 文本匹配任務中常用的孿生網絡
文本匹配任務中常用的孿生網絡
文本匹配是自然語言處理領域一個基礎且重要的方向,一般研究兩段文本之間的關系。文本相似度、自然語言推理、問答系統、信息檢索都可以看作針對不同數據和場景的文本匹配應用。
本文總結了文本匹配任務中的經典網絡Siamse Network,它和近期預訓練語言模型的組合,一些調優技巧以及在線下數據集上的效果檢驗。
Siamese 孿生網絡
在正式介紹前,我們先來看一個有趣的故事。
孿生網絡的由來
“Siamese”中的“Siam”是古時泰國的稱呼,中文譯作暹羅,所以“Siamese”就是指“暹羅”人或“泰國”人。“Siamese”在英語中同時表示“孿生”,這又是為什么呢?
十九世紀,泰國出生了一對連體嬰兒“恩”和“昌”,當時的醫學技術無法使他們分離出來,于是兩人頑強地生活了一生。
1829年他們被英國商人發現,進入馬戲團,在全世界各地演出。1839年他們訪問美國北卡羅萊那州成為“玲玲馬戲團” 的臺柱,最后成為美國公民。1843年4月13日跟英國一對姐妹結婚,恩生了10個小孩,昌生了12個。1874年,兩人因病均于63歲離開了人間。他們的肝至今仍保存在費城的馬特博物館內。
從此之后,“暹羅雙胞胎”(Siamese twins)就成了連體人的代名詞,也因為這對雙胞胎全世界開始重視這項特殊疾病。
孿生網絡
由于結構具有鮮明的對稱性,就像兩個孿生兄弟,所以下圖這種神經網絡結構被研究人員稱作“Siamese Network”,即孿生網絡。
其中最能體現“孿生”的地方,在于網絡具有相同的編碼器(sentence encoder),即將文本轉換為高維向量的部分。網絡隨后對兩段文本的特征進行交互,最后完成分類/相似預測。“孿生網絡”結構簡單,訓練穩定,是很多文本任務不錯的baseline模型。
孿生網絡的具體用途是衡量兩個輸入文本的相似程度。
例如,現在我們有文本1和2,首先把它們分別輸入 sentence encoder 進行特征提取和編碼,將輸入映射到新的空間得到特征向量u和v;最終通過u、v的拼接組合,經過下游網絡來計算文本1和2的相似性。
整個過程有2個值得關注的點:
在訓練和測試中,模型的編碼器是權重共享的(“孿生”);編碼器的選擇非常廣泛,傳統的CNN、RNN和Attention、Transformer都可以
得到特征u、v后,可以直接使用cosine距離、歐式距離得到兩個文本的相似度;不過更通用的做法是,基于u和v構建用于匹配兩者關系的特征向量,然后用額外的模型學習通用的文本關系映射;畢竟我們的場景不一定只是衡量相似度,可能還有問答、蘊含等復雜任務
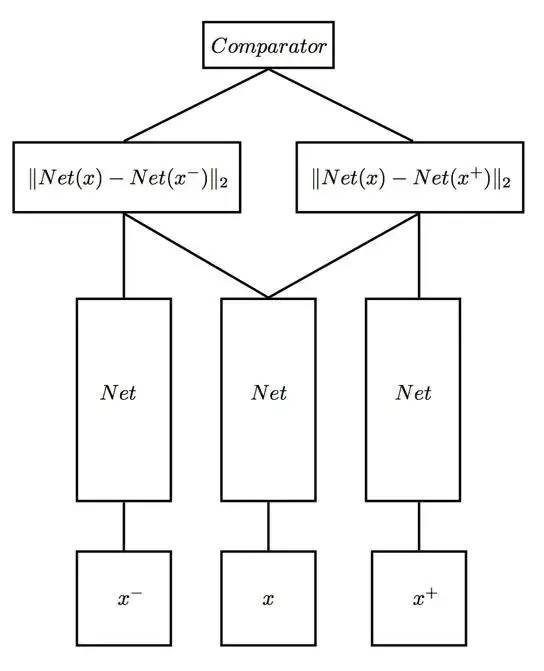
????????三連體網絡????????
基于孿生網絡,還有人提出了 Triplet network 三連體網絡。顧名思義,輸入由三部分組成,文本1,和1相似的文本2,和1不相似的文本3。
訓練的目標非常樸素,期望讓相同類別間的距離盡可能的小,讓不同類別間的距離盡可能的大,即減小類內距,增大類間距。
Sentence-BERT
自從2018年底Bert等預訓練語言模型橫空出世,NLP屆的游戲規則某種程度上被大幅更改了。在計算資源允許的條件下,Bert成為解決很多問題的首選。甚至有時候拿Bert跑一跑baseline,發現問題已經解決了十之八九。
但是Bert的缺點也很明顯,1.1億參數量使得推理速度明顯比CNN等傳統網絡慢了不止一個量級,對資源要求更高,也不適合處理某些任務。
例如,從10,000條句子中找到最相似的一對句子,由于可能的組合眾多,需要完成49,995,000次推理;在一塊現代V100GPU上使用Bert計算,將消耗65小時。
考慮到孿生網絡的簡潔有效,有沒有可能將它和Bert強強聯合呢?
當然可以,這正是論文《Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks》的工作,首次提出了Sentence-Bert模型(以下簡稱SBert)。
SBert在眾多文本匹配工作中(包括語義相似性、推理等)都取得了最優結果。更讓人驚訝的是,前文所述的從10,000條句子尋找最相似pair任務,SBert僅需5秒就能完成!
基于BERT的文本匹配
讓我們簡短回顧此前Bert是怎么處理文本匹配任務的。
常規做法是將匹配轉換成二分類任務。輸入的兩個文本拼接成一個序列(中間用特殊符號“SEP”分割),經過12層或24層Transformer模塊編碼后,將輸出層的字向量取平均或者取“CLS”位置的特征作為句向量,經softmax完成最終分類。
但是論文作者 Nils Reimers 在實驗中指出,這樣的做法產生的結果并不理想(至少在處理語義檢索和聚類問題時是如此),甚至比Glove詞向量取平均的效果還差。
基于S-BERT的文本匹配
為了讓Bert更好地利用文本信息,作者們在論文中提出了如下的SBert模型。是不是非常眼熟?對,這不就是之前見過的孿生網絡嘛!
SBert沿用了孿生網絡的結構,文本Encoder部分用同一個Bert來處理。之后,作者分別實驗了CLS-token和2種池化策略(Avg-Pooling、Mean-Pooling),對Bert輸出的字向量進一步特征提取、壓縮,得到u、v。關于u、v整合,作者提供了3種策略:
針對分類任務,將u、v拼接,接入全連接網絡,經softmax分類輸出;損失函數用交叉熵
直接計算、輸出余弦相似度;訓練損失函數采用均方根誤差
如果輸入的是三元組,論文種也給出了相應的損失函數
總的來說,SBert直接用Bert的原始權重初始化,在具體數據集上微調,訓練過程和傳統Siamse Network差異不大。
但是這種訓練方式能讓Bert更好的捕捉句子之間的關系,生成更優質的句向量。在測試階段,SBert直接使用余弦相似度來衡量兩個句向量之間的相似度,極大提升了推理速度。
實驗為證
作者在7個文本匹配相關的任務中做了對比實驗,結果在其中5個任務上,SBert都有更優表現。
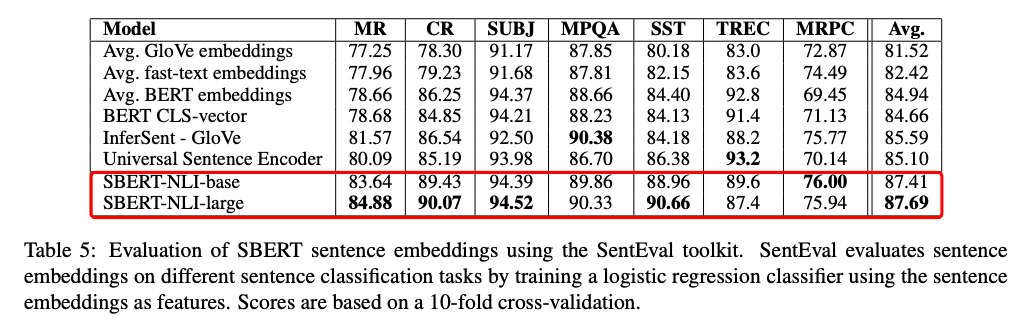
作者還做了一些有趣的消融實驗。
使用NLI和STS為代表的匹配數據集,在分類目標函數訓練時,作者測試了不同的整合策略,結果顯示“(u, v, |u-v|)”的組合效果最好。這里面最重要的部分是元素差:(|u - v|)。句向量之間的差異度量了兩個句子嵌入維度間的距離,確保相似的pair更近,不同的pair更遠。
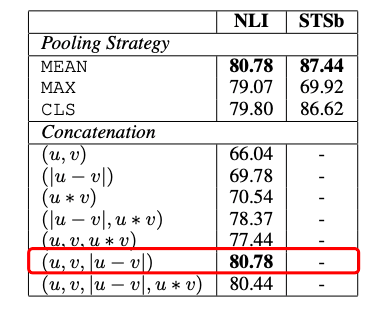
文章最后,作者將SBert和傳統方????法做了對比。
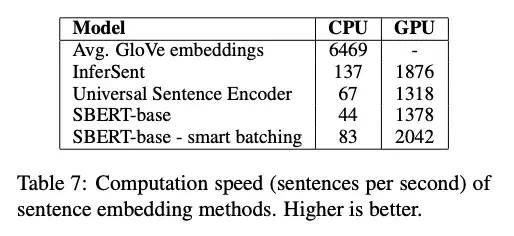
SBert的計算效率要更高。其中的smart-batching是一個小技巧。先將輸入的文本按長度排序,這樣同一個mini-batch的文本長度更加統一,padding時能顯著減少填充的token。
線下實測
我們將SBert模型在天池—新冠疫情相似句對判定比賽數據集上做了測試。經數據增強后,線下訓練集和驗證集分別是13,500和800條句子組合。預訓練模型權重選擇BERT_large。
最終SBert單模型在驗證集上的準確率是95.7%。直接使用Bert微調準確率為95.2%。
小結
本文介紹了文本匹配任務中常用的孿生網絡,和在此基礎上改進而來的Sentence-BERT模型。
Siamse Network 簡潔的設計和平穩高效訓練非常適合作為文本匹配任務的baseline模型。SBert則充分利用了孿生網絡的優點和預訓練模型的特征抽取優勢,在眾多匹配任務上取得了最優結果。
拋開具體任務,SBert 可以幫助我們生成更好的句向量,在一些任務上可能產生更優結果。在推理階段,SBert直接計算余弦相似度的方式,大大縮短了預測時間,在語義檢索、信息搜索等任務中預計會有不錯表現。同時,得益于生成的高質量句嵌入特征,SBert也非常適合做文本聚類、新FAQ發現等工作。
責任編輯:lq
-
模型
+關注
關注
1文章
3279瀏覽量
48970 -
數據集
+關注
關注
4文章
1208瀏覽量
24749 -
文本
+關注
關注
0文章
118瀏覽量
17098
原文標題:文本匹配利器:從孿生網絡到Sentence-BERT綜述
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
低壓配電柜中常用的電表有哪些?

使用語義線索增強局部特征匹配

數字孿生與物聯網的結合
NVIDIA文本嵌入模型NV-Embed的精度基準
華為設備中常用的RIP命令及其應用
不同類型神經網絡在回歸任務中的應用
機器視覺中常用的光源類型及優點?
卷積神經網絡在文本分類領域的應用
什么是數字孿生
矢量網絡分析儀和射頻網絡分析儀有什么區別
網絡安全數字孿生:一種新穎的汽車軟件解決方案
分享幾個嵌入式中常用的GUI

gis中常用的空間分析方法
淺談SoC中常用的處理器

網絡攻防模擬與城市安全演練 | 數字孿生






 工商網監
工商網監
評論