") 并行循環(huán)冗余校驗(yàn)算法
并行循環(huán)冗余校驗(yàn)算法
作者:劉歡,來(lái)源:網(wǎng)絡(luò)交換FPGA 微信公眾號(hào)
另外,F(xiàn)PGA LUT可編程的內(nèi)容也可以參考本公眾號(hào)之前的文章《【重磅干貨】手把手教你動(dòng)態(tài)編輯Xilinx FPGA內(nèi)LUT內(nèi)容》。
循環(huán)冗余碼校驗(yàn)(CRC)是一種眾所周知的錯(cuò)誤檢測(cè)代碼,已廣泛用于以太網(wǎng),PCIe和其他傳輸協(xié)議中。現(xiàn)有的基于FPGA的實(shí)現(xiàn)解決方案在高性能場(chǎng)景中會(huì)遇到資源過(guò)度利用的問(wèn)題。填充零問(wèn)題和可編程性的引入進(jìn)一步加劇了這個(gè)問(wèn)題。在本文中,提出了stride-by-5算法,以實(shí)現(xiàn)FPGA資源的最佳利用。提出了pipelining go back算法來(lái)解決填充零問(wèn)題。提出了使用HWICAP進(jìn)行重編程的方法,以實(shí)現(xiàn)資源占用少且恒定的可編程性。實(shí)驗(yàn)結(jié)果表明,所提出的非分段架構(gòu)的資源利用率與兩種基于FPGA的最新CRC實(shí)現(xiàn)相比,降低80.7%-87.5%和25.1%-46.2%,并且所提出的分段架構(gòu)具有比兩種最新狀態(tài)更低的資源利用率,分別降低了81.7%-85.9%和2.9%-20.8%藝術(shù)建筑。此外,保證了吞吐量和可編程性。源代碼已在GitHub開源。
1. 引言
“在硬件加速計(jì)算時(shí)代,識(shí)別并卸載通用的抽象和原語(yǔ),而不是單獨(dú)的算法和協(xié)議。”
隨著網(wǎng)絡(luò)吞吐量的不斷增加,越來(lái)越多的數(shù)據(jù)包處理任務(wù)被轉(zhuǎn)移到基于現(xiàn)場(chǎng)可編程門陣列的智能網(wǎng)卡上,包括循環(huán)冗余校驗(yàn)的生成和驗(yàn)證。400G等技術(shù)和即將到來(lái)的多太比特以太網(wǎng)要求更快的CRC計(jì)算[5],而基于FPGAs的高性能CRC計(jì)算的實(shí)現(xiàn)必須滿足三個(gè)要求:1)降低并行化成本。Dennard縮放[2]的結(jié)束導(dǎo)致了提高集成電路頻率的瓶頸,更高的吞吐量意味著芯片中更寬的總線。4切片和8切片算法是在[3]中提出的并行處理算法,適用于CPU,但不適用于FPGAs [4]。2)解決補(bǔ)零問(wèn)題。并行化意味著事務(wù)的最后一個(gè)字由有效字節(jié)和填充零組成。填充零的數(shù)量是不確定的,并且使用完整的最終字的循環(huán)冗余校驗(yàn)計(jì)算將導(dǎo)致錯(cuò)誤的結(jié)果,這被稱為填充零問(wèn)題。[5]說(shuō)明解決這個(gè)問(wèn)題的最新方案。最后一個(gè)字對(duì)應(yīng)的表是以流水線的方式組織的,每個(gè)流水線步驟對(duì)應(yīng)于一個(gè)二叉查找樹層。介紹了一種O(n)資源利用方式。3)保持可編程性。循環(huán)冗余校驗(yàn)算法的可編程實(shí)現(xiàn)可以實(shí)現(xiàn)更好的可重用性;因此,無(wú)需修改電路即可支持廣泛的應(yīng)用。需求可以在iSCSI [6]和P4 [7]找到。使用特定的電路架構(gòu)來(lái)保證可編程性[8],但不適用于FPGAs。[4]是適用于FPGAs的最先進(jìn)的方案,但它需要復(fù)雜的配置電路,導(dǎo)致資源利用率隨著總線寬度的增加而大幅提高。
上述三個(gè)要求導(dǎo)致了可觀的資源利用率。盡管slicing[3] [4]、aggressive strides、多個(gè)流的同時(shí)處理[5]以及支持循環(huán)冗余校驗(yàn)加速的許多其他原則是眾所周知的,但它們不能同時(shí)實(shí)現(xiàn)低成本、高性能和可編程性。采用英特爾循環(huán)冗余校驗(yàn)指令[9]的多核多插槽系統(tǒng)可以實(shí)現(xiàn)高吞吐量,但在數(shù)據(jù)包處理應(yīng)用中會(huì)面臨高延遲和高功耗的問(wèn)題。簡(jiǎn)單地說(shuō),提出了兩種算法和一種對(duì)應(yīng)于這三種要求的方法,以在保證吞吐量和可編程性的情況下降低資源利用率。首先,提出了stride-by-5算法,與slicing-by-4和slicing-by-8算法相比,該算法的資源利用率降低了79.69%-79.98%。其次,提出了pipelining go back算法來(lái)解決填充零問(wèn)題,這將引入一個(gè)O (log2 n)資源利用率。最后,硬件內(nèi)部配置訪問(wèn)端口(HWICAP)用于實(shí)現(xiàn)動(dòng)態(tài)可編程性,無(wú)論總線寬度如何,它都可以實(shí)現(xiàn)小而恒定的資源利用率。
本文的其余部分組織如下。第二節(jié)介紹了一些基礎(chǔ)知識(shí)。第三節(jié)討論了系統(tǒng)架構(gòu)和三個(gè)創(chuàng)新。第四節(jié)顯示了綜合結(jié)果。第五節(jié)是本文的結(jié)尾。
2. 基礎(chǔ)知識(shí)
2.1 并行循環(huán)冗余校驗(yàn)算法
并行循環(huán)冗余校驗(yàn)算法可以同時(shí)處理多個(gè)數(shù)據(jù)輸入位[10]。并行處理的位數(shù)設(shè)為,這也是本文剩余部分中內(nèi)部總線的寬度。并行輸入數(shù)據(jù)為
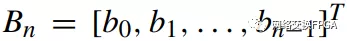 。在Bn進(jìn)入之前,循環(huán)冗余校驗(yàn)寄存器的值為Ck。Cn+k和Ck的關(guān)系是:
。在Bn進(jìn)入之前,循環(huán)冗余校驗(yàn)寄存器的值為Ck。Cn+k和Ck的關(guān)系是:
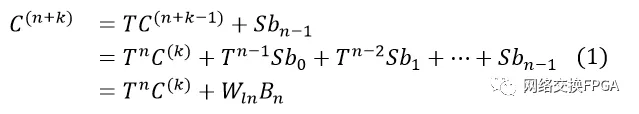


3. 設(shè)計(jì)思路
3.1 非分段系統(tǒng)架構(gòu)
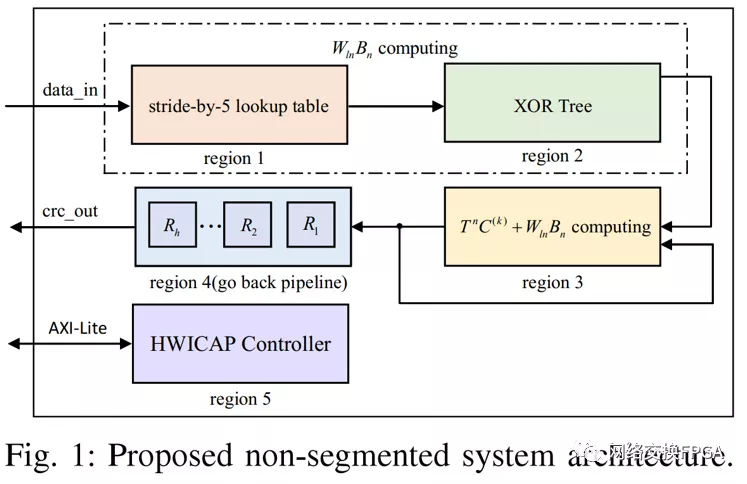
所提出的非分段系統(tǒng)架構(gòu)如圖1所示。在非分段系統(tǒng)架構(gòu)中,單個(gè)字中應(yīng)該有一個(gè)幀,分段系統(tǒng)架構(gòu)可以同時(shí)處理多個(gè)幀[13]。區(qū)域1和2對(duì)應(yīng)于(1)中WlnBn的計(jì)算。區(qū)域1消耗大部分查找表,消耗的查找表數(shù)量線性地取決于Wln的大小。在第二節(jié)中討論的stride-by-5算法是為了減少區(qū)域1的LUT消耗而提出的。區(qū)域2通過(guò)異或樹而不是一級(jí)異或函數(shù)來(lái)實(shí)現(xiàn),以獲得更高的性能。區(qū)域3完成了公式(1)的計(jì)算。區(qū)域4解決了填充零問(wèn)題,并在第五節(jié)中提出和討論了導(dǎo)致O(log2n)資源利用率的pipelining go back算法。區(qū)域5是一個(gè)HWICAP控制器,可以動(dòng)態(tài)修改查找表的內(nèi)容。操作程序在第四節(jié)中討論。分段系統(tǒng)架構(gòu)在第五節(jié)中提出。上述建議的實(shí)施細(xì)節(jié)可訪問(wèn)[1]。
3.2 stride-by-5算法

在這一部分中,建立了資源利用模型,證明了對(duì)于不同的總線寬度,5步是最佳的步幅(stride),stride-by-5算法在算法1中描述。顧名思義,Stride是指單個(gè)邏輯表處理的位數(shù)。邏輯表可以用FPGA LUTs實(shí)現(xiàn),可以加載一個(gè)函數(shù)的真值表。例如,八輸入函數(shù)定義為:
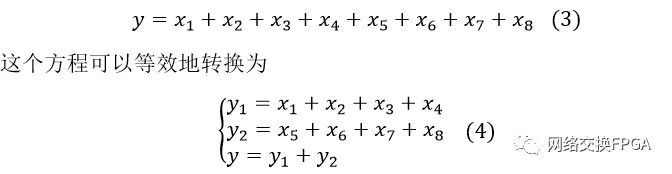
步幅為8和4的等式(3)和(4)可以分別如圖2(a)和圖2(b)所示實(shí)現(xiàn)。較小的步長(zhǎng)意味著較小的邏輯表可以通過(guò)單個(gè)LUT或級(jí)聯(lián)查找表來(lái)實(shí)現(xiàn)。步長(zhǎng)等于1可以認(rèn)為是FPGA實(shí)現(xiàn)的最佳步距嗎?我們將建立資源利用模型并確定答案。
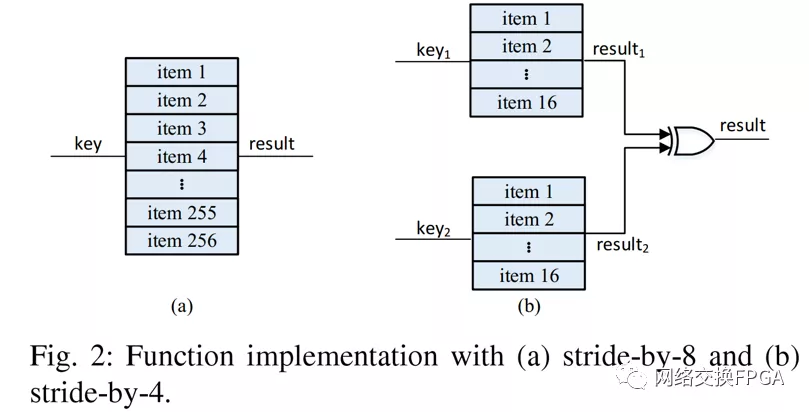

stride-by-5算法對(duì)于FPGAs中的5輸入查找表是最佳的。與slicing-by-4和slicing-by-8算法中使用的stride-by-8相比,stride-by-5將資源利用率降低了79.69%-79.98%。對(duì)于具有非5輸入查找表的FPGAs(Xilinx Virtex-5或Altera Stratix II之前),應(yīng)使用由LUT輸入數(shù)定義的步長(zhǎng),并應(yīng)利用LUT共享機(jī)制。stride-by-5算法在算法1中描述;它在這里處理區(qū)域1中的計(jì)算,但是該算法也可以在區(qū)域3和4中使用。
3.3 Pipelining Go Back算法
在這一部分中,提出了一種資源利用率為O(log2n)的pipelining go back算法,并給出了算法的推導(dǎo)和描述。

q可以表示為:


3.4 通過(guò)HWICAP進(jìn)行重編程
圖1中的區(qū)域5代表一個(gè)HWICAP IP核,它可以動(dòng)態(tài)修改查找表的內(nèi)容。對(duì)于任何總線寬度,它消耗186個(gè)查找表。相比之下,邏輯資源實(shí)現(xiàn)的配置邏輯導(dǎo)致n ≥ 1024 [4]時(shí)消耗幾千個(gè)lut,資源利用率隨著總線寬度的增加而增加。使用HWICAP IP核重新編程的操作程序如下所述:
1. 完成初始設(shè)計(jì),使用Vivado生成比特流,并將比特流下載到FPGA
2. 提取所用查找表的位置;
3. 當(dāng)需要重新編程時(shí),使用(1)和(12)計(jì)算查找表的新內(nèi)容;
4. 將查找表的內(nèi)容映射到查找表的初始值;
5. 使用HWICAP IP核的AXI Lite 接口將初始值寫入查找表。
重編程方法在工程上是有用的。我們的貢獻(xiàn)如下:
1. 我們驗(yàn)證了使用HWICAP IP核對(duì)循環(huán)冗余校驗(yàn)算法的現(xiàn)場(chǎng)可編程門陣列實(shí)現(xiàn)進(jìn)行重新編程的可行性。不考慮總線寬度,導(dǎo)致資源利用率小且恒定;
2. 該方法可以直接改變循環(huán)冗余校驗(yàn)多項(xiàng)式,無(wú)需重新編碼和合成;
3. 上述程序的代碼可作為整個(gè)項(xiàng)目的一部分在[1]中訪問(wèn)。據(jù)我們所知,這是第一個(gè)涵蓋上述整個(gè)過(guò)程的開源代碼。
3.5 分段系統(tǒng)架構(gòu)
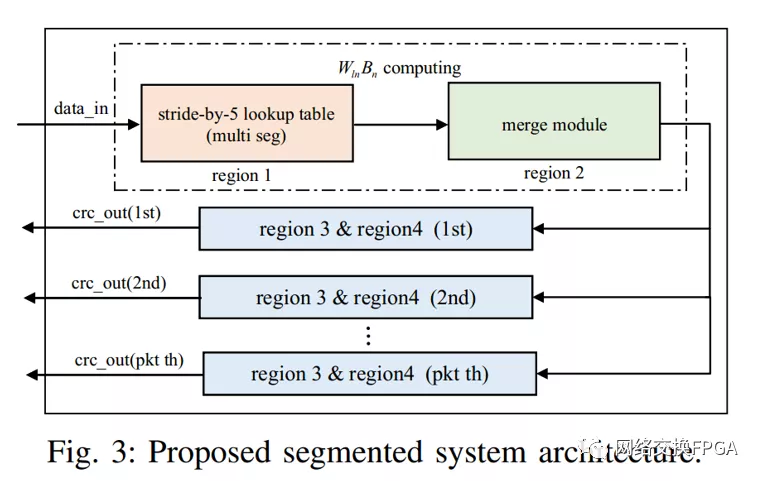
非分段系統(tǒng)架構(gòu)無(wú)法在一個(gè)字(時(shí)鐘)中處理多個(gè)幀,這降低了短幀或未對(duì)齊幀的吞吐量。這就是總線效率問(wèn)題。針對(duì)這一問(wèn)題,提出了一種分段的系統(tǒng)架構(gòu)。總線格式與[5]中的相同,[5]中的塊(block)是[13]中段(segment)的另一個(gè)名稱。比如一條4096位總線可以同時(shí)處理8個(gè)完整的幀;因此,總線可以分為八個(gè)區(qū)域[5]。區(qū)域的數(shù)量?jī)H取決于總線寬度。不同的段寬度是可行的,如果選擇64位的段寬度,一個(gè)區(qū)域可以分成八個(gè)段(塊)。圖3示出了所提出的分段系統(tǒng)架構(gòu)。與建議的非分段系統(tǒng)架構(gòu)相比,建議的分段系統(tǒng)架構(gòu)具有稍微更復(fù)雜的區(qū)域1和區(qū)域2以及區(qū)域3和區(qū)域4的多個(gè)副本。重復(fù)的數(shù)量只是單個(gè)字中處理的最大幀數(shù)。
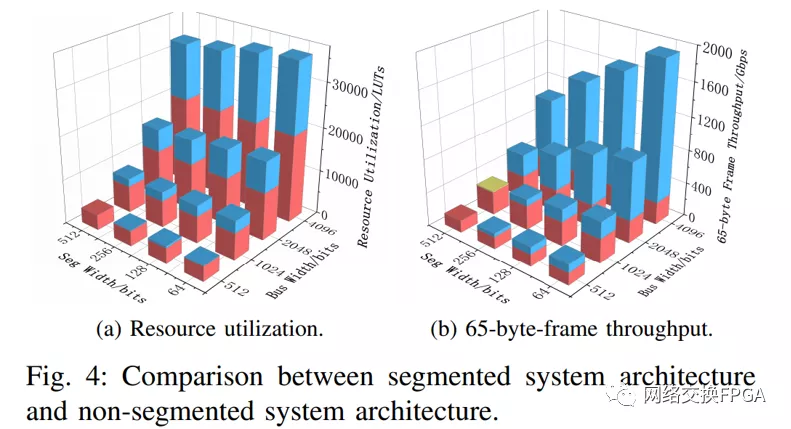
在圖4中可以找到所提出的分段系統(tǒng)架構(gòu)和所提出的非分段系統(tǒng)架構(gòu)之間的比較。紅色長(zhǎng)方體代表非分段系統(tǒng)架構(gòu)。藍(lán)色長(zhǎng)方體表示建議的分段系統(tǒng)架構(gòu)和建議的非分段系統(tǒng)架構(gòu)之間的增量。黃色切片(總線寬度= 1024,段寬度=512) 表示兩種體系結(jié)構(gòu)之間的減量。圖4a示出了資源利用率的增加主要取決于總線寬度而不是段寬度。這是因?yàn)橘Y源利用率的增加主要取決于區(qū)域3和4的副本數(shù)量,而區(qū)域3和4的副本數(shù)量?jī)H取決于總線寬度。圖4b顯示,在大多數(shù)情況下,65字節(jié)幀吞吐量的增加是明顯的。當(dāng)總線寬度為1024位,段寬度為512位時(shí),吞吐量只會(huì)下降,其中兩種架構(gòu)對(duì)于65字節(jié)幀吞吐量具有相同的總線效率,而非分段架構(gòu)的頻率略高。因此,在本文的其余部分,選擇64位作為段寬。分段和非分段架構(gòu)之間的詳細(xì)比較可以在本簡(jiǎn)報(bào)的擴(kuò)展版本中找到[11]。
4. 實(shí)驗(yàn)結(jié)果
有三個(gè)最先進(jìn)的研究[5][4][14]。[4][14]中的體系結(jié)構(gòu)可以重新編程,而[5]中的體系結(jié)構(gòu)不能重新編程。提出的兩種架構(gòu)分別用Virtex-7 XC7VX690T實(shí)現(xiàn),[5][4][14]使用Virtex-7 XCVH870T、Virtex-6 XC6VLX550T和Stratix-V 5SGSED6N1F45I2。在本節(jié)中,從資源利用率和最大吞吐量的角度將兩種建議的體系結(jié)構(gòu)與這些工作進(jìn)行了比較。就各種幀長(zhǎng)度的吞吐量而言,將所提出的分段架構(gòu)與[5]進(jìn)行了比較。還報(bào)告了兩種建議架構(gòu)的功耗。在下文中,我們使用SA來(lái)指代分段架構(gòu)。
綜合結(jié)果如圖5所示。圖5a示出了建議的非SA的資源利用率較分別比[4]和[5]中的體系結(jié)構(gòu)低80.7%-87.5%和25.1%-46.2%,SA的分別為81.7%-85.9%和2.9%-20.8%。資源利用率較低是由于實(shí)施了第三節(jié)中描述的算法和方法,這也可以保證高性能和可編程性。[14]中的體系結(jié)構(gòu)的資源利用率比非SA體系結(jié)構(gòu)低74.4%-81.3%。[14]資源利用率較低的原因如下:1)。[14]只需要處理半滿和全滿的數(shù)據(jù)包。換句話說(shuō),補(bǔ)零問(wèn)題得到了部分解決。相比之下,兩個(gè)建議的架構(gòu)和[5][4]可以完全解決填充零問(wèn)題。2)。Nios II IP核的成本在[14]中沒(méi)有考慮。相比之下,兩種建議的體系結(jié)構(gòu)都考慮了HWICAP的成本。此外,很難將[14]的總線寬度擴(kuò)展到1024位。
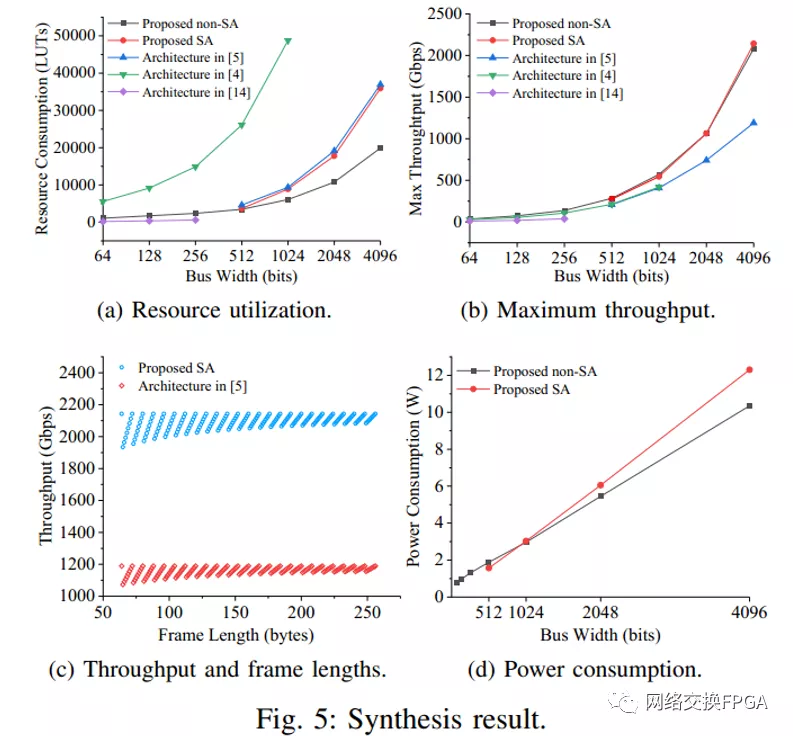
圖5b顯示,所提出的非SA的最大吞吐量分別比[4][5][14]中的架構(gòu)高24.2%-37.9%、37.4%-75.0%和259.4%-284.5%。提出的SA的最大吞吐量分別比[4][5]中的架構(gòu)高28.7%-30.2%和32.2%-80.2%。更高的頻率導(dǎo)致更高的吞吐量,并且兩個(gè)建議的架構(gòu)可以為區(qū)域1、2和4中排列良好的流水線實(shí)現(xiàn)更高的頻率。
幀長(zhǎng)度從64字節(jié)到256字節(jié)的吞吐量可以在圖5c中找到。只有[5]和提議的SA被比較,因?yàn)樗鼈冊(cè)谝粋€(gè)字中處理多個(gè)幀的能力。這兩種架構(gòu)使用4096位總線寬度和64位段寬度;因此,它們具有相同的總線效率。提議的SA的頻率和吞吐量比[5]高80.2%。當(dāng)幀長(zhǎng)度為65字節(jié)時(shí),最低吞吐量為1933.9 Gbps。
兩種提出架構(gòu)的功耗如圖5d所示。它們以500Mhz運(yùn)行。數(shù)據(jù)集來(lái)自vivado生成的實(shí)施后功耗報(bào)告。功耗由靜態(tài)功耗和動(dòng)態(tài)功耗組成。靜態(tài)功耗從0.32 W到0.48 W不等,動(dòng)態(tài)功耗隨著總線寬度的增加而線性增加。提議的SA的功耗比提議的非SA的功耗增長(zhǎng)更快。這是因?yàn)樘嶙h的SA的資源消耗比提議的非SA的資源消耗增加得更快。
板級(jí)實(shí)現(xiàn)和與其他作品的比較可以在本文的擴(kuò)展版本中找到[11]。
5. 結(jié)論和未來(lái)工作
本文提出了兩種算法和一種方法來(lái)實(shí)現(xiàn)低成本、高性能和可編程的循環(huán)冗余校驗(yàn)計(jì)算。這些算法和所提出的方法可用于分段或非分段架構(gòu)。綜合結(jié)果表明,與現(xiàn)有的兩種體系結(jié)構(gòu)相比,所提出的體系結(jié)構(gòu)可以實(shí)現(xiàn)更低的資源利用率和更高的吞吐量。源代碼可以在[1]中訪問(wèn)。我們未來(lái)的工作將集中在使硬件重配置方法(HWICAP)技術(shù)獨(dú)立。
審核編輯:何安
-
算法
+關(guān)注
關(guān)注
23文章
4615瀏覽量
92999
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
什么是raid磁盤冗余陣列
冗余電壓采集技術(shù)有哪些 冗余電壓不足的原因是什么
冗余電源怎么接線
循環(huán)神經(jīng)網(wǎng)絡(luò)算法原理及特點(diǎn)
循環(huán)神經(jīng)網(wǎng)絡(luò)算法有哪幾種
Hex文件格式CRC校驗(yàn),怎么編寫計(jì)算校驗(yàn)的程序?
FPGA壓縮算法有哪些

淺析MCU通信、存儲(chǔ)常用的簡(jiǎn)單校驗(yàn)算法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論