 深度學習圖像識別解釋方法的概述
深度學習圖像識別解釋方法的概述
圖像識別(即 對圖像中所顯示的對象進行分類)是計算機視覺中的一項核心任務,因為它可以支持各種下游的應用程序(自動為照片加標簽,為視障人士提供幫助等),并已成為機器學習(ML)算法的標準任務。
在過去的十年中,深度學習(DL)算法已成為最具競爭力的圖像識別算法。但是,它們默認是“黑匣子”算法,也就是說很難解釋為什么它們會做出特定的預測。
為什么這會成為一個問題呢?這是因為ML模型的使用者通常出于以下原因而希望能夠解釋圖像的哪些部分導致了算法的預測結果:
1.機器學習調試模型,開發人員可以分析解釋識別偏差和預測模型是否可能推廣到新的圖像
2. 機器學習模型的用戶可能會更加信任一個模型,如果提供了為什么做出特定預測的解釋的話。
3. 關于ML的法規(例如GDPR)要求一些算法決策可以用人類的語言來解釋。
在以上因素的推動下,在過去的十年中,研究人員開發了許多不同的方法來打開深度學習的“黑匣子”,旨在使基礎模型更具可解釋性。有些方法對于某些種類的算法是特定的,而有些則是通用的。有些是快的,有些是慢的。
在本文中,我們概述了一些為圖像識別而發明的解釋方法,討論了它們之間的權衡,并提供了一些示例和代碼,您可以自己使用Gradio來嘗試這些方法。
留一法 LEAVE-ONE-OUT
在深入研究之前,讓我們從一個適用于任何類型圖像分類的非常基本的算法開始:留一法(LOO)。
LOO是一種易于理解的方法。如果您要從頭開始設計一種解釋方法的話,那么這是您可能會想到的第一個算法。其想法是首先將輸入圖像分割為一系列較小的子區域。然后,運行一系列預測,每次遮罩(即將像素值設置為零)其中一個子區域。根據每個區域的“蒙版”相對于原始圖像影響預測的程度,為每個區域分配一個重要度分數。直觀地來說,這些分數量化了哪一部分的區域最有助于進行預測。
因此,如果我們在一個3x3的網格中將圖像分成9個子區域,則LOO如下所示:
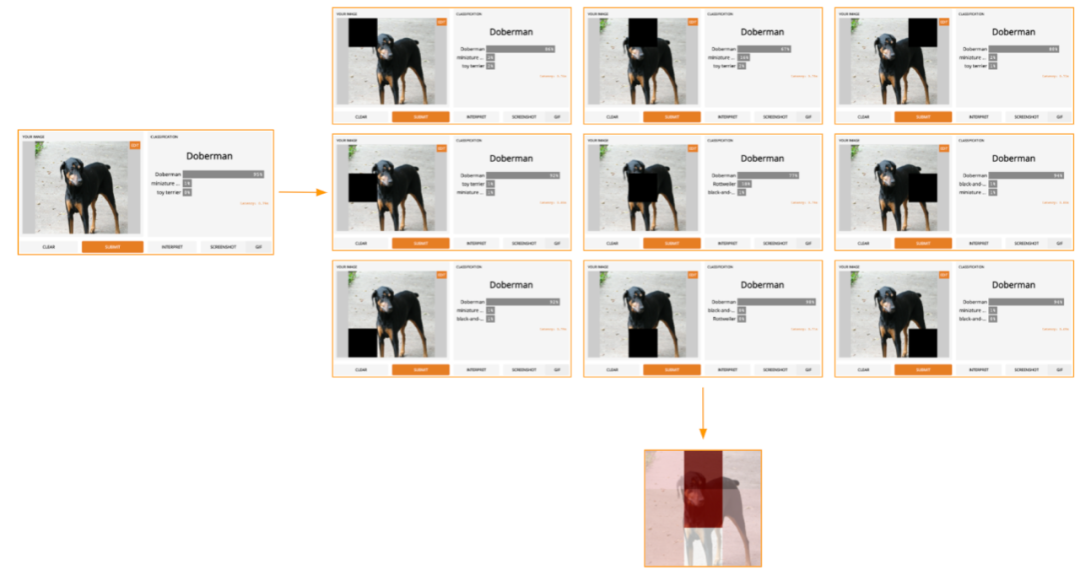
那些最暗的紅色方塊是影響輸出最大的方塊,而顏色最亮的方塊對輸出的影響最小。在這種情況下,當頂部中心區域被遮罩時,預測置信度下降幅度最大,從初始的95%下降到67%。
如果我們以更好的方式進行分割(例如,使用超像素而不是網格),我們將獲得一個相當合理的顯著圖,該圖突出了杜賓犬的臉,耳朵和尾巴。
LOO是一種簡單而強大的方法。根據圖像分辨率和分割方式,它可以產生非常準確和有用的結果。正如使用InceptionNet預測的那樣,下面這張圖就是LOO應用于1100?×?825像素的金毛尋回犬圖像。
在實踐中,LOO的一個巨大優勢是它不需要任何訪問模型內部的功能,甚至可以處理除識別之外的其他計算機視覺任務,從而使它成為一個靈活的通用工具。
那有什么缺點呢?首先,它很慢。每次一個區域被遮罩,我們就對圖像進行推斷。要獲得一個具有合理分辨率的顯著圖,您的遮罩尺寸可能必須很小。因此,如果您將圖像分割成100個區域,則將需要100倍的推理時間才能獲得熱度圖。另一方面,如果您有太多的子區域,則對它們中的任何一個區域進行遮罩不一定會在預測中產生很大的差異。此LOO的第二個限制是,它沒有考慮到區域之間的相互依賴性。
因此,讓我們來看一個更快,更復雜的技術:梯度上升。
梯度上升 VANILLA GRADIENT ASECENT [2013]
梯度上升這一方法的提出,可以追溯到2013年發表的一篇名為Visualizing Image Classification Models and Saliency Maps [2013]的論文中找到。LOO和梯度上升這兩個方法之間存在著概念上的關系。使用LOO時,我們考慮到當我們逐個遮蓋圖像中的每個區域時,輸出是如何變化的。通過梯度上升,我們可以一次計算出每單個像素對輸出的影響。我們如何做到這一點的呢?答案是使用反向傳播的改進版本。
通過使用標準的反向傳播,我們可以計算出模型損失相對于權值的梯度。梯度是一個包含每個權重值的向量,反映了該權重的微小變化將對輸出產生了多大的影響,并從本質上告訴我們哪些權重對于損失最重要。通過取該梯度的負值,我們可以將訓練過程中的損失降到最低。對于梯度上升,取而代之的是類分數相對于輸入像素的梯度,并告訴我們哪些輸入像素對圖像分類最重要。通過網絡的這一單個步驟為我們提供了每個像素的重要性值,我們以熱圖的形式顯示該值,如下所示:
Simonyan等人用單一反向傳播過程計算出顯著性圖示例
這是我們的杜賓犬的圖像:
這里的主要優勢是——速度;因為我們只需要通過網絡一次可以得到熱圖,所以梯度上升的方法比LOO快得多,盡管最終得到的熱圖有點粗糙。
在杜賓犬的圖像上,LOO(左)與梯度上升(右)方法進行了比較。這里的模型是InceptionNet。
盡管梯度上升是十分可行的,但人們發現這種被稱為Vanilla梯度上升的原始公式有一個明顯的缺點:它傳播負梯度,最終會導致干擾和噪聲的輸出。為解決這些問題,我們提出了一種新方法——“引導反向傳播”。
引導反向傳播 guided back-propogation [2014]
引導式反向傳播一開始是發表在了Striving for Simplicity: The All Convolutional Net [2014]上,其中,作者提出在反向傳播的常規步驟中增加一個來自更高層的額外引導信號。從本質上講,當輸出為負時,該方法就會阻止來自神經元的梯度反向流動,僅保留那些導致輸出增加的梯度,從而最終減少噪聲。
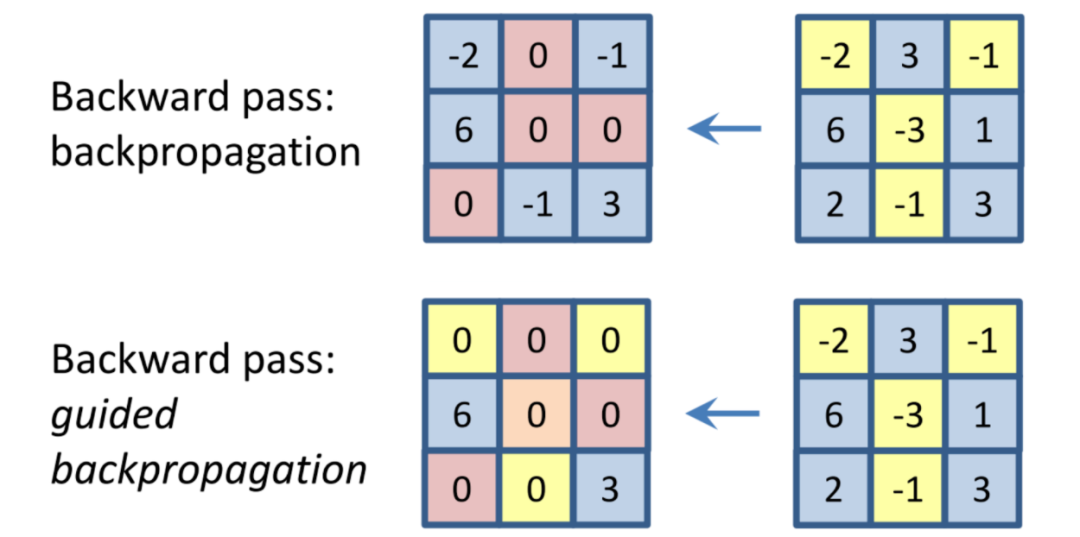
在此圖像中,我們顯示了一個給定圖層的反向傳播梯度(左),其輸出顯示在右側。在頂層,我們展示了整齊的梯度。在底層,我們展示了引導反向傳播,每當輸出為負時,它將零梯度化。(圖來自Springenberg等人)
引導式反向傳播的工作速度幾乎與梯度上升一樣快,因為它只需要通過網絡一次,但通常會產生更清晰的輸出,尤其是在物體邊緣附近。該方法相對于沒有最大池化層的神經體系結構中的其他方法來說特別有效。
在杜賓犬的圖像上,梯度上升(左)與“引導式反向傳播”(右)進行了比較。這里的模型是InceptionNet。
但是,人們發現,梯度上升和引導式反向傳播仍然存在一個主要問題:當圖像中存在兩個或更多類別時,它們通常無法正常工作,這通常發生在自然圖像中。
梯度類別響應圖 grad-cam [2016]
現在來到了Grad-CAM,或者梯度加權類別激活映射,該方法在: Visual Explanations from Deep Networks via Gradient-based Localization [2016]文章中有著相關的介紹。在這里,作者發現,當在最后一個卷基層的每個濾波器處而不是在類分數上(但仍相對于輸入像素)提取梯度時,其解釋的質量得到了改善。為了得到特定于類的解釋,Grad-CAM對這些梯度進行加權平均,其權重基于過濾器對類分數的貢獻。結果如下所示,這遠遠好于單獨的引導反向傳播。
具有兩個類別(“貓”和“狗”)的原始圖像使用了引導反向傳播的方式,但是生成的熱量圖突出顯示了這兩個類。一旦將Grad-CAM用作過濾器,引導式Grad-CAM便會生成高分辨率,區分類別的熱圖。(圖片來自Selvaraju等人)
作者進一步推廣了Grad-CAM,使其不僅適用于目標類,而且適用于任何目標“概念”。這意味著可以使用Grad-CAM來解釋為什么圖像字幕模型可以預測特定的字幕,甚至可以處理多個輸入的模型,例如可視化問答模型。由于這種靈活性,Grad-CAM已變得非常流行。以下是其架構的概述。
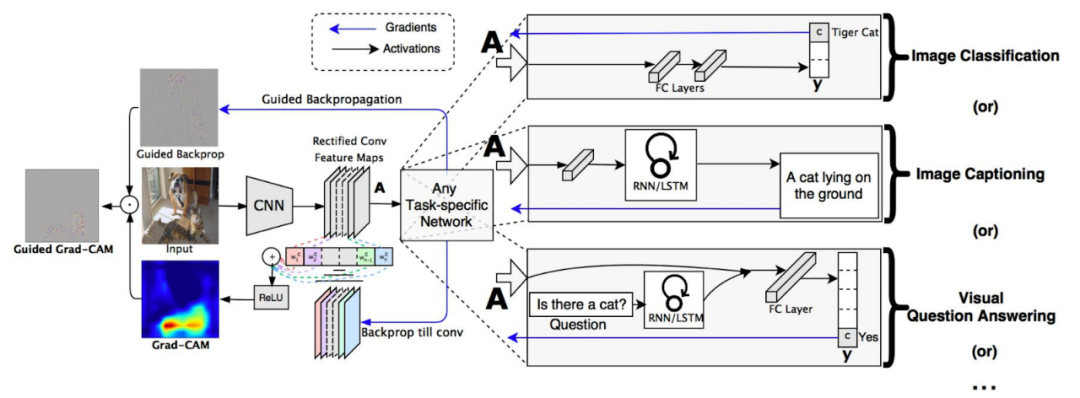
Grad-CAM概述:首先,我們向前傳播圖像。對于除所需類別(tiger cat)之外的所有類別梯度設置為0,其余設置為1。然后將該信號反向傳播到所關注的整流卷積特征圖,我們結合這些特征圖來計算粗糙Grad-CAM定位(藍色熱圖),它表示模型在做出特定決策時必須尋找的位置。最后,我們將熱圖與引導反向傳播逐點相乘,得到高分辨率和概念特定的Guided Grad-CAM可視化。(圖片和描述來自Selvaraju等人)
平滑梯度 smoothgrad [2017]
然而,您可能已經注意到,就算使用所有先前所介紹的方法,結果仍然不是很清晰。SmoothGrad, presented in SmoothGrad: removing noise by adding noise [2017], 這篇文章是對先前方法的修改版本。這個想法很簡單:作者指出,如果輸入圖像首先受到噪聲干擾,則可以為每個版本的干擾輸入計算一次梯度,然后將靈敏度圖平均化。盡管運行時間更長,但這會得到更清晰的結果。
以下是引導式反向傳播和平滑梯度圖像的對比:
杜賓犬圖像上的標準制引導反向傳播(左)與平滑梯度(右)。這里的模型是InceptionNet。
當您面對所有的方法時,會選擇哪一種?或者,當方法之間發生沖突時,是否有一種方法在理論上可以證明比其他方法更好?讓我們看一下集成梯度的方法。
集成梯度 integrated gradients [2017]
與此前的論文不同,Axiomatic Attribution for Deep Networks [2017]的作者從解釋的理論基礎開始。他們專注于兩個公理:靈敏度和實現不變性,為此,他們提出了一個好的解釋方法應該滿足這兩項。
靈敏度公理意味著,如果兩個圖像的有一個像素恰好不同(但所有其他像素都相同),并且產生不同的預測,則解釋算法應為該不同像素提供非零的屬性。而實現不變性公理意味著算法的底層實現不應影響解釋方法的結果。他們使用這些原則來指導一種新的歸因方法的設計,該歸因方法稱為“集成梯度(IG)”。
IG從基線圖像(通常是輸入圖像的完全變暗的版本)開始,并增加亮度,直到恢復原始圖像為止。針對每幅圖像計算類別分數相對于輸入像素的梯度,并對其進行平均以獲得每個像素的全局重要性值。IG除了理論特性外,還解決了普通梯度上升的另一個問題:飽和梯度。由于梯度是局部的,因此它們不能捕獲像素的全局重要性,而只能捕獲特定輸入點的靈敏度。通過改變圖像的亮度并計算不同點的梯度,IG可以獲得更完整的圖片,包含了每個像素的重要性。
在杜賓犬圖像上的標準引導反向傳播(左)與集成梯度(右),均使用了平滑梯度進行了平滑處理。這里的模型是InceptionNet。
盡管這通常可以產生更準確的靈敏度圖,但是該方法速度較慢,并且引入了兩個新的附加超參數:基線圖像的選擇以及生成集成梯度的步驟數。那么,我們可以不用這些么?
模糊集成梯度 blur integratedgradients [2020]
這就是我們最終的解釋方法,即模糊集成梯度。該方法在Attribution in Scale and Space [2020],中提出,旨在解決具有集成梯度的特定問題,包括消除“基線”參數,并消除某些易于在解釋中出現的視覺偽像。
模糊集成梯度方法通過測量一系列原始輸入圖像逐漸模糊的版本梯度(而不是像集成梯度那樣變暗的圖像)。盡管這看起來似乎是微小的差異,但作者認為這種選擇在理論上更為合理,因為模糊圖像不會像選擇基線圖像那樣在解釋中引入新的偽影。
杜賓犬圖像上的標準集成梯度(左)與模糊集成梯度(右),均使用平滑梯度進行了平滑。這里的模型是InceptionNet。
寫在最后
從2010年開始到現在,是機器學習在解釋方法方面碩果累累的十年,并且現在有大量用于解釋神經網絡行為的方法。我們已經在本篇文章中對它們進行了比較,我們非常感謝幾個很棒的圖書館,尤其是Gradio,來創建您在GIF和PAIR代碼的TensorFlow實現中看到的接口。用于所有接口的模型都是Inception Net圖像分類器。
原文標題:圖像識別解釋方法的視覺演變
文章出處:【微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
圖像識別
+關注
關注
9文章
521瀏覽量
38309 -
機器學習
+關注
關注
66文章
8428瀏覽量
132845 -
深度學習
+關注
關注
73文章
5510瀏覽量
121347
原文標題:圖像識別解釋方法的視覺演變
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI圖像識別攝像機






 工商網監
工商網監
評論