 在BuildRelay中會調用Codegen函數
在BuildRelay中會調用Codegen函數
作者:安平博,Xilinx高級工程師;來源:AI加速微信公眾號
接著上一章繼續深入代碼,在BuildRelay中會調用Codegen函數。這個函數實現在src/relay/backend/graph_runtime_codegen.cc中。Codegen實現了內存的分配,IR節點到TIR節點的轉換,tir圖節點的一個調度優化。內存分配由函數relay.backend.GraphPlanMemory來實現,VisitExpr對節點進行遍歷并進行節點信息的記錄。LowerExternalfunctions完成ir節點到tir節點的轉化以及schedule的優化。
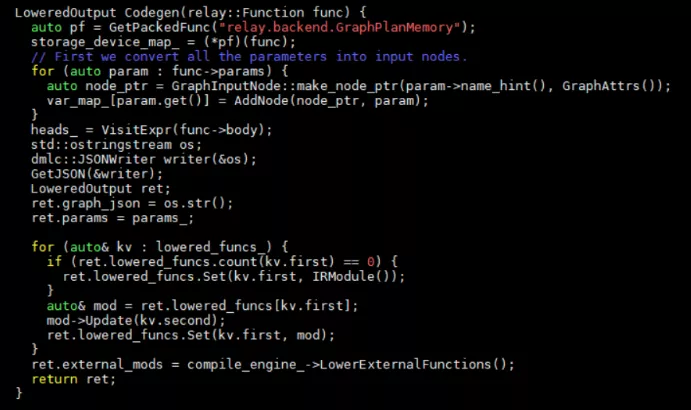
內存分配
通過GetPackedFunc函數來獲得注冊到global map的內存分配函數GraphPlanMemory。我們看一下文件src/relay/backend/graph_plan_memory.cc中對內存的處理。

在處理內存分配中主要使用了StorageAllocaBaseVisitor,StorageAllocaInit,StorageAllocator這三個類。StorageAllocaBaseVisitor是一個基類,實現了對每個節點的訪問,并分配token,但是token中信息是在派生類中處理的。定義了一個StorageToken的結構體,用于表示申請到內存的大小,類型等信息。在內存處理程序中,主要就是為每個節點分配這個token,同時定義token的內部信息。內存分配結果是一個節點和token的映射表。
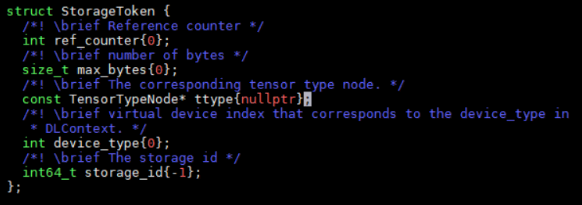
StorageAllocator類中Plan函數為:
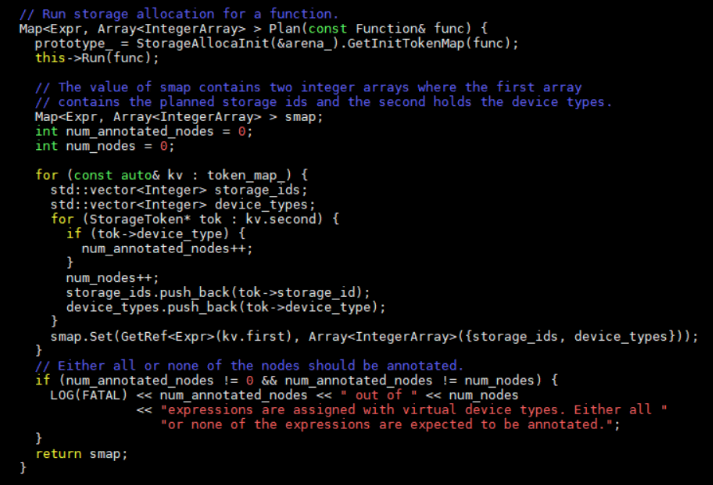
關鍵是前兩行代碼,第一行代碼初始化了storageToken,賦予了其設備類型和數據類型信息。第二行代碼遍歷每個節點,并且為每個節點分配內存空間。在內存初始化函數GetInitTokenMap中,首先收集每個節點的的設備信息。調用鏈為CollectDeviceInfo -> GetDeviceMap(src/relay/transforms/device_annotation.cc)。在構建relay圖結構的時候,每個節點是有設備號信息的,GetDeviceMap就是按照post-DFS順序獲得節點的設備號信息。當然并不是所有節點都有設備號信息,所以還需要根據節點之間的關系來推斷出設備號。比如下圖,add,sqrt,log節點被標注為1,2,3號設備,那么可以用兩種方式來推斷其它節點設備號。
1) 從一個copy節點由下而上遍歷一直到遇到下一個copy,比如可以推斷出add,x,y節點的設備號和copy1一樣;
2) 從最后一個copy節點向下遍歷,那么可以推斷出substract,exp設備號和copy3一樣。

設備號獲得后,this->run會調用基類的run函數,基類run函數會調用派生類的CreateToken函數。CreateToken會申請StorageToken空間并且賦予設備號和數據類型,然后返回一個token_map_。和節點遍歷相關函數為Run->GetToken->VisitExpr。VisitExpr會最終調用StorageAllocaInit類中定義的VisitExpr_函數來遍歷節點。
節點內存初始化完成后,回到StorageAllocator類中,run會調用其定義的CreateToken函數。
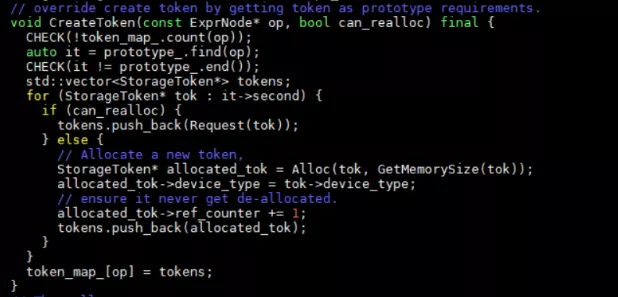
分配內存空間會有兩種情況,一種是can_realloc一種是不能can_realloc的。先看不can_realloc的,GetMemorySize是根據token中記錄的數據類型和shape信息來獲得數據的大小,Alloc函數就是為tok分配字節數量。現在看can_realloc的情況,Request中首先獲取節點數據的大小。然后從free_中查詢能夠滿足size的節點,如果有比該節點size大的就選擇大的空閑區間分配,如果沒有大的空間分配,選擇最接近的空間分配。然后最終返回一個token_map_。
codegen
第一步是對ir節點進行遍歷,轉換成codegen中定義的基礎節點。我們先看以下codegen中定義的節點類型,GraphNode是基礎節點,GraphInputNode, GraphOpNode繼承自這個基礎節點。這些節點中主要提供了一些節點屬性,比如name,op類型等。還提供了dmlc接口,可以實現可視化。
遍歷func的parameters,將parameters轉換到graph的input節點。通過AddNode添加這些input節點,并且將轉換后的graphInputNode加入var_map_中,var_map_中是expr到graphNode的映射。
接下來是節點遍歷,heads_=VisitExpr(func->body)。節點遍歷過程中會將func中的節點轉換為graphNode。對于varNode,因為已經記錄在var_map_中,直接返回引用。ConstantNode會轉換為GraphInputNode,tuppleNode會返回每個字段的graphNode。在遍歷節點過程中,會將graphNode都添加到nodes_中。
重點看一下對CallNode的處理,只支持op是functionNode類型的。
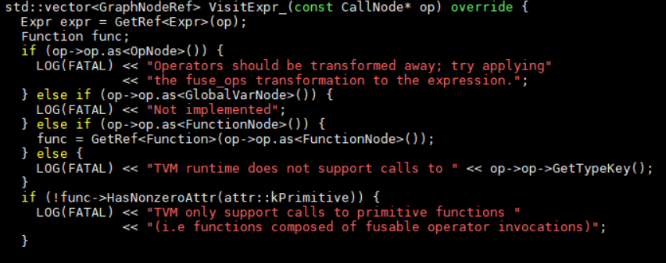
Function生成時,走兩個分支,一個是外部codegen,一個是通用分支。對應外部function codegen的處理為:
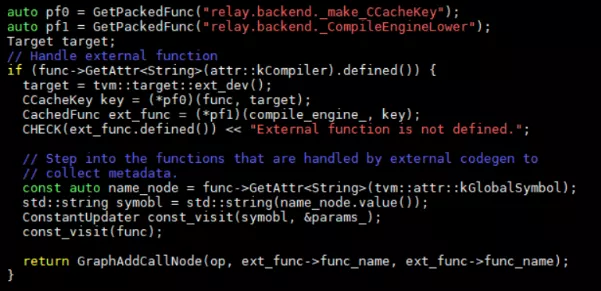
首先創建一個CCacheKey類型作為_CompileEngineLower函數的參數傳入。具體CcacheKey有什么作用,以后再深入研究吧。_CompileEngineLower的實現在文件src/relay/backend/compile_engine.cc中。調用鏈為Lower -> LowerInternal(key)->cached_func。定義了一個cache_node并封裝成cached_func返回。這塊具體的操作并不是很理解,可能還需要熟悉cachedFuncNode的作用。
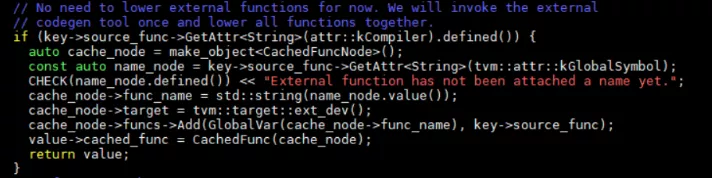
然后通過GraphAddCallNode將其加入nodes_中。在GraphAddCallNode中還會對op->args進行深入遍歷。
內部func處理如下:

也是通過相同的pf0和pf1函數。CcacheKey的創建過程一樣,但是在lowerInternal中不一樣。
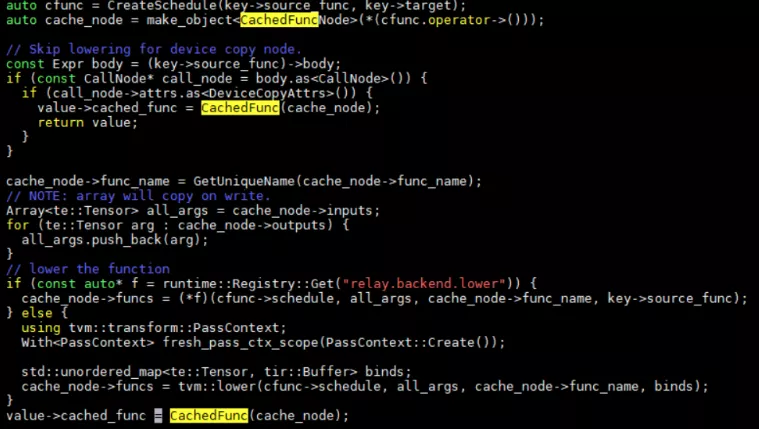
首先創建了一個schedule,schedule的具體實現很復雜目前還不夠理解。
如果是copy節點,那么不進行lower處理,直接返回CachedFunc封裝。不是copy節點,如果我們在python中自己定義了lower函數就調用python中的,如果沒有就會調用TVM中的lower函數。Lower函數在src/driver/driver_api.cc文件中。在這里調用了很多tir的passes來進行一個節點轉換。這塊后邊再詳細看。
審核編輯:何安
-
函數
+關注
關注
3文章
4341瀏覽量
62796
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論