 如何通過深度學習完成計算機視覺中的所有工作?
如何通過深度學習完成計算機視覺中的所有工作?
你想做計算機視覺嗎?
如今,深度學習是必經之路。大規模數據集以及深層卷積神經網絡(CNN)的表征能力可提供超準確和強大的模型。但目前仍然只有一個挑戰:如何設計模型?像計算機視覺這樣廣泛而復雜的領域,解決方案并不總是清晰明了的。計算機視覺中的許多標準任務都需要特別考慮:分類、檢測、分割、姿態估計、增強和恢復以及動作識別。盡管最先進的網絡呈現出共同的模式,但它們都需要自己獨特的設計。那么,我們如何為所有這些不同的任務建立模型呢?作者在這里向你展示如何通過深度學習完成計算機視覺中的所有工作!
1、分類
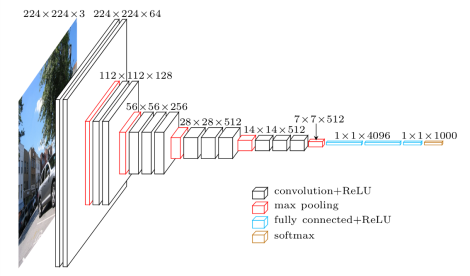
計算機視覺中最出名的就是分類。圖像分類網絡從一個固定大小的輸入開始。輸入圖像可以有任意數量的通道,但對于RGB圖像通常為3。在設計網絡時,分辨率在技術上可以是任意大小,只要足夠大到能夠支持在整個網絡中將要進行的向下采樣量即可。例如,如果你對網絡內的4個像素進行向下采樣,則你的輸入大小至少應為42= 16 x 16像素。隨著深入網絡,當我們嘗試壓縮所有信息并降至一維矢量表示形式時,空間分辨率將降低。為了確保網絡始終有能力將其提取的所有信息進行處理,我們根據深度的比例增加特征圖的數量,來適應空間分辨率的降低。也就是說,我們在向下采樣過程中損失了空間信息,為了適應這種損失,我們擴展了特征圖來增加我們的語義信息。在選擇了一定數量的向下采樣后,特征圖被矢量化并輸入到一系列完全連接的圖層中。最后一層的輸出與數據集中的類一樣多。
2、目標檢測
目標檢測器分為兩種:一級和二級。他們兩個都以錨框開始。這些是默認的邊界框。我們的檢測器將預測這些框與地面真相之間的差異,而不是直接預測這些框。在二級檢測器中,我們自然有兩個網絡:框提議網絡和分類網絡。框提議網絡在認為很有可能存在物體的情況下為邊界框提供坐標。再次,這些是相對于錨框。然后,分類網絡獲取每個邊界框中的潛在對象進行分類。在一級檢測器中,提議和分類器網絡融合為一個單一階段。網絡直接預測邊界框坐標和該框內的類。由于兩個階段融合在一起,所以一級檢測器往往比二級檢測器更快。但是由于兩個任務的分離,二級檢測器具有更高的精度。
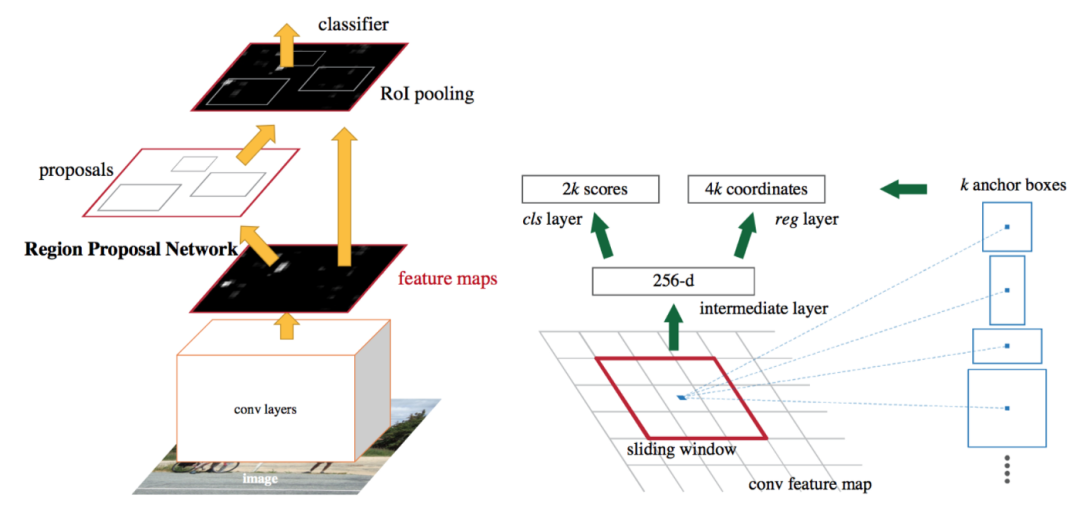
快速RCNN二級目標檢測架構
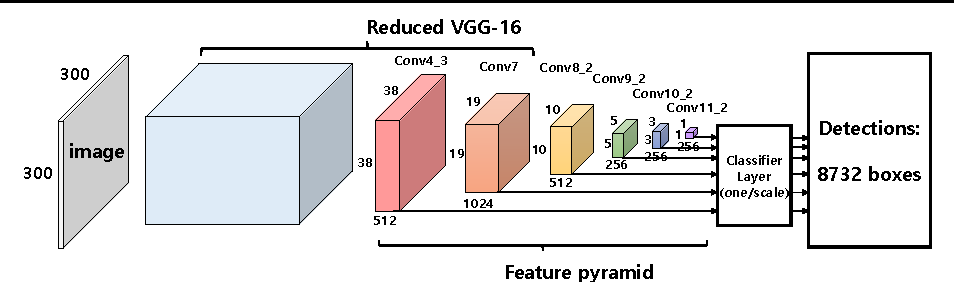
SSD一級目標檢測架構
3、分割
分割是計算機視覺中較獨特的任務之一,因為網絡既需要學習低級信息,也需要學習高級信息。低級信息可按像素精確分割圖像中的每個區域和對象,而高級信息可直接對這些像素進行分類。這導致網絡被設計為將來自較早層和高分辨率(低層空間信息)的信息與較深層和低分辨率(高層語義信息)相結合。如下所示,我們首先通過標準分類網絡運行圖像。然后,我們從網絡的每個階段提取特征,從而使用從低到高的范圍內的信息。每個信息級別在依次組合之前都是獨立處理的。當這些信息組合在一起時,我們對特征圖進行向上采樣,最終得到完整的圖像分辨率。
要了解更多關于如何分割與深度學習工作的細節,請查看這篇文章:
https://towardsdatascience.com/semantic-segmentation-with-deep-learning-a-guide-and-code-e52fc8958823
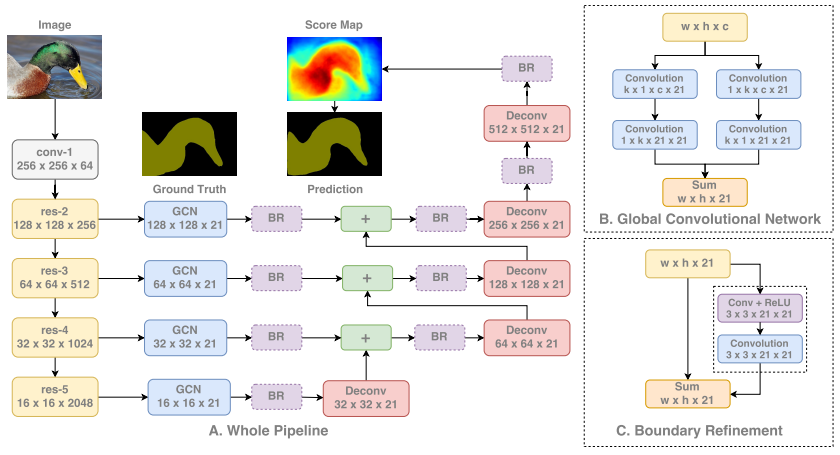
GCN細分架構
4、姿態估計
姿態估計模型需要完成兩個任務:(1)檢測圖像中每個身體部位的關鍵點;(2)找出如何正確連接這些關鍵點。這分以下三個階段完成:
使用標準分類網絡從圖像中提取特征。
給定這些特征,就可以訓練一個子網絡來預測一組2D熱圖。每個熱圖都與一個特定的關鍵點相關聯,并包含每個圖像像素關于是否可能存在關鍵點的置信值。
再次給出分類網絡的特征,我們訓練一個子網絡來預測一組2D向量場,其中每個向量場都與關鍵點之間的關聯度進行編碼。然后,具有較高關聯性的關鍵點被稱為已連接。
用這種方法訓練子網絡的模型,可以聯合優化關鍵點的檢測并將它們連接在一起。
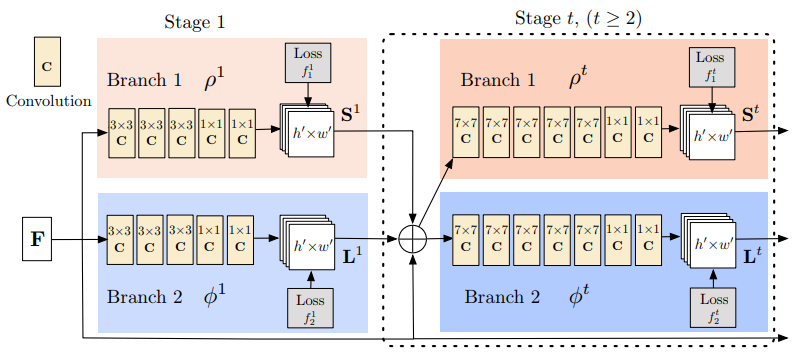
OpenPose姿態估計架構
5、增強和恢復
增強和恢復網絡是它們自己獨特的野獸。我們不會對此進行任何向下采樣,因為我們真正關心的是高像素/空間精度。向下采樣會真正抹殺這些信息,因為它將減少我們為空間精度而擁有的像素數。相反,所有處理都是在全圖像分辨率下完成的。我們開始以全分辨率將想要增強/恢復的圖像傳遞到我們的網絡,而無需進行任何修改。網絡僅由許多卷積和激活函數組成。這些塊通常是受啟發的,并且有時直接復制那些最初為圖像分類而開發的塊,例如殘差塊、密集塊、擠壓激勵塊等。最后一層沒有激活函數,即使是sigmoid或softmax也沒有,因為我們想直接預測圖像像素,不需要任何概率或分數。這就是所有這些類型的網絡。在圖像的全分辨率上進行了大量的處理,來達到較高的空間精度,使用了與其他任務相同的卷積。
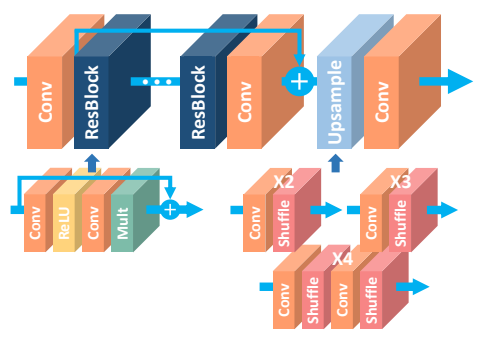
EDSR超分辨率架構
6、動作識別
動作識別是少數幾個需要視頻數據才能正常運行的應用程序之一。要對一個動作進行分類,我們需要了解隨著時間推移,場景中發生的變化, 這自然導致我們需要視頻。我們的網絡必須經過訓練來學習時空信息,即時空變化。最完美的網絡是3D-CNN。顧名思義,3D-CNN是使用3D卷積的卷積網絡。它們與常規CNN的不同之處在于,卷積是在3維上應用的:寬度、高度和時間。因此,每個輸出像素都是根據其周圍像素以及相同位置的前一幀和后一幀中的像素進行計算來預測的。
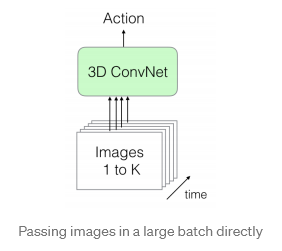
直接大量傳遞圖像視頻幀可以通過幾種方式傳遞:
直接在大批量中,例如第一個圖。由于我們正在傳遞一系列幀,因此空間和時間信息都是可用的。
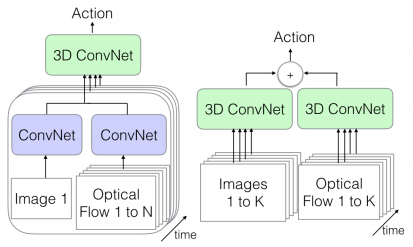
單幀+光流(左) 視頻+光流(右)
我們還可以在一個流中傳遞單個圖像幀(數據的空間信息),并從視頻中傳遞其相應的光流表示形式(數據的時間信息)。我們將使用常規2D CNN從這兩者中提取特征,然后再將其組合起來傳遞給我們的3D CNN,后者將兩種類型的信息進行合并。
將幀序列傳遞給一個3D CNN,并將視頻的光流表示傳遞給另一個3D CNN。這兩個數據流都具有可用的空間和時間信息。鑒于我們正在對視頻的兩種不同表示(均包含我們的所有信息)進行特定處理,因此這是最慢的選擇,但也可能是最準確的選擇。
所有這些網絡都輸出視頻的動作分類。
原文標題:如何通過深度學習,完成計算機視覺中的所有工作?
文章出處:【微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
計算機
+關注
關注
19文章
7496瀏覽量
88002 -
機器視覺
+關注
關注
162文章
4375瀏覽量
120345 -
人工智能
+關注
關注
1791文章
47294瀏覽量
238578
原文標題:如何通過深度學習,完成計算機視覺中的所有工作?
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【小白入門必看】一文讀懂深度學習計算機視覺技術及學習路線

計算機視覺有哪些優缺點
計算機視覺的工作原理和應用
計算機視覺與人工智能的關系是什么
計算機視覺與智能感知是干嘛的
計算機視覺怎么給圖像分類
深度學習在工業機器視覺檢測中的應用
計算機視覺的主要研究方向
計算機視覺的十大算法

計算機視覺:AI如何識別與理解圖像





 工商網監
工商網監
評論