 提供全域數據與服務的畫像標簽體系
提供全域數據與服務的畫像標簽體系
阿里
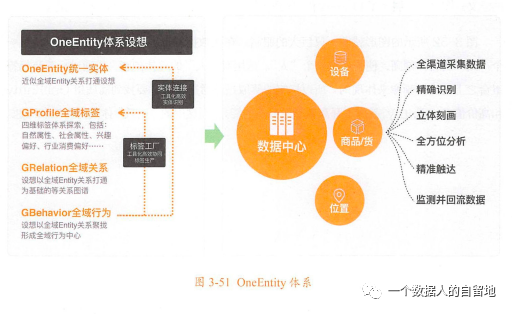
為打破數據孤島,創造更大的數據價值,阿里設計了OneEntity來提供全域數據與服務。OneEntity體系主要包含統一實體、全域標簽、全域關系、全域行為4大類。
01
標簽分類
其中GProfile全域標簽的分類,將“人”的立體刻畫劃分為“人的核心屬性”和“人的向往與需求”2大部分,具體包含4大類:
人的核心屬性,可分為自然屬性、社會屬性。
-自然屬性:是指人的肉體存在及其特征,是人自出生后自然存在的,一般不會因人為因素發生較大的改變。例如“性別”“生肖”“年齡”“身高”“體重”等。
-社會屬性:指人在實踐活動基礎上產生的一切社會關系的總和。人一旦進入社會就會產生社會屬性。例如經濟狀況、家庭狀況、社會地位、政治宗教、地理位置、價值觀等。
人的向往與需求,可分為興趣偏好、行為消費偏好。
-興趣偏好:是人堆非物化對象的內在心理向往與外在行為表達,是一種法子內心的本能喜好,與物質無必然關系。例如渴望愛情、需要安全感、討厭臟亂環境等。
-行為消費偏好:是人對物化對象的需求與外在行為表達,涉及各行業,與物質世界存在千絲萬縷的聯系。例如母嬰行業偏好、美妝行業偏好、洗護行業偏好、家裝行業偏好等。
在以上四大類的基礎上,我們又嘗試根據不同的業務形態進一步細分二級、三級分類。
02
標簽萃取
標簽的萃取工作包含:數據采集;清洗,去噪聲并統一;反復試用并確定最佳算法及模型;為模型選擇計算因子并對模型中的每一個計算因子調配權重;產出標簽質量評估報告以輔助驗收。
我們隨機抽查了若干個在用的標簽,預估工作量和工作周期,一個有價值的標簽的萃取,平均耗時2周。
慢的主要原因,一是由于萃取流程復雜,每個標簽萃取都依賴底層的基礎數據,而較少依賴上一層匯總的數據中間層數據;二是大量重復的人力,對應的標簽萃取邏輯時可以復用的,包含算法的選擇、模型訓練和計算因子的加權等,但由于不同人來做,造成了很多重復工作。
標簽萃取過程復雜,那有什么可以參考的流程呢?
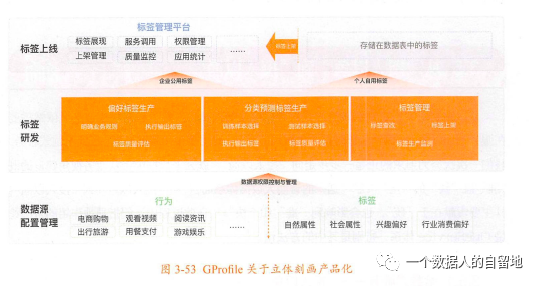
首先,數據源層面:建設一套完整的數據源,以OneEntity體系為核心,將OneEntity相關實體及其行為全部串聯起來,與存量的標簽一起作為數據源。
其次,標簽計算層面:將標簽萃取邏輯沉淀為2種,分別對應到偏好類標簽和分類預測類標簽的工具型產品的生產過程中,包含計算因子、權重等業務規則、數據樣本選擇、模型與算法選擇等。
最后,標簽監測層面:沉淀質量評估報告和生產監測、上線等管理流程。
當一整套工具型產品上線之后,批量生產十幾個同類型標簽只需要2天左右,這是因為在補足數據源、確定業務規則、選擇數據樣本、選擇算法與模型的過程中,減少了大量的代碼開發與模型訓練的工作。
在這個過程中,參與的角色也發生了變化,從原本的以數據產品經理、數倉工程師、數據科學家為主導,轉變為對業務更為熟悉的業務人員、數據分析師為主導。
2
網易
網易大數據融合用戶娛樂、電商購物、教育、新聞資訊、通訊等多行業10+產品線,構建起全域用戶畫像數據,目前總標簽1000+,ID量URS、phone、idfa、IMEI、oaid等均達到憶級。
01
標簽分類
1.基礎標簽:
性別、年齡、教育背景、生活習慣(早起晚起)、地理位置(POI信息)、職業狀況、經濟情況(有車有房)、設備信息(手機、運營商等)、會員信息(會員等級)、衍生信息。
其中衍生標簽,如評估是否已婚,在原由標簽體系下沒有此類標簽,但可通過多個標簽進行組合生成新的標簽,包含是否有小孩、30歲等條件組合。
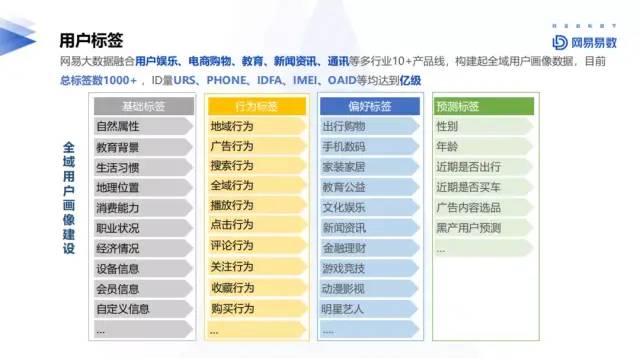
2. 行為標簽
包含地域、廣告、搜過、播放、點擊、評論、關注、收藏、購買等維度。
3. 偏好標簽
包含出行購物、手機數碼、家裝家居、教育公益、文化娛樂、新聞資訊、金融理財、游戲競技、動漫影視、明星藝人等維度
4. 預測標簽
包含利用算法進行預測生成的標簽,包含是否出行、是否買車等標簽。
注意:
1. 標簽的枚舉值十分重要,業務分析過程中很容易出現枚舉值的偏差,不符合實際業務邏輯
2. 注意標簽之間的沖突,如年齡15歲,學歷卻是博士或者有小孩
02
標簽計算
預測類標簽案例:性別,主要包含三種方案:
1. 標簽傳播:根據用戶在各個業務場景,如母嬰商品點擊行為,進行item標記,構建user-item的興趣網絡進行 Graph Embedding,最后進行分類,預測用戶的性別。
2. 語義分析:利用NLP算法對用戶昵稱進行語義分析
3. 自行填寫:利用業務屬性自行填寫的內容進行判斷,此處需對數據質量進行過濾,排除如生日為1990-01-01的參數異常值信息。

基于上述三類算法特征結果集,對模型進行融合,然后對用戶的性別進行預測,其準確率在0.6以上。
注意:需要突破的地方在于特征的稀疏性,因為ID-mapping打通后,數據覆蓋率僅20%左右,嚴重影響了模型的整體效果。
3
汽車之家
用戶畫像的構建就是把用戶標簽分列到不同的類里面,這些類都是什么,彼此之間的聯系,就構成了標簽體系。
01
按用途分類
1.人口屬性:用戶自然屬性、用戶會員、用戶所屬年代、用戶價值登記、是否增換購用戶、用戶分群、UVN-B用戶分群、用戶分層、用戶流失預警
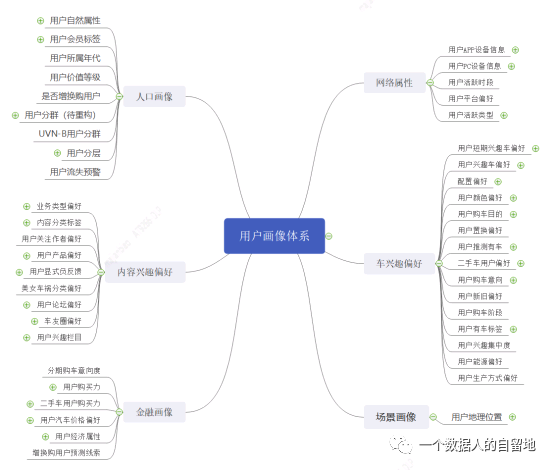
2.網絡屬性:用戶APP設備信息、用戶PC設備信息、用戶活躍時段、用戶平臺偏好、用戶活躍類型
3.內容興趣偏好:業務類型偏好、內容分類標簽、用戶關注作者偏好、用戶產品偏好、用戶顯式負反饋、用戶論壇偏好、車友圈偏好、用戶興趣欄目
4.車興趣偏好 :用戶短期興趣車偏好、用戶興趣車偏好、配置偏好、用戶顏色偏好、用戶購車目的、用戶置換偏好、用戶推薦有車、二手車用戶偏好、用戶購車意向、用戶新舊偏好、用戶購車階段、用戶有車標簽、用戶興趣集中度、用戶能源偏好、用戶生產方式偏好
5.金融畫像:分期購車意向度、用戶購買力、二手車用戶購買力、用戶汽車價格偏好、用戶經濟屬性、增換購用戶預測線索
6.場景畫像:用戶地理位置
02
按統計方式分類
1.統計類標簽
統計類標簽,通過業務規則,將業務問題轉化為數據口徑實現。如收藏列表、 搜索關鍵詞、保險到期時間、是否下過線索、30天內訪問xx次等。
2.興趣類標簽
興趣類標簽,基于興趣遷移模型構建用戶標簽。綜合考慮特征、特征權重、距今時間、行為次數等因素,用戶興趣標簽構建公式如下:
用戶興趣標簽=行為類型權重*時間衰減*行為次數
-特征:需要結合業務選擇,如瀏覽、搜索、線索、對比、互動、點擊、有車等行為。
-權重:用戶在平臺上發生的行為具體到用戶標簽層面有著不同的行為權重,一般而言,行為發生的成本越高,權重越大。可以由業務人員確定,也可以采用TF-IDF技術分析得出。
-時間衰減:用戶行為收時間的影響不斷衰減,距離現在越遠,對用戶興趣的影響越低,這里采用牛頓冷卻定律的思想擬合衰減系數,衰減周期結合業務制定。
-行為次數:在固定時間周期內行為發生的次數越多,興趣傾向越重。
3.模型類標簽
基于機器學習方法進行數據建模預測用戶的標簽,這類標簽在標簽體系中占比較少,其實現難度高,開發成本高。
例如:
-是否有車:基于RF+LR模型實現
-常駐地:基于GPS聚類獲取,采用DBSCAN
-購車轉化:GBDT
-用戶分群:KMENAS聚類產生
03
按時效分類
從數據時效上,可分為離線畫像和實時畫像。離線與實時采用的構建思想相同,不同之處在于:
-離線畫像:描述用戶長期的習慣;
-實時畫像:描述用戶當下的興趣,會隨時間的改變而發生變更;
總結
各大公司的標簽分類不同,現市面上有三種常用的標簽分類方式,按用途分類,可分為基礎信息、用戶行為、業務偏好、場景標簽;按統計方式分類,可分為事實類標簽、規則類標簽、預測類標簽;按時效分類,可分為靜態標簽、動態標簽。
原文標題:干貨:阿里/網易/汽車之家畫像標簽體系
文章出處:【微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
數據
+關注
關注
8文章
7104瀏覽量
89287 -
機器學習
+關注
關注
66文章
8428瀏覽量
132841
原文標題:干貨:阿里/網易/汽車之家畫像標簽體系
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
有方科技參加中國信通院城市全域數字化轉型分論壇
【「RISC-V體系結構編程與實踐」閱讀體驗】-- SBI及NEMU環境
IP風險畫像詳細接入規范、API參數(Ipdatacloud)

華為云全域 Serverless 8 月更新盤點

軟通動力數據庫全棧服務,助力企業數據庫體系全面升級

調用云服務認證體系
IP風險畫像如何維護網絡安全
凱睿德制造與 Loftware 合作提供 MES 和標簽的無縫集成
服務提供商數據在精確定位中的應用
元服務體驗-服務發現
云安全服務體系由哪五部分組成
工業互聯網三大體系是什么?
AWTK 開源串口屏開發(16) - 提供 MODBUS 服務

海辰儲能榮獲NECAS、CTEAS售后服務體系雙項權威認證






 工商網監
工商網監
評論