 一套高性能高靈活性的硬編解碼推理技術方案
一套高性能高靈活性的硬編解碼推理技術方案
在基于NVIDIA平臺上推理時,通常會遇到讀取視頻進行解碼然后輸入到GPU進行推理的需求。視頻一般以RTMP/RTSP的流媒體,文件等形式出現。解碼通常有VideoCapture/FFmpeg/GStreamer等選擇,推理一般選擇TensorRT。
NVIDIA已經為用戶提供了基于GStreamer插件拼裝的DeepStream Toolkit來解決上述需求,實現RTMP/RTSP/FileSystem到GStreamer再到TensorRT,從視頻數據的輸入到高性能解碼推理,再到渲染編碼,直到最終結果輸出。端到端的屏蔽了細節,易于上手使用,用戶只需要開發對應GStreamer插件即可輕易實現高性能解碼推理。這個方案涵蓋了服務端GPU、邊緣端嵌入式設備的高性能支持。 由于項目的緣故,面臨了大規模(96路)視頻文件的同時處理,同時推理的模型種類有6種(Object Detection[Anchor base/Anchor free]、Instance Segmentation、Semantic Segmentation、Keypoint Detection、Classification),處理的模型約96個(分類器36個,檢測分割60個)。項目需要極高的靈活度(模型種類和數量增加變化)、穩定性和高性能,考察DeepStream后發現其靈活度無法滿足需求,因此針對該需求,使用FFMPEG、NVDEC(CUVID)、CUDA、TensorRT、ThreadPool、Lua等技術實現了一套高性能高靈活性的硬編解碼推理技術方案,高擴展性,靈活的性能自動調整,任務調度。
解碼器
VideoCapture/FFMPEG/NVDEC
VideoCapture基于FFMPEG,如果單獨使用FFMPEG則可以做到更細粒度的性能控制,如果配合NVDEC則需要修改FFMPEG。
其中尤為重要的部分是:
a. 謹慎使用cvtColor,在OpenCV底層,cvtColor函數是一個多線程運行加速的函數,即使僅僅是CV_BGR2RGB這個通道交換的操作也如此。他是一個非常消耗CPU的操作。
通過上面可以觀察到,具有64線程的服務器,也只能實時處理3路帶有cvtColor的視頻文件。沒有cvtColor時,指標約為12路。也側面反映了CPU解碼效率其實很感人。 而cvtColor在CPU上運行的替代方案是sws_scale,具有靈活的性能配置選擇。不過也僅僅是比cvtColor稍好一點,問題并沒有得到解決。 顏色空間轉換,第一個使用場景為H264解碼后得到的是YUV格式圖像,需要轉換為BGR(這個過程在VideoCapture中默認存在sws_scale,輸出圖像為BGR格式)。第二個使用場景是神經網絡推理所需要的轉換(訓練時指定為RGB格式)。 解決方案是: 1) 使用BGR進行訓練,盡量避免顏色空間轉換; 2) 使用FFMPEG解碼,并輸出YUV格式,使用CUDA把YUV格式轉換為BGR,同時還進行進行標準化、BGRBGRBGR轉為BBBGGGRRR等推理常有操作。實現多個步驟合并為一個cuda核,降低數據流轉,提升吞吐量。例如yolov5,則可以把Focus也合并到一個cuda核中。如果需要中心對齊等操作,依舊可以把仿射變換矩陣傳入到cuda核中,一次完成整個預處理流程。 下圖為同時實現歸一化、focus、bgr到rgb、bgrbgrbgr轉bbbgggrrr共4個操作。

b. 僅考慮CPU解碼,使用FFMPEG可以配合nasm編譯(--enable_asm)支持CPU的SIMD流指令集(SSE、AVX、MMX),比默認VideoCapture配置的ffmpeg性能更好。同時還可以根據需要配置解碼所使用的線程數,控制sws_scale、decode的消耗。
編碼而言,ffmpeg可以使用preset=veryfast實現更高的速度提升于VideoWriter,設置合理的gop_size、bit_rate可以實現更加高效的編碼速度、更小的編碼后文件、以及更快的解碼速度。
c. NVDEC是一個基于CUDA的GPU硬件解碼器庫,CUVID(NVENC)是編碼庫。
地址是:https://developer.nvidia.com/nvidia-video-codec-sdk
對于ffmpeg配合NVDEC時,需要修改libavutil/hwcontext_cuda.c:356 對于hwctx->cuda_ctx 的創建不能放到ffmpeg內部進行管理。這對于大規模(例如超過32路同時創建解碼器時)是個災難。硬件解碼的一個核心就是CUcontext的管理,CUcontext應該在線程池的一個線程上下文中全局存在一個,而不是重復創建。TensorRT的模型加載時(cudaStreamCreate時),會在上下文中創建CUcontext,直接與其公用一個context即可。
對于沒有合理管理CUcontext的,異步獲取ffmpeg的輸出數據會存在異常并且難以排查。如果大規模同時創建32個解碼器,則同時執行的程序,其前后最大時長差為32秒。并且由于占用GPU顯存,導致程序穩定性差,極其容易出現OOM。
frames_ctx->format指定為AV_PIX_FMT_CUDA后,解碼出的圖像數據直接在GPU顯存上,格式是YUV_NV12,可以直接在顯卡上對接后續的pipline。
在ffmpeg解碼流程中,配合硬件解碼,需要在avcodec_send_packet/avcodec_decode_video2之前,將codec_ctx_->pix_fmt設置為AV_PIX_FMT_CUDA,該操作每次執行都需要存在,并不是全局設置一次。
基于以上的結論為:
a) CPU編解碼,使用配置了nasm的ffmpeg進行,避免使用VideoCapture/VideoWriter;
b) GPU編解碼,服務器使用配置了NVDEC的ffmpeg進行,嵌入式使用DeepStream(不支持NVDEC);
c) 避免使用cvtColor,盡量合并為一個cuda kernel減少數據扭轉實現多重功能。
CUDA/TensorRT
關于推理的一些優化
a. 對于圖像預處理部分,通常有居中對齊操作:把圖像等比縮放后,圖像中心移動到目標中心。通常可以使用resize+ROI復制實現,也可以使用copyMakeBorder等CPU操作。
在這里推薦采用GPU的warpAffine來替代resize+坐標運算。原因是warpAffine可以達到一樣效果,并且代碼邏輯簡單,而且更加容易實現框坐標反算回圖像尺度。對于反變換,計算warpAffine矩陣的逆矩陣即可(使用invertAffineTransform)。GPU的warpAffine實現,也僅僅只需要實現雙線性插值即可。
b. 注意計算的密集性問題。
cudaStream的使用,將圖像預處理、模型推理、后處理全部加入到同一個cudaStream中,使得計算密集性增加。實現更好的計算效率,統一的流進行管理。所有的GPU操作均采用Async異步,并盡可能減少主機到顯存復制的情況發生。方案是定義MemoryManager類型,實現自動內存管理,在需要GPU內存時檢查GPU是否是最新來決定是否發生復制操作。取自caffe的blob類。
c. 檢測器通常遇到的sigmoid操作,是一個可以加速的地方。
例如通常onnx導出后會增加一個sigmoid節點,對數據進行sigmoid變為概率后進行后處理得到結果。Yolov5為例,我們有BxHxWx [(num_classes + 5) * num_anchor]個通道需要做sigmoid,假設B=8,H=80,W=80,num_classes=80,num_anchor=3,則我們有8x80x80x255個數字需要進行sigmoid。而真實情況是,我們僅僅只需要保留confidence > threshold的框需要保留。而大于threshold的框一般是很小的比例,例如200個以內。真正需要計算sigmoid的其實只有最多200個。這之間相差65280倍。這個問題適用全部存在類似需求的檢測器后處理上。 解決對策為,實現cuda核時,使用desigmoid threshold為閾值過濾掉絕大部分不滿足條件的框,僅對滿足的少量框進行后續計算。
d. 在cuda核中,避免使用例如1.0,應該使用1.0f。
因為1.0是雙精度浮點數,這會導致這個核的計算使用了雙精度計算。眾所周知,雙精度性能遠低于單精度,更低于半精度。
線程池Thread Pool
主要利用了c++11提供的condition_variable、promise、 future、mutex、queue、thread實現。線程池是整個系統的基本單元,由于線程池的存在,輕易實現模型推理的高度并行化異步化。
使用線程池后,任務通過 commit提交,推理時序圖為:
當線程池配合硬件解碼后,時序圖為:
此時實現了GPU運算的連續化,異步化。GPU與CPU之間沒有等待。
資源管理的RAII機制
Resource Acquisition Is Initialization
在C++中,使用RAII機制封裝后,具有頭文件干凈,依賴簡單,管理容易等好處。
其要點在于:第一,資源創建即初始化,創建失敗返回空指針;第二,使用shared_ptr自動內存管理,避免丑陋的create、release,new、delete等操作;第三,使用接口模式,hpp聲明,cpp實現,隱藏細節。外界只需要看到必要的部分,不需要知道細節。
頭文件:interface.hpp
實現文件:interface.cpp
責任編輯:lq
-
gpu
+關注
關注
28文章
4760瀏覽量
129131 -
編解碼器
+關注
關注
0文章
266瀏覽量
24263 -
流媒體
+關注
關注
1文章
194瀏覽量
16671
原文標題:實戰 | 硬編解碼技術的AI應用
文章出處:【微信號:kmdian,微信公眾號:深蘭科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
面對快速迭代的技術,怎能忽視設備升級的高效與靈活性?

NVIDIA助力麗蟾科技打造AI訓練與推理加速解決方案


OPSL 優勢1:波長靈活性
8芯M16公頭如何提升靈活性

英特爾銳炫A系列顯卡為客戶提供了強大的性能和靈活性

意法半導體推出一款兼備智能功能和設計靈活性的八路高邊開關
編解碼一體機相對于傳統的編解碼設備有哪些優勢?

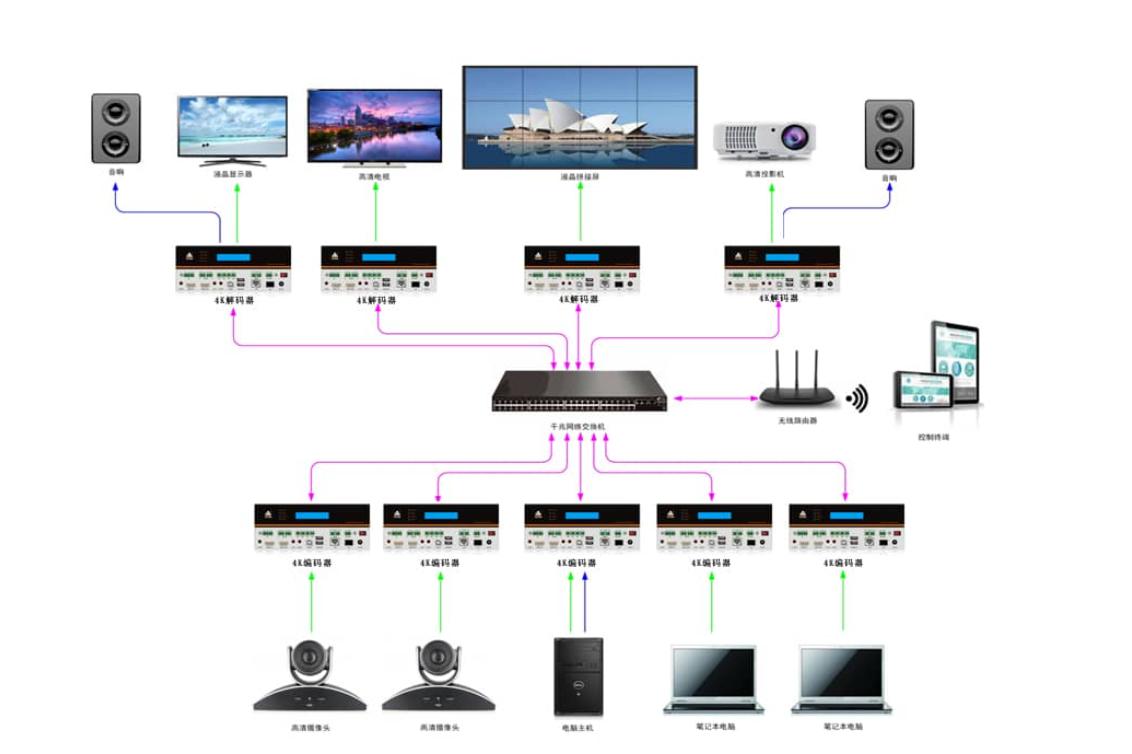
從編解碼一體機看視頻處理技術的未來








 工商網監
工商網監
評論