 TensorFlow模型優化:模型量化
TensorFlow模型優化:模型量化
1. 模型量化需求
為了滿足各種 AI 應用對檢測精度的要求,深度神經網絡結構的寬度、層數、深度以及各類參數等數量急速上升,導致深度學習模型占用了更大的存儲空間,需要更長的推理時延,不利于工業化部署;目前的模型都運行在 CPU,GPU,FPGA,ASIC 等四類芯片上,芯片的算力有限;對于邊緣設備上的芯片而言,在存儲、內存、功耗及時延性方面有許多限制,推理效率尤其重要。
作為通用的深度學習優化的手段之一,模型量化將深度學習模型量化為更小的定點模型和更快的推理速度,而且幾乎不會有精度損失,其適用于絕大多數模型和使用場景。此外,模型量化解鎖了定點硬件(Fixed-point hardware) 和下一代硬件加速器的處理能力,能夠實現相同時延的網絡模型推理功能,硬件價格只有原來的幾十分之一,尤其是 FPGA,用硬件電路去實現網絡推理功能,時延是各類芯片中最低的。
TensorFlow 模型優化工具包是一套能夠優化機器學習模型以便于部署和執行的工具。該工具包用途很多,其中包括支持用于以下方面的技術:
通過模型量化等方式降低云和邊緣設備(例如移動設備和 IoT 設備)的延遲時間和推斷成本。將優化后的模型部署到邊緣設備,這些設備在處理、內存、耗電量、網絡連接和模型存儲空間方面存在限制。在現有硬件或新的專用加速器上執行模型并進行優化。
根據您的任務選擇模型和優化工具:
利用現成模型提高性能在很多情況下,預先優化的模型可以提高應用的效率。
2. 模型量化過程
大家都知道模型是有權重 (w) 和偏置 (b) 組成,其中 w,b 都是以 float32 存儲的,float32 在計算機中存儲時占 32bit,int8 在計算機中存儲時占 8bit;模型量化就是用 int8 等更少位數的數據類型來代替 float32 表示模型的權重 (w) 和偏置 (b) 的過程,從而達到減少模型尺寸大小、減少模型內存消耗及加快模型推理速度等目標。
模型量化以損失推理精度為代價,將網絡中連續取值或離散取值的浮點型參數(權重 w 和輸入 x)線性映射為定點近似 (int8/uint8) 的離散值,取代原有的 float32 格式數據,同時保持輸入輸出為浮點型,從而達到減少模型尺寸大小、減少模型內存消耗及加快模型推理速度等目標。定點量化近似表示卷積和反卷積如下圖 所示,左邊是原始權重 float32 分布,右邊是原始權重 float32 經過量化后又反量化后權重分布。
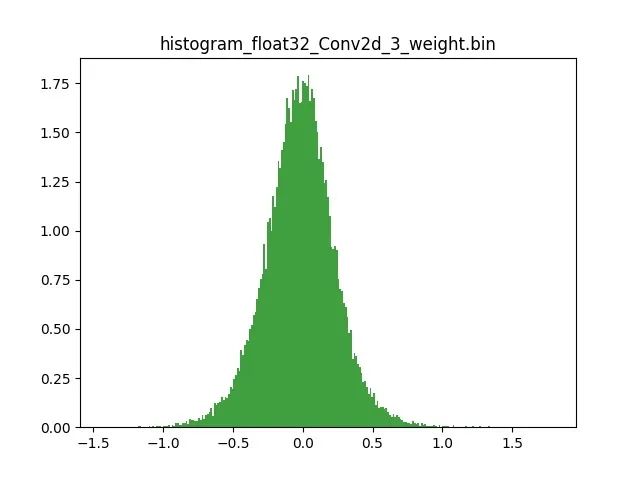
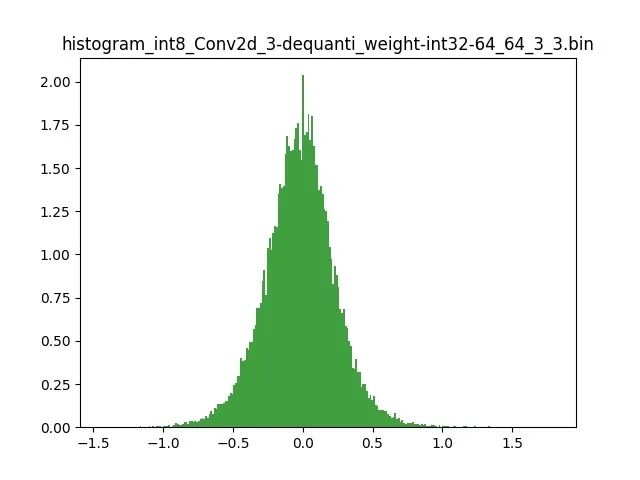
圖 2.1 Int8 量化近似表示卷積
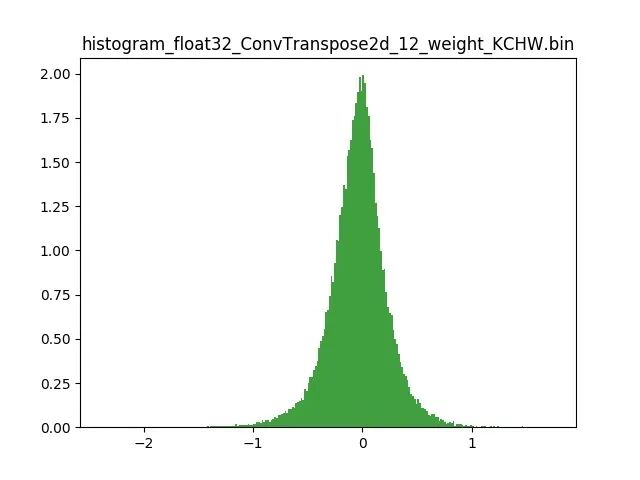
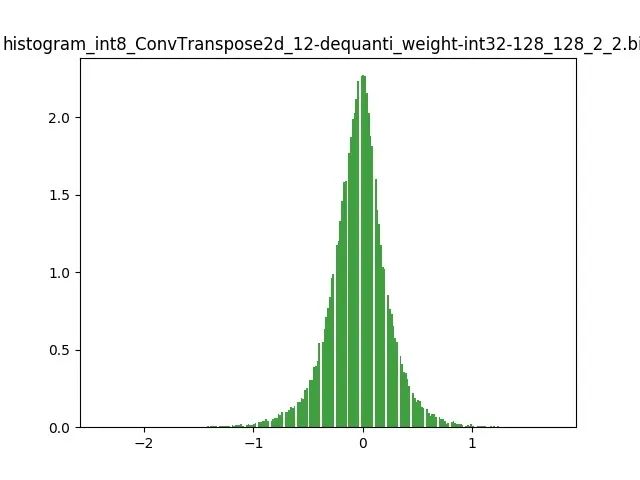
圖 2.2 Int8 量化近似表示反卷積
3. 模型量化好處
減小模型尺寸,如 8 位整型量化可減少 75% 的模型大小;
減少存儲空間,在邊緣側存儲空間不足時更具有意義;
減少內存耗用,更小的模型大小意味著不需要更多的內存;
加快推理速度,訪問一次 32 位浮點型可以訪問四次 int8 整型,整型運算比浮點型運算更快;CPU 用 int8 計算的速度更快
減少設備功耗,內存耗用少了推理速度快了自然減少了設備功耗;
支持微處理器,有些微處理器屬于 8 位的,低功耗運行浮點運算速度慢,需要進行 8bit 量化。
某些硬件加速器如 DSP/NPU 只支持 int8
4. 模型量化原理
模型前向推理過程中所有的計算都可以簡化為 x= w*x +b; x 是輸入,也叫作 FeatureMap,w 是權重,b 是偏置;實際過程中 b 對模型的推理結果影響不大,一般丟棄。原本 w,x 是 float32,現在使用 int8 來表示為 qw,qx;模型量化的原理就是定點 (qw qx) 與浮點 (w,x),建立了一種有效的數據映射關系.。不僅僅量化權重 W ,輸入 X 也要量化;詳解如下:
R 表示真實的浮點值(w 或者 x),
責任編輯:lq
-
模型
+關注
關注
1文章
3280瀏覽量
48985 -
機器學習
+關注
關注
66文章
8429瀏覽量
132855 -
深度學習
+關注
關注
73文章
5511瀏覽量
121355
原文標題:社區分享 | TensorFlow 模型優化:模型量化
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「基于大模型的RAG應用開發與優化」閱讀體驗】+Embedding技術解讀
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
Meta發布Llama 3.2量化版模型
理解LLM中的模型量化

快速部署Tensorflow和TFLITE模型在Jacinto7 Soc







 工商網監
工商網監
評論