 Linux中epoll是如何實現IO多路復用的?
Linux中epoll是如何實現IO多路復用的?
進程在 Linux 上是一個開銷不小的家伙,先不說創建,光是上下文切換一次就得幾個微秒。所以為了高效地對海量用戶提供服務,必須要讓一個進程能同時處理很多個 tcp 連接才行。現在假設一個進程保持了 10000 條連接,那么如何發現哪條連接上有數據可讀了、哪條連接可寫了 ?
我們當然可以采用循環遍歷的方式來發現 IO 事件,但這種方式太低級了。我們希望有一種更高效的機制,在很多連接中的某條上有 IO 事件發生的時候直接快速把它找出來。其實這個事情 Linux 操作系統已經替我們都做好了,它就是我們所熟知的 IO 多路復用機制。這里的復用指的就是對進程的復用。
在 Linux 上多路復用方案有 select、poll、epoll。它們三個中 epoll 的性能表現是最優秀的,能支持的并發量也最大。所以我們今天把 epoll 作為要拆解的對象,深入揭秘內核是如何實現多路的 IO 管理的。
為了方便討論,我們舉一個使用了 epoll 的簡單示例(只是個例子,實踐中不這么寫):
int main(){
listen(lfd, );
cfd1 = accept();
cfd2 = accept();
efd = epoll_create();
epoll_ctl(efd, EPOLL_CTL_ADD, cfd1, );
epoll_ctl(efd, EPOLL_CTL_ADD, cfd2, );
epoll_wait(efd, )
}
其中和 epoll 相關的函數是如下三個:
epoll_create:創建一個 epoll 對象
epoll_ctl:向 epoll 對象中添加要管理的連接
epoll_wait:等待其管理的連接上的 IO 事件
借助這個 demo,我們來展開對 epoll 原理的深度拆解。相信等你理解了這篇文章以后,你對 epoll 的駕馭能力將變得爐火純青!!
友情提示,萬字長文,慎入!!
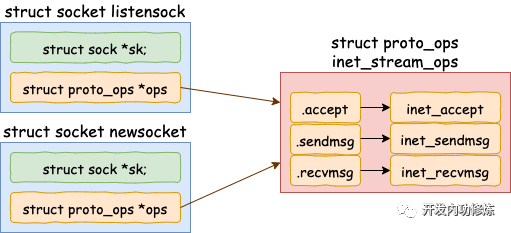
一、accept 創建新 socket
我們直接從服務器端的 accept 講起。當 accept 之后,進程會創建一個新的 socket 出來,專門用于和對應的客戶端通信,然后把它放到當前進程的打開文件列表中。
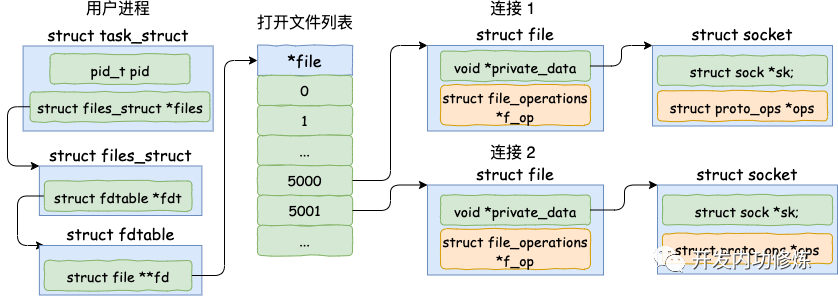
其中一條連接的 socket 內核對象更為具體一點的結構圖如下。
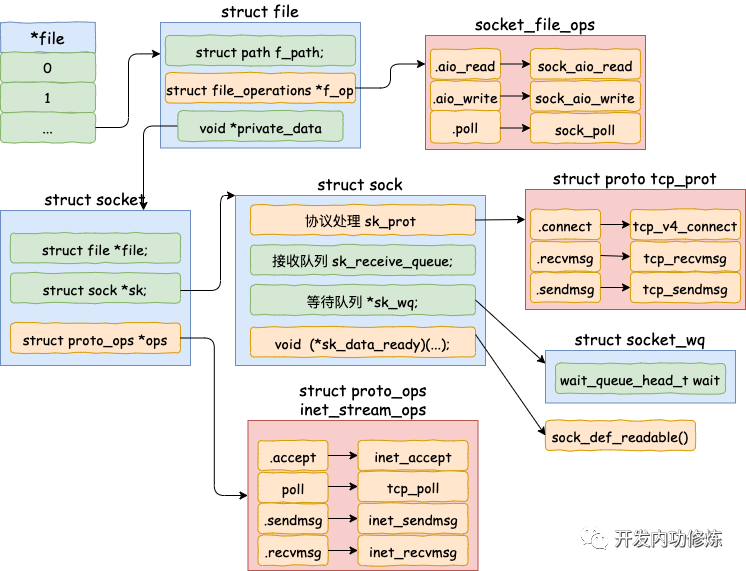
接下來我們來看一下接收連接時 socket 內核對象的創建源碼。accept 的系統調用代碼位于源文件 net/socket.c 下。
//file: net/socket.c
SYSCALL_DEFINE4(accept4, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen, int, flags)
{
struct socket *sock, *newsock;
//根據 fd 查找到監聽的 socket
sock = sockfd_lookup_light(fd, &err, &fput_needed);
//1.1 申請并初始化新的 socket
newsock = sock_alloc();
newsock-》type = sock-》type;
newsock-》ops = sock-》ops;
//1.2 申請新的 file 對象,并設置到新 socket 上
newfile = sock_alloc_file(newsock, flags, sock-》sk-》sk_prot_creator-》name);
//1.3 接收連接
err = sock-》ops-》accept(sock, newsock, sock-》file-》f_flags);
//1.4 添加新文件到當前進程的打開文件列表
fd_install(newfd, newfile);
1.1 初始化 struct socket 對象
在上述的源碼中,首先是調用 sock_alloc 申請一個 struct socket 對象出來。然后接著把 listen 狀態的 socket 對象上的協議操作函數集合 ops 賦值給新的 socket。(對于所有的 AF_INET 協議族下的 socket 來說,它們的 ops 方法都是一樣的,所以這里可以直接復制過來)
其中 inet_stream_ops 的定義如下
//file: net/ipv4/af_inet.c
const struct proto_ops inet_stream_ops = {
.accept = inet_accept,
.listen = inet_listen,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
}
1.2 為新 socket 對象申請 file
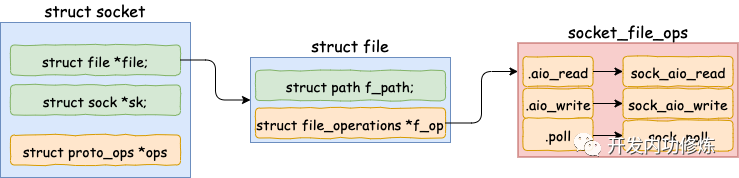
struct socket 對象中有一個重要的成員 -- file 內核對象指針。這個指針初始化的時候是空的。在 accept 方法里會調用 sock_alloc_file 來申請內存并初始化。然后將新 file 對象設置到 sock-》file 上。
來看 sock_alloc_file 的實現過程:
struct file *sock_alloc_file(struct socket *sock, int flags,
const char *dname)
{
struct file *file;
file = alloc_file(&path, FMODE_READ | FMODE_WRITE,
&socket_file_ops);
sock-》file = file;
}
sock_alloc_file 又會接著調用到 alloc_file。注意在 alloc_file 方法中,把 socket_file_ops 函數集合一并賦到了新 file-》f_op 里了。
//file: fs/file_table.c
struct file *alloc_file(struct path *path, fmode_t mode,
const struct file_operations *fop)
{
struct file *file;
file-》f_op = fop;
}
socket_file_ops 的具體定義如下:
//file: net/socket.c
static const struct file_operations socket_file_ops = {
.aio_read = sock_aio_read,
.aio_write = sock_aio_write,
.poll = sock_poll,
.release = sock_close,
};
這里看到,在accept里創建的新 socket 里的 file-》f_op-》poll 函數指向的是 sock_poll。接下來我們會調用到它,后面我們再說。
其實 file 對象內部也有一個 socket 指針,指向 socket 對象。
1.3 接收連接
在 socket 內核對象中除了 file 對象指針以外,有一個核心成員 sock。
//file: include/linux/net.h
struct socket {
struct file *file;
struct sock *sk;
}
這個 struct sock 數據結構非常大,是 socket 的核心內核對象。發送隊列、接收隊列、等待隊列等核心數據結構都位于此。其定義位置文件 include/net/sock.h,由于太長就不展示了。
在 accept 的源碼中:
//file: net/socket.c
SYSCALL_DEFINE4(accept4, )
//1.3 接收連接
err = sock-》ops-》accept(sock, newsock, sock-》file-》f_flags);
}
sock-》ops-》accept 對應的方法是 inet_accept。它執行的時候會從握手隊列里直接獲取創建好的 sock。sock 對象的完整創建過程涉及到三次握手,比較復雜,不展開了說了。咱們只看 struct sock 初始化過程中用到的一個函數:
void sock_init_data(struct socket *sock, struct sock *sk)
{
sk-》sk_wq = NULL;
sk-》sk_data_ready = sock_def_readable;
}
在這里把 sock 對象的 sk_data_ready 函數指針設置為 sock_def_readable。這個這里先記住就行了,后面會用到。
1.4 添加新文件到當前進程的打開文件列表中
當 file、socket、sock 等關鍵內核對象創建完畢以后,剩下要做的一件事情就是把它掛到當前進程的打開文件列表中就行了。
//file: fs/file.c
void fd_install(unsigned int fd, struct file *file)
{
__fd_install(current-》files, fd, file);
}
void __fd_install(struct files_struct *files, unsigned int fd,
struct file *file)
{
fdt = files_fdtable(files);
BUG_ON(fdt-》fd[fd] != NULL);
rcu_assign_pointer(fdt-》fd[fd], file);
}
二、epoll_create 實現
在用戶進程調用 epoll_create 時,內核會創建一個 struct eventpoll 的內核對象。并同樣把它關聯到當前進程的已打開文件列表中。
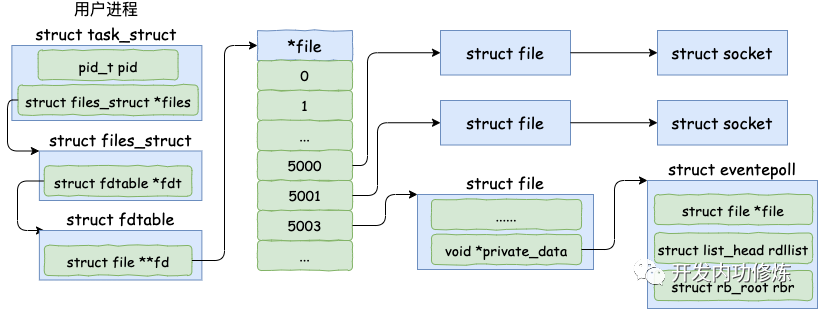
對于 struct eventpoll 對象,更詳細的結構如下(同樣只列出和今天主題相關的成員)。

epoll_create 的源代碼相對比較簡單。在 fs/eventpoll.c 下
// file:fs/eventpoll.c
SYSCALL_DEFINE1(epoll_create1, int, flags)
{
struct eventpoll *ep = NULL;
//創建一個 eventpoll 對象
error = ep_alloc(&ep);
}
struct eventpoll 的定義也在這個源文件中。
// file:fs/eventpoll.c
struct eventpoll {
//sys_epoll_wait用到的等待隊列
wait_queue_head_t wq;
//接收就緒的描述符都會放到這里
struct list_head rdllist;
//每個epoll對象中都有一顆紅黑樹
struct rb_root rbr;
}
eventpoll 這個結構體中的幾個成員的含義如下:
wq: 等待隊列鏈表。軟中斷數據就緒的時候會通過 wq 來找到阻塞在 epoll 對象上的用戶進程。
rbr: 一棵紅黑樹。為了支持對海量連接的高效查找、插入和刪除,eventpoll 內部使用了一棵紅黑樹。通過這棵樹來管理用戶進程下添加進來的所有 socket 連接。
rdllist: 就緒的描述符的鏈表。當有的連接就緒的時候,內核會把就緒的連接放到 rdllist 鏈表里。這樣應用進程只需要判斷鏈表就能找出就緒進程,而不用去遍歷整棵樹。
當然這個結構被申請完之后,需要做一點點的初始化工作,這都在 ep_alloc 中完成。
//file: fs/eventpoll.c
static int ep_alloc(struct eventpoll **pep)
{
struct eventpoll *ep;
//申請 epollevent 內存
ep = kzalloc(sizeof(*ep), GFP_KERNEL);
//初始化等待隊列頭
init_waitqueue_head(&ep-》wq);
//初始化就緒列表
INIT_LIST_HEAD(&ep-》rdllist);
//初始化紅黑樹指針
ep-》rbr = RB_ROOT;
}
說到這兒,這些成員其實只是剛被定義或初始化了,還都沒有被使用。它們會在下面被用到。
三、epoll_ctl 添加 socket
理解這一步是理解整個 epoll 的關鍵。
為了簡單,我們只考慮使用 EPOLL_CTL_ADD 添加 socket,先忽略刪除和更新。
假設我們現在和客戶端們的多個連接的 socket 都創建好了,也創建好了 epoll 內核對象。在使用 epoll_ctl 注冊每一個 socket 的時候,內核會做如下三件事情
1.分配一個紅黑樹節點對象 epitem,
2.添加等待事件到 socket 的等待隊列中,其回調函數是 ep_poll_callback
3.將 epitem 插入到 epoll 對象的紅黑樹里
通過 epoll_ctl 添加兩個 socket 以后,這些內核數據結構最終在進程中的關系圖大致如下:
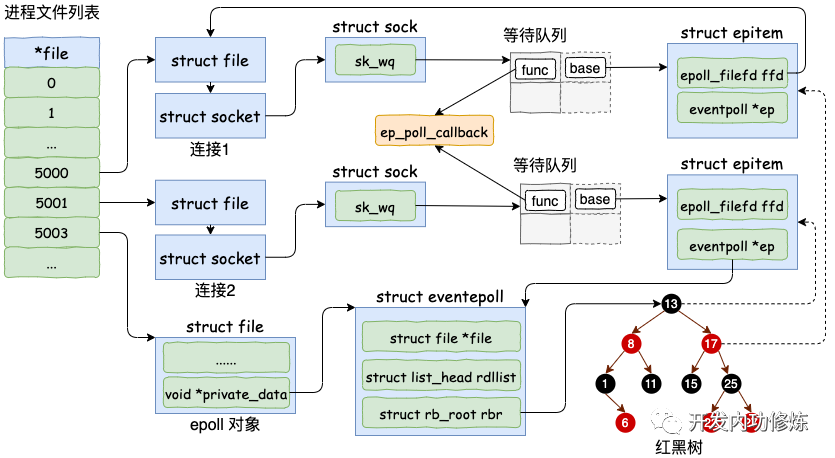
我們來詳細看看 socket 是如何添加到 epoll 對象里的,找到 epoll_ctl 的源碼。
// file:fs/eventpoll.c
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
struct eventpoll *ep;
struct file *file, *tfile;
//根據 epfd 找到 eventpoll 內核對象
file = fget(epfd);
ep = file-》private_data;
//根據 socket 句柄號, 找到其 file 內核對象
tfile = fget(fd);
switch (op) {
case EPOLL_CTL_ADD:
if (!epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_insert(ep, &epds, tfile, fd);
} else
error = -EEXIST;
clear_tfile_check_list();
break;
}
在 epoll_ctl 中首先根據傳入 fd 找到 eventpoll、socket相關的內核對象 。對于 EPOLL_CTL_ADD 操作來說,會然后執行到 ep_insert 函數。所有的注冊都是在這個函數中完成的。
//file: fs/eventpoll.c
static int ep_insert(struct eventpoll *ep,
struct epoll_event *event,
struct file *tfile, int fd)
{
//3.1 分配并初始化 epitem
//分配一個epi對象
struct epitem *epi;
if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)))
return -ENOMEM;
//對分配的epi進行初始化
//epi-》ffd中存了句柄號和struct file對象地址
INIT_LIST_HEAD(&epi-》pwqlist);
epi-》ep = ep;
ep_set_ffd(&epi-》ffd, tfile, fd);
//3.2 設置 socket 等待隊列
//定義并初始化 ep_pqueue 對象
struct ep_pqueue epq;
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
//調用 ep_ptable_queue_proc 注冊回調函數
//實際注入的函數為 ep_poll_callback
revents = ep_item_poll(epi, &epq.pt);
//3.3 將epi插入到 eventpoll 對象中的紅黑樹中
ep_rbtree_insert(ep, epi);
}
3.1 分配并初始化 epitem
對于每一個 socket,調用 epoll_ctl 的時候,都會為之分配一個 epitem。該結構的主要數據如下:
//file: fs/eventpoll.c
struct epitem {
//紅黑樹節點
struct rb_node rbn;
//socket文件描述符信息
struct epoll_filefd ffd;
//所歸屬的 eventpoll 對象
struct eventpoll *ep;
//等待隊列
struct list_head pwqlist;
}
對 epitem 進行了一些初始化,首先在 epi-》ep = ep 這行代碼中將其 ep 指針指向 eventpoll 對象。另外用要添加的 socket 的 file、fd 來填充 epitem-》ffd。
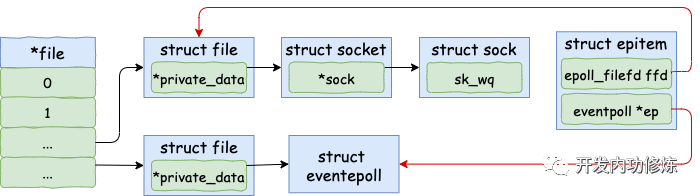
其中使用到的 ep_set_ffd 函數如下。
static inline void ep_set_ffd(struct epoll_filefd *ffd,
struct file *file, int fd)
{
ffd-》file = file;
ffd-》fd = fd;
}
3.2 設置 socket 等待隊列
在創建 epitem 并初始化之后,ep_insert 中第二件事情就是設置 socket 對象上的等待任務隊列。并把函數 fs/eventpoll.c 文件下的 ep_poll_callback 設置為數據就緒時候的回調函數。
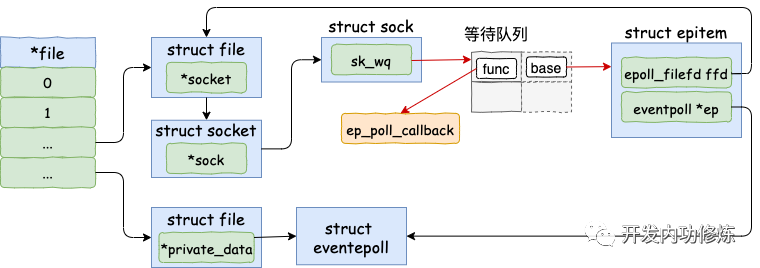
這一塊的源代碼稍微有點繞,沒有耐心的話直接跳到下面的加粗字體來看。首先來看 ep_item_poll。
static inline unsigned int ep_item_poll(struct epitem *epi, poll_table *pt)
{
pt-》_key = epi-》event.events;
return epi-》ffd.file-》f_op-》poll(epi-》ffd.file, pt) & epi-》event.events;
}
看,這里調用到了 socket 下的 file-》f_op-》poll。通過上面第一節的 socket 的結構圖,我們知道這個函數實際上是 sock_poll。
/* No kernel lock held - perfect */
static unsigned int sock_poll(struct file *file, poll_table *wait)
{
return sock-》ops-》poll(file, sock, wait);
}
同樣回看第一節里的 socket 的結構圖,sock-》ops-》poll 其實指向的是 tcp_poll。
//file: net/ipv4/tcp.c
unsigned int tcp_poll(struct file *file, struct socket *sock, poll_table *wait)
{
struct sock *sk = sock-》sk;
sock_poll_wait(file, sk_sleep(sk), wait);
}
在 sock_poll_wait 的第二個參數傳參前,先調用了 sk_sleep 函數。在這個函數里它獲取了 sock 對象下的等待隊列列表頭 wait_queue_head_t,待會等待隊列項就插入這里。這里稍微注意下,是 socket 的等待隊列,不是 epoll 對象的。來看 sk_sleep 源碼:
//file: include/net/sock.h
static inline wait_queue_head_t *sk_sleep(struct sock *sk)
{
BUILD_BUG_ON(offsetof(struct socket_wq, wait) != 0);
return &rcu_dereference_raw(sk-》sk_wq)-》wait;
}
接著真正進入 sock_poll_wait。
static inline void sock_poll_wait(struct file *filp,
wait_queue_head_t *wait_address, poll_table *p)
{
poll_wait(filp, wait_address, p);
}
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && p-》_qproc && wait_address)
p-》_qproc(filp, wait_address, p);
}
這里的 qproc 是個函數指針,它在前面的 init_poll_funcptr 調用時被設置成了 ep_ptable_queue_proc 函數。
static int ep_insert()
{
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
}
//file: include/linux/poll.h
static inline void init_poll_funcptr(poll_table *pt,
poll_queue_proc qproc)
{
pt-》_qproc = qproc;
pt-》_key = ~0UL; /* all events enabled */
}
敲黑板!!!注意,廢了半天的勁,終于到了重點了!在 ep_ptable_queue_proc 函數中,新建了一個等待隊列項,并注冊其回調函數為 ep_poll_callback 函數。然后再將這個等待項添加到 socket 的等待隊列中。
//file: fs/eventpoll.c
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct eppoll_entry *pwq;
f (epi-》nwait 》= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
//初始化回調方法
init_waitqueue_func_entry(&pwq-》wait, ep_poll_callback);
//將ep_poll_callback放入socket的等待隊列whead(注意不是epoll的等待隊列)
add_wait_queue(whead, &pwq-》wait);
}
在前文 深入理解高性能網絡開發路上的絆腳石 - 同步阻塞網絡 IO 里阻塞式的系統調用 recvfrom 里,由于需要在數據就緒的時候喚醒用戶進程,所以等待對象項的 private (這個變量名起的也是醉了) 會設置成當前用戶進程描述符 current。而我們今天的 socket 是交給 epoll 來管理的,不需要在一個 socket 就緒的時候就喚醒進程,所以這里的 q-》private 沒有啥卵用就設置成了 NULL。
//file:include/linux/wait.h
static inline void init_waitqueue_func_entry(
wait_queue_t *q, wait_queue_func_t func)
{
q-》flags = 0;
q-》private = NULL;
//ep_poll_callback 注冊到 wait_queue_t對象上
//有數據到達的時候調用 q-》func
q-》func = func;
}
如上,等待隊列項中僅僅只設置了回調函數 q-》func 為 ep_poll_callback。在后面的第 5 節數據來啦中我們將看到,軟中斷將數據收到 socket 的接收隊列后,會通過注冊的這個 ep_poll_callback 函數來回調,進而通知到 epoll 對象。
3.3 插入紅黑樹
分配完 epitem 對象后,緊接著并把它插入到紅黑樹中。一個插入了一些 socket 描述符的 epoll 里的紅黑樹的示意圖如下:
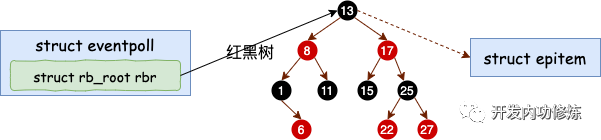
這里我們再聊聊為啥要用紅黑樹,很多人說是因為效率高。其實我覺得這個解釋不夠全面,要說查找效率樹哪能比的上 HASHTABLE。我個人認為覺得更為合理的一個解釋是為了讓 epoll 在查找效率、插入效率、內存開銷等等多個方面比較均衡,最后發現最適合這個需求的數據結構是紅黑樹。
四、epoll_wait 等待接收
epoll_wait 做的事情不復雜,當它被調用時它觀察 eventpoll-》rdllist 鏈表里有沒有數據即可。有數據就返回,沒有數據就創建一個等待隊列項,將其添加到 eventpoll 的等待隊列上,然后把自己阻塞掉就完事。
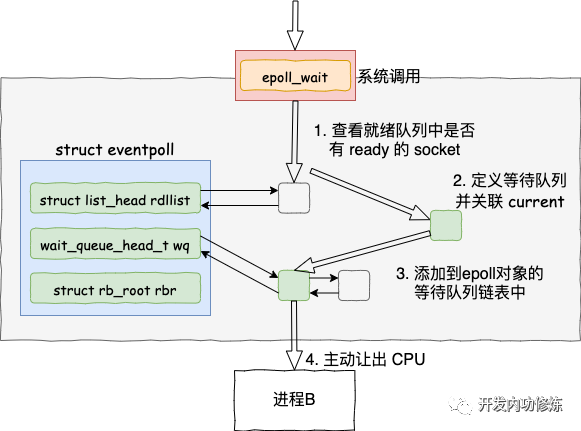
注意:epoll_ctl 添加 socket 時也創建了等待隊列項。不同的是這里的等待隊列項是掛在 epoll 對象上的,而前者是掛在 socket 對象上的。
其源代碼如下:
//file: fs/eventpoll.c
SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
int, maxevents, int, timeout)
{
error = ep_poll(ep, events, maxevents, timeout);
}
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
wait_queue_t wait;
fetch_events:
//4.1 判斷就緒隊列上有沒有事件就緒
if (!ep_events_available(ep)) {
//4.2 定義等待事件并關聯當前進程
init_waitqueue_entry(&wait, current);
//4.3 把新 waitqueue 添加到 epoll-》wq 鏈表里
__add_wait_queue_exclusive(&ep-》wq, &wait);
for (;;) {
//4.4 讓出CPU 主動進入睡眠狀態
if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS))
timed_out = 1;
}
4.1 判斷就緒隊列上有沒有事件就緒
首先調用 ep_events_available 來判斷就緒鏈表中是否有可處理的事件。
//file: fs/eventpoll.c
static inline int ep_events_available(struct eventpoll *ep)
{
return !list_empty(&ep-》rdllist) || ep-》ovflist != EP_UNACTIVE_PTR;
}
4.2 定義等待事件并關聯當前進程
假設確實沒有就緒的連接,那接著會進入 init_waitqueue_entry 中定義等待任務,并把 current (當前進程)添加到 waitqueue 上。
是的,當沒有 IO 事件的時候, epoll 也是會阻塞掉當前進程。這個是合理的,因為沒有事情可做了占著 CPU 也沒啥意義。網上的很多文章有個很不好的習慣,討論阻塞、非阻塞等概念的時候都不說主語。這會導致你看的云里霧里。拿 epoll 來說,epoll 本身是阻塞的,但一般會把 socket 設置成非阻塞。只有說了主語,這些概念才有意義。
//file: include/linux/wait.h
static inline void init_waitqueue_entry(wait_queue_t *q, struct task_struct *p)
{
q-》flags = 0;
q-》private = p;
q-》func = default_wake_function;
}
注意這里的回調函數名稱是 default_wake_function。后續在第 5 節數據來啦時將會調用到該函數。
4.3 添加到等待隊列
static inline void __add_wait_queue_exclusive(wait_queue_head_t *q,
wait_queue_t *wait)
{
wait-》flags |= WQ_FLAG_EXCLUSIVE;
__add_wait_queue(q, wait);
}
在這里,把上一小節定義的等待事件添加到了 epoll 對象的等待隊列中。
4.4 讓出CPU 主動進入睡眠狀態
通過 set_current_state 把當前進程設置為可打斷。調用 schedule_hrtimeout_range 讓出 CPU,主動進入睡眠狀態
//file: kernel/hrtimer.c
int __sched schedule_hrtimeout_range(ktime_t *expires,
unsigned long delta, const enum hrtimer_mode mode)
{
return schedule_hrtimeout_range_clock(
expires, delta, mode, CLOCK_MONOTONIC);
}
int __sched schedule_hrtimeout_range_clock()
{
schedule();
}
在 schedule 中選擇下一個進程調度
//file: kernel/sched/core.c
static void __sched __schedule(void)
{
next = pick_next_task(rq);
context_switch(rq, prev, next);
}
五、數據來啦
在前面 epoll_ctl 執行的時候,內核為每一個 socket 上都添加了一個等待隊列項。在 epoll_wait 運行完的時候,又在 event poll 對象上添加了等待隊列元素。在討論數據開始接收之前,我們把這些隊列項的內容再稍微總結一下。
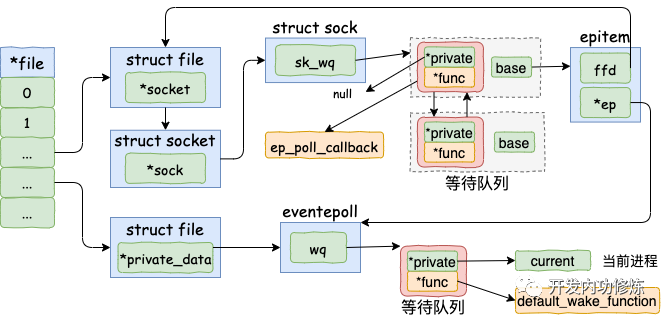
socket-》sock-》sk_data_ready 設置的就緒處理函數是 sock_def_readable
在 socket 的等待隊列項中,其回調函數是 ep_poll_callback。另外其 private 沒有用了,指向的是空指針 null。
在 eventpoll 的等待隊列項中,回調函數是 default_wake_function。其 private 指向的是等待該事件的用戶進程。
在這一小節里,我們將看到軟中斷是怎么樣在數據處理完之后依次進入各個回調函數,最后通知到用戶進程的。
5.1 接收數據到任務隊列
關于軟中斷是怎么處理網絡幀,為了避免篇幅過于臃腫,這里不再介紹。感興趣的可以看文章 《圖解Linux網絡包接收過程》。我們今天直接從 tcp 協議棧的處理入口函數 tcp_v4_rcv 開始說起。
// file: net/ipv4/tcp_ipv4.c
int tcp_v4_rcv(struct sk_buff *skb)
{
th = tcp_hdr(skb); //獲取tcp header
iph = ip_hdr(skb); //獲取ip header
//根據數據包 header 中的 ip、端口信息查找到對應的socket
sk = __inet_lookup_skb(&tcp_hashinfo, skb, th-》source, th-》dest);
//socket 未被用戶鎖定
if (!sock_owned_by_user(sk)) {
{
if (!tcp_prequeue(sk, skb))
ret = tcp_v4_do_rcv(sk, skb);
}
}
}
在 tcp_v4_rcv 中首先根據收到的網絡包的 header 里的 source 和 dest 信息來在本機上查詢對應的 socket。找到以后,我們直接進入接收的主體函數 tcp_v4_do_rcv 來看。
//file: net/ipv4/tcp_ipv4.c
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
if (sk-》sk_state == TCP_ESTABLISHED) {
//執行連接狀態下的數據處理
if (tcp_rcv_established(sk, skb, tcp_hdr(skb), skb-》len)) {
rsk = sk;
goto reset;
}
return 0;
}
//其它非 ESTABLISH 狀態的數據包處理
}
我們假設處理的是 ESTABLISH 狀態下的包,這樣就又進入 tcp_rcv_established 函數中進行處理。
//file: net/ipv4/tcp_input.c
int tcp_rcv_established(struct sock *sk, struct sk_buff *skb,
const struct tcphdr *th, unsigned int len)
{
//接收數據到隊列中
eaten = tcp_queue_rcv(sk, skb, tcp_header_len,
&fragstolen);
//數據 ready,喚醒 socket 上阻塞掉的進程
sk-》sk_data_ready(sk, 0);
在 tcp_rcv_established 中通過調用 tcp_queue_rcv 函數中完成了將接收數據放到 socket 的接收隊列上。
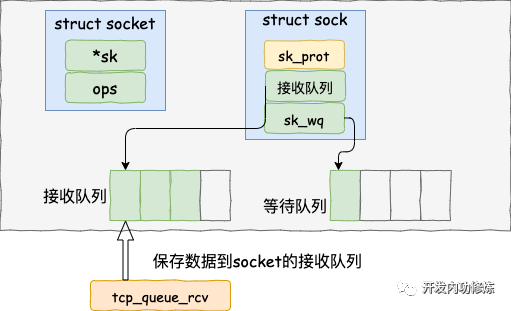
如下源碼所示
//file: net/ipv4/tcp_input.c
static int __must_check tcp_queue_rcv(struct sock *sk, struct sk_buff *skb, int hdrlen,
bool *fragstolen)
{
//把接收到的數據放到 socket 的接收隊列的尾部
if (!eaten) {
__skb_queue_tail(&sk-》sk_receive_queue, skb);
skb_set_owner_r(skb, sk);
}
return eaten;
}
5.2 查找就緒回調函數
調用 tcp_queue_rcv 接收完成之后,接著再調用 sk_data_ready 來喚醒在 socket上等待的用戶進程。這又是一個函數指針。回想上面第一節我們在 accept 函數創建 socket 流程里提到的 sock_init_data 函數,在這個函數里已經把 sk_data_ready 設置成 sock_def_readable 函數了。它是默認的數據就緒處理函數。
當 socket 上數據就緒時候,內核將以 sock_def_readable 這個函數為入口,找到 epoll_ctl 添加 socket 時在其上設置的回調函數 ep_poll_callback。
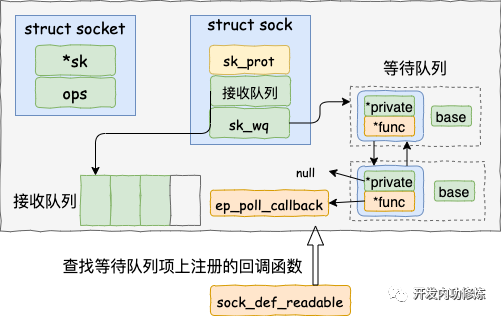
我們來詳細看下細節:
//file: net/core/sock.c
static void sock_def_readable(struct sock *sk, int len)
{
struct socket_wq *wq;
rcu_read_lock();
wq = rcu_dereference(sk-》sk_wq);
//這個名字起的不好,并不是有阻塞的進程,
//而是判斷等待隊列不為空
if (wq_has_sleeper(wq))
//執行等待隊列項上的回調函數
wake_up_interruptible_sync_poll(&wq-》wait, POLLIN | POLLPRI |
POLLRDNORM | POLLRDBAND);
sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_IN);
rcu_read_unlock();
}
這里的函數名其實都有迷惑人的地方。
wq_has_sleeper,對于簡單的 recvfrom 系統調用來說,確實是判斷是否有進程阻塞。但是對于 epoll 下的 socket 只是判斷等待隊列不為空,不一定有進程阻塞的。
wake_up_interruptible_sync_poll,只是會進入到 socket 等待隊列項上設置的回調函數,并不一定有喚醒進程的操作。
那接下來就是我們重點看 wake_up_interruptible_sync_poll 。
我們看一下內核是怎么找到等待隊列項里注冊的回調函數的。
//file: include/linux/wait.h
#define wake_up_interruptible_sync_poll(x, m)
__wake_up_sync_key((x), TASK_INTERRUPTIBLE, 1, (void *) (m))
//file: kernel/sched/core.c
void __wake_up_sync_key(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, void *key)
{
__wake_up_common(q, mode, nr_exclusive, wake_flags, key);
}
接著進入 __wake_up_common
static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, int wake_flags, void *key)
{
wait_queue_t *curr, *next;
list_for_each_entry_safe(curr, next, &q-》task_list, task_list) {
unsigned flags = curr-》flags;
if (curr-》func(curr, mode, wake_flags, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}
在 __wake_up_common 中,選出等待隊列里注冊某個元素 curr, 回調其 curr-》func。回憶我們 ep_insert 調用的時候,把這個 func 設置成 ep_poll_callback 了。
5.3 執行 socket 就緒回調函數
在上一小節找到了 socket 等待隊列項里注冊的函數 ep_poll_callback,軟中斷接著就會調用它。
//file: fs/eventpoll.c
static int ep_poll_callback(wait_queue_t *wait, unsigned mode, int sync, void *key)
{
//獲取 wait 對應的 epitem
struct epitem *epi = ep_item_from_wait(wait);
//獲取 epitem 對應的 eventpoll 結構體
struct eventpoll *ep = epi-》ep;
//1. 將當前epitem 添加到 eventpoll 的就緒隊列中
list_add_tail(&epi-》rdllink, &ep-》rdllist);
//2. 查看 eventpoll 的等待隊列上是否有在等待
if (waitqueue_active(&ep-》wq))
wake_up_locked(&ep-》wq);
在 ep_poll_callback 根據等待任務隊列項上的額外的 base 指針可以找到 epitem, 進而也可以找到 eventpoll對象。
首先它做的第一件事就是把自己的 epitem 添加到 epoll 的就緒隊列中。
接著它又會查看 eventpoll 對象上的等待隊列里是否有等待項(epoll_wait 執行的時候會設置)。
如果沒執行軟中斷的事情就做完了。如果有等待項,那就查找到等待項里設置的回調函數。
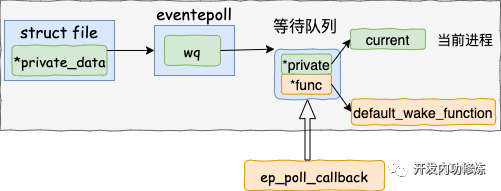
調用 wake_up_locked() =》 __wake_up_locked() =》 __wake_up_common。
static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, int wake_flags, void *key)
{
wait_queue_t *curr, *next;
list_for_each_entry_safe(curr, next, &q-》task_list, task_list) {
unsigned flags = curr-》flags;
if (curr-》func(curr, mode, wake_flags, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}
在 __wake_up_common里, 調用 curr-》func。這里的 func 是在 epoll_wait 是傳入的 default_wake_function 函數。
5.4 執行 epoll 就緒通知
在default_wake_function 中找到等待隊列項里的進程描述符,然后喚醒之。
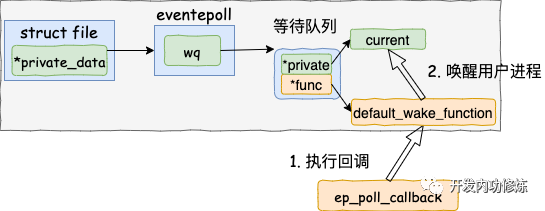
源代碼如下:
//file:kernel/sched/core.c
int default_wake_function(wait_queue_t *curr, unsigned mode, int wake_flags,
void *key)
{
return try_to_wake_up(curr-》private, mode, wake_flags);
}
等待隊列項 curr-》private 指針是在 epoll 對象上等待而被阻塞掉的進程。
將epoll_wait進程推入可運行隊列,等待內核重新調度進程。然后epoll_wait對應的這個進程重新運行后,就從 schedule 恢復
當進程醒來后,繼續從 epoll_wait 時暫停的代碼繼續執行。把 rdlist 中就緒的事件返回給用戶進程
//file: fs/eventpoll.c
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
__remove_wait_queue(&ep-》wq, &wait);
set_current_state(TASK_RUNNING);
}
check_events:
//返回就緒事件給用戶進程
ep_send_events(ep, events, maxevents))
}
從用戶角度來看,epoll_wait 只是多等了一會兒而已,但執行流程還是順序的。
總結
我們來用一幅圖總結一下 epoll 的整個工作路程。
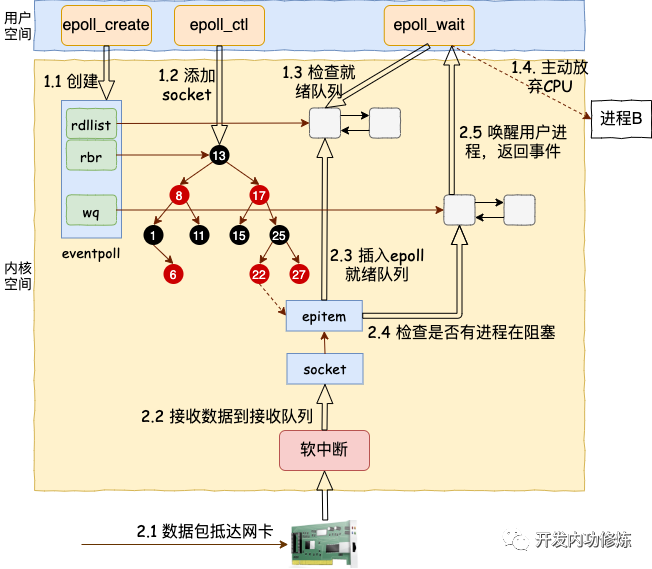
其中軟中斷回調的時候回調函數也整理一下:
sock_def_readable:sock 對象初始化時設置的=》 ep_poll_callback : epoll_ctl 時添加到 socket 上的=》 default_wake_function: epoll_wait 是設置到 epoll上的
總結下,epoll 相關的函數里內核運行環境分兩部分:
用戶進程內核態。進行調用 epoll_wait 等函數時會將進程陷入內核態來執行。這部分代碼負責查看接收隊列,以及負責把當前進程阻塞掉,讓出 CPU。
硬軟中斷上下文。在這些組件中,將包從網卡接收過來進行處理,然后放到 socket 的接收隊列。對于 epoll 來說,再找到 socket 關聯的 epitem,并把它添加到 epoll 對象的就緒鏈表中。這個時候再捎帶檢查一下 epoll 上是否有被阻塞的進程,如果有喚醒之。
為了介紹到每個細節,本文涉及到的流程比較多,把阻塞都介紹進來了。
但其實在實踐中,只要活兒足夠的多,epoll_wait 根本都不會讓進程阻塞。用戶進程會一直干活,一直干活,直到 epoll_wait 里實在沒活兒可干的時候才主動讓出 CPU。這就是 epoll 高效的地方所在!
包括本文在內,飛哥總共用三篇文章分析了一件事情,一個網絡包是如何從網卡達到你的用戶進程里的。另外兩篇如下:
圖解 | Linux 網絡包接收過程
圖解 | 深入理解高性能網絡開發路上的絆腳石 - 同步阻塞網絡 IO
恭喜你沒被內核源碼勸退,一直能堅持到了現在。趕快給先自己鼓個掌,晚飯去加個雞腿!
當然網絡編程剩下還有一些概念我們沒有講到,比如 Reactor 和 Proactor 等。不過相對內核來講,這些用戶層的技術相對就很簡單了。這些只是在討論當多進程一起配合工作時誰負責查看 IO 事件、誰該負責計算、誰負責發送和接收,僅僅是用戶進程的不同分工模式罷了。
原文標題:深入揭秘 epoll 是如何實現 IO 多路復用的!
文章出處:【微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
Linux
+關注
關注
87文章
11336瀏覽量
210101 -
進程
+關注
關注
0文章
204瀏覽量
13974
原文標題:深入揭秘 epoll 是如何實現 IO 多路復用的!
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
CMOS開關和多路復用器中的Ron調制;它是什么及如何預測它對信號失真的影響

Linux--IO多路復用(select,poll,epoll)
什么是多路復用器?它有哪些作用和應用?
頻分多路復用和時分多路復用的區別有哪些
多路復用技術主要有幾種類型?它們各有什么特點?
頻分多路復用的原理 頻分多路復用方式的分類





 工商網監
工商網監
評論