") 詳解多任務學習的方法與現(xiàn)實
詳解多任務學習的方法與現(xiàn)實
大家在做模型的時候,往往關注一個特定指標的優(yōu)化,如做點擊率模型,就優(yōu)化AUC,做二分類模型,就優(yōu)化f-score。然而,這樣忽視了模型通過學習其他任務所能帶來的信息增益和效果上的提升。通過在不同的任務中共享向量表達,我們能夠讓模型在各個任務上的泛化效果大大提升。這個方法就是我們今天要談論的主題-多任務學習(MTL)。
所以如何判定是不是多任務學習呢?不需要看模型結構全貌,只需要看下loss函數(shù)即可,如果loss包含很多項,每一項都是不同目標,這個模型就是在多任務學習了。有時,雖然你的模型僅僅是優(yōu)化一個目標,同樣可以通過多任務學習,提升該模型的泛化效果。比如點擊率模型,我們可以通過添加轉化樣本,構建輔助loss(預估轉化率),從而提升點擊率模型的泛化性。
為什么多任務學習會有效?舉個例子,一個模型已經(jīng)學會了區(qū)分顏色,如果直接把這個模型用于蔬菜和肉類的分類任務呢?模型很容易學到綠色的是蔬菜,其他更大概率是肉。正則化算不算多任務?正則化的優(yōu)化的loss不僅有本身的回歸/分類產(chǎn)生的loss,還有l(wèi)1/l2產(chǎn)生的loss,因為我們認為“正確且不過擬合”的模型的參數(shù)應該稀疏,且不易過大,要把這種假設注入到模型中去學習,就產(chǎn)生了正則化項,本質也是一個額外的任務。
MTL兩個方法
第一種是hard parameter sharing,如下圖所示:
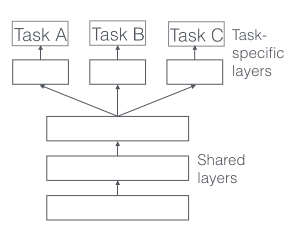
比較簡單,前幾層dnn為各個任務共享,后面分離出不同任務的layers。這種方法有效降低了過擬合的風險: 模型同時學習的任務數(shù)越多,模型在共享層就要學到一個通用的嵌入式表達使得每個任務都表現(xiàn)較好,從而降低過擬合的風險。
第二種是soft parameter sharing,如下圖所示:
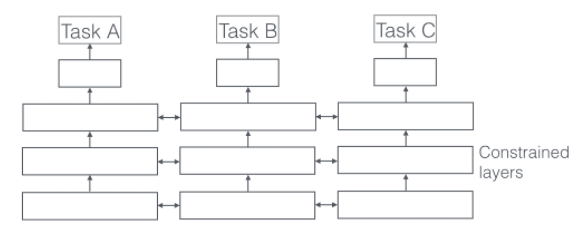
在這種方法下,每個任務都有自己的模型,有自己的參數(shù),但是對不同模型之間的參數(shù)是有限制的,不同模型的參數(shù)之間必須相似,由此會有個distance描述參數(shù)之間的相似度,會作為額外的任務加入到模型的學習中,類似正則化項。
多任務學習能提效,主要是由于以下幾點原因:
隱式數(shù)據(jù)增強:每個任務都有自己的樣本,使用多任務學習的話,模型的樣本量會提升很多。而且數(shù)據(jù)都會有噪聲,如果單學A任務,模型會把A數(shù)據(jù)的噪聲也學進去,如果是多任務學習,模型因為要求B任務也要學習好,就會忽視掉A任務的噪聲,同理,模型學A的時候也會忽視掉B任務的噪聲,因此多任務學習可以學到一個更精確的嵌入表達。
注意力聚焦:如果任務的數(shù)據(jù)噪聲非常多,數(shù)據(jù)很少且非常高維,模型對相關特征和非相關特征就無法區(qū)分。多任務學習可以幫助模型聚焦到有用的特征上,因為不同任務都會反應特征與任務的相關性。
特征信息竊取:有些特征在任務B中容易學習,在任務A中較難學習,主要原因是任務A與這些特征的交互更為復雜,且對于任務A來說其他特征可能會阻礙部分特征的學習,因此通過多任務學習,模型可以高效的學習每一個重要的特征。
表達偏差:MTL使模型學到所有任務都偏好的向量表示。這也將有助于該模型推廣到未來的新任務,因為假設空間對于足夠多的訓練任務表現(xiàn)良好,對于學習新任務也表現(xiàn)良好。
正則化:對于一個任務而言,其他任務的學習都會對該任務有正則化效果。
多任務深度學習模型
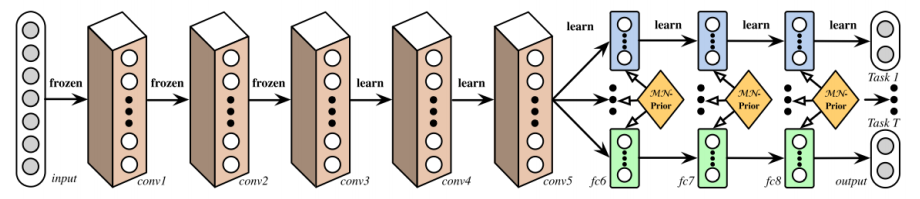
Deep Relationship Networks:從下圖,我們可以看到卷積層前幾層是預訓練好的,后幾層是共享參數(shù)的,用于學習不同任務之間的聯(lián)系,最后獨立的dnn模塊用于學習各個任務。
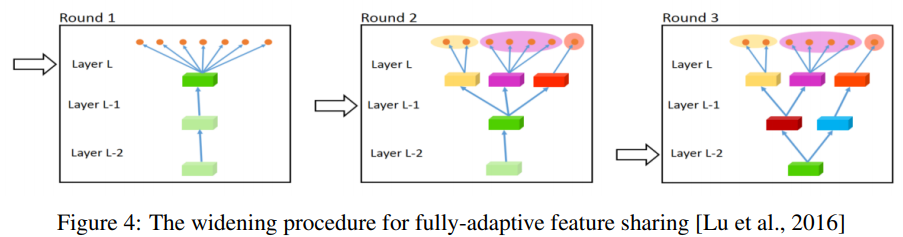
Fully-Adaptive Feature Sharing:從另一個極端開始,下圖是一種自底向上的方法,從一個簡單的網(wǎng)絡開始,并在訓練過程中利用相似任務的分組準則貪婪地動態(tài)擴展網(wǎng)絡。貪婪方法可能無法發(fā)現(xiàn)一個全局最優(yōu)的模型,而且只將每個分支分配給一個任務使得模型無法學習任務之間復雜的交互。
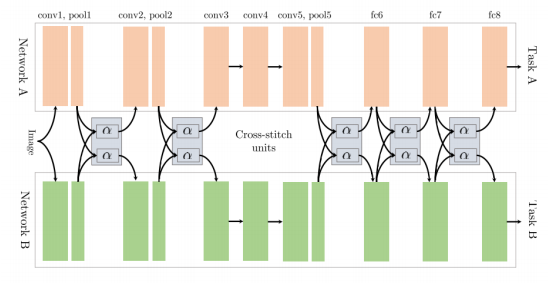
cross-stitch Networks: 如上文中所談到的soft parameter sharing,該模型是兩個完全分離的模型結構,該結構用了cross-stitch單元去讓分離的模型學到不同任務之間的關系,如下圖所示,通過在pooling層和全連接層后分別增加cross-stitch對前面學到的特征表達進行線性融合,再輸出到后面的卷積/全連接模塊。
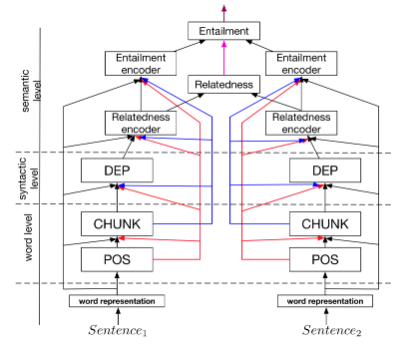
A Joint Many-Task Model:如下圖所示,預定義的層級結構由各個NLP任務組成,低層級的結構通過詞級別的任務學習,如此行分析,組塊標注等。中間層級的結構通過句法分析級別的任務學習,如句法依存。高層級的結構通過語義級別的任務學習。
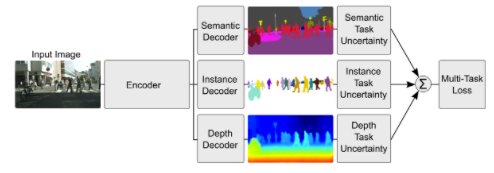
weighting losses with uncertainty:考慮到不同任務之間相關度的不確定性,基于高斯似然最大化的多任務損失函數(shù),調整每個任務在成本函數(shù)中的相對權重。結構如下圖所示,對像素深度回歸、語義和實例分割。
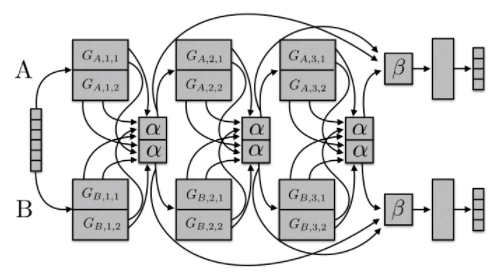
sluice networks: 下圖模型概括了基于深度學習的MTL方法,如硬參數(shù)共享和cross-stitch網(wǎng)絡、塊稀疏正則化方法,以及最近創(chuàng)建任務層次結構的NLP方法。該模型能夠學習到哪些層和子空間應該被共享,以及網(wǎng)絡在哪些層學習了輸入序列的最佳表示。
ESSM: 在電商場景下,轉化是指從點擊到購買。在CVR預估時候,我們往往會遇到兩個問題:樣本偏差和數(shù)據(jù)系數(shù)問題。樣本偏差是指訓練和測試集樣本不同,拿電商舉例,模型用點擊的數(shù)據(jù)來訓練,而預估的卻是整個樣本空間。數(shù)據(jù)稀疏問題就更嚴重了,本身點擊樣本就很少,轉化就更少了,所以可以借鑒多任務學習的思路,引入輔助學習任務,擬合pCTR和pCTCVR(pCTCVR = pCTR * pCVR),如下圖所示:
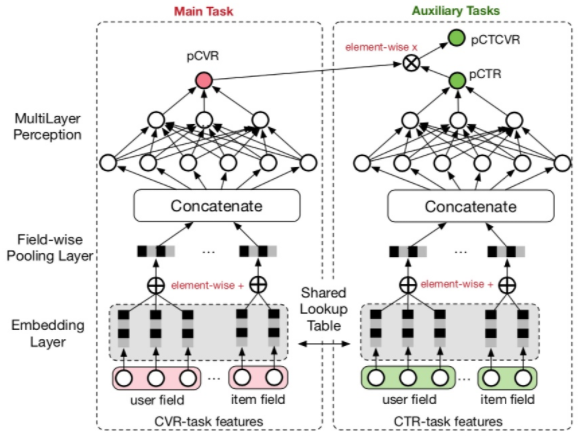
對于pCTR來說,可將有點擊行為的曝光事件作為正樣本,沒有點擊行為的曝光事件作為負樣本
對于pCTCVR來說,可將同時有點擊行為和購買行為的曝光事件作為正樣本,其他作為負樣本
對于pCVR來說,只有曝光沒有點擊的樣本中的梯度也能回傳到main task的網(wǎng)絡中
另外這兩個子網(wǎng)絡的embedding層是共享的,由于CTR任務的訓練樣本量要遠超過CVR任務的訓練樣本量,從而能夠緩解訓練數(shù)據(jù)稀疏性問題。
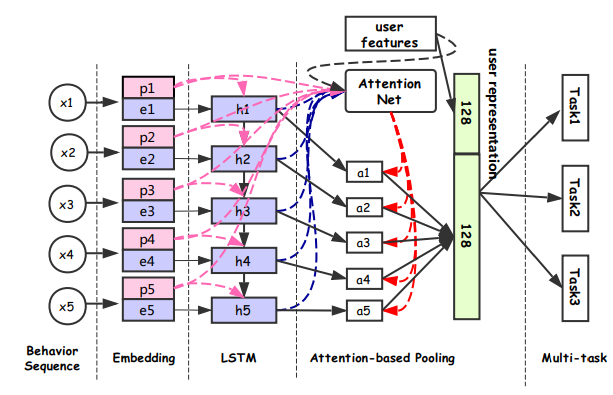
DUPN:模型分為行為序列層、Embedding層、LSTM層、Attention層、下游多任務層(CTR、LTR、時尚達人關注預估、用戶購買力度量)。如下圖所示
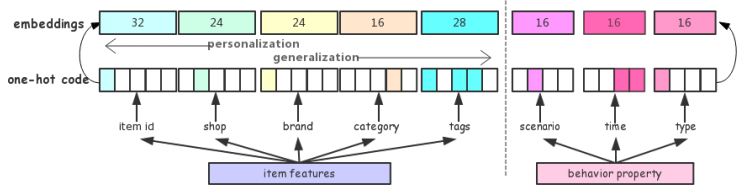

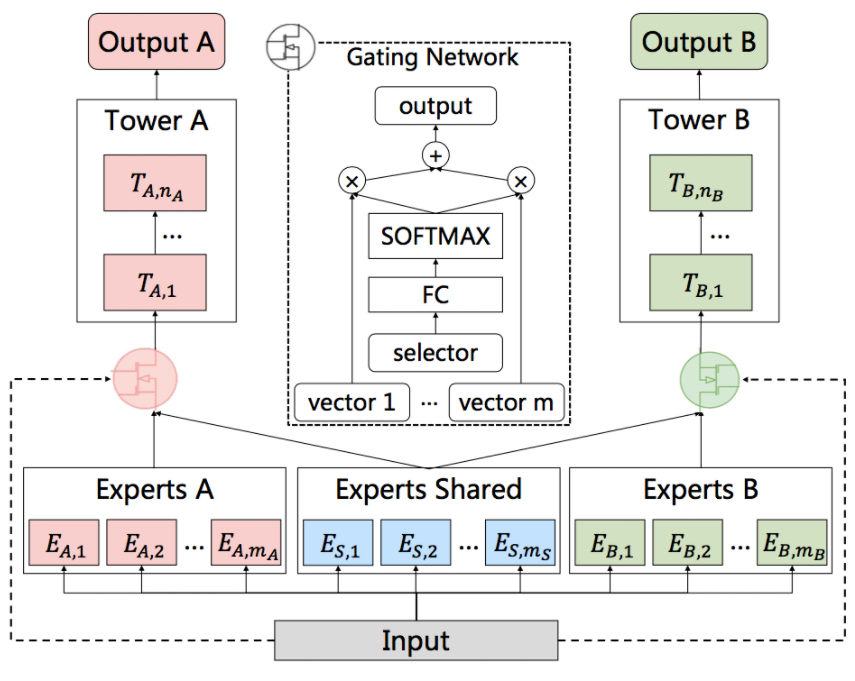
MMOE: 如下圖所示,模型(a)最常見,共享了底層網(wǎng)絡,上面分別接不同任務的全連接層。模型(b)認為不同的專家可以從相同的輸入中提取出不同的特征,由一個Gate(類似) attention結構,把專家提取出的特征篩選出各個task最相關的特征,最后分別接不同任務的全連接層。MMOE的思想就是對于不同任務,需要不同專家提取出的信息,因此每個任務都需要一個獨立的gate。
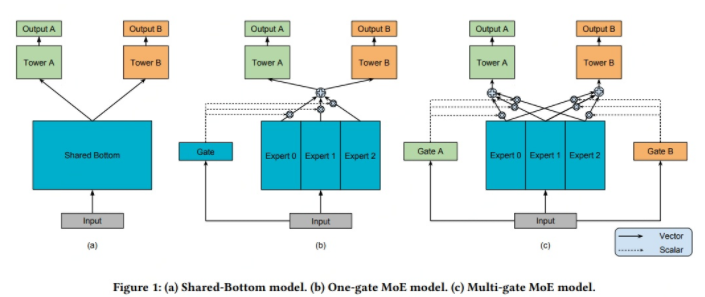
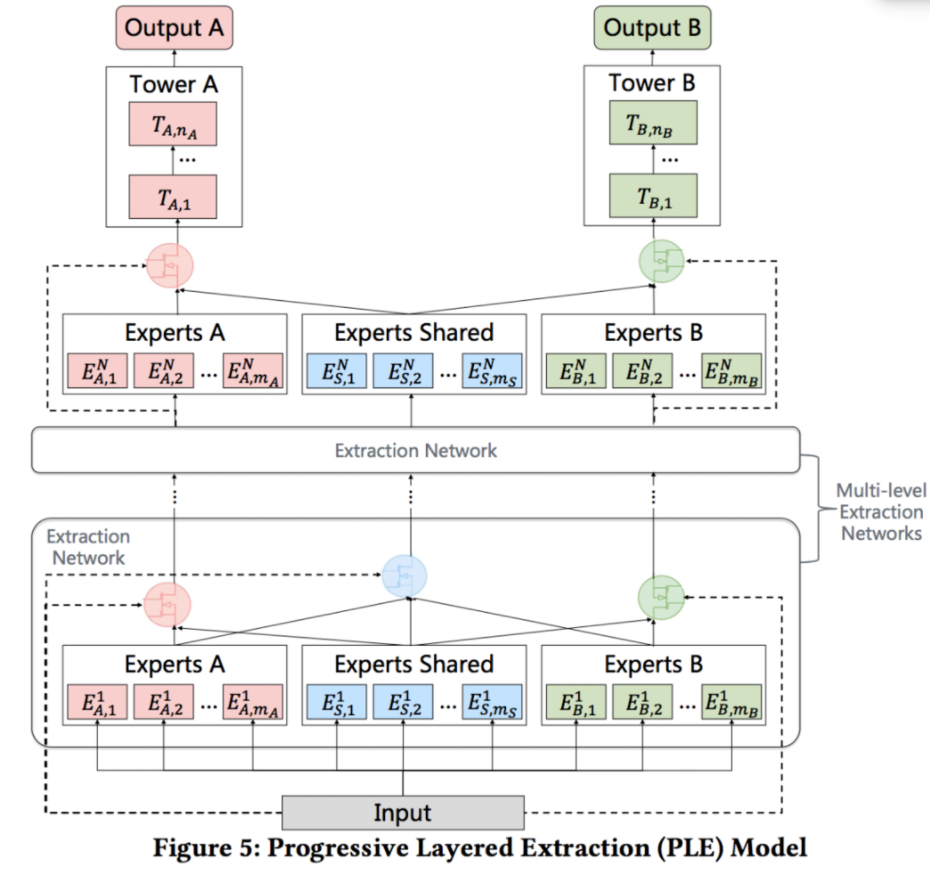
PLE:即使通過MMoE這種方式減輕負遷移現(xiàn)象,蹺蹺板現(xiàn)象仍然是廣泛存在的(蹺蹺板現(xiàn)象指多任務之間相關性不強時,信息共享就會影響模型效果,會出現(xiàn)一個任務泛化性變強,另一個變?nèi)醯默F(xiàn)象)。PLE的本質是MMOE的改進版本,有些expert是任務專屬,有些expert是共享的,如下圖CGC架構,對于任務A而言,通過A的gate把A的expert和共享的expert進行融合,去學習A。
最終PLE結構如下,融合了定制的expert和MMOE,堆疊多層CGC架構,如下所示:
參考文獻
1. An overview of multi-task learning in deep neural networks. Retireved from https://arxiv.org/pdf/1706.05098.pdf
2. Long, M., & Wang, J. (2015)。 Learning Multiple Tasks with Deep Relationship Networks. arXiv Preprint arXiv:1506.02117. Retrieved from http://arxiv.org/abs/1506.02117
3. Lu, Y., Kumar, A., Zhai, S., Cheng, Y., Javidi, T., & Feris, R. (2016)。 Fully-adaptive Feature Sharing in Multi-Task Networks with Applications in Person Attribute Classification. Retrieved from http://arxiv.org/abs/1611.05377
4. Misra, I., Shrivastava, A., Gupta, A., & Hebert, M. (2016)。 Cross-stitch Networks for Multi-task Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR.2016.433
5. Hashimoto, K., Xiong, C., Tsuruoka, Y., & Socher, R. (2016)。 A Joint Many-Task Model: Growing a Neural Network for Multiple NLP Tasks. arXiv Preprint arXiv:1611.01587. Retrieved from http://arxiv.org/abs/1611.01587
6. Yang, Y., & Hospedales, T. (2017)。 Deep Multi-task Representation Learning: A Tensor Factorisation Approach. In ICLR 2017. https://doi.org/10.1002/joe.20070
7. Ruder, S., Bingel, J., Augenstein, I., & S?gaard, A. (2017)。 Sluice networks: Learning what to share between loosely related tasks. Retrieved from http://arxiv.org/abs/1705.08142
8. Entire Space Multi-Task Model: An Effective Approach forEstimating Post-Click Conversion Rate. Retrieved from: https://arxiv.org/pdf/1804.07931.pdf
9. Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-commerce Tasks. Retrieved from: https://arxiv.org/pdf/1805.10727.pdf
編輯:lyn
-
多任務
+關注
關注
0文章
18瀏覽量
9066 -
AUC
+關注
關注
0文章
9瀏覽量
6662 -
深度學習
+關注
關注
73文章
5503瀏覽量
121170
原文標題:一文"看透"多任務學習
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦

機器學習中的數(shù)據(jù)分割方法
深度學習中的時間序列分類方法
深度學習中的無監(jiān)督學習方法綜述
遷移學習的基本概念和實現(xiàn)方法
機器學習算法原理詳解
esp32-c3工程中怎么創(chuàng)建多個freertos任務?
鋰電池充放電測試方法詳解

【大語言模型:原理與工程實踐】核心技術綜述
學習平板電腦主板定制_基于展銳T610/T618平臺解決方案







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論