶來的弊端如下:
① 我們可能會(huì)創(chuàng)建一些用不到的對(duì)象;
② 對(duì)象被賦值兩次,一次是默認(rèn)初始化時(shí),一次是賦值時(shí);
③ 沒有默認(rèn)構(gòu)造函數(shù)的類甚至不能動(dòng)態(tài)分配數(shù)組;
使用allocator之后,我們便可以解決上述問題。
分配
為n個(gè)string分配內(nèi)存:
allocator<string>alloc;//構(gòu)造allocator對(duì)象
autoconstp=alloc.allocate(n);//分配n個(gè)未初始化的string
構(gòu)造
在剛才分配的內(nèi)存上構(gòu)造兩個(gè)string:
autoq=p;
alloc.construct(q++,"hello");//在分配的內(nèi)存處創(chuàng)建對(duì)象
alloc.construct(q++,10,'c');
銷毀
將已構(gòu)造的string銷毀:
while(q!=p)
alloc.destroy(--q);
釋放
將分配的n個(gè)string內(nèi)存空間釋放:
alloc.deallocate(p,n);
注意:傳遞給deallocate的指針不能為空,且必須指向由allocate分配的內(nèi)存,并保證大小參數(shù)一致。
拷貝和填充
uninitialized_copy(b,e,b2)
//從迭代器b, e 中的元素拷貝到b2指定的未構(gòu)造的原始內(nèi)存中;
uninitialized_copy(b,n,b2)
//從迭代器b指向的元素開始,拷貝n個(gè)元素到b2開始的內(nèi)存中;
uninitialized_fill(b,e,t)
//從迭代器b和e指定的原始內(nèi)存范圍中創(chuàng)建對(duì)象,對(duì)象的值均為t的拷貝;
uninitialized_fill_n(b,n,t)
//從迭代器b指向的內(nèi)存地址開始創(chuàng)建n個(gè)對(duì)象;
為什么stl的allocator并不好用
如果仔細(xì)觀察,我們會(huì)發(fā)現(xiàn)很多商業(yè)引擎都沒有使用stl中的容器和分配器,而是自己實(shí)現(xiàn)了相應(yīng)的功能。這意味著allocator無法滿足某些引擎開發(fā)一些定制化的需求:
① allocator內(nèi)存對(duì)齊無法控制
② allocator難以應(yīng)用內(nèi)存池之類的優(yōu)化機(jī)制
③ 綁定模板簽名
shared_ptr, unique_ptr和weak_ptr
智能指針是針對(duì)裸指針可能出現(xiàn)的問題封裝的指針類,它能夠更安全、更方便地使用動(dòng)態(tài)內(nèi)存。
shared_ptr
shared_ptr的主要應(yīng)用場景是當(dāng)我們需要在多個(gè)類中共享指針時(shí)。
多個(gè)類共享指針存在這么一個(gè)問題:每個(gè)類都存儲(chǔ)了指針地址的一個(gè)拷貝,如果其中一個(gè)類刪除了這個(gè)指針,其它類并不知道這個(gè)指針已經(jīng)失效,此時(shí)就會(huì)出現(xiàn)野指針的現(xiàn)象。為了解決這一問題,我們可以使用引用指針來計(jì)數(shù),僅當(dāng)檢測(cè)到引用計(jì)數(shù)為0時(shí),才主動(dòng)刪除這個(gè)數(shù)據(jù),以上就是shared_ptr的工作原理。
shared_ptr的基本語法如下:
初始化
shared_ptr<int>p=make_shared<int>(42);
拷貝和賦值
autop=make_shared<int>(42);
autor=make_shared<int>(42);
r=q;//遞增q指向的對(duì)象,遞減r指向的對(duì)象
只支持直接初始化
由于接受指針參數(shù)的構(gòu)造函數(shù)是explicit的,因此不能將指針隱式轉(zhuǎn)換為shared_ptr:
shared_ptr<int>p1=newint(1024);//err
shared_ptr<int>p2(newint(1024));//ok
不與普通指針混用
(1) 通過get()函數(shù),我們可以獲取原始指針,但我們不應(yīng)該delete這一指針,也不應(yīng)該用它賦值/初始化另一個(gè)智能指針;
(2) 當(dāng)我們將原生指針傳給shared_ptr后,就應(yīng)該讓shared_ptr接管這一指針,而不再直接操作原生指針。
重新賦值
p.reset(newint(1024));
unique_ptr
有時(shí)候我們會(huì)在函數(shù)域內(nèi)臨時(shí)申請(qǐng)指針,或者在類中聲明非共享的指針,但我們很有可能忘記刪除這個(gè)指針,造成內(nèi)存泄漏。此時(shí)我們可以考慮使用unique_ptr,由名字可見,某一時(shí)刻只有一個(gè)unique_ptr指向給定的對(duì)象,且它會(huì)在析構(gòu)的時(shí)候自動(dòng)釋放對(duì)應(yīng)指針的內(nèi)存。
unique_ptr的基本語法如下:
初始化
unique_ptr<string>p=make_unique<string>("test");
不支持直接拷貝/賦值
為了確保某一時(shí)刻只有一個(gè)unique_ptr指向給定對(duì)象,unique_ptr不支持普通的拷貝或賦值。
unique_ptr<string>p1(newstring("test"));
unique_ptr<string>p2(p1);//err
unique_ptr<string>p3;
p3=p2;//err
所有權(quán)轉(zhuǎn)移
可以通過調(diào)用release或reset將指針的所有權(quán)在unique_ptr之間轉(zhuǎn)移:
unique_ptr<string>p2(p1.release());
unique_ptr<string>p3(newstring("test"));
p2.reset(p3.release());
不能忽視r(shí)elease返回的結(jié)果
release返回的指針通常用來初始化/賦值另一個(gè)智能指針,如果我們只調(diào)用release,而沒有刪除其返回值,會(huì)造成內(nèi)存泄漏:
p2.release();//err
autop=p2.release();//ok,butremembertodelete(p)
支持移動(dòng)
unique_ptr<int>clone(intp){
returnunique_ptr<int>(newint(p));
}
weak_ptr
weak_ptr不控制所指向?qū)ο蟮纳嫫冢床粫?huì)影響引用計(jì)數(shù)。它指向一個(gè)shared_ptr管理的對(duì)象。通常而言,它的存在有如下兩個(gè)作用:
(1) 解決循環(huán)引用的問題
(2) 作為一個(gè)“觀察者”:
詳細(xì)來說,和之前提到的多個(gè)類共享內(nèi)存的例子一樣,使用普通指針可能會(huì)導(dǎo)致一個(gè)類刪除了數(shù)據(jù)后其它類無法同步這一信息,導(dǎo)致野指針;之前我們提出了shared_ptr,也就是每個(gè)類記錄一個(gè)引用,釋放時(shí)引用數(shù)減一,直到減為0才釋放。
但在有些情況下,我們并不希望當(dāng)前類影響到引用計(jì)數(shù),而是希望實(shí)現(xiàn)這樣的邏輯:假設(shè)有兩個(gè)類引用一個(gè)數(shù)據(jù),其中有一個(gè)類將主動(dòng)控制類的釋放,而無需等待另外一個(gè)類也釋放才真正銷毀指針?biāo)笇?duì)象。對(duì)于另一個(gè)類而言,它只需要知道這個(gè)指針已經(jīng)失效即可,此時(shí)我們就可以使用weak_ptr。
我們可以像如下這樣檢測(cè)weak_ptr所有對(duì)象是否有效,并在有效的情況下做相關(guān)操作:
autop=make_shared<int>(42);
weak_ptr<int>wp(p);
if(shared_ptr<int>np=wp.lock())
{
//...
}
分配與管理機(jī)制
到目前為止,我們對(duì)內(nèi)存的概念有了初步的了解,也掌握了一些基本的語法。接下來我們要討論如何進(jìn)行有效的內(nèi)存管理。
設(shè)計(jì)高效的內(nèi)存分配器通常會(huì)考慮到以下幾點(diǎn):
① 盡可能減少內(nèi)存碎片,提高內(nèi)存利用率
② 盡可能提高內(nèi)存的訪問局部性
③ 設(shè)計(jì)在不同場合上適用的內(nèi)存分配器
④ 考慮到內(nèi)存對(duì)齊
含freelist的分配器
我們首先來考慮一種能夠處理任何請(qǐng)求的通用分配器。
一個(gè)非常樸素的想法是,對(duì)于釋放的內(nèi)存,通過鏈表將空閑內(nèi)存鏈接起來,稱為freelist。
分配內(nèi)存時(shí),先從freelist中查找是否存在滿足要求的內(nèi)存塊,如果不存在,再從未分配內(nèi)存中獲取;當(dāng)我們找到合適的內(nèi)存塊后,分配合適的內(nèi)存,并將多余的部分放回freelist。
釋放內(nèi)存時(shí),將內(nèi)存插入到空閑鏈表,可能的話,合并前后內(nèi)存塊。
其中,有一些細(xì)節(jié)問題值得考慮:
① 空閑空間應(yīng)該如何進(jìn)行管理?
我們知道freelist是用于管理空閑內(nèi)存的,但是freelist本身的存儲(chǔ)也需要占用內(nèi)存。我們可以按如下兩種方式存儲(chǔ)freelist:
● 隱式空閑鏈表
將空閑鏈表信息與內(nèi)存塊存儲(chǔ)在一起。主要記錄大小,已分配位等信息。
● 顯式空閑鏈表
單獨(dú)維護(hù)一塊空間來記錄所有空閑塊信息。
● 分離適配(segregated-freelist)
將不同大小的內(nèi)存塊放在一起容易造成外部碎片,可以設(shè)置多個(gè)freelist,并讓每個(gè)freelist存儲(chǔ)不同大小的內(nèi)存塊,申請(qǐng)內(nèi)存時(shí)選擇滿足條件的最小內(nèi)存塊。
● 位圖
除了freelist之外,還可以考慮用0,1表示對(duì)應(yīng)內(nèi)存區(qū)域是否已分配,稱為位圖。
② 分配內(nèi)存優(yōu)先分配哪塊內(nèi)存?
一般而言,從策略不同來分,有以下幾種常見的分配方式:
● 首次適應(yīng)(first-fit):找到的第一個(gè)滿足大小要求的空閑區(qū)
● 最佳適應(yīng)(best-fit) : 滿足大小要求的最小空閑區(qū)
● 循環(huán)首次適應(yīng)(next-fit) :在先前停止搜索的地方開始搜索找到的第一個(gè)滿足大小要求的空閑區(qū)
③ 釋放內(nèi)存后如何放置到空閑鏈表中?
● 直接放回鏈表頭部/尾部
● 按照地址順序放回
這幾種策略本質(zhì)上都是取舍問題:分配/放回時(shí)間復(fù)雜度如果低,內(nèi)存碎片就有可能更多,反之亦然。
buddy分配器
按照一分為二,二分為四的原則,直到分裂出一個(gè)滿足大小的內(nèi)存塊;合并的時(shí)候看buddy是否空閑,如果是就合并。
可以通過位運(yùn)算直接算出buddy,buddy的buddy,速度較快。但內(nèi)存碎片較多。
含對(duì)齊的分配器
一般而言,對(duì)于通用分配器來說,都應(yīng)當(dāng)傳回對(duì)齊的內(nèi)存塊,即根據(jù)對(duì)齊量,分配比請(qǐng)求多的對(duì)齊的內(nèi)存。
如下,是ue4中計(jì)算對(duì)齊的方式,它返回和對(duì)齊量向上對(duì)齊后的值,其中Alignment應(yīng)為2的冪次。
template<typenameT>
FORCEINLINEconstexprTAlign(TVal,uint64Alignment)
{
static_assert(TIsIntegral::Value||TIsPointer::Value,"Alignexpectsanintegerorpointertype");
return(T)(((uint64)Val+Alignment-1)&~(Alignment-1));
}
其中~(Alignment - 1) 代表的是高位掩碼,類似于11110000的格式,它將剔除低位。在對(duì)Val進(jìn)行掩碼計(jì)算時(shí),加上Alignment - 1的做法類似于(x + a) % a,避免Val值過小得到0的結(jié)果。
單幀分配器模型
用于分配一些臨時(shí)的每幀生成的數(shù)據(jù)。分配的內(nèi)存僅在當(dāng)前幀適用,每幀開始時(shí)會(huì)將上一幀的緩沖數(shù)據(jù)清除,無需手動(dòng)釋放。
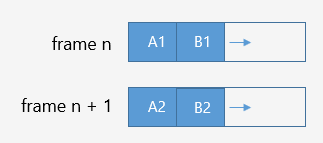
雙幀分配器模型
它的基本特點(diǎn)和單幀分配器相近,區(qū)別在于第i+1幀適用第i幀分配的內(nèi)存。它適用于處理非同步的一些數(shù)據(jù),避免當(dāng)前緩沖區(qū)被重寫(同時(shí)讀寫)
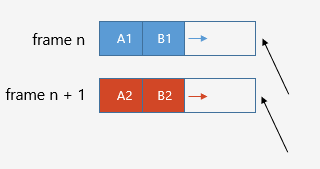
堆棧分配器模型
堆棧分配器,它的優(yōu)點(diǎn)是實(shí)現(xiàn)簡單,并且完全避免了內(nèi)存碎片,如前文所述,函數(shù)棧的設(shè)計(jì)也使用了堆棧分配器的模型。
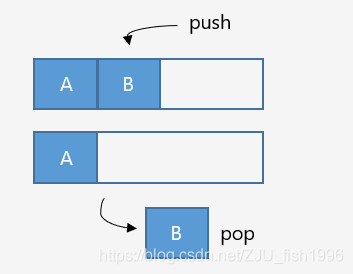
堆棧分配器
雙端堆棧分配器模型
可以從兩端開始分配內(nèi)存,分別用于處理不同的事務(wù),能夠更充分地利用內(nèi)存。
雙端堆棧分配器
池分配器模型
池分配器可以分配大量同尺寸的小塊內(nèi)存。它的空閑塊也是由freelist管理的,但由于每個(gè)塊的尺寸一致,它的操作復(fù)雜度更低,且也不存在內(nèi)存碎片的問題。
tcmalloc的內(nèi)存分配
tcmalloc是一個(gè)應(yīng)用比較廣泛的內(nèi)存分配第三方庫。
對(duì)于大于頁結(jié)構(gòu)和小于頁結(jié)構(gòu)的內(nèi)存塊申請(qǐng),tcmalloc分別做不同的處理。
小于頁的內(nèi)存塊分配
使用多個(gè)內(nèi)存塊定長的freelist進(jìn)行內(nèi)存分配,如:8,16,32……,對(duì)實(shí)際申請(qǐng)的內(nèi)存向上“取整”。
freelist采用隱式存儲(chǔ)的方式。
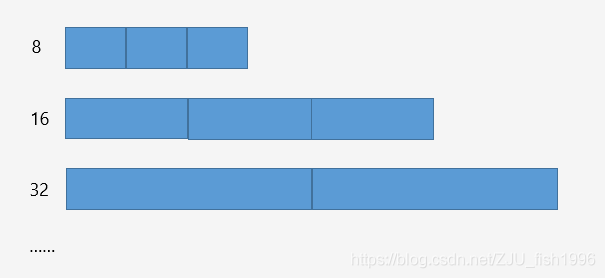
多個(gè)定長的freelist
大于頁的內(nèi)存塊分配
可以一次申請(qǐng)多個(gè)page,多個(gè)page構(gòu)成一個(gè)span。同樣的,我們使用多個(gè)定長的span鏈表來管理不同大小的span。
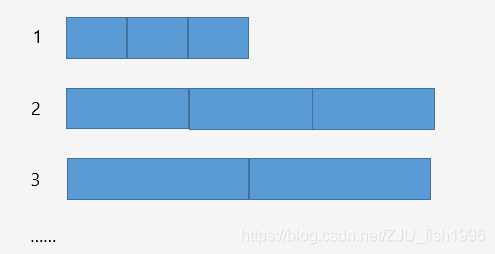
多個(gè)定長的spanlist
對(duì)于不同大小的對(duì)象,都有一個(gè)對(duì)應(yīng)的內(nèi)存分配器,稱為CentralCache。具體的數(shù)據(jù)都存儲(chǔ)在span內(nèi),每個(gè)CentralCache維護(hù)了對(duì)應(yīng)的spanlist。如果一個(gè)span可以存儲(chǔ)多個(gè)對(duì)象,spanlist內(nèi)部還會(huì)維護(hù)對(duì)應(yīng)的freelist。
容器的訪問局部性
由于操作系統(tǒng)內(nèi)部存在緩存命中的問題,所以我們需要考慮程序的訪問局部性,這個(gè)訪問局部性實(shí)際上有兩層意思:
(1) 時(shí)間局部性:如果當(dāng)前數(shù)據(jù)被訪問,那么它將在不久后很可能在此被訪問;
(2) 空間局部性:如果當(dāng)前數(shù)據(jù)被訪問,那么它相鄰位置的數(shù)據(jù)很可能也被訪問;
我們來認(rèn)識(shí)一下常用的幾種容器的內(nèi)存布局:
數(shù)組/順序容器:內(nèi)存連續(xù),訪問局部性良好;
map:內(nèi)部是樹狀結(jié)構(gòu),為節(jié)點(diǎn)存儲(chǔ),無法保證內(nèi)存連續(xù)性,訪問局部性較差(flat_map支持順序存儲(chǔ));
鏈表:初始狀態(tài)下,如果我們連續(xù)順序插入節(jié)點(diǎn),此時(shí)我們認(rèn)為內(nèi)存連續(xù),訪問較快;但通過多次插入、刪除、交換等操作,鏈表結(jié)構(gòu)變得散亂,訪問局部性較差;
碎片整理機(jī)制
內(nèi)存碎片幾乎是不可完全避免的,當(dāng)一個(gè)程序運(yùn)行一定時(shí)間后,將會(huì)出現(xiàn)越來越多的內(nèi)存碎片。一個(gè)優(yōu)化的思路就是在引擎底層支持定期地整理內(nèi)存碎片。
簡單來說,碎片整理通過不斷的移動(dòng)操作,使所有的內(nèi)存塊“貼合”在一起。為了處理指針可能失效的問題,可以考慮使用智能指針。
由于內(nèi)存碎片整理會(huì)造成卡頓,我們可以考慮將整理操作分?jǐn)偟蕉鄮瓿伞?/p>
ue4內(nèi)存管理
自定義內(nèi)存管理

ue4的內(nèi)存管理主要是通過FMalloc類型的GMalloc這一結(jié)構(gòu)來完成特定的需求,這是一個(gè)虛基類,它定義了malloc,realloc,free等一系列常用的內(nèi)存管理操作。其中,Malloc的兩個(gè)參數(shù)分別是分配內(nèi)存的大小和對(duì)應(yīng)的對(duì)齊量,默認(rèn)對(duì)齊量為0。
/**Theglobalmemoryallocator'sinterface.*/
classCORE_APIFMalloc:
publicFUseSystemMallocForNew,
publicFExec
{
public:
virtualvoid*Malloc(SIZE_TCount,uint32Alignment=DEFAULT_ALIGNMENT)=0;
virtualvoid*TryMalloc(SIZE_TCount,uint32Alignment=DEFAULT_ALIGNMENT);
virtualvoid*Realloc(void*Original,SIZE_TCount,uint32Alignment=DEFAULT_ALIGNMENT)=0;
virtualvoid*TryRealloc(void*Original,SIZE_TCount,uint32Alignment=DEFAULT_ALIGNMENT);
virtualvoidFree(void*Original)=0;
//...
};
FMalloc有許多不同的實(shí)現(xiàn),如FMallocBinned,F(xiàn)MallocBinned2等,可以在HAL文件夾下找到相關(guān)的頭文件和定義,如下:
內(nèi)部通過枚舉量來確定對(duì)應(yīng)使用的Allocator:
/**Whichallocatorisbeingused*/
enumEMemoryAllocatorToUse
{
Ansi,//DefaultCallocator
Stomp,//Allocatortocheckformemorystomping
TBB,//ThreadBuildingBlocksmalloc
Jemalloc,//Linux/FreeBSDmalloc
Binned,//Olderbinnedmalloc
Binned2,//Newerbinnedmalloc
Binned3,//NewerVM-basedbinnedmalloc,64bitonly
Platform,//Customplatformspecificallocator
Mimalloc,//mimalloc
};
對(duì)于不同平臺(tái)而言,都有自己對(duì)應(yīng)的平臺(tái)內(nèi)存管理類,它們繼承自FGenericPlatformMemory,封裝了平臺(tái)相關(guān)的內(nèi)存操作。具體而言,包含F(xiàn)AndroidPlatformMemory,F(xiàn)ApplePlatformMemory,F(xiàn)IOSPlatformMemory,F(xiàn)WindowsPlatformMemory等。
通過調(diào)用PlatformMemory的BaseAllocator函數(shù),我們?nèi)〉闷脚_(tái)對(duì)應(yīng)的FMalloc類型,基類默認(rèn)返回默認(rèn)的C allocator,而不同平臺(tái)會(huì)有自己特殊的實(shí)現(xiàn)。
在PlatformMemory的基礎(chǔ)上,為了方便調(diào)用,ue4又封裝了FMemory類,定義通用內(nèi)存操作,如在申請(qǐng)內(nèi)存時(shí),會(huì)調(diào)用FMemory::Malloc,F(xiàn)Memory內(nèi)部又會(huì)繼續(xù)調(diào)用GMalloc->Malloc。如下為節(jié)選代碼:
structCORE_APIFMemory
{
/**@nameMemoryfunctions(wrapperforFPlatformMemory)*/
staticFORCEINLINEvoid*Memmove(void*Dest,constvoid*Src,SIZE_TCount)
{
returnFPlatformMemory::Memmove(Dest,Src,Count);
}
staticFORCEINLINEint32Memcmp(constvoid*Buf1,constvoid*Buf2,SIZE_TCount)
{
returnFPlatformMemory::Memcmp(Buf1,Buf2,Count);
}
//...
staticvoid*Malloc(SIZE_TCount,uint32Alignment=DEFAULT_ALIGNMENT);
staticvoid*Realloc(void*Original,SIZE_TCount,uint32Alignment=DEFAULT_ALIGNMENT);
staticvoidFree(void*Original);
staticSIZE_TGetAllocSize(void*Original);
//...
};
為了在調(diào)用new/delete能夠調(diào)用ue4的自定義函數(shù),ue4內(nèi)部替換了operator new。這一替換是通過IMPLEMENT_MODULE宏引入的:

IMPLEMENT_MODULE通過定義REPLACEMENT_OPERATOR_NEW_AND_DELETE宏實(shí)現(xiàn)替換,如下圖所示,operator new/delete內(nèi)實(shí)際調(diào)用被替換為FMemory的相關(guān)函數(shù)。
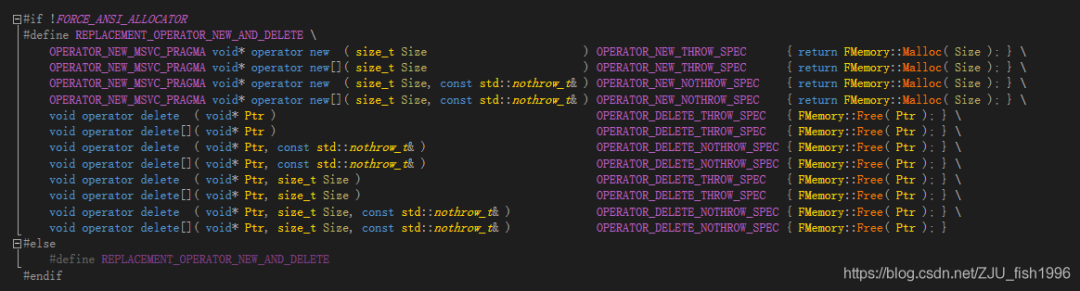
FMallocBinned
我們以FMallocBinned為例介紹ue4中通用內(nèi)存的分配。
基本介紹
(1) 空閑內(nèi)存如何管理?
FMallocBinned使用freelist機(jī)制管理空閑內(nèi)存。每個(gè)空閑塊的信息記錄在FFreeMem結(jié)構(gòu)中,顯式存儲(chǔ)。
(2)不同大小內(nèi)存如何分配?
FMallocBinned使用內(nèi)存池機(jī)制,內(nèi)部包含POOL_COUNT(42)個(gè)內(nèi)存池和2個(gè)擴(kuò)展的頁內(nèi)存池;其中每個(gè)內(nèi)存池的信息由FPoolInfo結(jié)構(gòu)體維護(hù),記錄了當(dāng)前FreeMem內(nèi)存塊指針等,而特定大小的所有內(nèi)存池由FPoolTable維護(hù);內(nèi)存池內(nèi)包含了內(nèi)存塊的雙向鏈表。
(3)如何快速根據(jù)分配元素大小找到對(duì)應(yīng)的內(nèi)存池?
為了快速查詢當(dāng)前分配內(nèi)存大小應(yīng)該對(duì)應(yīng)使用哪個(gè)內(nèi)存池,有兩種辦法,一種是二分搜索O(logN),另一種是打表(O1),考慮到可分配內(nèi)存數(shù)量并不大,MallocBinned選擇了打表的方式,將信息記錄在MemSizeToPoolTable。
(4)如何快速刪除已分配內(nèi)存?
為了能夠在釋放的時(shí)候以O(shè)(1)時(shí)間找到對(duì)應(yīng)內(nèi)存池,F(xiàn)MallocBinned維護(hù)了PoolHashBucket結(jié)構(gòu)用于跟蹤內(nèi)存分配的記錄。它組織為雙向鏈表形式,存儲(chǔ)了對(duì)應(yīng)內(nèi)存塊和鍵值。
內(nèi)存池
● 多個(gè)小對(duì)象內(nèi)存池(內(nèi)存池大小均為PageSize,但存儲(chǔ)的數(shù)據(jù)量不一樣)。數(shù)據(jù)塊大小設(shè)定如下:
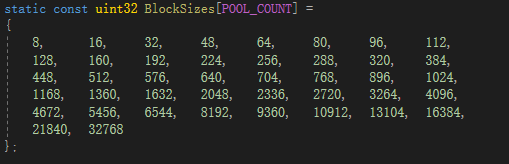
● 兩個(gè)額外的頁內(nèi)存池,管理大于一個(gè)頁的內(nèi)存池,大小為3*PageSize和6*PageSize
● 操作系統(tǒng)的內(nèi)存池
分配策略
分配內(nèi)存的函數(shù)為void* FMallocBinned::Malloc(SIZE_T Size, uint32 Alignment)。
其中第一個(gè)參數(shù)為需要分配的內(nèi)存的大小,第二個(gè)參數(shù)為對(duì)齊的內(nèi)存數(shù)。
如果用戶未指定對(duì)齊的內(nèi)存大小,MallocBinned內(nèi)部會(huì)默認(rèn)對(duì)齊于16字節(jié),如果指定了大于16字節(jié)的對(duì)齊內(nèi)存大小,則對(duì)齊于用戶指定的對(duì)齊大小。根據(jù)對(duì)齊量,計(jì)算出最終實(shí)際分配的內(nèi)存大小。
MallocBinned內(nèi)部對(duì)于不同的內(nèi)存大小有三種不同的處理:
(1) 分配小塊內(nèi)存(0,PAGE_SIZE_LIMIT/2)
根據(jù)分配大小從MemSizeToPoolTable中獲取對(duì)應(yīng)內(nèi)存池,并從內(nèi)存池的當(dāng)前空閑位置讀取一塊內(nèi)存,并移動(dòng)當(dāng)前內(nèi)存指針。如果移動(dòng)后的內(nèi)存指針指向的內(nèi)存塊已經(jīng)使用,則將指針移動(dòng)到FreeMem鏈表的下一個(gè)元素;如果當(dāng)前內(nèi)存池已滿,將該內(nèi)存池移除,并鏈接到耗盡的內(nèi)存池。
如果當(dāng)前內(nèi)存池已經(jīng)用盡,下次內(nèi)存分配時(shí),檢測(cè)到內(nèi)存池用盡,會(huì)從系統(tǒng)重新申請(qǐng)一塊對(duì)應(yīng)大小的內(nèi)存池。
(2) 分配大塊內(nèi)存 [PAGE_SIZE_LIMIT/2, PAGE_SIZE_LIMIT*3/4]∪(PageSize,PageSize + PAGE_SIZE_LIMIT/2)
需要從額外的頁內(nèi)存池分配,分配方式和(1)一樣。
(3) 分配超大內(nèi)存
從系統(tǒng)內(nèi)存池中分配。
Allocator
對(duì)于ue4中的容器而言,它的模板有兩個(gè)參數(shù),第一個(gè)是元素類型,第二個(gè)就是對(duì)應(yīng)的分配器(Allocator):
template<typenameInElementType,typenameInAllocator>
classTArray
{
//...
};
如下圖,容器一般都指定了自己默認(rèn)的分配器:
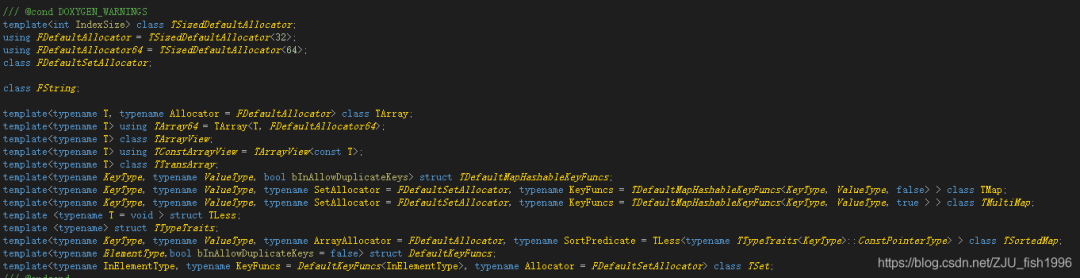
默認(rèn)的堆分配器
template<intIndexSize>
classTSizedHeapAllocator{...};
//DefaultAllocator
usingFHeapAllocator=TSizedHeapAllocator<32>;
默認(rèn)情況下,如果我們不指定特定的Allocator,容器會(huì)使用大小類型為int32堆分配器,默認(rèn)由FMemory控制分配(和new一致)
含對(duì)齊的分配器
template
classTAlignedHeapAllocator
{
//...
};
由FMemory控制分配,含對(duì)齊。
可擴(kuò)展大小的分配器
templatetypenameSecondaryAllocator=FDefaultAllocator>
classTInlineAllocator
{
//...
};
可擴(kuò)展大小的分配器存儲(chǔ)大小為NumInlineElements的定長數(shù)組,當(dāng)實(shí)際存儲(chǔ)的元素?cái)?shù)量高于NumInlineElements時(shí),會(huì)從SecondaryAllocator申請(qǐng)分配內(nèi)存,默認(rèn)情況下為堆分配器。
對(duì)齊量總為DEFAULT_ALIGNMENT。
不可重定位的可擴(kuò)展大小的分配器
template
classTNonRelocatableInlineAllocator
{
//...
};
在支持第二分配器的基礎(chǔ)上,允許第二分配器存儲(chǔ)指向內(nèi)聯(lián)元素的指針。這意味著Allocator不應(yīng)做指針重定向的操作。但ue4的Allocator通常依賴于指針重定向,因此該分配器不應(yīng)用于其它Allocator容器。
固定大小的分配器
template
classTFixedAllocator
{
//...
};
類似于InlineAllocator,會(huì)分配固定大小內(nèi)存,區(qū)別在于當(dāng)內(nèi)聯(lián)存儲(chǔ)耗盡后,不會(huì)提供額外的分配器。
稀疏數(shù)組分配器
template<typenameInElementAllocator=FDefaultAllocator,typenameInBitArrayAllocator=FDefaultBitArrayAllocator>
classTSparseArrayAllocator
{
public:
typedefInElementAllocatorElementAllocator;
typedefInBitArrayAllocatorBitArrayAllocator;
};
稀疏數(shù)組本身的定義比較簡單,它主要用于稀疏數(shù)組(Sparse Array),相關(guān)的操作也在對(duì)應(yīng)數(shù)組類中完成。稀疏數(shù)組支持不連續(xù)的下標(biāo)索引,通過BitArrayAllocator來控制分配哪個(gè)位是可用的,能夠以O(shè)(1)的時(shí)間刪除元素。
默認(rèn)使用堆分配。
哈希分配器
template<
?typenameInSparseArrayAllocator=TSparseArrayAllocator<>,
typenameInHashAllocator=TInlineAllocator<1,FDefaultAllocator>,
uint32AverageNumberOfElementsPerHashBucket=DEFAULT_NUMBER_OF_ELEMENTS_PER_HASH_BUCKET,
uint32BaseNumberOfHashBuckets=DEFAULT_BASE_NUMBER_OF_HASH_BUCKETS,
uint32MinNumberOfHashedElements=DEFAULT_MIN_NUMBER_OF_HASHED_ELEMENTS
>
classTSetAllocator
{
public:
staticFORCEINLINEuint32GetNumberOfHashBuckets(uint32NumHashedElements){//...}
typedefInSparseArrayAllocatorSparseArrayAllocator;
typedefInHashAllocatorHashAllocator;
};
用于TSet/TMap等結(jié)構(gòu)的哈希分配器,同樣的實(shí)現(xiàn)比較簡單,具體的分配策略在TSet等結(jié)構(gòu)中實(shí)現(xiàn)。其中SparseArrayAllocator用于管理Value,HashAllocator用于管理Key。Hash空間不足時(shí),按照2的冪次進(jìn)行擴(kuò)展。
默認(rèn)使用堆分配。
除了使用默認(rèn)的堆分配器,稀疏數(shù)組分配器和哈希分配器都有對(duì)應(yīng)的可擴(kuò)展大小(InlineAllocator)/固定大小(FixedAllocator)分配版本。
動(dòng)態(tài)內(nèi)存管理
TSharedPtr
templateclassObjectType,ESPModeMode>
classTSharedPtr
{
//...
private:
ObjectType*Object;
SharedPointerInternals::FSharedReferencerSharedReferenceCount;
};
TSharedPtr是ue4提供的類似stl sharedptr的解決方案,但相比起stl,它可由第二個(gè)模板參數(shù)控制是否線程安全。
如上所示,它基于類內(nèi)的引用計(jì)數(shù)實(shí)現(xiàn)(SharedReferenceCount),為了確保多個(gè)TSharedPtr能夠同步當(dāng)前引用計(jì)數(shù)的信息,引用計(jì)數(shù)被設(shè)計(jì)為指針類型。在拷貝/構(gòu)造/賦值等操作時(shí),會(huì)增加或減少引用計(jì)數(shù)的值,當(dāng)引用計(jì)數(shù)為0時(shí)將銷毀指針?biāo)笇?duì)象。
TSharedRef
templateclassObjectType,ESPModeMode>
classTSharedRef
{
//...
private:
ObjectType*Object;
SharedPointerInternals::FSharedReferencerSharedReferenceCount;
};
和TSharedPtr類似,但存儲(chǔ)的指針不可為空,創(chuàng)建時(shí)需同時(shí)初始化指針。類似于C++中的引用。
TRefCountPtr
template<typenameReferencedType>
classTRefCountPtr
{
//...
private:
ReferencedType*Reference;
};
TRefCountPtr是基于引用計(jì)數(shù)的共享指針的另一種實(shí)現(xiàn)。和TSharedPtr的差異在于它的引用計(jì)數(shù)并非智能指針類內(nèi)維護(hù)的,而是基于對(duì)象的,相當(dāng)于TRefCountPtr內(nèi)部只存儲(chǔ)了對(duì)應(yīng)的指針信息(ReferencedType* Reference)。
基于對(duì)象的引用計(jì)數(shù),即引用計(jì)數(shù)存儲(chǔ)在對(duì)象內(nèi)部,這是通過從FRefCountBase繼承引入的。這也就意味著TRefCountPtr引用的對(duì)象必須從FRefCountBase繼承,它的使用是有局限性的。
但是在如統(tǒng)計(jì)資源引用而判斷資源是否需要卸載的應(yīng)用場景中,TRefCountPtr可手動(dòng)添加/釋放引用,使用上更友好。
classFRefCountBase
{
public:
//...
private:
mutableint32NumRefs=0;
};
TWeakPtr
templateclassObjectType,ESPModeMode>
classTWeakPtr
{
};
類似的,TWeakObjectPtr是ue4提供的類似stl weakptr的解決方案,它將不影響引用計(jì)數(shù)。
TWeakObjectPtr
template<classT,classTWeakObjectPtrBase>
structTWeakObjectPtr:privateTWeakObjectPtrBase
{
//...
};
structFWeakObjectPtr
{
//...
private:
int32ObjectIndex;
int32ObjectSerialNumber;
};
特別的,由于UObject有對(duì)應(yīng)的gc機(jī)制,TWeakObjectPtr為指向UObject的弱指針,用于查詢對(duì)象是否有效(是否被回收)
垃圾回收
C++語言本身并沒有垃圾回收機(jī)制,ue4基于內(nèi)部的UObject,單獨(dú)實(shí)現(xiàn)了一套GC機(jī)制,此處僅做簡單介紹。
首先,對(duì)于UObject相關(guān)對(duì)象,為了維持引用(防止被回收),通常使用UProperty()宏,使用容器(如TArray存儲(chǔ)),或調(diào)用AddToRoot的方法。
ue4的垃圾回收代碼實(shí)現(xiàn)位于GarbageCollection.cpp中的CollectGarbage函數(shù)中。這一函數(shù)會(huì)在游戲線程中被反復(fù)調(diào)用,要么在一些情況下手動(dòng)調(diào)用,要么在游戲循環(huán)Tick()中滿足條件時(shí)自動(dòng)調(diào)用。
GC過程中,首先會(huì)收集所有不可到達(dá)的對(duì)象(無引用)。
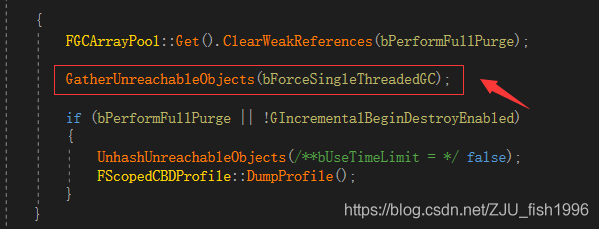
之后,根據(jù)當(dāng)前情況,會(huì)在單幀(無時(shí)間限制)或多幀(有時(shí)間限制)的時(shí)間內(nèi),清理相關(guān)對(duì)象(IncrementalPurgeGarbage)
SIMD
合理的內(nèi)存布局/對(duì)齊有利于SIMD的廣泛應(yīng)用,在編寫定義基礎(chǔ)類型/底層數(shù)學(xué)算法庫時(shí),我們通常有必要考慮到這一點(diǎn)。
我們可以參考ue4中封裝的sse初始化、加法、減法、乘法等操作,其中,__m128類型的變量需程序確保為16字節(jié)對(duì)齊,它適用于浮點(diǎn)數(shù)存儲(chǔ),大部分情況下存儲(chǔ)于內(nèi)存中,計(jì)算時(shí)會(huì)在SSE寄存器中運(yùn)用。
typedef__m128VectorRegister;
FORCEINLINEVectorRegisterVectorLoad(constvoid*Ptr)
{
return_mm_loadu_ps((float*)(Ptr));
}
FORCEINLINEVectorRegisterVectorAdd(constVectorRegister&Vec1,constVectorRegister&Vec2)
{
return_mm_add_ps(Vec1,Vec2);
}
FORCEINLINEVectorRegisterVectorSubtract(constVectorRegister&Vec1,constVectorRegister&Vec2)
{
return_mm_sub_ps(Vec1,Vec2);
}
FORCEINLINEVectorRegisterVectorMultiply(constVectorRegister&Vec1,constVectorRegister&Vec2)
{
return_mm_mul_ps(Vec1,Vec2);
}
除了SSE外,ue4還針對(duì)Neon/FPU等寄存器封裝了統(tǒng)一的接口,這意味調(diào)用者可以無需考慮過多硬件的細(xì)節(jié)。
我們可以在多個(gè)數(shù)學(xué)運(yùn)算庫中看到相關(guān)的調(diào)用,如球諧向量的相加:
/**Additionoperator.*/
friendFORCEINLINETSHVectoroperator+(constTSHVector&A,constTSHVector&B)
{
TSHVectorResult;
for(int32BasisIndex=0;BasisIndexreturnResult;
}
責(zé)任編輯:xj
原文標(biāo)題:做引擎開發(fā),更需要深入 C++ 內(nèi)存管理
文章出處:【微信公眾號(hào):Linux愛好者】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
引擎
+關(guān)注
關(guān)注
1文章
361瀏覽量
22563 -
C++
+關(guān)注
關(guān)注
22文章
2108瀏覽量
73652 -
內(nèi)存管理
+關(guān)注
關(guān)注
0文章
168瀏覽量
14141
原文標(biāo)題:做引擎開發(fā),更需要深入 C++ 內(nèi)存管理
文章出處:【微信號(hào):LinuxHub,微信公眾號(hào):Linux愛好者】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Linux下如何管理虛擬內(nèi)存 使用虛擬內(nèi)存時(shí)的常見問題
C7000優(yōu)化C/C++編譯器

Windows管理內(nèi)存的三種主要方式
使用OpenVINO GenAI API在C++中構(gòu)建AI應(yīng)用程序
【「倉頡編程快速上手」閱讀體驗(yàn)】簡潔包管理的命脈
C++語言基礎(chǔ)知識(shí)
C++中實(shí)現(xiàn)類似instanceof的方法

SEGGER編譯器優(yōu)化和安全技術(shù)介紹 支持最新C和C++語言

鴻蒙OS開發(fā)實(shí)例:【Native C++】
使用 MISRA C++:2023? 避免基于范圍的 for 循環(huán)中的錯(cuò)誤

C語言中的動(dòng)態(tài)內(nèi)存管理講解

c語言,c++,java,python區(qū)別
vb語言和c++語言的區(qū)別
C++簡史:C++是如何開始的





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論