 關于三篇論文中自然語言研究進展與發展方向詳解
關于三篇論文中自然語言研究進展與發展方向詳解
引言
自然語言理解(Natural Language Understanding,NLU)是希望機器像人一樣,具備正常人的語言理解能力,是人機對話系統中重要的組成部分。NLU主要包括兩大任務,分別是意圖識別(Intent Detection)和槽填充(Slot Filling)。其中,意圖識別就是判斷用戶的意圖,是一個文本分類的問題;槽填充是識別句子中重要的語義成分,常建模成序列標注的任務。
本次分享EMNLP2020中的三篇和NLU相關的文章,介紹這個領域目前的研究進展和關注方向。
文章概覽
SlotRefine: A Fast Non-Autoregressive Model for Joint Intent Detection and Slot Filling
論文提出了一個非自回歸的意圖識別和槽填充聯合模型,該模型以Transformer為基本結構,使用兩階段迭代機制顯著地提高了模型性能和模型速度。
論文地址:https://www.aclweb.org/anthology/2020.emnlp-main.152
Incremental Processing in the Age of Non-Incremental Encoders: An Empirical Assessment of Bidirectional Models for Incremental NLU
論文提出了三種適用于增量NLU任務的評價指標,探究了目前非增量編碼器在增量系統中的模型性能。
論文地址:https://www.aclweb.org/anthology/2020.emnlp-main.26
End-to-End Slot Alignment and Recognition for Cross-Lingual NLU
論文提出了用于一種跨語言自然語言理解的端到端槽位標簽對齊和識別模型,該模型運用注意力機制將目標語言文本表示和源語言的槽位標簽軟對齊,并且同時預測意圖和槽標簽。
論文地址:https://www.aclweb.org/anthology/2020.emnlp-main.410/
1論文細節

論文動機
以往的自然語言理解模型大多依賴于自回歸的方法(例如,基于RNN的模型或seq2seq的架構)來捕捉話語中的語法結構,并且在槽填充任務中常使用條件隨機場(CRF)模塊來確保序列標簽之間的合理性。然而本文作者發現,對于槽填充任務而言,從槽塊之間建模依賴關系就足以滿足任務需要,而使用自回歸的方法對整個序列的依賴關系建模會導致冗余計算和高延遲。因此作者使用非自回歸的方法來建模意圖識別和槽填充兩個任務,從而消除非必要的時間依賴,并且采用兩階段迭代機制來處理由于條件獨立性導致的槽標簽之間的不合理問題。
模型
模型主要包括兩個方面,分別是非自回歸的聯合模型以及兩階段改善機制。
非自回歸的聯合模型
模型使用了《Attention is all you need》(Vaswani等人, 2017)這篇論文中提出的Transformer模型的encoder部分作為本文模型編碼層的主要結構。與原始Transformer不同的是,作者將絕對位置編碼改為相對位置表示來建模文本序列信息。
對于每個輸入的文本序列,都會在初始位置添加一個特殊的符號“CLS”來表示句子信息。文本序列的輸入為,經過Multi-Head Self Attention編碼后得到輸出向量為 。其中,向量將用于意圖分類,將和每個時刻的拼接用于對應的槽位預測。意圖識別和槽填充的計算公式如下:
聯合模型的任務目標是通過優化交叉熵損失函數來最大化條件概率分布:
與自回歸模型不同的是,這個模型中每個槽位預測可以并行優化,由此提高了模型速度。
兩階段改善機制
由于槽位標簽之間的條件獨立性,上述非自回歸聯合模型難以捕獲每個槽位塊之間的依賴關系,從而導致一些槽位標簽不合理現象。如下圖所示,根據BIO標簽規則,“I-song”并不能跟在“B-singer”后面。
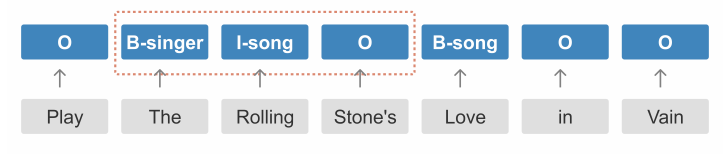
因此,作者提出兩階段的迭代機制,使用兩次槽位預測的方法來改善這個問題。模型的輸入除了文本信息之外,還有槽位標簽信息,初始化的槽位標簽均為“O”。在第一階段,模型的目標是預測每個槽塊的起始標簽“B-tags”,在第二階段,預測的“B-tags”將作為相應槽位標簽的輸入,由此,模型可以進一步預測出“B-tags”后面對應的標簽。兩階段的改善機制可以看作是自回歸與非自回歸之間的權衡,其中完整的馬爾可夫過程可以表示為:
其中,是第一階段的槽標簽預測結果。
實驗
實驗使用的數據集是NLU領域兩個經典的公開數據集:ATIS(Tur等人,2010)和Snips(Coucke等人,2018)。作者將本文模型與六種意圖識別和槽填充聯合模型進行了比較。結果如下:
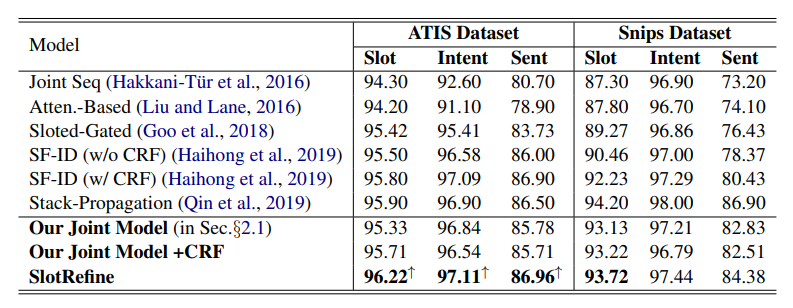
由上表可知,本文模型SlotRefine在ATIS數據集上取得了最佳效果,在槽填充F1值、意圖識別準確率和句子層面準確率三個指標上均超過了現有模型。在Snips數據集上,模型效果沒有Stack-Propagation好。從消融實驗結果看到,在非自回歸聯合模型上加入CRF層會有效提高槽填充任務的性能,但會降低意圖識別準確率和句子層面準確率,而本文提出的兩階段改善機制則可以顯著提高模型效果。
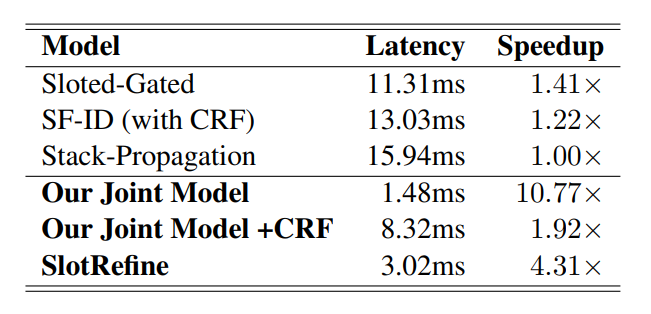
作者還比較了模型速度上的改進效果,由上表可知,在ATIS數據集上,與現有的最優模型Stack-Propagation相比,本文提出的模型SlotRefine的速度提高了4.31倍。由于每個槽標簽均可以并行計算,因此模型的推理延遲可以顯著減少。

2論文動機
增量學習是指模型能夠不斷地處理現實世界中連續的信息流,在吸收新知識的同時保留甚至整合、優化舊知識的能力。在NLP領域,增量處理方式在認知上更加合理,并且在工程層面,一些實時應用(如自然語言理解、對話狀態追蹤、自然語言生成、語音合成和語音識別)要求在一定時間步長的部分輸入的基礎上必須提供部分輸出。雖然人類使用增量的方式處理語言,但目前在NLP中效果最好的語言編碼器(如BiLSTM和Transformer)并不是這樣的。BiLSTM和Transformer均假定編碼的整個序列是完全可用的,可以向前或向后處理(BiLSTM),也可以作為一個整體處理(Transformer)。本文主要想探究這些非增量模型在增量系統下的效果,作者在不同的NLU數據集上實驗了五個非增量模型,并使用三個增量評估指標比較它們的性能。
增量系統評價指標
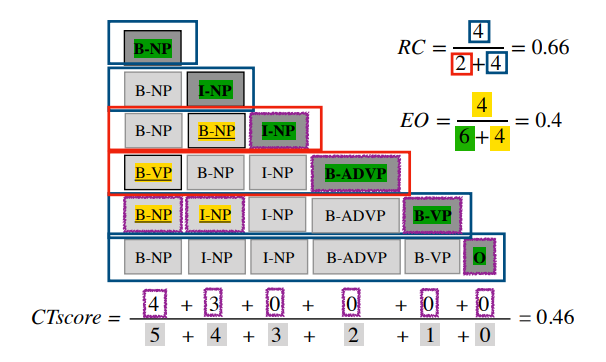
增量系統可以通過添加、撤銷和替換輸出部分來編輯輸出。一個效果良好的增量系統應當能夠盡快產生準確的輸出,并且撤銷和替換要盡可能少。由此,本文提出三個評價指標:編輯開銷、校正時間和相對正確性。
編輯開銷(Edit Overhead,EO):不必要的編輯比例,范圍在0-1之間,越接近于0,說明編輯越少。
校正時間(Correction Time,CT):系統提交某一輸出內容的最終決策之前所花的時間,范圍在0-1之間,越接近于0,說明系統越快做出最終決策。
相對正確性(Relative Correctness,RC):輸出相對于非增量輸出時正確的比例,范圍在0-1之間,越接近于1表示系統的輸出大部分時刻下都是非增量輸出的正確前綴。
作者以詞性標注任務為例展示了三個評價指標的計算過程。如下圖所示:
模型
作者一共探究了五種非增量模型在增量系統中的表現,分別是:(a) LSTM模型;(b)BiLSTM模型;(c)LSTM+CRF;(d)BiLSTM+CRF;(e)BERT。其中,(a)、(b)、(e)模型同時用于序列標注和文本分類任務,(c)和(d)模型只用于序列標注任務。
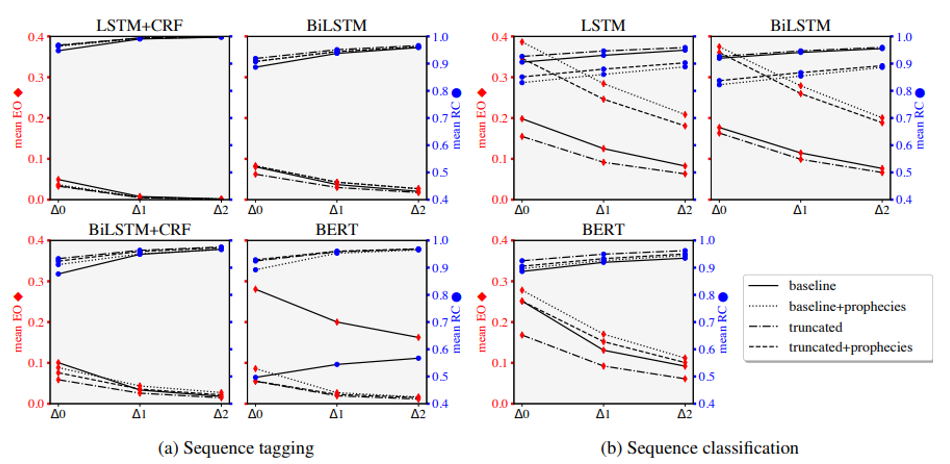
本文探索了三種策略的效果,分別是截斷訓練、延遲輸出和語言:
截斷訓練(truncated training):去掉訓練集中每個句子的結尾來修改訓練機制。
延遲輸出(delayed output):允許模型在輸出當前時刻單詞的標簽之前觀察后續1-2個時刻的單詞。
語言(prophecies):使用GPT-2語言模型將每個時刻的輸入前綴作為左上下文,并由此生成一個持續到句子末尾的文本,創建一個假設的完整上下文,以滿足模型的非增量特性的需要。如下圖所示:
實驗
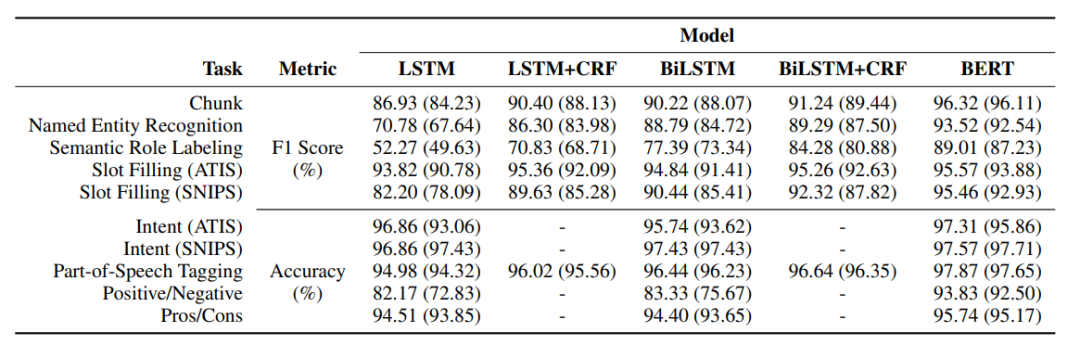
作者一共在十個英文數據集上進行了實驗,六個數據集用于序列標注任務:組塊分析(Chunk)、槽填充(Slot Filling (ATIS)和Slot Filling (SNIPS))、命名實體識別(NER)、詞性標注(Part-of-Speech Tagging) 、語義角色標注(Semantic Role Labeling);四個數據集用于文本分類任務:意圖識別(Intent (ATIS)和Intent (SNIPS))、情感分析(Positive/Negative和Pros/Cons)。其中,Chunking、NER、SRL和Slot Filling均使用BIO標簽體系并且使用F1值進行評估,其他的任務使用準確率評價。
五種模型在上述數據集上的實驗結果如下所示,括號里代表使用了截斷訓練的結果。從中可知,大部分情況下BiLSTM比LSTM效果好;BERT可以提升所有任務性能;截斷訓練后模型性能都有所下降,但BERT仍優于其他所有模型。整體來說,目前的非增量編碼器可以適應在增量系統下使用,其性能產生不會有太大影響。
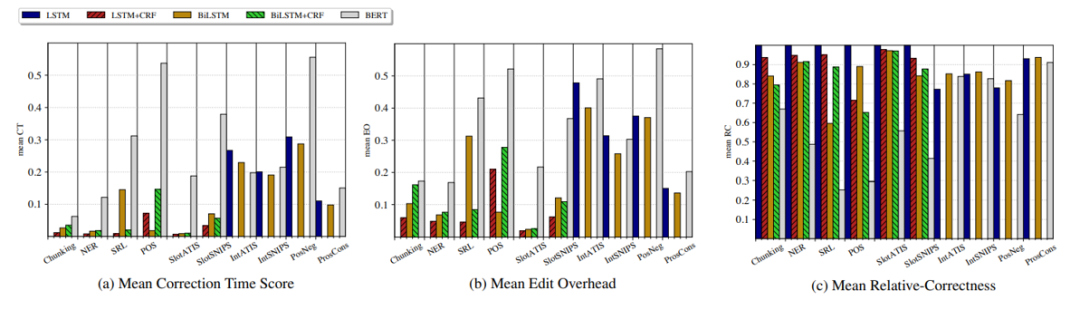
模型在三個增量系統的評價指標上的表現結果如下所示。從中可以發現,除BERT外,模型在序列標注任務的編輯開銷和校正時間均較低;在文本分類中,由于往往需要捕捉全局信息,編輯開銷和校正時間均較高;對于相對正確性這個指標,在序列標注任務中BERT比其他模型效果都差,在文本分類任務中性能差不多。
作者還探究了不同策略的效果,從圖中可知,截斷訓練可以有效減少編輯開銷,提高相對正確性;預言對于文本分類任務有負面作用,但對于一些序列標注任務可能有效。BERT模型在增量評價指標上的缺陷可以通過這些策略得到一定緩解,從而使其在增量系統下的模型效果與其他模型一樣好。
3

論文動機
NLU可以將話語解析成特定的語義框架,以識別用戶的需求。雖然目前神經網絡模型在意圖檢測和槽填充方面取得了很高的準確性,在兩個公開的英文數據集上模型的效果已經達到95%以上,但如果使用一種新的語言訓練這樣的模型仍需要大量的數據和人工標注工作。因此考慮通過跨語言學習將模型從高資源語言遷移到低資源語言,從而減少數據收集和標注的工作量。
跨語言遷移學習主要有兩種方式:一種是使用多語言模型來實現語言的遷移,例如multilingual BERT;另一種是通過機器翻譯的方式先統一語言類型,雖然它在跨語言文本分類上取得了很好的效果,但在序列標注任務上存在一些挑戰,源語言的標簽需要映射到目標語言中,而如果兩個語言差別較大,則較難找到良好的映射關系。
目前跨語言NLU任務中存在一些挑戰:(1)可以使用的數據集(Multilingual ATIS)僅支持三種語言,語言類型不足;(2)現有的模型使用機器翻譯和槽標簽投影的方法將NLU系統擴展到新語言中,這種方法對標簽投影錯誤很敏感。
因此,這篇文章發布了一個新的跨語言NLU數據庫(MultiATIS++),探索了不同的跨語言遷移方法的效果,并且提出了一種新的端到端模型,該模型可以對目標語言槽標簽進行聯合對齊和預測,以實現跨語言遷移。
數據集
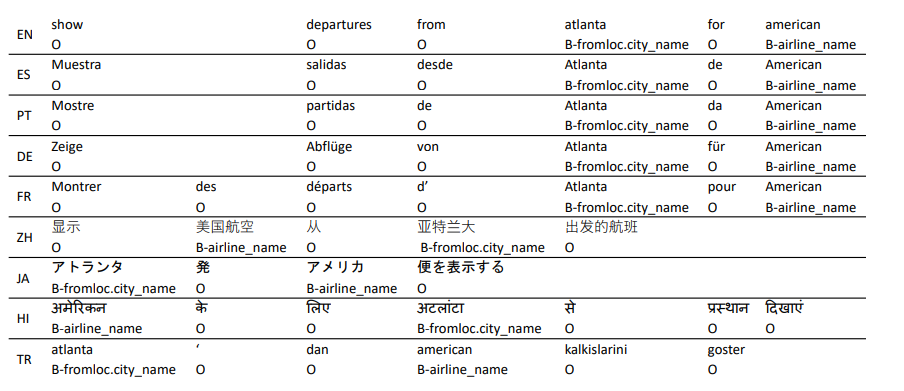
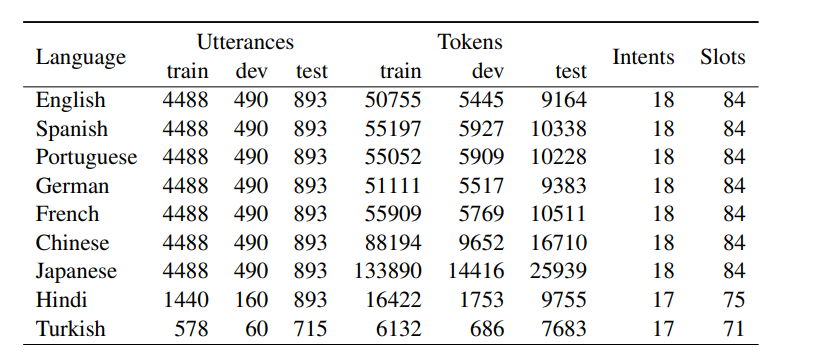
MultiATIS++數據集在Multilingual ATIS數據集基礎上新增了六種語言,共覆蓋九種語言,并對每種語言人工打上槽位標簽(使用BIO標簽體系)。數據集樣例和數據集的描述特征如下所示:
模型
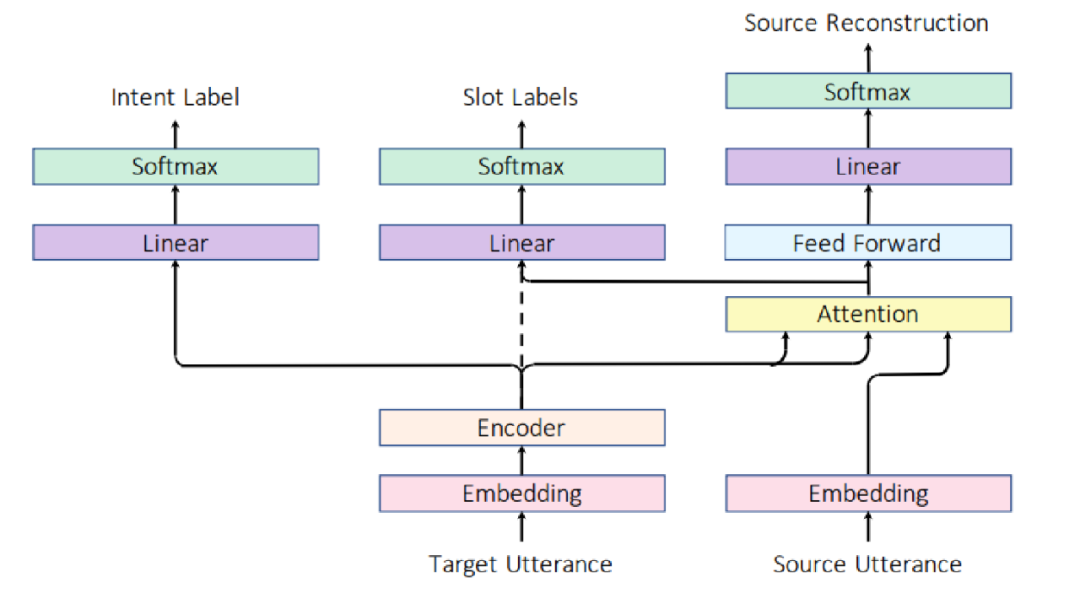
上圖為作者提出的端到端槽對齊和識別模型,使用Attention機制將目標語言表示與源語言槽標簽進行軟對齊,模型直接將編碼器模塊連接到意圖和槽分類層,對目標語言同時預測意圖和槽標簽。該模型使用額外的Attention層來同時完成槽標簽對齊和識別任務,不需要額外的槽標簽投影過程。
記為源語言文本序列,為目標語言文本序列,源語言文本經過Embedding之后得到向量表示,目標語言經過Embedding和Encoder后得到上下文表示,其中是額外添加的符號,用于表示目標語言句子表示。意圖識別任務的公式如下:
對于槽填充任務,先計算目標語言和源語言的注意力向量,然后再進行目標語言的槽位預測,其公式如下:
此外,作者還提出了一個重構模塊來提高目標語言和源語言的對齊效果:
意圖識別、槽填充和重構模塊的損失函數如下所示,模型的損失函數為三者相加:
實驗結果
Multilingual NLU
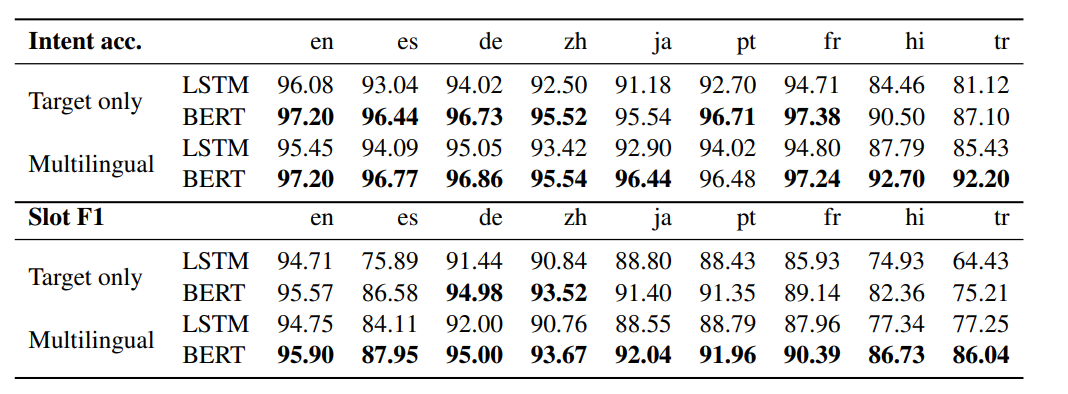
作者使用multilingual BERT預訓練模型作為encoder,并比較了僅使用目標語言進行NLU和使用全部的語言進行NLU時監督訓練的效果。如圖所示,BERT相比于LSTM在不同語言上均能顯著提高模型性能,并且多語言監督訓練能進一步提高模型性能。
Cross-Lingual Transfer
作者比較了不同的跨語言遷移學習方法,其中源語言是英語,目標語言共有八種。實驗結果和模型速度如下所示:
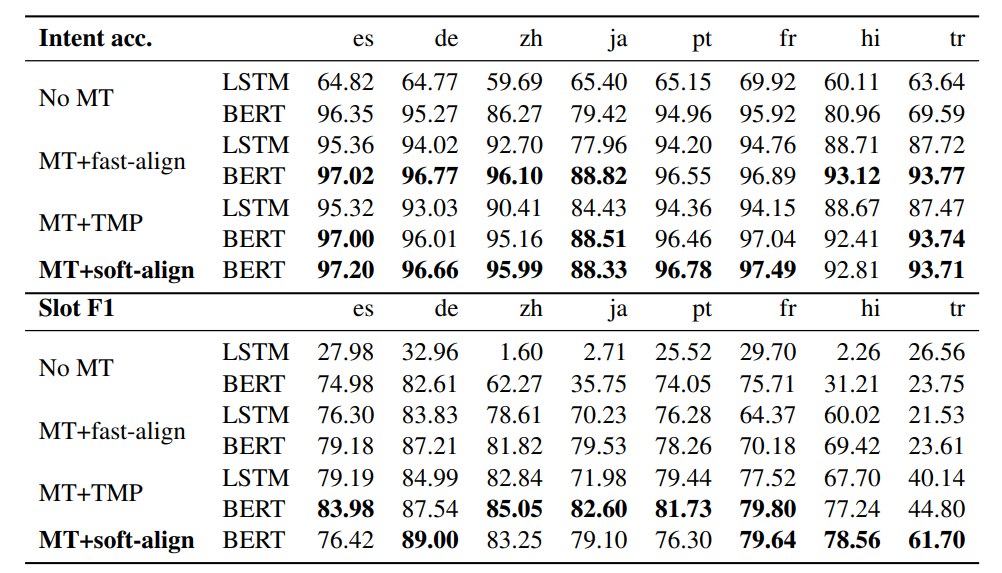
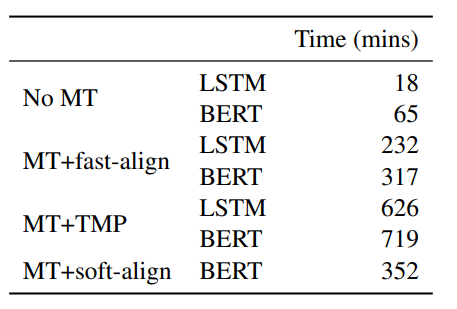
MT+soft-align是本文提出的模型,在八個目標語言數據集中,有五個語言本文模型相比于MT+fast-align的效果更好,并且在意圖識別和槽填充任務中本文模型的魯棒性更強。本文模型的速度明顯優于MT+TMP模型,在模型性能上,意圖識別任務中,本文模型在六個語言上表現更好,槽填充任務中,本文模型在四個語言上表現更佳。綜合模型性能和模型速度,端到端的槽標簽軟對齊和識別模型在跨語言NLU任務上具有一定優勢。
參考文獻
[1] Vaswani A , Shazeer N , Parmar N , et al. Attention Is All You Need[J]。 arXiv, 2017.
[2] Tur G , Hakkani-Tur D , Heck L 。 What is left to be understood in ATIS?[C]// Spoken Language Technology Workshop (SLT), 2010 IEEE. IEEE, 2011.
[3] Coucke A , Saade A , Ball A , et al. Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces. 2018.
編輯:lyn
-
識別模型
+關注
關注
0文章
5瀏覽量
6754 -
自然語言
+關注
關注
1文章
288瀏覽量
13360
原文標題:【論文分享】EMNLP 2020 自然語言理解
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論