") 有關(guān)AV1的編碼器優(yōu)化技術(shù)
有關(guān)AV1的編碼器優(yōu)化技術(shù)
AV1視頻編解碼器是一種由開放媒體聯(lián)盟AOM開發(fā)的royalty-free的壓縮技術(shù)。libaom庫是AV1的參考軟件,應(yīng)用各種編碼器優(yōu)化技術(shù)來實(shí)現(xiàn)更好的編碼效率。本次分享,我們邀請到了來自Google 的李博晗,一起來討論 GOP優(yōu)化、時(shí)域濾波器、libaom庫的其他改進(jìn)以及正在進(jìn)行的一些工作。
大家好!我是來自Google網(wǎng)絡(luò)媒體團(tuán)隊(duì)的李博晗。今天,我將討論有關(guān)AV1的編碼器優(yōu)化技術(shù)。 1 概 述

AV1視頻編解碼器是一種由開放媒體聯(lián)盟AOM開發(fā)的royalty-free的壓縮技術(shù)。它于2018年發(fā)布,與其前身(VP9)相比,AV1提高了約30%的壓縮效率。libaom庫是AV1的參考軟件,它也是由大量AOM的成員開發(fā)的,且它是開源的。libaom庫使用了各種編碼器優(yōu)化技術(shù)以便達(dá)到更好的編碼效率。今天,我們將討論其中的部分技術(shù)。 首先我們將討論GOP優(yōu)化;接著,我們會討論時(shí)域?yàn)V波器;其后,我們還將提到libaom庫的其他改進(jìn)和一些正在進(jìn)行的工作。 2 GDP優(yōu)化
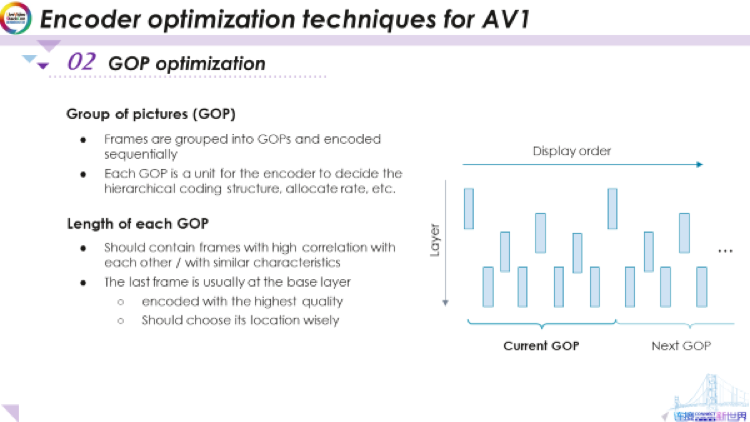
首先是GOP優(yōu)化,GOP代表圖片組(group of picture)。我們要編碼的視頻序列有很多幀,編碼器會將這些幀分組為GOP。然后,編碼器將順序?qū)γ總€GOP進(jìn)行編碼。基本上GOP是用于決定諸如分層編碼結(jié)構(gòu)和碼率分配等的基本單元。舉一個例子,這是一個包含九幀的GOP。
GOP內(nèi)具有層次結(jié)構(gòu),基礎(chǔ)層一般包括第一幀和最后一幀。可以從這兩個幀來預(yù)測下一層的幀。而再下一層的幀可以由這個三個幀來預(yù)測,以此類推。現(xiàn)在,我們想要確定每個GOP的長度。它的長度非常重要,因?yàn)閺闹庇X上來說,我們希望每個GOP中的幀都包含具有相似特征,或者這些幀在GOP內(nèi)部存在更高的相關(guān)性。
想要知道GOP的長度,就要確定最后一幀在哪里。通常,最后一幀位于基礎(chǔ)層,這意味著它將被用于預(yù)測此GOP中存在的所有其他幀。因此,為了提供更好的預(yù)測,我們想為最后一幀分配更高的質(zhì)量。
但是,如果我們錯誤地分配了GOP,例如,這里的最后一幀,如果它位于非常糟糕的位置,與其他幀之間相關(guān)性較低(比如GOP停止在場景更改的中間),那么即使我們此幀的重建質(zhì)量非常高,也不會幫助到其他幀的預(yù)測。
2.1 Utilizing first-pass stats

從直覺出發(fā),我們希望可以確定GOP的長度,使得最后一幀可以更好的預(yù)測其他幀。我們可以使用一些自適應(yīng)方法來確定每個GOP應(yīng)該多長以及最后一幀應(yīng)該在哪里。在這里我們使用第一次編碼(first-pass)數(shù)據(jù)。liibom支持兩次(two-pass)編碼,它先將所有幀編碼處理一次,然后收集數(shù)據(jù),再重新對所有幀進(jìn)行編碼。第一部分很快,而第二部分才是真正的編碼——它使用所有從第一部分收集到的各種幀級別的統(tǒng)計(jì)信息。
在這里有三個第一次編碼數(shù)據(jù)的示例,分別是幀內(nèi)編碼錯誤,一階編碼錯誤和二階編碼錯誤。幀內(nèi)編碼錯誤意味著在從其他幀預(yù)測的情況下對該幀進(jìn)行幀內(nèi)預(yù)測而得到的平均誤差。一階編碼錯誤和我們前面提到的幀內(nèi)編碼錯誤意義相似,只是我們不僅可以進(jìn)行幀內(nèi)編碼,還可以進(jìn)行幀間預(yù)測,不過必須通過前一幀。這樣,該幀的最大平均預(yù)測誤差,就是一階編碼錯誤,二階編碼錯誤也非常相似。我們?nèi)匀豢梢允褂脦瑑?nèi)編碼或進(jìn)行幀間預(yù)測,但是只能使用相隔兩幀的那一幀,這樣就得到了二階編碼錯誤。
擁有這些很多幀級別的特征和數(shù)據(jù),我們要使用它們來確定GOP的長度。我們想從這些統(tǒng)計(jì)信息中,獲悉或者至少估計(jì)一下幀之間的相關(guān)性,以及其他一些我們關(guān)注的特征,并依此來分析第一遍的統(tǒng)計(jì)數(shù)據(jù)。
2.2 The hidden Markov model
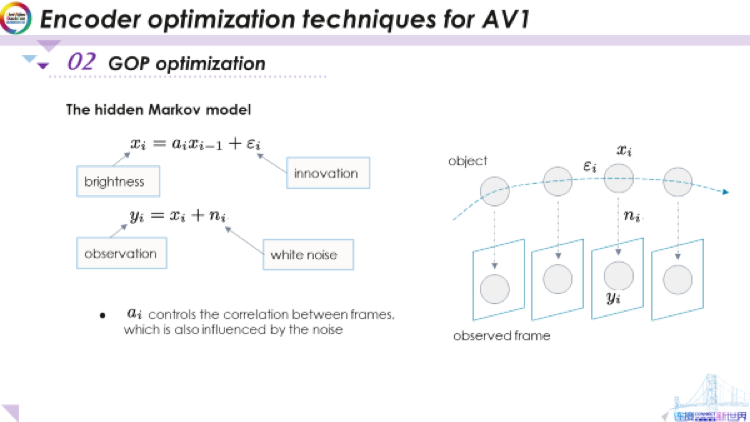
這里,我們使用隱馬爾可夫模型(HMM)。該模型假設(shè)兩件事,首先,它假定基礎(chǔ)對象的亮度遵循馬爾可夫鏈。在此示例中,我們可以看這個球,此球沿著這樣的軌跡移動。沿著該運(yùn)動軌跡,我們用xi表示在時(shí)間i的亮度。這個模型是一個回歸模型,但與自動回歸略微有所不同,因?yàn)?a href="http://www.xsypw.cn/tags/ai/" target="_blank">ai會變化。對于xi來說,這是一個馬爾可夫鏈,因?yàn)槟憧梢钥吹?x 在時(shí)間 i 的亮度,僅取決于 x 在時(shí)間 i-1 的亮度。在此條件下,它與以前所有的亮度都沒有關(guān)系,這就是馬爾可夫模型。
馬爾可夫模型已被廣泛用于對運(yùn)動對象在運(yùn)動軌跡上的建模。這里的ε是創(chuàng)新項(xiàng)(也就是新息),創(chuàng)新項(xiàng)代表xi無法從xi-1中預(yù)測的部分。例如,當(dāng)光逐漸變化,或者物體在其表面上有一些細(xì)微的變化時(shí),你將無法得到精確為 1 的相關(guān)性,而可能會得到0.95、0.98之類的值,以及這樣一個無法預(yù)測的創(chuàng)新項(xiàng)。這基本就是我們使用的馬爾可夫模型。
應(yīng)用這里的馬爾可夫模型,我們進(jìn)一步假設(shè)當(dāng)觀察物體的亮度時(shí),例如如下所示,捕獲每一幀視頻時(shí)將會捕獲到噪聲,那些噪聲并不依賴于創(chuàng)新項(xiàng),實(shí)際上也與xi無關(guān)。它們只是捕獲時(shí)的加性噪聲。在這里用另一個隨機(jī)變量ni對表示這些噪聲。我們假設(shè)它是IID(獨(dú)立同分布)的白噪聲。這樣我們便得到觀察值yi。可以看到,因?yàn)樵肼暤拇嬖冢趯κ挛镞M(jìn)行編碼時(shí)我們根本無法直接得知xi,而只能訪問觀測值 yi。我們在這里得出的yi以及它背后的模型,這就是一個隱馬爾可夫模型,也就是指實(shí)際的馬爾科夫模型被這種噪聲隱藏了。
以上是一個隱馬爾科夫模型的非常簡單的示例,這就是我們對模型的假設(shè)。要注意有兩點(diǎn)非常重要,第一是一個重要參數(shù)ai。ai基本控制著幀之間的相關(guān)性,如果假設(shè)xi的方差不變,則ai就是xi和xi-1 之間的相關(guān)系數(shù)。從我們的出發(fā)點(diǎn)來看,我們希望能夠估測幀之間的相關(guān)性,ai能夠幫助我們借用此模型來估測。同時(shí),我們也想了解噪聲有多大,從實(shí)際情況來看,噪聲的方差也很重要。
2.3 Optimal linear prediction error

我們能觀測到在任意的時(shí)間點(diǎn)i和j的觀測值yi和yj,并希望能夠估測ai和噪聲。為了能做到這一點(diǎn),我們首先假設(shè)我們使用最優(yōu)線性預(yù)測器,也就是用一個系數(shù)w乘以yj來預(yù)測yi。如果我們考慮最優(yōu)線性預(yù)測的誤差,且使用先前的模型進(jìn)行計(jì)算的話你最終會得到這個等式。此處顯示了最佳線性預(yù)測誤差e^i,j。這個等式是由幾個部分組成的。首先,你需要yi和yj的方差,以及從 j 到 i的ak,還需要該幀的噪聲的方差。有了這個方程式。回過頭來,我們將討論如何使用它來預(yù)測ai。

讓我們來看看,首先,知道在這個方程式中,實(shí)際上很多東西可以直接從第一遍統(tǒng)計(jì)數(shù)據(jù)中估算出來。
例如yi的方差,也就是觀察到的像素方差,可以用幀內(nèi)編碼錯誤用以近似估計(jì)。其背后的原因是,當(dāng)你進(jìn)行幀內(nèi)預(yù)測時(shí),可以使用其相鄰像素預(yù)測該塊。然后從該塊中移除該預(yù)測,這與減去估算出的區(qū)塊平均值非常相似。這樣的話,則幀內(nèi)編碼錯誤基本上就可以看作像素的方差。這并非完全準(zhǔn)確,但非常接近。
其后,當(dāng)j等于i-1時(shí),我們是在從前一幀來預(yù)測當(dāng)前幀。而這恰恰是我們所說的一階編碼錯誤的含義。同理,如果j等于i-2,最佳線性預(yù)測誤差就基本可以看作是二階編碼錯誤。因此,我們使用這三個第一遍統(tǒng)計(jì)信息來估測隨機(jī)變量的這三個特征。我們將獲得y的方差,e^i,i-1的方差和e^i,i-2的方差。
2.4 Estimate correlation from first-pass stats

如果假設(shè)所有這些都成立,同時(shí)再假設(shè)該鄰域中的噪聲方差不變,即nj的方差在該鄰域中保持不變,那么我們可以針對幀i,j寫出以下幾個等式。一個是從 i-1 預(yù)測 i,一個是從i -2預(yù)測i-1,還以一個是從i -2預(yù)測 i。也就是說我們關(guān)心這三個幀,以及其對應(yīng)的三個預(yù)測。現(xiàn)在,如果你寫下這三個方程式,你將會發(fā)現(xiàn),實(shí)際上我們只有三個未知變量,即ai-1,ai-2,以及該鄰域中的噪聲方差。因而,基于這三個方程,我們可以很輕松地計(jì)算出這三個未知變量。算出之后,也就可以得到ai,aj,可以得到噪聲方差。到目前為止,基于此隱馬爾可夫模型,我們成功地僅通過第一遍的數(shù)據(jù),就能夠通過幀鄰域來估測幀與幀之間的相關(guān)性以及噪聲水平。
2.5 Frame regions and GOP length decision

如果現(xiàn)在我們想使用分析出的相關(guān)性和噪聲水平,來決定GOP長度。首先要做的是確定幀區(qū)域的類型,幀可能處于穩(wěn)定區(qū)域或不穩(wěn)定區(qū)域中。
我們將不穩(wěn)定區(qū)域分為三種:一種是高變化區(qū)域,它其中的幀會變化得較快;一種是場景切換,它會突然改變幀內(nèi)容;還有一種是漸變區(qū)域,這經(jīng)常出現(xiàn)在電影以及其他內(nèi)容類型的視頻中,一個場景淡出的同時(shí),另一個場景淡入。有了這四種類型的幀區(qū)域,首先我們要將每一幀分組到這些區(qū)域中。該分組使用前面分析第一遍統(tǒng)計(jì)數(shù)據(jù)得到的ai,噪聲水平和其他數(shù)據(jù)。

有了這些幀區(qū)域后,我們希望最終決定的GOP不包括場景切換,也就是不在一組圖片中改變場景。同時(shí)還希望該GOP的最后一幀找到處于穩(wěn)定區(qū)域,這背后的原因是,如果它在穩(wěn)定區(qū)域中,則意味著它可以很好地預(yù)測其相鄰幀。這是我們的首選,如果無法在穩(wěn)定的區(qū)域中找到結(jié)束幀,我們將嘗試在高變化區(qū)域內(nèi)找到相對穩(wěn)定的幀。
同時(shí),我們也要確保我們不會在漸變區(qū)域的中間放置最后一幀。因?yàn)橥ㄟ^使用雙向多參考,實(shí)際上可以很好地對漸變區(qū)域進(jìn)行預(yù)測。如果我們將其切開,則意味著預(yù)測將變得比較難。因而,我們一般希望將漸變區(qū)域放入一個單獨(dú)的GOP中,而不想將它從中切開。可以看到,一旦我們得到所有幀區(qū)域,這些邏輯是很簡單的。
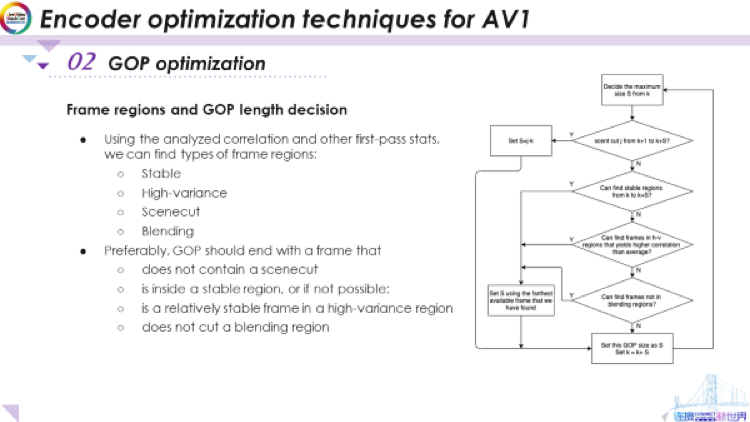
此處以流程圖形式展示以上的邏輯。在這里我不想再談得過于深入,但基本邏輯就如我們在這里所描述的這樣。
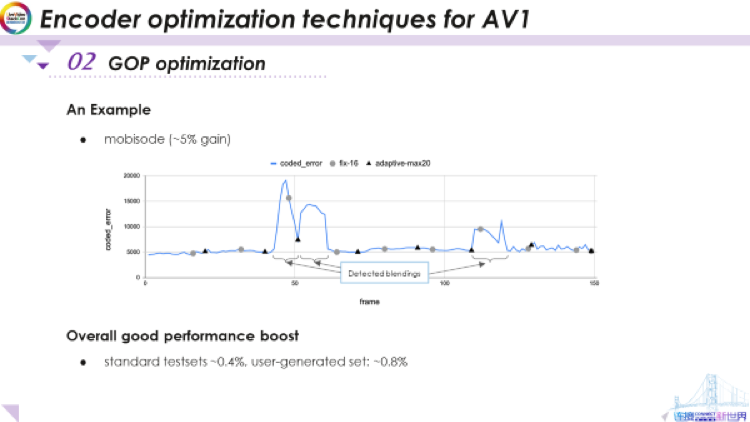
上圖是GOP長度優(yōu)化的一個例子。這里展示了幀的編碼錯誤。這是我們標(biāo)準(zhǔn)測試集中的mobisode視頻序列。這些編碼錯誤顯示了它與前一幀相比發(fā)生了多大變化。
你可以看到直到第40幀左右為止它的場景都相當(dāng)穩(wěn)定。而在40幀這里實(shí)際上是一個場景切換,這是一個漸變場景——實(shí)際上視頻中的人正在慢慢打開燈,在它(場景)之后這兒又有一個漸變場景。之后一段時(shí)間內(nèi)情況很穩(wěn)定,然后,就在這里還有另一個漸變場景。之后它會稍微穩(wěn)定一些,有點(diǎn)高變化,不過并不劇烈。這就是視頻序列的情況。
現(xiàn)在看這里的灰色圓圈,這些圓圈是最初由編解碼器在沒有此自適應(yīng)GOP技術(shù)的情況下完成的GOP長度決策。可以看到實(shí)際上切割發(fā)生在了該區(qū)域的中間。而且就在這個漸變區(qū)域的中間,這并不是我們真正想要的。通過自適應(yīng)方法得到的結(jié)果用黑色三角形表示,這是我們實(shí)際切割GOP的地方。
我們將最大間隙長度設(shè)置為20——而之前是固定為16。然后,如你所見,它選擇了最佳的切割位置,這是一個GOP,在這里附近切割。不過它沒有在漸變區(qū)域內(nèi)切割,以及下在一個漸變區(qū)域之前就結(jié)束了當(dāng)前GOP。對于這個序列,如果我們可以像這樣準(zhǔn)確地切割GOP,我們會得到大約5%的增益,對于僅是更改GOP而言,這是相當(dāng)大的。
如你所見,此方法可能相當(dāng)高效,但這具體取決于視頻的內(nèi)容。當(dāng)然,如果視頻非常穩(wěn)定,則無需在此處進(jìn)行太多調(diào)整,也不會有太多增益。但是如果對于這樣具有某些特定特征的序列,你將獲得很大增益。標(biāo)準(zhǔn)測試集中我們能看到平均0.4%(已經(jīng)比較大的)左右的增益,但是在用戶生成集中,我們看到的增益更大,約0.8%。因?yàn)閷τ谟脩羯杉裕蠖鄶?shù)視頻比標(biāo)準(zhǔn)測試集中的視頻更加不穩(wěn)定,其中有的是通過一直晃動的手機(jī)拍攝的,有的是包含像場景剪輯、光線變化之類快速變化的內(nèi)容。對于它們,自適應(yīng)GOP方法可以提供更多幫助。以上就是有關(guān)libaom編碼器中的自適應(yīng)GOP優(yōu)化的內(nèi)容。接下來我們要談?wù)剷r(shí)域?yàn)V波。
3 時(shí)域?yàn)V波
3.1 Frame decomposition
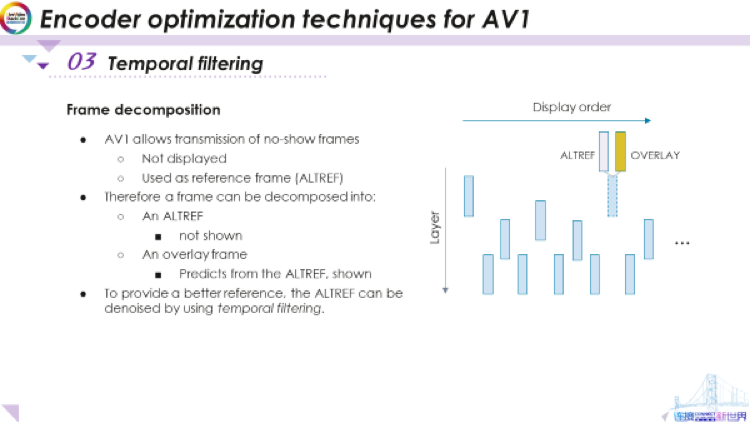
首先我們需要提到AV1中的幀分解。AV1可將一幀分解為一個未顯示幀和一個覆蓋顯示幀。如此處所示,這仍然是我們的GOP。很多時(shí)候,GOP的最后一幀,或我們稱為ALTREF的幀,會被分解為兩幀,一個ALTREF和一個覆蓋幀。這里的想法是,我們將對ALTREF進(jìn)行編碼。
然后,解碼器將解碼它,但不會顯示,只是將其保存在幀緩沖區(qū)中,并用以對其他幀進(jìn)行預(yù)測。之所以要這樣做,是因?yàn)槲覀兿M軌驅(qū)υ搸M(jìn)行某些處理,以便其可以為其他幀更好地提供預(yù)測。當(dāng)我們完成了其他幀之后又回到了這一幀時(shí),我們不直接顯示該幀,而是再添加一個疊加幀,以修正我們對該幀的處理,這便是覆蓋幀的作用。
綜上所述,我們有一個通常沒有顯示的替代參考幀ALTREF,根據(jù)ALTREF預(yù)測我們得到一個覆蓋幀,能夠修正前面的處理,并且顯示出來,這就是每個幀的分解。正如我提到的為了提供更好的預(yù)測,我們想對ALTREF進(jìn)行處理,使其可以很好地預(yù)測其他幀,在libaom編碼器中可行的一種方法是使用時(shí)域?yàn)V波器。 3.2 Temporal filtering of a frame
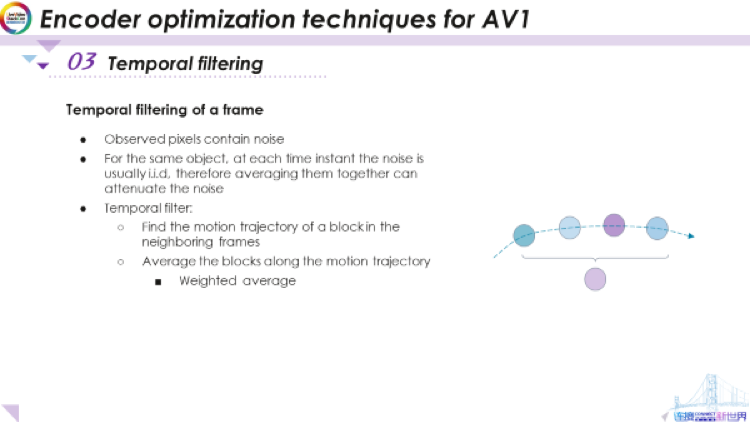
那么,什么是時(shí)域?yàn)V波器呢?讓我們來看看,例如,對于某個像素,假設(shè)我要研究該像素的運(yùn)動軌跡,正如我們前面提到的,運(yùn)動軌跡存在觀察噪聲,而我們希望能夠?yàn)V除該噪聲。要做到這一點(diǎn),我們對該軌跡上的像素進(jìn)行平均,假設(shè)像素實(shí)際亮度沒有變化,但是存在噪聲,那么通過這種方式進(jìn)行均衡,噪聲將有所減少,但像素原始值不會改變。這就是使用時(shí)域?yàn)V波器來降低噪聲的基本想法。
時(shí)間過濾包含了幾個步驟,第一步是通過運(yùn)動估計(jì)及運(yùn)動搜索來找到運(yùn)動軌跡。如果我們可以為這些對象的像素塊在每一幀中尋找合適的位置,我們就可以對各個塊進(jìn)行平均,以降低噪聲水平,從而達(dá)到預(yù)期的效果。然而,實(shí)際上,這并非易事,因?yàn)槲覀冃枰獙λ袑ο笄蠹訖?quán)平均值,也就是說需要確定運(yùn)動規(guī)矩上每個像素的權(quán)重。我們接下來會討論這一點(diǎn)。

出于實(shí)際考慮,首先,我們并沒有真正的運(yùn)動軌跡,我們能做到的最好就是嘗試進(jìn)行運(yùn)動估計(jì)。而且由于我們只是在處理幀,無法真正執(zhí)行非常好的運(yùn)動搜索,而大多數(shù)時(shí)候只是使用一個快速的算法,因此我們獲得的運(yùn)動軌跡的運(yùn)動矢量并不總是準(zhǔn)確的,甚至有時(shí)候很不準(zhǔn)確。我們還需要注意的是,過濾后的ALTREF幀并不一定是其他幀中唯一可用的參考幀,它們也可以參考其他可用的參考幀。因此,僅將所有這些像素放在一起求平均可能不是一個好主意,因?yàn)槟承粫眠@個參考幀來預(yù)測。因而,我們需要慎重考慮設(shè)定權(quán)重。 為了確定權(quán)重,我們提出以下直觀原因,首先,如果我們找到一些塊的運(yùn)動軌跡,我們在這個軌跡中找到對應(yīng)的像素塊,然后將該塊與幀過濾源進(jìn)行比較。如果這兩個區(qū)塊彼此之間差異太大,這意味著我們當(dāng)前的運(yùn)動矢量非常糟糕,或者我們觀測到來非常高的噪聲影響,兩者皆有可能。
如果發(fā)生這種情況,我們可能不想為該塊分配太高的權(quán)重,因?yàn)楹苡锌赡茉搲K并不會不使用ALTREF作為參考或運(yùn)動矢量不好,我們也不想冒險(xiǎn)。
因此我們使用一種稱為非局部均值的方法來計(jì)算塊差異,并確定我們要分配給該塊的權(quán)重,這是一方面。另一個直觀感受是我們想要降低噪聲,因此當(dāng)噪聲水平較高時(shí)我們就傾向于使用更強(qiáng)的濾波。我們需要能夠估計(jì)噪聲水平,因而,我們在幀內(nèi)有一個噪聲水平估計(jì)算法,一旦噪聲很高時(shí),我們便使用更強(qiáng)的過濾器。這個噪聲水平估計(jì)及其影響也被并入我們的非本地均值方法之中。

總體過濾方案如下:首先,我們要確定要使用的相鄰幀的數(shù)量,這很重要,如果說有一個場景變換,或者說幀之間相關(guān)性不是很高,我們將使用更少的幀數(shù)。反之,當(dāng)運(yùn)動比較穩(wěn)定時(shí),我們可以使用更多的幀,因?yàn)榧僭O(shè)運(yùn)動矢量良好,使用更多的幀可以將噪聲控制在較低水平。
幀數(shù)一旦確定,對于想過濾的幀中的每個塊,我們先在相鄰幀中找到匹配的塊,然后使用非局部均值方法來確定這些幀中每個塊的相關(guān)權(quán)重,接著應(yīng)用過濾器計(jì)算得到所有區(qū)塊的加權(quán)平均值。基本方法就是這樣,還有很多細(xì)節(jié)的內(nèi)容我們這里不再作介紹。
從(這里引用的)文中你可以看到,在標(biāo)準(zhǔn)測試集上,這個方法得到了相當(dāng)大的增益,約2.4%。因此,在給出更好的預(yù)測方面,這種時(shí)間過濾器實(shí)際上非常有效。以上是時(shí)間過濾器相關(guān)內(nèi)容。 以上我們舉了兩個例子,GOP長度決策和時(shí)域?yàn)V波器。我們在libaom庫中還有很多其他的改進(jìn)。 4 其他改進(jìn)

首先是運(yùn)動搜索模式,我們改為使用八邊形運(yùn)動搜索模式。之前我們使用的是棱形或四角搜索,但是現(xiàn)在我們我們使用八邊形,它基本上是八點(diǎn)搜索模式,可以更好地適應(yīng)復(fù)雜的角度。而且我們調(diào)整了采樣半徑,之前是2的次方,越遠(yuǎn),它越粗糙。但是現(xiàn)在我們對其作了一些微調(diào),并借此獲得了一些增益。我們還要注意的另一件事是從最近的報(bào)告來看,似乎,復(fù)合運(yùn)動搜索并沒有帶來先前預(yù)期的那般增益。
復(fù)合模式是我們有多個參考塊,然后將參考結(jié)合在一起以創(chuàng)建對該區(qū)塊的預(yù)測。大多數(shù)的時(shí)間它是雙向或單向的,我們注意到它并沒有像預(yù)期的那樣帶來可觀的增益,但是復(fù)合運(yùn)動搜索模式實(shí)際上非常強(qiáng)大,它擁有各種模式來適應(yīng)不同的條件。
所以,我們的確寄希望它會有更好的增益,這就是為什么我們最近正在重新設(shè)計(jì)復(fù)合模式的算法。這其中有很多速度方面的功能,現(xiàn)在我們正在嘗試重新設(shè)計(jì)它們。其中一些改變已經(jīng)在代碼中了,并獲得不錯的增益效果。 另一個非常重要的事是碼率控制。目前,碼率控制是不易做到的一塊。AV1中的原始碼率控制方案比較復(fù)雜,我們試圖簡化,重新設(shè)計(jì)控制邏輯,而且也希望借此獲得更好的控制性能,我們不想犧牲任何東西。目前,有嚴(yán)格的碼率控制條件時(shí),也就是當(dāng)碼率控制非常準(zhǔn)確時(shí),與以前相比,壓縮性能比以前變得更好。我們?nèi)栽谂κ沟迷谀撤N程度上更寬松的控制情況下它能運(yùn)行得更好。
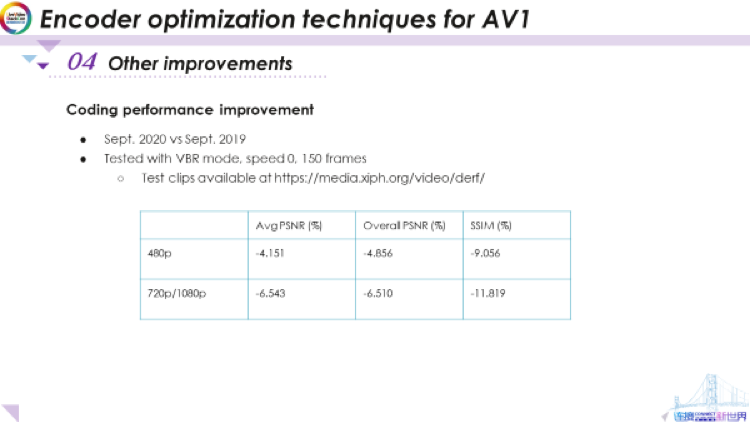
這里展示了編碼性能的提高。這是使用VBR模式(可變比特率模式),速度0(這是最高性能),150幀,今年(2020年)9月與去年9月的對比,視頻序列可在此處網(wǎng)址上找到。我們測試了很多視頻序列,并計(jì)算了平均增益。對于480p的中分辨率視頻,PSNR的增益約為4-5%,SSIM的增益約為9%。
這是相當(dāng)高的。對于720和1080p這類較高分辨率的視頻內(nèi)容,我們的PSNR增益約為6.5%,而SSIM的增益約為11%至12%。考慮到AV1本身的性能要比vp9約好30%,這些都是相當(dāng)不錯的增益,且僅基于編碼器優(yōu)化。我們認(rèn)為libaom庫的性能還有較大的提升空間,我們也將繼續(xù)為之努力。
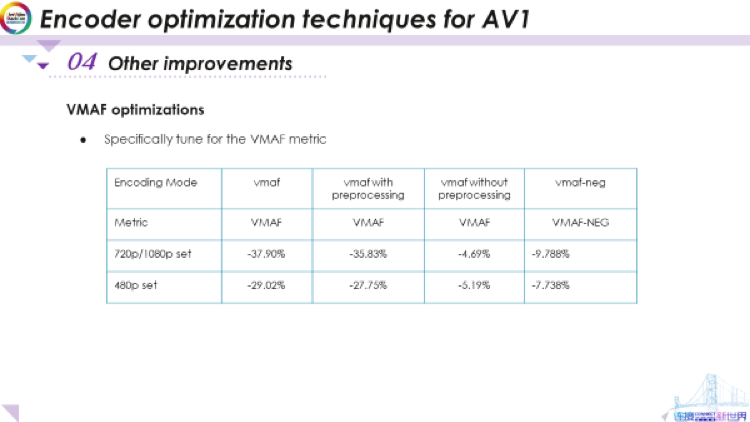
我們還要提到VMAF,這是一項(xiàng)以主觀質(zhì)量為目標(biāo)的客觀質(zhì)量指標(biāo)。我們也有一個特定的調(diào)優(yōu)模式,它有命令行選項(xiàng)。如果我們使用VMAF進(jìn)行調(diào)優(yōu),我們大約能獲得30%到40%的增益,這是巨大的,但這是要通過先對視頻進(jìn)行銳化然后運(yùn)行所有編碼來達(dá)到的。
如果沒有經(jīng)過預(yù)處理,我們將獲得大約5%的增益,在沒有經(jīng)過銳化的情況下,這也非常可觀了。最近VMAF NEG模式也被提出,在這個模式下我們不過多地專注于預(yù)處理導(dǎo)致的影響。不過即使如此,我們的調(diào)優(yōu)模式也可以使它獲得大約8%到10%的增益。因此,如果你關(guān)心VMAF指標(biāo),你可以嘗試一下libaom庫的這些功能。

還有一點(diǎn)值得注意的,是我們的文檔。libaom是一個非常大的代碼庫,為了可以促進(jìn)開發(fā)者加入貢獻(xiàn),也使其作為參考編碼器更容易理解,我們進(jìn)行了優(yōu)化文檔的工作。
首先,我們使用doxygen來從代碼注釋生成文檔。因此,你將獲得上層和重要函數(shù)的解釋和說明,這是可以在編譯時(shí)生成的。
此外,我們還添加了軟件開發(fā)人員指南,你也可以在代碼庫中找到(也需使用doxygen)。它包含一些重要的算法流程,例如GOP決策,時(shí)域?yàn)V波,TPL,碼率控制等。如果需要,你也可以參考它們。此外,我們也提交了關(guān)于AV1的更詳細(xì)的綜述論文,現(xiàn)在可以在此處的鏈接查看。
責(zé)任編輯:lq
-
濾波器
+關(guān)注
關(guān)注
161文章
7817瀏覽量
178128 -
編碼器
+關(guān)注
關(guān)注
45文章
3643瀏覽量
134519 -
壓縮技術(shù)
+關(guān)注
關(guān)注
0文章
14瀏覽量
8385
原文標(biāo)題:AV1編碼器優(yōu)化技術(shù)
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
編碼器在機(jī)器人技術(shù)中的應(yīng)用 編碼器在傳感器系統(tǒng)中的作用
編碼器種類大觀:探索技術(shù)前沿與應(yīng)用創(chuàng)新
編碼器類型詳解:探索不同編碼技術(shù)的奧秘

二進(jìn)制編碼器與絕對編碼器的區(qū)別
磁電編碼器和光電編碼器的區(qū)別
編碼器有哪些類型? 編碼器如何選適合自己產(chǎn)品的型號?
增量編碼器和絕對值編碼器的區(qū)別
微軟Teams應(yīng)用整合AV1編解碼器,降低帶寬需求,提升畫面清晰度
谷歌計(jì)劃在Android系統(tǒng)升級中采用libdav1d替換libgav1,提高AV1視頻性能
編碼器分辨率是什么意思 編碼器分辨率和脈沖數(shù)的關(guān)系

編碼器原點(diǎn)設(shè)定方法 | 編碼器原點(diǎn)丟失怎樣找回
編碼器零點(diǎn)位置怎么看 | 編碼器零位怎樣確定






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論