 TVM中schedule介紹
TVM中schedule介紹
作者:安平博,Xilinx高級工程師;來源:AI加速微信公眾號
Schedule是和硬件體系結構相關的一些列優化,Halide在其文章中對其做了以下定義:
1 When and where should be the value at each coordinate in each function be computed?
2 Where should they be stored?
3 How long are values cached and communicated across multiple consumers, and when are they independently recomputed by each?
第一條是描述了數據計算順序對性能的影響,第二條是數據的存儲位置對性能影響,最后一條是多線程處理過程中,不同線程數據應該如何進行交互。
參考文章:https://zhuanlan.zhihu.com/p/94846767,常用的shcedule有:
1 cache_read
將數據存儲到片上緩存,減少訪問數據時間。
2 cache_write
將結果寫入片上緩存,然后再寫入片外緩存。當然這里的片上和片外并不是絕對的概念,也可以理解為不同層次的存儲結構。
3 set_scope
為數據指定存儲位置,相比于cache_read和cache_write提供了更靈活的指定數據存儲方式。本質上是相同的。
4 storage_align
在我看的文章中,storage_align是針對GPU shared memory的一個優化,目的是為了減少同一個bank的訪問沖突。在GPU中shared memory被分割成多個bank,這些bank可以被獨立線程同時訪問。Storage_align就是為了將數據和bank大小匹配,減少bank conflict的發生。AI芯片中也有類似的問題,只有盡量減少bank沖突的發生,才能最大化并行計算。
5 compute_at
不懂CUDA,所以對文章中的代碼不是很理解,但是從其解釋看,對于多次循環的計算(或者多維計算),可以通過并行計算來降維。
6 compute_inline
將獨立操作轉化為內聯函數,有點類似FPGA上的流水線計算。轉化成內聯函數從上層層面減少了stage。在FPGA中也有類似問題,可以將具有相同迭代的多條指令放在一起執行。
7 compute_root
Compute_at的反操作。
8 fuse
將多個循環iter融合為一個iter。
9 split
Fuse的反操作,將一次循環迭代拆分為多次。
10 reorder
調整循環計算迭代順序。
11 tile
Tile也是將循環迭代進行拆分,拆分多次計算。是split+reorder。
12 unroll
將循環展開,增加并發執行。
13 vectorize
將循環迭代替換成ramp,可以通過SIMD指令實現數據批量計算,也就是單指令多數據計算。這在AI加速中會很常用,每條指令都是多數據計算的。
14 bind
CUDA中使用的優化方法,將iter綁定到不同線程,實現并發計算。
15 parallel
實現多設備并行.
16 pragma
可以在代碼中人為添加編譯注釋,人為干預編譯優化。HLS中就是通過這樣的方式來實現c的硬件編程的。
17 prefetch
將數據計算和load后者store數據重疊起來,在FPGA中是很常見優化方法。
18 tensorize
將tensor作為一個整體匹配硬件的計算核心,比如一個卷積運算就可以實現在FPGA上的一個匹配。
文章https://zhuanlan.zhihu.com/p/166551011 是通過官網的一個例子來介紹schedule的。在這個例子中,首先利用te的節點表達式建立了計算函數,然后調用create_schedule來創建schedule實例,然后再調用lower函數實現schedule優化。代碼如下:
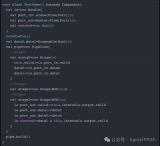
# declare a matrix element-wise multiply A = te.placeholder((m, n), nam) B = te.placeholder((m, n), nam) C = te.compute((m, n), lambda i, j: A[i, j] * B[i, j], nam) s = te.create_schedule([C.op]) # lower will transform the computation from definition to the real # callable function. With argument `simple_mode=True`, it will # return you a readable C like statement, we use it here to print the # schedule result. print(tvm.lower(s, [A, B, C], simple_mode=True))
我這里依然延續上一章的內容,看代碼中關于schedule的處理。
在上一章我們在codegen生成中,通過以下調用鏈轉到了schedule的處理。Codegen -> VisitExpr(CallNode* op) -> relay.backend._CompileEngineLower -> LowerInternal。LowerInternal函數為:
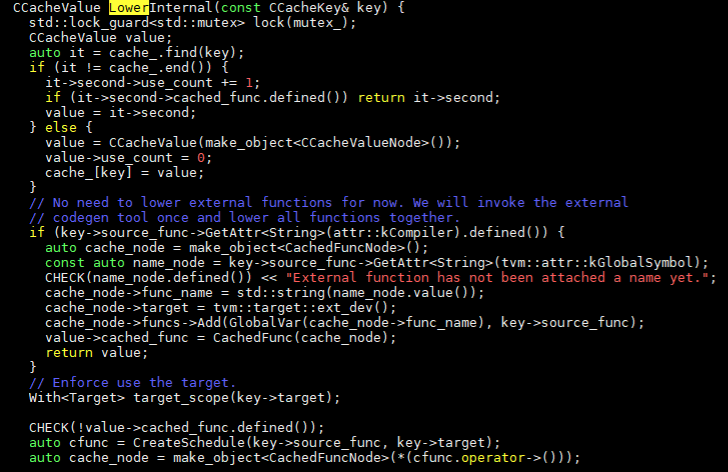
如果是外部定義的編譯器,就只是建立cache_node節點和cache_func。如果是使用內部編譯器,就會調用CreateSchedule建立schedule。接下來調用鏈為CreateSchedule -> ScheduleGetter.create -> te::create_schedule -> Schedule。create_schedule函數調用在文件re/schedule.h和te/schedule_lang.cc中。
create_schedule中主要有兩件工作:
1 創建ReadGraph,獲取post-dfs順序的算符圖。
2 初始化stage。
TVM中引入了stage的概念,一個op相當于一個stage,schedule優化是對stage的一個更改,可以增加,刪減,更改其特性等。
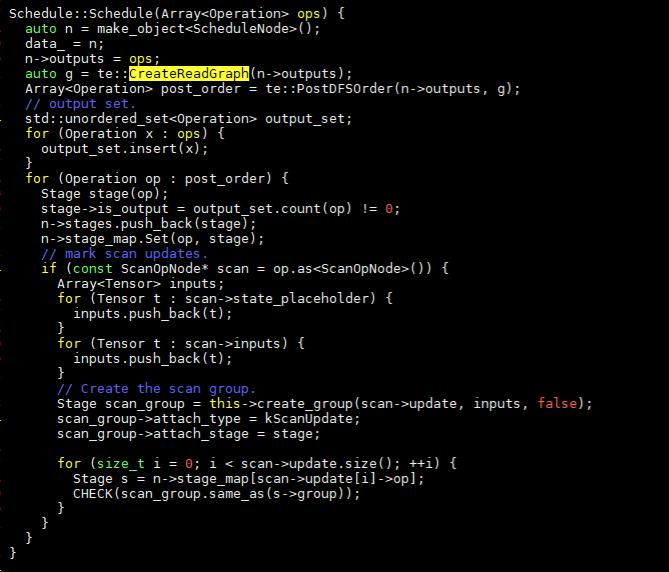
通過createReadGraph可以遍歷op圖,返回op和其依賴的tensor列表。和遍歷有關的主要函數為:
Op -> InputTensors -> PostOrderVisit -> IRApplyVisit,在IRApplyVisit中定義了VisitExpr和VisitStmt函數用于遍歷節點。
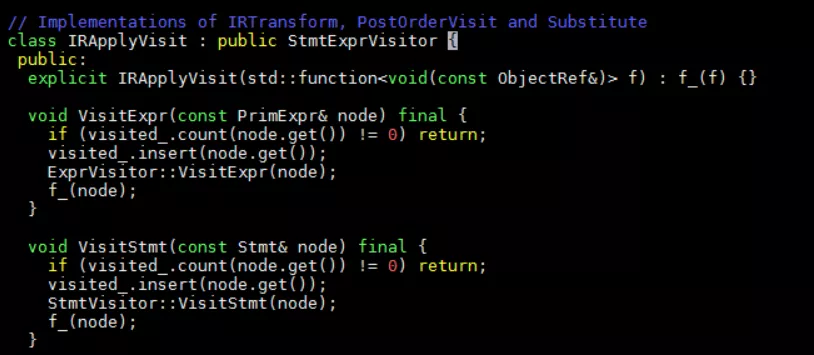
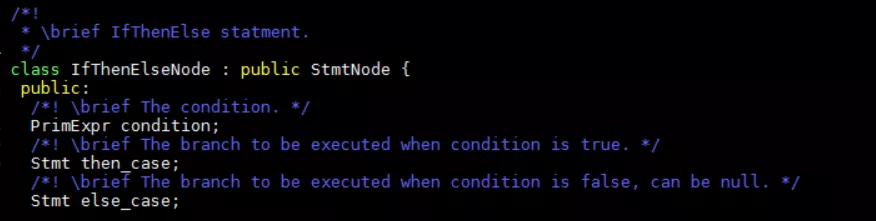
Stmt節點通常是節點中的主體實現,PrimExpr是TIR中節點的一個簡單表達式。比如if節點:
ReadGraph創建完成后,通過PostDFSOrder來獲取post-dfs列表,其函數具體實現在graph.cc中,
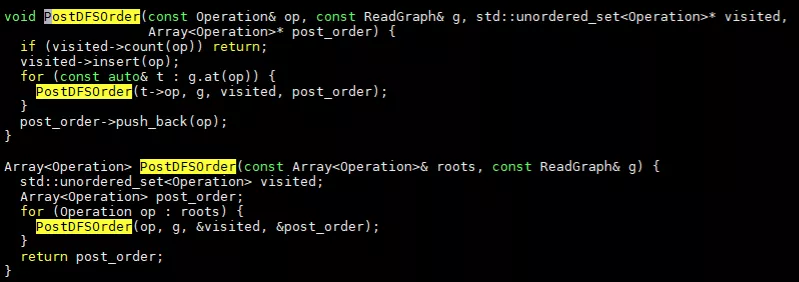
通過不斷迭代來進行深度優先搜索。
接下來是對stage進行初始化。
首先對postorder中的所有op初始化一個stage對象。我們看以下stage的定義:
Stage類中主要定義了set_scope, compute_at, compute_root, bind, split, fuse等幾種優化算法。同時定義了StageNode,在StageNode中定義了和優化相關的變量,包括op,iter變量等。看一下stage初始化代碼:
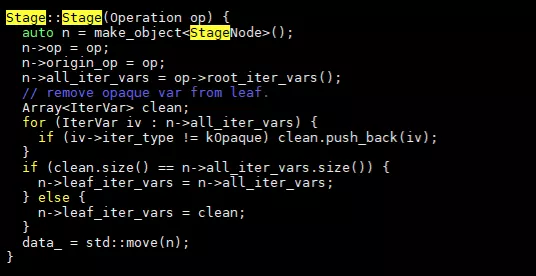
關鍵的幾個變量lef_iter_vars,all_iter_vars,這些有什么作用還需要深入看優化函數的代碼。我們看幾個schedule函數,先看一個最簡單的:compute_inline。代碼只有一行:
(*this)->attach_type = kInline
對于標記了kInline的節點,在lower的時候會進行處理。應該會將其直接和調用的節點結合,合并兩個op。
再看fuse函數,其代碼為:
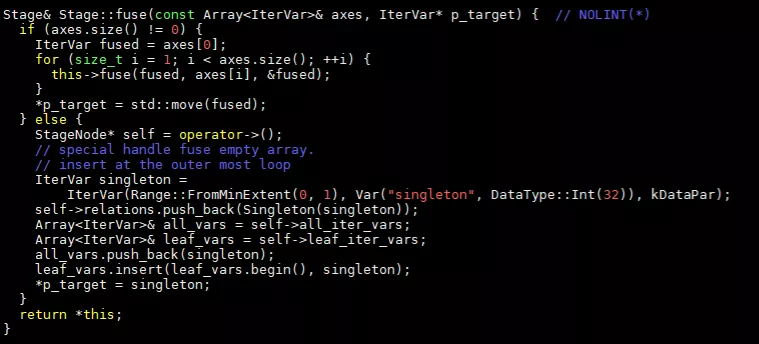
IterVar表示計算中坐標軸,比如一個兩級循環,每級循環就是一個axis。從代碼中看出,fuse函數會對輸入的所有axis進行合并,用fused變量替換合并后的axis。
這塊代碼比較抽象,先熟悉以下流程,之后再深入讀一下。
審核編輯:何安
-
TVM
+關注
關注
0文章
19瀏覽量
3663
發布評論請先 登錄
相關推薦
電子成像中的耦合介紹


SemiDrive X9 AI 開發環境搭建

SDRAM中的active命令介紹
使用TVM量化部署模型報錯NameError: name \'GenerateESPConstants\' is not defined如何解決?
電路中的串聯與并聯介紹

淺析SpinalHDL中Pipeline中的復位定制
介紹智能照明系統在綠色建筑中的應用與產品選型
RT-Thread程序在執行rt_schedule_remove_thread(to_thread);語句里面的打印時會進Hard_defaut的原因?
Proteus元件庫中的電阻元件介紹
AMBA總線中APB slave設計介紹

電源設計中電容的工作原理介紹





 工商網監
工商網監
評論