") 多語言翻譯新范式的工作:機(jī)器翻譯界的BERT
多語言翻譯新范式的工作:機(jī)器翻譯界的BERT
今天給大家介紹EMNLP2020的一篇關(guān)于多語言翻譯新范式的工作multilingual Random Aligned Substitution Pre-training (mRASP)[1],核心思想就是打造“機(jī)器翻譯界的BERT”,通過預(yù)訓(xùn)練技術(shù)再在具體語種上微調(diào)即可達(dá)到領(lǐng)先的翻譯效果,其在32個(gè)語種上預(yù)訓(xùn)練出的統(tǒng)一模型在47個(gè)翻譯測試集上取得了全面顯著的提升。
目錄
機(jī)器翻譯預(yù)訓(xùn)練的挑戰(zhàn)
mRASP發(fā)明的動(dòng)機(jī)和方法
mRASP實(shí)際效果和分析
En-De和En-Fr Benchmark
預(yù)訓(xùn)練階段沒見過的語言擴(kuò)展
案例分析
效果分析
手把手教你用mRASP快速得到任意翻譯模型
附注:相關(guān)技術(shù)已經(jīng)被應(yīng)用于火山翻譯[2]
1. 機(jī)器翻譯預(yù)訓(xùn)練的挑戰(zhàn)
目前絕大多數(shù)AI任務(wù)都是建立在數(shù)據(jù)的基礎(chǔ)之上的統(tǒng)計(jì)學(xué)習(xí),模型的表現(xiàn)效果很大程度上依賴于數(shù)據(jù)的質(zhì)量和數(shù)量。利用大量較易獲得的數(shù)據(jù)來預(yù)訓(xùn)練模型,在具體應(yīng)用場景再利用少量標(biāo)注數(shù)據(jù)微調(diào)來實(shí)現(xiàn)實(shí)際場景可用的模型,已經(jīng)成為NLP新的成功范式。例如BERT[3]在大規(guī)模純文本上預(yù)訓(xùn)練后,在自然語言理解的11項(xiàng)任務(wù)上少量微調(diào)就能取得很好的成績。不過,在多語言的機(jī)器翻譯中,通過預(yù)訓(xùn)練再微調(diào)的范式還未取得普遍的成功。以前的NLP預(yù)訓(xùn)練方式例如BERT、GPT[4]訓(xùn)練目標(biāo)與翻譯關(guān)注的目標(biāo)之間差距過大,不易直接使用。mRASP提出了全新的思路,利用多個(gè)語言已經(jīng)積累的大量雙語平行語料,合并起來聯(lián)合訓(xùn)練一個(gè)統(tǒng)一的模型,之后再基于此微調(diào),讓預(yù)訓(xùn)練和微調(diào)目標(biāo)盡可能接近,這樣才能更大發(fā)揮預(yù)訓(xùn)練模型作用。
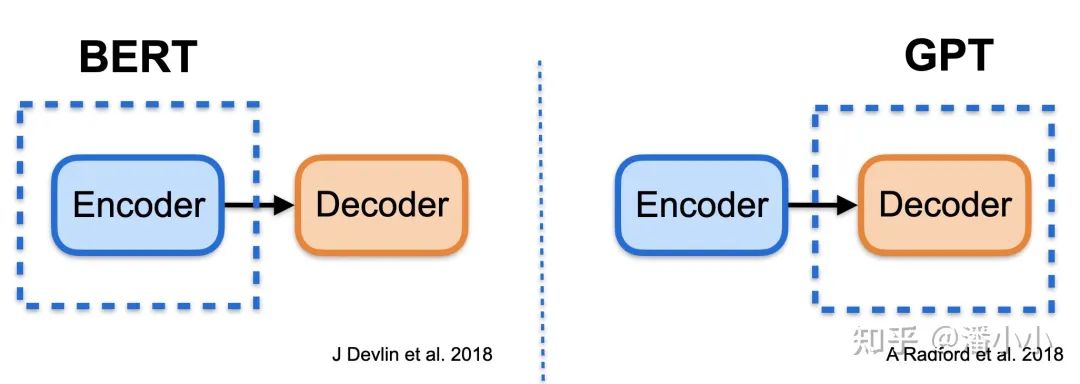
BERT和GPT的示意圖
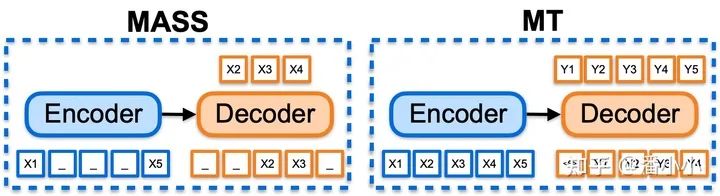
MASS和機(jī)器翻譯示意圖對比
上圖對比分析了之前NLP預(yù)訓(xùn)練方法在機(jī)器翻譯場景直接應(yīng)用的限制。BERT和GPT分別對應(yīng)了Transformer[5] 編碼器部分和解碼器部分的預(yù)訓(xùn)練,而機(jī)器翻譯用的是序列生成模型。這種模型結(jié)構(gòu)的不一致會(huì)導(dǎo)致翻譯模型只有一部分參數(shù)被初始化,有效發(fā)揮預(yù)訓(xùn)練作用會(huì)比較困難,因此需要很多特殊的技巧才能得到提升[6]。
針對序列模型,很快也有研究者提出了MASS[7]和BART[8]等框架將預(yù)訓(xùn)練擴(kuò)展到序列生成任務(wù),它們使用 auto-encoder(自編碼器)進(jìn)行自學(xué)習(xí),在很多下游生成任務(wù)上都取得了顯著的效果,但是在機(jī)器翻譯的應(yīng)用上依然存在兩個(gè)重要的問題,第一是在資源豐富的語種(例如英德和英法)上沒有觀察到提升,第二是沒有辦法擴(kuò)展到多語種翻譯任務(wù)上。這種局限性,很大一部分原因就是自編碼相對是簡單任務(wù),很難學(xué)習(xí)到更深層次的表示,而機(jī)器翻譯需要更復(fù)雜的語義轉(zhuǎn)化,這種預(yù)訓(xùn)練目標(biāo)和下游任務(wù)之間的差異,導(dǎo)致模型很難最大程度利用好預(yù)訓(xùn)練數(shù)據(jù)。如何克服著兩個(gè)問題,成了預(yù)訓(xùn)練模型在機(jī)器翻譯領(lǐng)域應(yīng)用的重要挑戰(zhàn)。
2. 多語言翻譯預(yù)訓(xùn)練方法mRASP的動(dòng)機(jī)和方法
對于語言學(xué)習(xí)者來說,有一個(gè)非常有意思的現(xiàn)象,他們發(fā)現(xiàn)在學(xué)習(xí)了三四種語言之后,再學(xué)習(xí)一個(gè)新的語言速度會(huì)加快。一個(gè)簡單的例子,如果有人分別學(xué)習(xí)德語和法語,可能各需要一年的時(shí)間,然而他先學(xué)習(xí)了德語,再去學(xué)法語,可能只需要一年零三個(gè)月就學(xué)會(huì)了,接下來再去學(xué)習(xí)西班牙語,速度可能會(huì)更快。對于程序語言其實(shí)也是類似的道理,學(xué)習(xí)C++可能需要一年,接下來再學(xué)習(xí) Java,Python 可能只需要一個(gè)月。一個(gè)淺顯的解釋是,人類在多語言學(xué)習(xí)的過程會(huì)自發(fā)去總結(jié)語言中比較抽象的共性,重點(diǎn)學(xué)習(xí)新語言的特性。因此想要提升個(gè)人的語言學(xué)習(xí)能力,往往需要學(xué)習(xí)更多的語言,能夠?qū)φZ言的共性有更精確的把握,而不是拼命學(xué)習(xí)一個(gè)語言。同樣的道理,對于機(jī)器翻譯而言,能否把翻譯能力遷移到不同語言上,使得不同語言之間的信息可以互相利用,就成了一件非常有趣的問題。
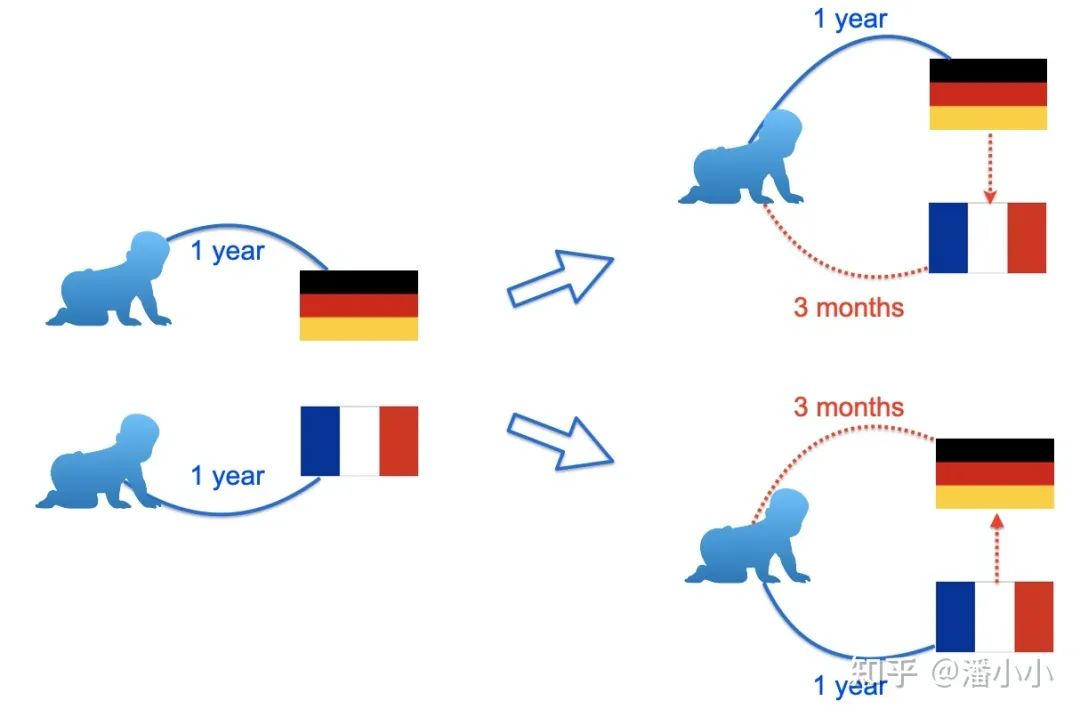
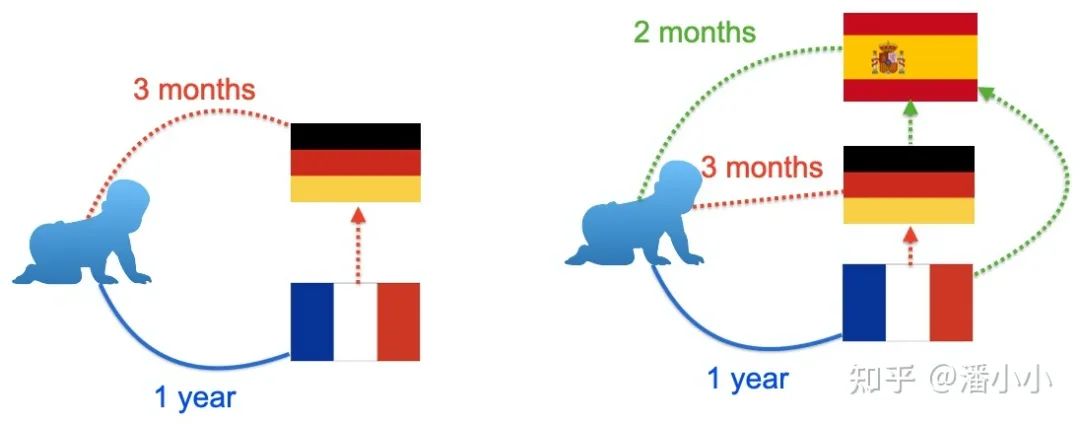
mRASP的設(shè)計(jì)目標(biāo)正是基于這樣的考慮,設(shè)計(jì)一個(gè)通用的預(yù)訓(xùn)練模型,學(xué)習(xí)語言之間轉(zhuǎn)換的共性,接下來就被更容易遷移到新的翻譯方向。就好像語言學(xué)習(xí)者一樣,在學(xué)習(xí)了兩種語言之后,第三種語言就變得很輕松了。mRASP 的設(shè)計(jì)遵循了兩個(gè)基本原則:第一,預(yù)訓(xùn)練的目標(biāo)和機(jī)器翻譯基本一致,需要學(xué)習(xí)到語言的轉(zhuǎn)換能力;第二,盡可能學(xué)習(xí)語言的通用表示,跨語言的句子或詞語,如果語義接近則隱空間中的表示也應(yīng)該接近。
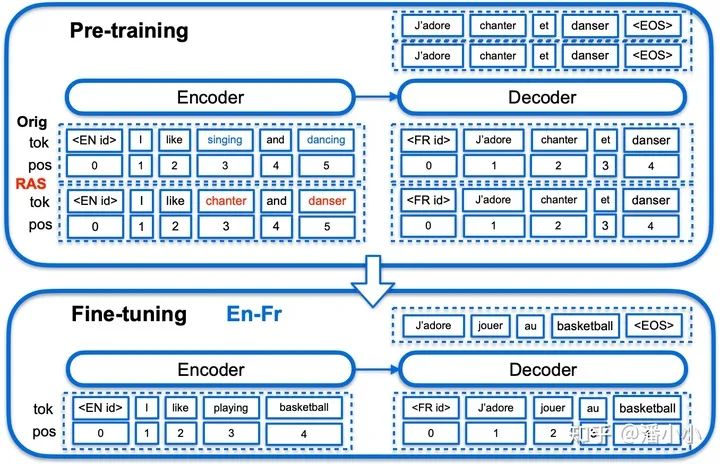
mRASP方法,使用帶語言標(biāo)識(shí)的Transformer作為翻譯網(wǎng)絡(luò)框架
mRASP遵循了通用的預(yù)訓(xùn)練-微調(diào)框架。預(yù)訓(xùn)練階段,不同于傳統(tǒng)預(yù)訓(xùn)練模型大量堆疊無監(jiān)督單語數(shù)據(jù)的方式, mRASP另辟蹊徑,采用了多語言平行數(shù)據(jù)作為預(yù)訓(xùn)練的主要目標(biāo),將幾十種語言的平行數(shù)據(jù)放到同一個(gè)模型進(jìn)行聯(lián)合訓(xùn)練。神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)采用Transformer,加上語言標(biāo)識(shí)符(Language token)標(biāo)識(shí)源語言和目標(biāo)語言。為了保證不同語言的句子和詞語能嵌入到同一個(gè)空間,同一個(gè)意思的句子無論中文還是英文說得都應(yīng)該是對應(yīng)同一個(gè)向量表示,又引入了隨機(jī)替換對齊技術(shù)RAS,來制造更豐富的上下文。
一句中文的句子“我 愛 北京 天安門”中的“愛”有一定概率被替換成“aime”(法語),“北京”也有一定概率被替換成“Pékin”(法語),于是原句就可能會(huì)變成“我 aime Pékin 天安門”。訓(xùn)練集中的一對平行句對可以變?yōu)閮蓪Γㄉ踔寥龑Α⑺膶Γ?/p>
我 愛 北京 天安門 ==》 I love Beijing Tiananmen Square
我 aime Pékin 天安門 ==》 I love Beijing Tiananmen Square
而在微調(diào)階段,只需要使用預(yù)訓(xùn)練階段的參數(shù)作初始化,之后采用和傳統(tǒng)單向機(jī)器翻譯相同的訓(xùn)練方法即可。因此使用mRASP并不需要掌握任何額外的技能。
3. mRASP實(shí)際效果和分析
mRASP使用32個(gè)語言的平行語料來預(yù)訓(xùn)練,在英語到法語方向上僅使用wmt14的平行語料進(jìn)行微調(diào),就達(dá)到了不需要使用費(fèi)時(shí)費(fèi)力的海量單語Back Translation的最佳效果(44.3 BLEU),同時(shí),應(yīng)用到新的語言方向荷蘭語(Nl)到葡萄牙語(Pt)上,僅使用1.2萬平行句對,微調(diào)了十分鐘就可以獲得一個(gè)可使用的(BLEU 10+)模型,而同等平行句對量很難從頭訓(xùn)練一個(gè)可使用的MT模型(BLEU接近0)。
簡單概況,mRASP具有如下幾點(diǎn)優(yōu)勢:
1. 模型簡單易復(fù)現(xiàn)
mRASP的預(yù)訓(xùn)練僅使用了共1.1億對平行句對(由于同一對平行句對對兩個(gè)方向都適用,所以一共是2.2億個(gè)訓(xùn)練樣本),詞表大小僅64k個(gè)bpe subword,相比于其它預(yù)訓(xùn)練方法,動(dòng)輒百億數(shù)據(jù)幾十層網(wǎng)絡(luò),訓(xùn)練難度更小,單機(jī)8卡不到一周在32個(gè)語言上就可以完成預(yù)訓(xùn)練。當(dāng)然在更多語言上的預(yù)訓(xùn)練模型也可以簡單擴(kuò)展獲得。
2. 通用性極強(qiáng)
mRASP在大中小規(guī)模訓(xùn)練集上,相對于直接訓(xùn)練的單向機(jī)器翻譯模型,效果都有一定的提升,甚至包括平行語料最多的語向英語到法語(提升了1.1BLEU)。即使對于預(yù)訓(xùn)練數(shù)據(jù)中從來沒有見過的語種荷蘭語到葡萄牙語,也取得了 10+BLEU 的顯著收益。
這里摘錄了有代表性的部分實(shí)驗(yàn)結(jié)果:
3.1. En-De和En-Fr Benchmark
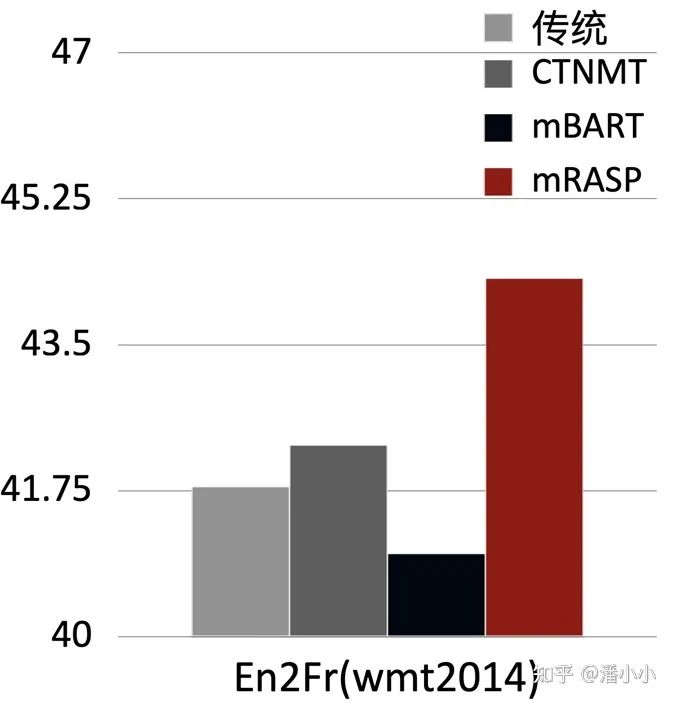
下圖中對比了mRASP加微調(diào)在英德(En-De)和英法(En-Fr)上的效果和最近同期的其他幾個(gè)跨語言預(yù)訓(xùn)練模型加微調(diào)的結(jié)果。可以看出,mRASP的效果是有一定優(yōu)勢的,En-》De wmt 2016測試集上達(dá)到了30.3 (tokenized BLEU), En-》Fr wmt 2014測試集上達(dá)到了44.3 (tokenized BLEU)。CTNMT 使用了 BERT預(yù)訓(xùn)練。MASS使用了大規(guī)模單語數(shù)據(jù)。mBERT是多語言 BERT 模型。mBART 是同期出現(xiàn)的另一種預(yù)訓(xùn)練方式,引入了海量多語言單語數(shù)據(jù),訓(xùn)練時(shí)間也達(dá)到256卡20天。
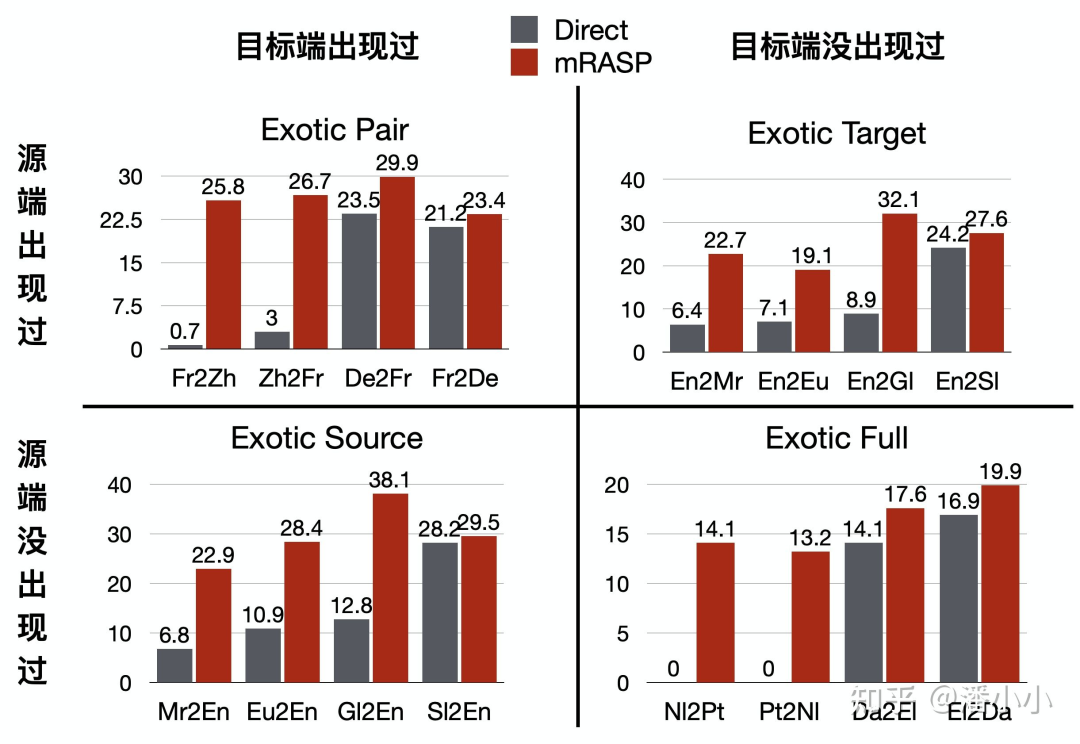
3.2. 預(yù)訓(xùn)練階段沒見過的語言擴(kuò)展
不包含在預(yù)訓(xùn)練階段平行句對中的語向,也稱作“Exotic Directions”,在Exotic Directions上是否有效果,決定了 mRASP 是否具有很好的擴(kuò)展性和泛化能力。
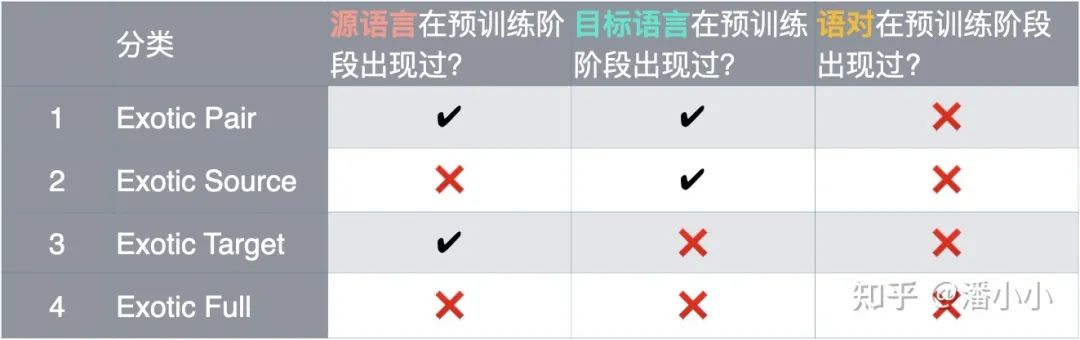
論文中對Exotic Directions分為四種情況:
Exotic Pair: 源語言和目標(biāo)語言都經(jīng)過了單獨(dú)的預(yù)訓(xùn)練,但模型還沒有見過它們組成的雙語對
Exotic Source: 模型在預(yù)訓(xùn)練階段只見過目標(biāo)端語言,源端語言完全沒見過
Exotic Target: 模型在預(yù)訓(xùn)練階段只見過源端語言,目標(biāo)端語言完全沒見過
Exotic Full: 模型在預(yù)訓(xùn)練階段完全沒見過源端語言和目標(biāo)端語言
這四種未見語對情況下訓(xùn)練機(jī)器翻譯都很難。當(dāng)然其中難度最大的是最后一種,相當(dāng)于要求只學(xué)習(xí)了中文和英語的人,讀少量拉丁語和印地語的句子就可以從拉丁語到印地語翻譯。
Exotic Directions的四種分類
值得關(guān)注的是,法中(Fr-Zh)兩邊都單獨(dú)出現(xiàn)過,但是沒有作為平行語對出現(xiàn)過,只使用了20K平行語料就可以達(dá)到20+的BLEU score。
同時(shí),對于兩邊語言都沒在預(yù)訓(xùn)練階段出現(xiàn)過的語對,比如荷蘭語到葡萄牙語(Nl-Pt),只使用1.2萬句平行語料,經(jīng)過大概10分鐘的訓(xùn)練后,也可以達(dá)到10+ BLEU score。
3.3. 案例分析

英語-法語案例。mRASP方法訓(xùn)練出來的模型比Direct方法的模型優(yōu)秀的地方之一在于: Direct系統(tǒng)忽略了無實(shí)際意義單詞(比如冠詞,指示詞等)的傾向,而mRASP保持了冠詞和指示詞的一致。

法語-中文案例。Exotic Pair,20k平行句對。Direct 0.7 BLEU 遠(yuǎn)弱于 mRASP 25.8 BLEU,Direct系統(tǒng)完全不能翻譯,而mRASP系統(tǒng)翻譯得很好

荷蘭語-葡萄牙語案例。Exotic Full,1.2萬平行句對。Direct 0 BLEU vs mRASP 14.1 BLEU。mRASP得到的荷葡翻譯模型的翻譯效果雖然不能成功翻譯每個(gè)細(xì)節(jié),但是能抓住原文的一些關(guān)鍵信息。比如例子中的(1) 日期 (2) 會(huì)議記錄 -會(huì)議的消息 (3) 分發(fā)-共享。
3.4. 效果分析mRASP
作為通用的預(yù)訓(xùn)練模型,它對各個(gè)MT下游任務(wù)的的提升效果從何而來?
作者認(rèn)為,其提升主要來源于兩個(gè)方面:
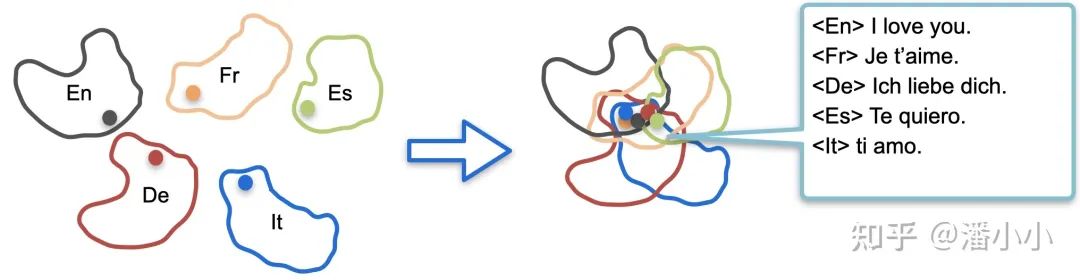
mRASP拉近了不同語言間同義詞的向量表示
mRASP拉近了不同語言間同義句子的向量表示
單詞級(jí)別和句子級(jí)別的表示被拉近意味著: 經(jīng)過預(yù)訓(xùn)練階段對大量語言的平行句對的處理和學(xué)習(xí),mRASP隱式地“掌握”了語言無關(guān)的表示,而這個(gè)表示是可以被遷移到任意語言上的,因此mRASP可以普遍地提高機(jī)器翻譯下游任務(wù)的效果。
1. mRASP拉近不同語言單詞級(jí)別的向量表示
RAS的引入通過使得不同語言的同義詞之間共享相同的上下文,而在NLP中詞義是由上下文(context)決定的,從而進(jìn)一步拉近不同語言之間同義詞的表示。
左圖: w/o RAS, 右圖: w/ RAS
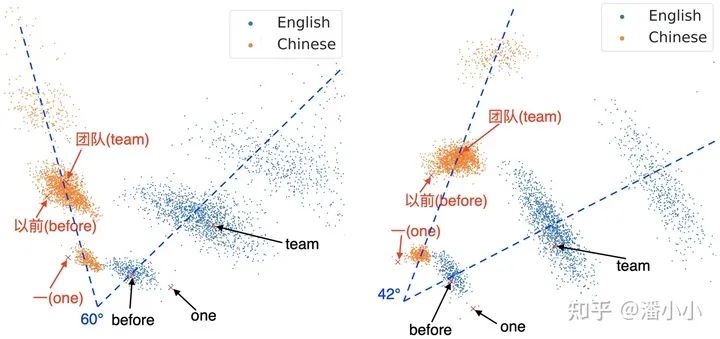
可以看出,加了RAS方法之后,不同語言之間的embedding分布被拉近了(角度變小)。
2. mRASP拉近不同語言句子級(jí)別的向量表示
除了拉近同義詞的向量表示之外,mRASP也拉近了語義的向量表示。
使用編碼器輸出向量作為句子的空間表征(L2 normalized averaged-pooled encoder output),從TED平行測試集(經(jīng)過過濾得到的15-way 平行測試集,共2284條) 中匹配到相似度(cosine similarity)最近的句子,計(jì)算Top-1準(zhǔn)確度(sentence retrieval accuracy)。mRASP 檢索的平均準(zhǔn)確度達(dá)到76%。我們將mRASP和mBART[9]進(jìn)行對比:
mRASP的準(zhǔn)確度減去mBART的準(zhǔn)確度,注意荷蘭語(Nl)在mRASP預(yù)訓(xùn)練數(shù)據(jù)中完全沒出現(xiàn)過,其他方向上的準(zhǔn)確度都大大超過了mBART。
mRASP的準(zhǔn)確度減去不使用RAS的mRASP的方法的準(zhǔn)確度。可以看出mRASP的RAS方法在預(yù)訓(xùn)練階段沒出現(xiàn)過的語言(Nl)上有明顯收益
將句首的語種標(biāo)識(shí)符(Language token)去掉以后,Nl的準(zhǔn)確度還可以進(jìn)一步提升,不過其他語言上的準(zhǔn)確度大幅下降
總結(jié)
mRASP建立了多語言預(yù)訓(xùn)練到微調(diào)到多個(gè)語種翻譯模型的成功路徑,這也會(huì)成為機(jī)器翻譯的新范式。我們很期待在這個(gè)方向上不斷有新的方法涌現(xiàn)出來,朝向最終目標(biāo)大踏步前進(jìn)。未來幾年,機(jī)器翻譯的進(jìn)展可以幫助幾十上百個(gè)國家的每個(gè)人真正無語言障礙的溝通交流。
最后,附上我們的Github[10]、Paper[11]和體驗(yàn)官網(wǎng)[12]。
4. 手把手教你用mRASP快速得到任意翻譯模型
簡單上手
下面我們就來手把手教大家如何使用作者開源的mRASP模型來快速得到一個(gè)單向的機(jī)器翻譯模型。在后面的例子中,我們選用作者提供的toy en-de數(shù)據(jù)集[13]來做示范。
環(huán)境配置
在開始正式訓(xùn)練的過程之前,我們首先需要配置好環(huán)境。
由于作者的實(shí)現(xiàn)是基于fairseq(使用pytorch框架)的,因此你需要安裝pytorch。
將repo同步到本地,并且使用pip命令安裝requirements.txt文件里的包。
git
clone https://github.com/linzehui/mRASP.git
cd mRASP
pip install -r requirements.txt
下載mRASP模型
進(jìn)入作者分享的鏈接里下載,這里我們需要下載有RAS的版本[14]。
訓(xùn)練數(shù)據(jù)預(yù)處理
合并詞表(可選)
如果使用原來的詞表,跳過這一步。當(dāng)你需要加入新的語種(不在原詞表支持的59個(gè)語種中)時(shí),需要先將詞表進(jìn)行合并:
python ${PROJECT_ROOT}/train/scripts/concat_merge_vocab.py --checkpoint ${CKPT} --now-vocab ${CURRENT_VOCAB} --to-append-vocab ${NEW_VOCAB} --output-dir ${OUTPUT_DIR}
預(yù)處理訓(xùn)練集和測試集
對數(shù)據(jù)進(jìn)行清洗、tokenize、subword操作,其中subword使用的是原來的詞表或者合并后的詞表,具體配置在yaml配置文件中展開。
# training set
bash ${PROJECT_ROOT}/preprocess/multilingual_preprocess_main.sh ${PROJECT_ROOT}/experiments/example/configs/preprocess/train_en2de.yml
# test set
bash ${PROJECT_ROOT}/preprocess/multilingual_preprocess_main.sh ${PROJECT_ROOT}/experiments/example/configs/preprocess/test_en2de.yml
配置文件如下
https://github.com/linzehui/mRASP/blob/master/experiments/example/configs/preprocess/train_en2de.yml
https://github.com/linzehui/mRASP/blob/master/experiments/example/configs/preprocess/test_en2de.yml
運(yùn)行預(yù)處理腳本會(huì)產(chǎn)生如下輸出
==== Working directory: ====
/data00/home/panxiao.94/experiments/pmnmt/preprocess
============================
======== 1. Clean & Tokenization BEGIN ========
******** Generate config for LANGUAGE ********
******** Generate config for LANGUAGE PAIR en_de and Clean & Tokenize en_de Parallel Data ********
======== 1. Clean & Tokenization ALL DONE ========
======== 2. Subword & Vocab BEGIN ========
******** Only Apply BEGIN ********
******** Only Apply ALL DONE ********
======== 2. Subword & Vocab ALL DONE ========
======== 3. Merge BEGIN ========
======== 3. Merge ALL DONE ========
處理好的數(shù)據(jù)會(huì)出現(xiàn)在${merged_output_path}所指定的位置
#比如,在測試集配置文件所指定的${merged_output_path}目錄下面
dev.de dev.en
在預(yù)處理完之后,需要將上述數(shù)據(jù)進(jìn)行binarize(fairseq中特定的二進(jìn)制化操作),具體操作可以參考
bash ${PROJECT_ROOT}/experiments/example/bin_finetune.sh
運(yùn)行時(shí)顯示如下
微調(diào)訓(xùn)練
新建微調(diào)階段配置文件
作者使用的是yaml格式的配置文件,微調(diào)階段的配置參數(shù)如下面的例子,各參數(shù)的具體說明可以在作者的說明中找到。
src: en
tgt: de
model_arch: transformer_wmt_en_de_big
encoder_learned_pos: true
decoder_learned_pos: true
data_path: /data00/home/panxiao.94/experiments/mRASP/experiments/example/data/fine-tune/en2de
model_dir: /data00/home/panxiao.94/experiments/mRASP/experiments/example/models/fine-tune/transformer_big/en2de
pretrain_model_dir: /data00/home/panxiao.94/experiments/mRASP/experiments/example/models/pre-train/transformer_big
update_freq: 1
log_interval: 5
save_interval_updates: 50
max_update: 500
max_tokens: 2048
max_source_positions: 256
max_target_positions: 256
lr: 5e-4
dropout: 0.2
activation_fn: gelu
criterion: label_smoothed_cross_entropy
reset_optimizer: true
reset_lr_scheduler: true
reset_dataloader: true
reset_meters: true
lr_scheduler: inverse_sqrt
weight_decay: 0.0
clip_norm: 0.0
warmup_init_lr: 1e-07
label_smoothing: 0.1
fp16: true
seed: 9823843
開始訓(xùn)練!
在準(zhǔn)備好配置文件后,運(yùn)行下面的命令
export CUDA_VISIBLE_DEVICES=0,1,2 && export EVAL_GPU_INDEX=${eval_gpu_index} && bash ${PROJECT_ROOT}/train/fine-tune.sh ${finetune_yml} ${eval_yml}
eval_gpu_index 表示被分配用于在訓(xùn)練時(shí)進(jìn)行評(píng)估的GPU的id,如果設(shè)置成 -1則表示在訓(xùn)練過程中將使用CPU進(jìn)行評(píng)估。
${finetune_yml}是上一步中配置好的yaml文件
${eval_yml} 參考https://github.com/linzehui/mRASP/blob/master/experiments/example/configs/eval/en2de_eval.yml
用模型翻譯吧!
當(dāng)訓(xùn)練完成后,我們就可以直接使用fairseq-interactive來實(shí)時(shí)生成翻譯了。假設(shè)將checkpoint和bpe codes文件都放在${PROJECT_ROOT}/model目錄下,那么可以運(yùn)行下面的命令:
repo_dir=${PROJECT_ROOT}
fairseq-interactive
--path ${repo_dir}/model/checkpoint_last.pt
--beam 5 --source-lang en --target-lang de
--tokenizer moses
--bpe subword_nmt --bpe-codes ${repo_dir}/model/codes.bpe.32000
注意輸入文本時(shí),一定要在句子前加上language token,比如:
LANG_TOK_EN This was also confirmed by Peter Arnold from the Offenburg District Office.
模型的輸出也會(huì)以目標(biāo)端語言的language token為開頭:
LANG_TOK_DE Dies best?tigt auch Peter Arnold vom Landratsamt Offenburg.
原文標(biāo)題:機(jī)器翻譯界的BERT:可快速得到任意機(jī)翻模型的mRASP
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
AI
+關(guān)注
關(guān)注
87文章
30896瀏覽量
269108 -
人工智能
+關(guān)注
關(guān)注
1791文章
47279瀏覽量
238511 -
機(jī)器翻譯
+關(guān)注
關(guān)注
0文章
139瀏覽量
14886
原文標(biāo)題:機(jī)器翻譯界的BERT:可快速得到任意機(jī)翻模型的mRASP
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
相關(guān)推薦
LLMWorld上線代碼翻譯新工具——問丫·碼語翻譯俠,快來體驗(yàn)!
IMAX攜手Camb.AI實(shí)現(xiàn)影院實(shí)時(shí)語言翻譯
ASR技術(shù)的未來發(fā)展趨勢 ASR系統(tǒng)常見問題及解決方案
安寶特分享 | AR技術(shù)引領(lǐng):跨國工業(yè)遠(yuǎn)程協(xié)作創(chuàng)新模式

ChatGPT 的多語言支持特點(diǎn)
科大訊飛發(fā)布訊飛星火4.0 Turbo大模型及星火多語言大模型
DeepL推出新一代翻譯編輯大型語言模型
超ChatGPT-4o,國產(chǎn)大模型竟然更懂翻譯,8款大模型深度測評(píng)|AI 橫評(píng)

nlp自然語言處理基本概念及關(guān)鍵技術(shù)
nlp自然語言處理的應(yīng)用有哪些
微軟Edge瀏覽器將支持多語言實(shí)時(shí)視頻翻譯功能
【大語言模型:原理與工程實(shí)踐】大語言模型的基礎(chǔ)技術(shù)
大語言模型(LLMs)如何處理多語言輸入問題

Transformer壓縮部署的前沿技術(shù):RPTQ與PB-LLM





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論