 IBM 新款高能效 AI 芯片:能效比高過 NVIDIA A100
IBM 新款高能效 AI 芯片:能效比高過 NVIDIA A100
2 月 18 日報道,本屆集成電路設計領域頂會 “國際固態電路會議(ISSCC 2021)”正在進行中(2021 年 2 月 13 日到 22 日)。作為已有近 70 年歷史的集成電路產學屆盛會,ISSCC 2021 亦被許多廠商視為發布其領先芯片技術的權威舞臺。
本屆會議上,IBM 發表了據稱是 “全球首款”的高能效 AI 芯片,該芯片采用 7nm 制程工藝,可達到 80% 以上的訓練利用率和 60% 以上的推理利用率,而通常情況下,GPU 的利用率在 30% 以下。
性能參數方面,IBM 新品的運算密度高于同樣采用 7nm 工藝的 NVIDIA A100 GPU;其在多種精度下的整數運算性能,還優于聯發科 7nm 專用 AI 芯片等產品。
據 IBM 官網分享,其新款 7nm 高能效 AI 芯片該款芯片在多種場景中均有較好的應用前景,比如,可用于混合云環境中的低能耗 AI 訓練、或用于實現更接近邊緣的云端訓練等。
一、IBM 新款高能效 AI 芯片:能效比高過 NVIDIA A100
對比結果顯示,IBM 新款 7nm 高能效 AI 芯片的性能和能效,不同程度地超越了 IBM 此前推出的 14nm 芯片、韓國科學院(KAIST)推出的 65nm 芯片、阿里巴巴旗下芯片公司平頭哥推出的 12nm 芯片含光 800、NVIDIA 推出的 7nm 芯片 A100、聯發科推出的 7nm 芯片。
IBM 新款 7nm 高能效 AI 芯片支持 fp8、fp16、fp32、int4、int2 混合精度。
在 fp32 和 fp8 精度下,IBM 新款高能效 AI 芯片的每秒浮點運算次數,分別達到 16TFLOPS 和 25.6TFLOPS;運算密度分別為 0.82TFLOPS/mm^2 和 1.31TFLOPS/mm^2;能效比分別為 3.5TFLOPS/W 和 1.9TFLOPS。
在 int2 和 int4 精度下,IBM 新款高能效 AI 芯片的運算密度分別為 3.27TOPS/mm^2 和 5.22TOPS/mm^2;能效比分別為 16.5TOPS/W 和 8.9TOPS/W。
對比之下,IBM 此前推出的 14nm 芯片在 fp32 和 fp8 精度下的每秒浮點運算次數,分別為 2TFLOPS 和 3TFLOPS;在在 fp32 精度下的能效比為 1.4TFLOPS/W。
另外,在 7nm 芯片陣營中,NVIDIA A100 GPU 在 fp16 精度下的能效比為 0.78TFLOPS/W,在 int4 精度下的能效比為 3.12TOPS/W,均低于 IBM 新款高能效 AI 芯片。
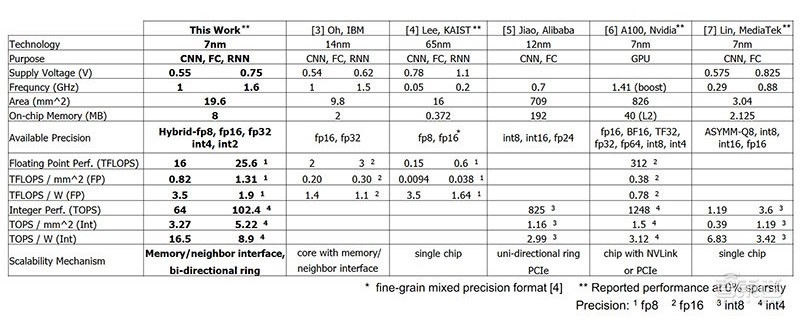
▲ IBM 新款高能效 AI 芯片與同類產品的性能參數對比
二、采用 IBM 自研超低精度訓練 / 推理設計
IBM 官網文章寫道,其新款 AI 芯片之所以能夠兼顧能效和性能,是因為該芯片支持超低精度混合 8 位浮點格式((HFP8,hybrid FP8)。這是 IBM 于 2019 年發布的一種高度優化設計,允許 AI 芯片在低精度下完成訓練任務和不同 AI 模型的推理任務,同時避免任何質量損失。
據悉,目前 IBM 將超低精度混合 8 位浮點格式用于訓練、超低精度混合 4 位浮點格式用于推理,并開發了數據通信協議,以提升多核心 AI 芯片上不同核心間的數據交換效率。
據 IBM 官網文章,自 2015 年起,該公司每年將芯片的功耗性能提升 2.5 倍。這背后,IBM 致力于實現算法、架構、軟件堆棧等各方面的創新。
▲ IBM 在低精度 AI 訓練、推理方面的研究歷程
除了采用超低精度混合 8 位浮點格式外,IBM 新款高能效 AI 芯片添加了電源管理功能。IBM 研究顯示,在同等功率的情況下,通過減緩計算階段的功率消耗,可以最大限度地提升芯片性能。
結語:AI 發展對芯片能耗提出更高要求
隨著智能化浪潮席卷各個領域,AI 模型的復雜性日趨提高。相應地,AI 應用的能源消耗水平亦水漲船高。這一背景下,如何最大限度提升能效,成為 AI 芯片設計玩家們面臨的重要命題。
IBM 通過采用超低精度混合 8 位浮點格式和內置電源管理功能,為其新款 AI 芯片實現了業界領先的高能效。但是,這一芯片尚未實現規模化量產,仍有待市場檢驗。
責任編輯:PSY
-
芯片
+關注
關注
456文章
50873瀏覽量
424073 -
IBM
+關注
關注
3文章
1757瀏覽量
74713 -
NVIDIA
+關注
關注
14文章
4991瀏覽量
103134 -
AI
+關注
關注
87文章
30979瀏覽量
269249
發布評論請先 登錄
相關推薦
安科瑞能效管理監測云平臺
Erp指令能效
直播預約 |開源芯片系列講座第24期:SRAM存算一體:賦能高能效RISC-V計算

上海貝嶺超小封裝物聯網能效監測芯片BL0971介紹

安森美推動數據中心能效革新
智慧水務綜合能效管理系統-提高污水廠能效
聯發科天璣9400發布:能效比與端側AI引領移動芯片行業革新

此芯科技發布“此芯P1”異構高能效芯片,引領AI PC新紀元
利用AI和加速計算提升天氣預報效率和能效
智慧水務能效管理平臺-為污水處理的能效管理提供科學、精細的解決方案
華為GigaGreen創新發布,構筑5G-A時代極致體驗、極致能效







 工商網監
工商網監
評論