") AMD Instinct MI200計(jì)算卡首曝:用上MCM多芯封裝
AMD Instinct MI200計(jì)算卡首曝:用上MCM多芯封裝
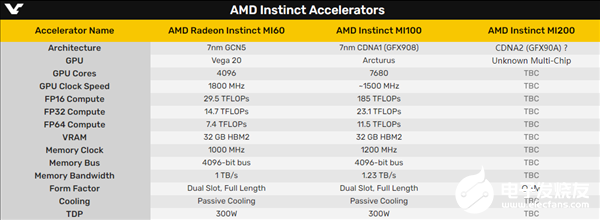
去年11月份,AMD發(fā)布了頂級(jí)加速計(jì)算卡Instinct MI100,首次采用針對(duì)HPC高性能計(jì)算、AI人工智能全新設(shè)計(jì)的CDNA架構(gòu),和游戲向的RDNA架構(gòu)截然不同。現(xiàn)在,第二代的MI200也首次浮出了水面。
MI100采用臺(tái)積電7nm工藝制造,集成120個(gè)計(jì)算單元、7680個(gè)流處理器,并專門(mén)加入Matrix Core(矩陣核心)用于加速HPC、AI運(yùn)算,還整合了4096-bit 32GB HBM2顯存,支持PCIe 4.0 x16和八卡并行,整卡功耗300W。
它的FP64雙精度浮點(diǎn)性能首次突破10TFlops(也就是每秒1億億次),混合精度和FP16半精度的AI性能提升接近7倍。
根據(jù)最新消息,MI200將會(huì)采用下一代CNDA架構(gòu),并首次引入MCM多芯片封裝,看這樣子翻番到1.5萬(wàn)個(gè)流處理器問(wèn)題不大。
本次曝光的MI200將用于HPE Cray EX超級(jí)計(jì)算機(jī),執(zhí)行加速計(jì)算,產(chǎn)品名被描述為“MCM Special FIO Accelerator”,其中FIO代表“Factory Installation Option”(廠商安裝選項(xiàng)),此外還有OAM形態(tài),代表開(kāi)源加速卡。
不過(guò),MI200的具體規(guī)格目前一無(wú)所知,除了猜測(cè)流處理器可能因?yàn)镸CM封裝而翻一番,還有望加入FullRate640ps指令集、支持全速率FP64浮點(diǎn)計(jì)算。

MI200預(yù)計(jì)今年晚些時(shí)候發(fā)布,未來(lái)將搭配代號(hào)“Trento”(特倫托)的霄龍?zhí)幚砥鳎餐糜贏MD為美國(guó)國(guó)防部打造的百億億次超級(jí)計(jì)算機(jī)“Frontier”。
Trento并未出現(xiàn)在AMD霄龍演進(jìn)路線圖上,其實(shí)是即將發(fā)布的第三代“Milan”(米蘭)的定制版,專為超算優(yōu)化,可能會(huì)提前支持PCIe 5.0。
責(zé)任編輯:PSY
-
芯片
+關(guān)注
關(guān)注
455文章
50817瀏覽量
423680 -
amd
+關(guān)注
關(guān)注
25文章
5468瀏覽量
134169 -
計(jì)算卡
+關(guān)注
關(guān)注
0文章
14瀏覽量
3232
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
AMD最強(qiáng)AI芯片,性能強(qiáng)過(guò)英偉達(dá)H200,但市場(chǎng)仍不買賬,生態(tài)是最大短板?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論