 循環神經網絡LSTM為何如此有效?
循環神經網絡LSTM為何如此有效?
長短期記憶網絡(LSTM),作為一種改進之后的循環神經網絡,不僅能夠解決 RNN無法處理長距離的依賴的問題,還能夠解決神經網絡中常見的梯度爆炸或梯度消失等問題,在處理序列數據方面非常有效。
有效背后的根本原因有哪些?本文結合簡單的案例,帶大家了解關于 LSTM 的五個秘密,也解釋了 LSTM如此有效的關鍵所在。
秘密一:發明LSTM是因為RNN 發生嚴重的內存泄漏
之前,我們介紹了遞歸神經網絡(RNN),并演示了如何將它們用于情感分析。 RNN 的問題是遠程內存。例如,它們能夠預測出“the clouds are in the…”這句話的下一個單詞“sky”,但卻無法預測出下面這句話中缺失的單詞:“她在法國長大。現在到中國才幾個月。她說一口流利的 …”(“She grew up in France. Now she has been in China for few months only. She speaks fluent …”) 隨著間隔的拉長,RNN變得無法學會信息連接。在此示例中,最近的信息表明,下一個詞可能是一種語言的名稱,但是如果我們想縮小哪種語言的范圍,那么就需要到間隔很長的前文中去找“法國”。在自然語言文本中,這種問題,完全有可能在相關信息和需要該信息的地方出現很大的差異。這種差異在德語中也很常見。
為什么RNN在長序列文本方面存在巨大的問題?根據設計,RNN 在每個時間步長上都會接受兩個輸入:一個輸入向量(例如,輸入句子中的一個詞)和一個隱藏狀態(例如,以前詞中的記憶表示)。 RNN下一個時間步長采用第二個輸入向量和第一隱藏狀態來創建該時間步長的輸出。因此,為了捕獲長序列中的語義,我們需要在多個時間步長上運行RNN,將展開的RNN變成一個非常深的網絡。
長序列并不是RNN的唯一麻煩制造者。就像任何非常深的神經網絡一樣,RNN也存在梯度消失和爆炸的問題,因此需要花費大量時間進行訓練。人們已經提出了許多技術來緩解此問題,但還無法完全消除該問題,這些技術包括:
仔細地初始化參數
使用非飽和激活函數,如ReLU
應用批量歸一化、梯度消失、舍棄網絡細胞等方法
使用經過時間截斷的反向傳播
這些方法仍然有其局限性。此外,除了訓練時間長之外,長期運行的RNN還面臨另一個問題是:對首個輸入的記憶會逐漸消失。 一段時間后,RNN的狀態庫中幾乎沒有首個輸入的任何痕跡。例如,如果我們想對以“我喜歡這款產品”開頭的長評論進行情感分析,但其余評論列出了許多可能使該產品變得更好的因素,那么 RNN 將逐漸忘記首個評論中傳遞的正面情緒,并且會完全誤認為該評論是負面的。
為了解決RNN的這些問題,研究者已經在研究中引入了各類具有長期記憶的細胞。實際上,不再使用基本的RNN的大多數工作是通過所謂的長短期記憶網絡(LSTM)完成的。LSTM是由S. Hochreiter和J. Schmidhuber發明的。
秘密2 :LSTM的一個關鍵思想是“門”
每個LSTM細胞都控制著要記住的內容、要忘記的內容以及如何使用門來更新存儲器。這樣,LSTM網絡解決了梯度爆炸或梯度消失的問題,以及前面提到的所有其他問題! LSTM細胞的架構如下圖所示:
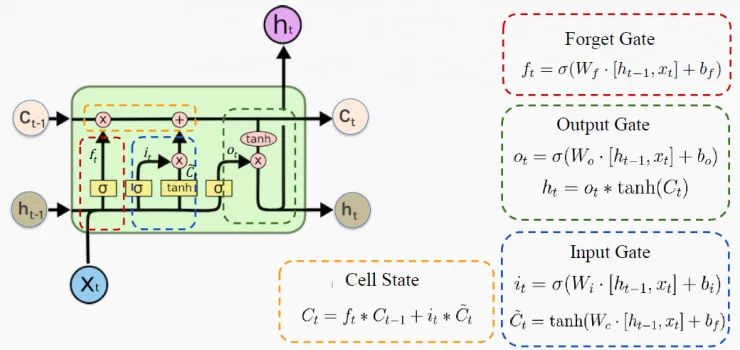
來源:哈佛大學 P. Protopapas教授的課堂講稿(下同,不再一一注釋) h 是隱藏狀態,表示的是短期記憶;C是細胞狀態,表示的是長期記憶;x表示輸入。 門只能執行很少的矩陣轉換,激活 sigmoid函數和tanh函數可以神奇地解決所有RNN問題。 在下一節中,我們將通過觀察這些細胞如何遺忘、記憶和更新其內存來深入研究這一過程。 一個有趣的故事: 讓我們設置一個有趣的情節來探索這個圖表。假設你是老板,你的員工要求加薪。你會同意嗎?這取決于多個因素,比如你當時的心情。 下面我們將你的大腦視為LSTM細胞,當然我們無意冒犯你聰明的大腦。
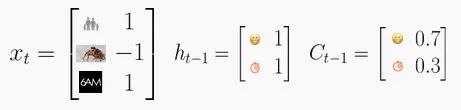
你的長期狀態C將影響你的決定。平均來說,你有70%的時間心情很好,而你還剩下30%的預算。因此你的細胞狀態是C=[0.7, 0.3]。 最近,所有的事情對你來說都很順利,100%地提升了你的好心情,而你有100%的可能性預留可操作的預算。這就把你的隱藏狀態變成了h=[1,1]。 今天,發生了三件事:你的孩子在學校考試中取得了好成績,盡管你的老板對你的評價很差,但是你發現你仍然有足夠的時間來完成工作。因此,今天的輸入是x=[1,- 1,1]。
基于這個評估,你會給你的員工加薪嗎?
秘密3:LSTM通過使用“忘記門”來忘記
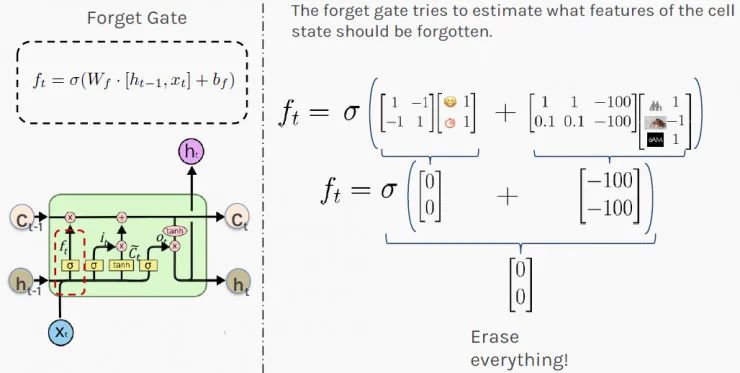
在上述情況下,你的第一步可能是弄清楚今天發生的事情(輸入x)和最近發生的事情(隱藏狀態h),二者會影響你對情況的長期判斷(細胞狀態C)。“忘記門”( Forget Gate)控制著過去存儲的內存量。 在收到員工加薪的請求后,你的“忘記門”會運行以下f_t的計算,其值最終會影響你的長期記憶。 下圖中顯示的權重是為了便于說明目的的隨意選擇。它們的值通常是在網絡訓練期間計算的。結果[0,0]表示要抹去(完全忘記)你的長期記憶,不要讓它影響你今天的決定。
秘密4:LSTM 記得使用“輸入門”
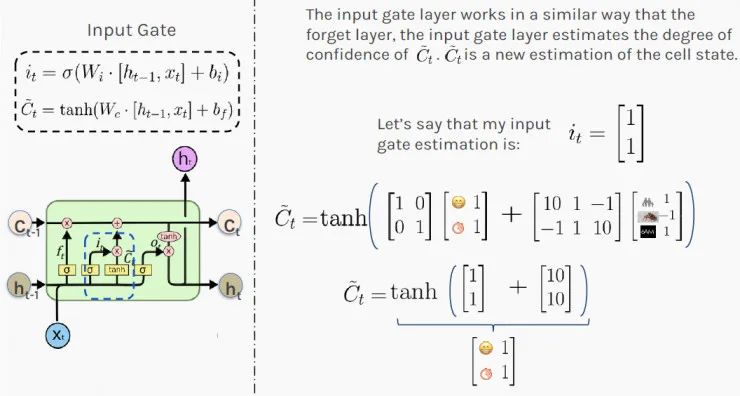
接下來,你需要決定:最近發生的事情(隱藏狀態h)和今天發生的事情(輸入x)中的哪些信息需要記錄到你對所處情況的長遠判斷中(狀態狀態C)。LSTM通過使用“輸入門”( Input Gate)來決定要記住什么。 首先,你要計算輸入門的值 i_t,由于激活了sigmoid函數,值落在0和1之間;接下來,你要tanh激活函數在-1和1之間縮放輸入;最后,你要通過添加這兩個結果來估計新的細胞狀態。 結果[1,1]表明,根據最近和當前的信息,你100%處于良好狀態,給員工加薪有很高的可能性。這對你的員工來說很有希望。
秘密5 :LSTM使用“細胞狀態”保持長期記憶
現在,你知道最近發生的事情會如何影響你的狀態。接下來,是時候根據新的理論來更新你對所處情況的長期判斷了。 當出現新值時,LSTM 再次通過使用門來決定如何更新其內存。門控的新值將添加到當前存儲器中。這種加法運算解決了簡單RNN的梯度爆炸或梯度消失問題。 LSTM 通過相加而不是相乘的方式來計算新狀態。結果C_t 被存儲為所處情況的新的長期判斷(細胞狀態)。 值[1,1]表示你整體有100%的時間保持良好的心情,并且有100%的可能性一直都有錢!你是位無可挑剔的老板!
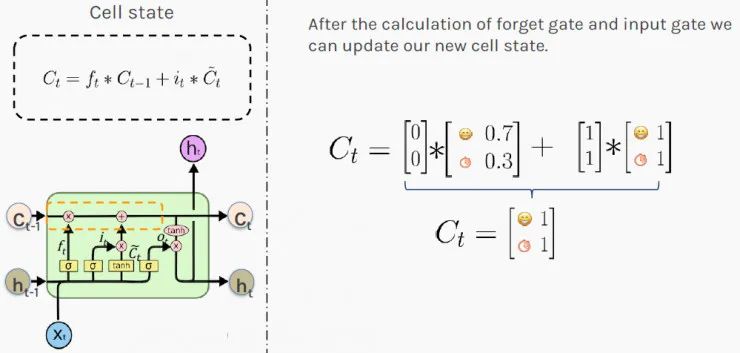
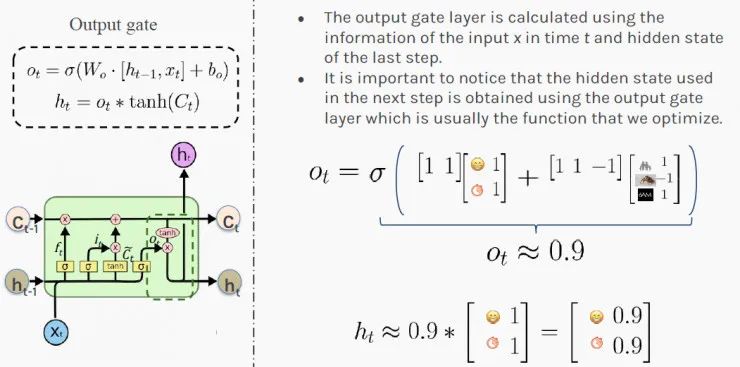
根據這些信息,你可以更新所處情況的短期判斷:h_t(下一個隱藏狀態)。值[0.9,0.9]表示你有90%的可能性在下一步增加員工的工資!祝賀他!
1、門控循環單元LSTM細胞的一種變體被稱為門控循環單元,簡稱GRU。GRU 是Kyunghyun Cho等人在2014年的一篇論文中提出的。 GRU是LSTM細胞的簡化版本,速度比LSTM快一點,而且性能似乎也與LSTM相當,這就是它為什么越來越受歡迎的原因。
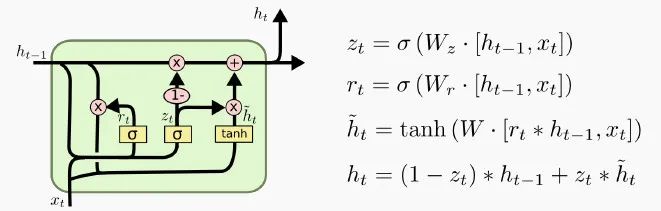
如上所示,這兩個狀態向量合并為一個向量。單個門控制器控制“忘記門”和“輸入門”。如果門控制器輸出 1,則輸入門打開,忘記門關閉。如果輸出0,則相反。換句話說,每當必須存儲內存時,其存儲位置先被刪除。 上圖中沒有輸出門,在每一步都輸出完整的狀態向量。但是,增加了一個新的門控制器,它控制之前狀態的哪一部分將呈現給主層。2、堆疊LSTM細胞通過對齊多個LSTM細胞,我們可以處理序列數據的輸入,例如下圖中有4個單詞的句子。
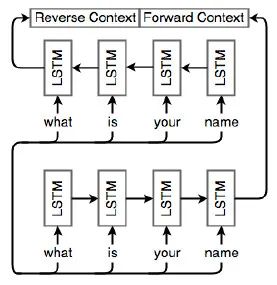
LSTM單元通常是分層排列的,因此每個單元的輸出都是其他單元的輸入。在本例中,我們有兩個層,每個層有4個細胞。通過這種方式,網絡變得更加豐富,并捕獲到更多的依賴項。3、雙向LSTMRNN、LSTM和GRU是用來分析數值序列的。有時候,按相反的順序分析序列也是有意義的。 例如,在“老板對員工說,他需要更努力地工作”這個句子中,盡管“他”一開始就出現了,但這句話中的他指的是:在句末提到的員工。 因此,分析序列的順序需要顛倒或通過組合向前和向后的順序。下圖描述了這種雙向架構:
下圖進一步說明了雙向 LSTM。底部的網絡接收原始順序的序列,而頂部的網絡按相反順序接收相同的輸入。這兩個網絡不一定完全相同。重要的是,它們的輸出被合并為最終的預測。
想要知道更多的秘密? 正如我們剛剛提到的那樣,LSTM細胞可以學會識別重要的輸入(輸入門的作用),將該輸入存儲在長期狀態下,學會在需要時將其保留(忘記門的作用),并在需要時學會提取它。 LSTM 已經改變了機器學習范式,現在可以通過世界上最有價值的上市公司如谷歌、Amazon和Facebook向數十億用戶提供服務。 自2015年中期以來,LSTM極大地改善了超過40億部Android手機的語音識別。 自2016年11月以來,LSTM應用在了谷歌翻譯中,極大地改善了機器翻譯。 Facebook每天執行超過40億個基于LSTM的翻譯。 自2016年以來,近20億部iPhone手機上搭載了基于LSTM的Siri。 亞馬遜的Alexa回答問題也是基于 LSTM。
原文標題:LSTM 為何如此有效?這五個秘密是你要知道的
文章出處:【微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100772
原文標題:LSTM 為何如此有效?這五個秘密是你要知道的
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論