 為什么ElasticSearch復雜條件查詢比MySQL好?
為什么ElasticSearch復雜條件查詢比MySQL好?
熟悉 MySQL 的同學一定都知道,MySQL 對于復雜條件查詢的支持并不好。MySQL 最多使用一個條件涉及的索引來過濾,然后剩余的條件只能在遍歷行過程中進行內存過濾。
上述這種處理復雜條件查詢的方式因為只能通過一個索引進行過濾,所以需要進行大量的 I/O 操作來讀取行數據,并消耗 CPU 進行內存過濾,導致查詢性能的下降。
而 ElasticSearch 因其特性,十分適合進行復雜條件查詢,是業界主流的復雜條件查詢場景解決方案,廣泛應用于訂單和日志查詢等場景。
下面我們就一起來看一下,為什么 ElasticSearch 適合進行復雜條件查詢。
ElasticSearch 簡介
Elasticsearch 是開源的實時分布式搜索分析引擎,內部使用 Lucene 做索引與搜索。它提供"準實時搜索"能力,并且能動態集群規模,彈性擴容。
Elasticsearch 使用 Lucene 作為其全文搜索引擎,用于處理純文本的數據,但 Lucene 只是一個庫,提供建立索引、執行搜索等接口,但不包含分布式服務,這些正是 Elasticsearch 做的。
下面,我們來介紹一下 ElasticSearch 的相關概念。為了便于初學者理解,我們先將 ElasticSearch 中的概念和 MySQL 中的概念大致地進行對應。但是二者在具體細節上還是有很多差異的,大家深入了解 ElasticSearch 就會將二者區分清楚,不能強行對比等同。
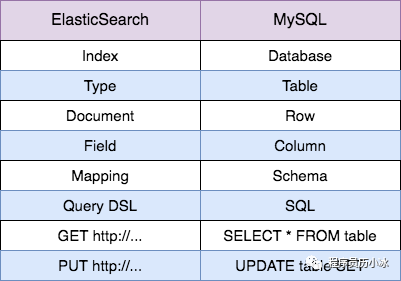
ElasticSearch 中的索引 Index 類似于 MySQL 中的數據庫 Database;
ElasticSearch 中的類型 Type 類似于 MySQL 中的表 Table;需要注意,這個概念在 7.x 版本中被完全刪除,而且概念上和 Table 也有較大差異;
ElasticSearch 中的文檔 Document 類似于 MySQL 中的數據行 Row,每個文檔由多個字段 Filed 組成,這個Filed 就類似于 MySQL 的 Column;
ElasticSearch 中的映射 Mapping 是對索引庫中的索引字段及其數據類型進行定義,類似于關系型數據庫中的表結構 Schema;
ElasticSearch 使用自己的領域語言 Query DSL 來進行增刪改查,而 MySQL 使用 SQL 語言進行上訴操作。
ElasticSearch 還有一系列有關其分布式特性的概念,我們這里就暫不介紹了,等后續學習到其分布式特性時在進行介紹。
倒排索引
MySQL 有 B+ 樹索引,而 ElasticSearch 則是倒排索引 (Inverted Index),它通過倒排索引來實現比 MySQL 更快的過濾和復雜條件的查詢,此外,全文搜索功能也是依賴倒排索引才能實現。下面,我們就具體來看一下何為倒排索引。
倒排索引按照維基百科的描述,是存儲文檔內容到文檔位置映射關系的數據庫索引結構。不過只看定義,我是有點迷惑,這不是和 MySQL 的非主鍵索引類似嘛,為什么要叫它“倒排”呢?這個問題我目前也為搞清楚,可能要等到后續了解了其具體實現才能理解。
我們還是以書籍檢索為例,假設有以下數據,每一行就是一個 Document,每個 Document 由 id、ISBN 號,作者名稱和評分組成。
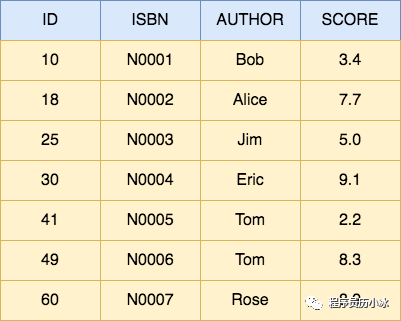
給上述數據按照 ISBN 和 Author 建立的倒排索引如下所示。倒排索引是每個字段分開建立的,相互獨立。有兩個專門的術語,分別是索引 Term 和倒排表 Posting List。字段的值就是 Term,比如 N0007,而 Term 對應的文檔 ID 的列表就是 Posting List,對應圖中紅色的部分。

一般 Term 都是按照順序排序的,比如 Author 名稱就是按照字母序進行了排序,排序之后,當我們搜索某一個 Term 時,就不需要從頭遍歷,而是采用二分查找。一系列排序后的 Term 就組成了索引表 Term Dictionary。
但是 Term Dictionary 往往很大,無法完整放入內存,這是為了更快的查詢,還需要再給它創建索引,也就是 Term Index 。
ElasticSearch 使用 Burst-Trie 結構來實現 Term Index,它是一種前綴樹 Trie 的一種變種,它主要是將后綴進行了壓縮,降低了Trie的高度,從而獲取更好查詢性能。
Term Index 并不需要像 MySQL 的索引一樣,包含所有的 Term,而是包含的是這些 Term 的前綴。它就類似于字典的查詢目錄,可以進行快速定位到 Term Dictionary 的某一位置,然后再從這個位置向后查詢。
綜上, Alice,Alf,Arlan,Bob,Tom 等詞的倒排索引如下所示。綠色部分是 Term Index,藍色部分是 Term Dictionary,紅色部分是 Posting List。
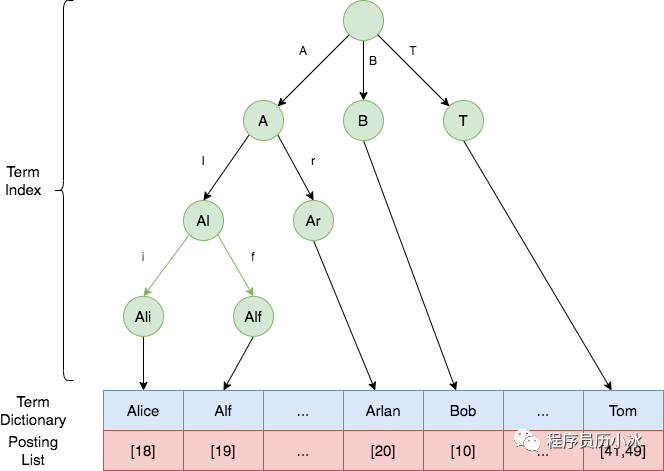
一般來說,Term Index 都是全部緩存在內存中,查詢時,先通過其快速定位到 Term Dictionary 對應的大致范圍,然后再進行磁盤讀取查找對應的 Term,這樣就大大減少了磁盤 I/O 的次數。
聯合索引查詢
了解了 ElasticSearch 的倒排索引后,我們再來看看其如何處理復雜的聯合索引查詢。比如上述書籍例子中,我們需要查詢評分等于2.2并且作者名稱叫 Tom 的書籍。
理論上,我們只需要分別按照 Score 和 Author 字段的倒排索引進行查詢,獲取響應的 Posting List,再將其做交集合并即可。
這里又要吐槽一下 MySQL,它是不支持這個合并操作的,它只能按照一個字段的索引進行查詢,然后根據另外一個字段的條件做內存過濾。順便說一下,MySQL 的 join 功能也弱爆了,感興趣的同學可以了解一下。
而 ElasticSearch 則支持使用跳表 Skip List和 Bitset 的方式將數據集進行合并。
使用 Skip List 結構,同時遍歷 Score 和 Author 查詢出來的 Posting List,利用其 Skip List 結構,相互跳躍對比,得出合集。
使用 Bitset 結構,對 Score 和 Author 查詢出來的 Posting List 的值計算出各自的 Bitset,然后進行 AND 操作。
跳表合并策略
ElasticSearch 在存儲 Posting List 數據時,就保存了對應的多級跳表結構響應的數據,這也體現了其空間換時間的基本思想。
這里先介紹一下跳表的基本概念,它其實是一種可以進行二分查找的有序鏈表。跳表在原有的有序鏈表上面增加了多級索引,通過索引來實現快速查找。首先在最高級索引上查找最后一個小于當前查找元素的位置,然后再跳到次高級索引繼續查找,直到跳到最底層為止,通過這種方式,加快了查詢的速度。
比如,按照 Score 查出來的 Posting List 為 [2,3,4,5,7,9,10,11],按照 Author 查出來的結果為 [3,8,9,12,13],則二者的跳表結構如下圖所示。
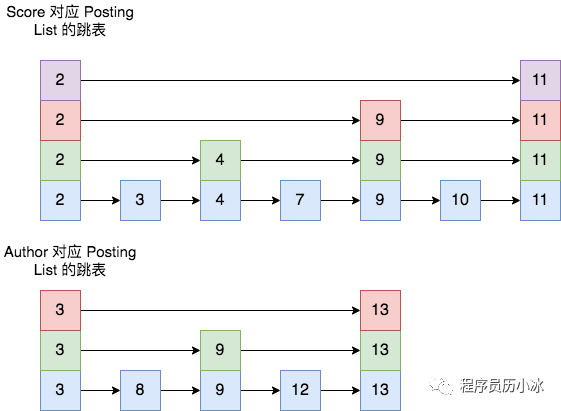
具體合并過程則是先選最短的 posting list,也就是 Author 的結果集,從其最小的一個 id 開始,將其作為當前最大值。然后依次剩余 posting list 中查找大于或等于該值的位置。
比如上述結果集中,先去 Score 結果集中查找 3,找到后,就表明 3是二者的合集元素之一;然后再重新開啟一輪,選取 Author 結果集中 3 的下一個值 8 ,去 Score 結果集查詢 8,發現了大于等于 8 的最小的值是 9 ,所以不可能有共同的值 8,然后再去 Author 結果集查找 9 ,發現其大于等于 9 的最小值是 12,所以再去 Score 結果集中查找大于等于 12的值,發現并不存在;最終得出二者的合集就只有 [3]。
在查詢過程中,每個 posting list 都可以根據當前 id 通過 skip list 快速跳過不符合的 id 值,加速整個合并取交集的過程。
ElasticSearch 對于較長的 posting list 也會使用 Frame Of Reference 進行壓縮編碼,減少了磁盤占用,減少了索引尺寸。有關具體存儲結構的實現我們后續再進行細聊。
Bitset 合并策略
ElasticSearch 除了使用 skipList 來進行數據磁盤讀取時的合并操作外,還會將一些查詢條件對應的結果集 posting list 進行內存緩存,也就是所謂的 Filter Cache,為了后續再次復用。
為了減少內存緩存所消耗的內存空間大小,ElasticSearch 沒有使用單純的數組和 bitset 來存儲 posting list,而是使用要壓縮效率更高的 Roaring Bitmap。
我們可以先來講一下單純數組或 bitset 數據結構為什么并不使用。比如如下一道較為常見的面試題目:
給定含有 40 億個不重復的位于 [0, 2^32 - 1] 區間內的整數的集合,如何快速判定某個數是否在該集合內?
如果我們要使用 unsigned long 數組來存儲它的話,也就需要消耗 40億 * 32 位 = 160 Byte,大致是 16000 MB。
如果要使用位圖 Bitset 來存儲的話,即某個數位于原集合內,就將它對應的位圖內的比特置為1,否則保持為0。這樣只需要消耗 2 ^ 32 位 = 512 MB,這可只有原來的 3.2 % 左右。
但是,Bitset 也有其缺陷,也就是稀疏存儲的問題,比如上述集合并不是 40億,而是只有2、3個,那么 Bitset 中只有少數幾位是1,其他位都是 0,但是它仍然占用了 512 MB。
而 RoaringBitmap 就是為了解決稀疏存儲的問題。下圖就是 RoaringBitmap 的基本原理示意圖。
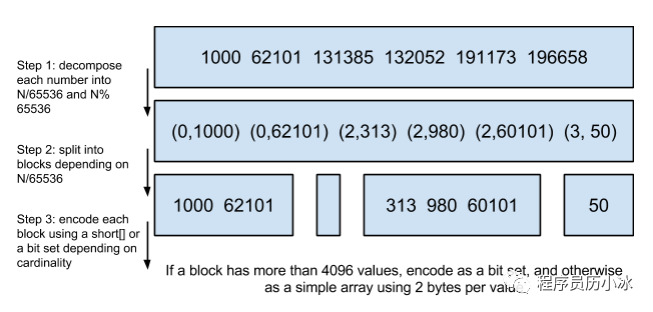
首先,如上圖所示,計算出32位無符號整數和 65536 的除數和余數。其含義表示,將32位無符號整數按照高16位分桶,即最多可能有2^16=65536個桶,術語懲治為 container。存儲數據時,按照數據的高16位找到 container(找不到就會新建一個),再將低16位放入container中。也就是說,一個 RoaringBitmap 就是很多container的集合。
然后 container 內具體的存儲結構要根據存入其內數據的基數來決定。
基數小于 2 ^ 12 次方即 4096時,使用unsigned short類型的有序數組來存儲,最大消耗空間就是 8 KB;
基數大于 4096 時,則使用大小為 2 ^ 16 次方的普通 bitset 來存儲,固定消耗 8 KB。當然,有些時候也會對 bitset 進行行程長度編碼(RLE)壓縮,進一步減少空間占用。
ElasticSearch 就是使用 Roaring Bitmap 來緩存不同條件查詢出來的 posting list,然后再進行與操作計算出最終結果集。
后記
至此,我們也算了解了 ElasticSearch 為什么比 MySQL 更適合復雜條件查詢,但是有好就有弊,因為為了查詢做了這么多的準備工作,ElasticSearch 的插入速度就會慢于 MySQL,而且數據存入 ES 后并不是立馬就能檢索到。
原文標題:為什么 ElasticSearch 比 MySQL 更適合復雜條件搜索
文章出處:【微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
開源
+關注
關注
3文章
3396瀏覽量
42638 -
MySQL
+關注
關注
1文章
829瀏覽量
26669
原文標題:為什么 ElasticSearch 比 MySQL 更適合復雜條件搜索
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
適用于MySQL的dbExpress驅動程序:提供對MySQL的快速訪問
使用插件將Excel連接到MySQL/MariaDB
如何在Linux環境下高效安裝部署和配置Elasticsearch
MySQL數據庫的安裝
在華為云上通過 Docker 容器部署 Elasticsearch 并進行性能評測
云服務器 Flexus X 實例 MySQL 應用加速測試
數據庫數據恢復—Mysql數據庫表記錄丟失的數據恢復流程

數據庫數據恢復—MYSQL數據庫ibdata1文件損壞的數據恢復案例
MySQL還能跟上PostgreSQL的步伐嗎

Elasticsearch 再次開源


一文了解MySQL索引機制

分庫分表后復雜查詢的應對之道:基于DTS實時性ES寬表構建技術實踐
MySQL的整體邏輯架構






 工商網監
工商網監
評論