 如何透過數字直剖本質評估AI芯片的真實性能?
如何透過數字直剖本質評估AI芯片的真實性能?
特斯拉 Hardware 3.0 的效率之謎
特斯拉在其推出的 Hardware 3.0 自動駕駛平臺中,采用自研芯片替代了Nvidia Drive PX2,其理論算力直線提升了 3 倍,而以 MAPS 方式來評估,其真實 AI 性能更是驚人的提升了 21 倍。具體而言,Hardware 2.0 時每秒只能處理 110 幀圖像,而現在則高達 2300 幀。
那么,Hardware 的效率提升應該如何認識呢?在“算力至上”的今天,如何透過數字直剖本質評估 AI 芯片的真實性能?
算力攀升,為什么卻看不到實用性?
隨著芯片制程技術的演進,摩爾定律的發展卻逐漸進入瓶頸期,這與當下計算 AI 計算需求量爆發式的增長顯得格格不入。追求純算力突破并不可持續,同時算力也并不代表汽車智能芯片“真實性能”,芯片計算效率也同樣需要關注。于是,軟硬結合、算法加持的 AI 芯片接過了跑贏新場景的接力棒。
當前,行業普遍以“TOPS”為單位來評估AI的理論峰值算力。盡管在目前主流的AI芯片性能基準測試( MLPerf )下很多頂級廠商頻繁刷新榜單記錄,但在實際場景下的算力有效利用率卻差強人意。
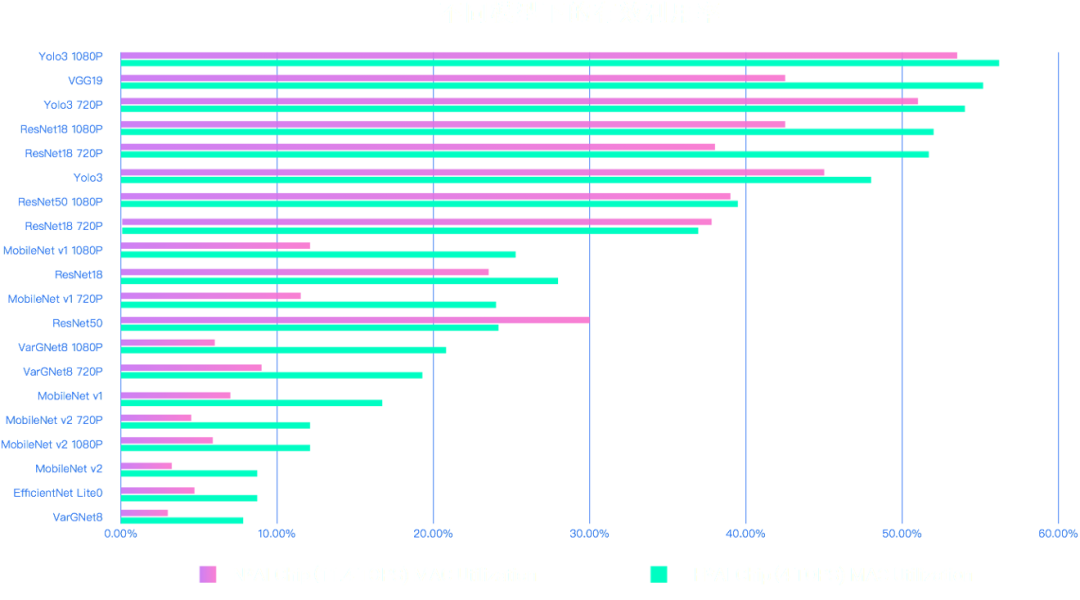
人們逐漸認識到,AI 芯片理論峰值算力并不一定能在實際運行中完全釋放。例如,一款擁有理論峰值算力為 16 TOPS 的芯片,在計算不同模型時甚至會有接近 80% 的差異。此外,在卷積神經網絡任務實測中,從 2014 年到 2019 年,最好的神經網絡計算效率相差了 100 倍,相當于計算效率每 9 個月翻一倍,遠快于每 18 個月翻倍的摩爾定律。因此在模型算法演進速度遠快于芯片性能提升的速度的現在,不僅需要算力更高的芯片,也需要更合理的性能評估方法幫助用戶選擇適合的 AI 芯片。
對這些 AI 時代出現的新變化,以地平線為代表的 AI 芯片企業認為,單純依賴于 PPA 芯片設計指標,很容易陷入算力至上的“誤區”,但算力并不是完全反應芯片性能唯一評估標準。因此,地平線提出了 MAPS(Mean Accuracy-guaranteed Processing Speed)概念和評估方法,以此作為檢驗 AI 性能的真正標準。通俗來說,就是在特定的 AI 應用領域,看芯片處理 AI 任務的速度和精度,即“多快”和“多準”。
MAPS 動態評估芯片真實 AI 性能
隨著 AI 算法的不斷演進,幾乎每 10-14 個月,相同的計算精度計算量可以下降一半。這種提升與算法設計的精妙程度息息相關,但算法的快速演進也對計算架構提出巨大的挑戰,尤其是對傳統通用的并行架構而言,例如亟需高效AI專用處理器的自動駕駛場景。
MAPS 其實是在物理算力的基礎上,通過對大量模型的測試,綜合各個模型的速度(正比與物理算力*實際利用率)和準確率得到的最佳方案的量化結果。它更聚焦于使用戶能夠通過可視化的圖表直觀的感知 AI 芯片真實算力。正如對于汽車來說,馬力(單位: HP)不如百公里加速時間(單位:秒)更真實反映整車動力性能;算力(單位: TOPS)并不反映汽車智能芯片實際性能,而每秒準確識別幀率 MAPS(單位: FPS)才是更真實的性能指標。
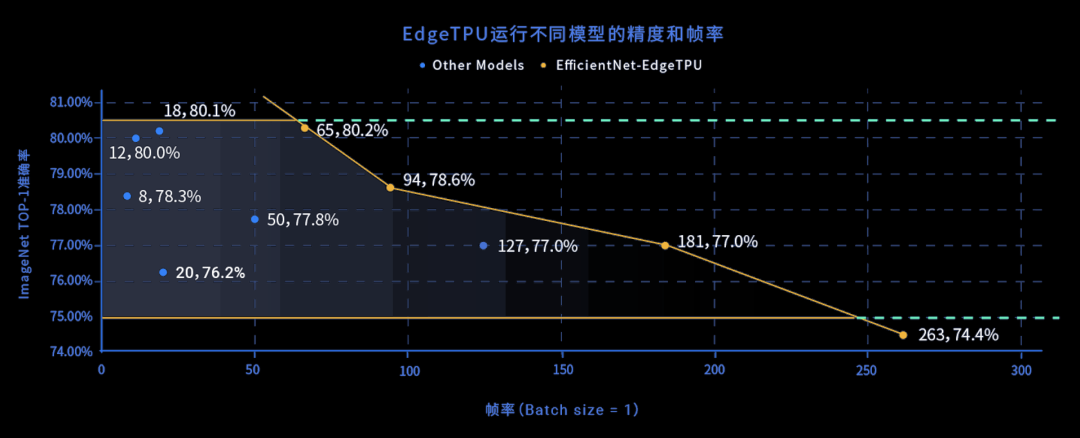
MAPS=最佳模型多邊形面積/(精度上界—精度下界),其中橫軸反應幀率,縱軸反應精度
此外,在自動駕駛中應該如何對速度和精度做取舍呢?現實生活中我們經常遇到一些極端的案例,例如當汽車遭遇小孩子橫穿馬路的突發狀況時,如果自動駕駛識別延時過高,會剎車不及時;如果精度不夠,則會造成無法識別。在很多類似的場景中,我們往往面臨既要“快”,又要兼顧“準”的境況。而在 MAPS 評估方法下,我們可以清晰看到幀率和精度之間的動態關系,這也是其對實際場景的重要價值之一。
更高級別自動駕駛需要多少“FPS”?
軟件定義的汽車的趨勢下,未來汽車正逐步成為四個輪子上的超級計算機。可以清晰預見的是,電動車賣點不是車,而是「智能」,這是一個堪比計算機誕生級別的創新。
特斯拉在 Hardware 3.0 中,采用其自研 AI 芯片 FSD Chip 替代了 Hardware 2.5 中的 Nvidia Drive PX2,算力從 24 TOPS 提升到了 72 TOPS,但運行同樣模型的精度卻驚人的提升了 21 倍。具體而言,Hardware 2.0 時每秒只能處理 110 幀圖像,而現在則高達 2300 幀。除了絕對算力的提升,額外提升則來自于利用率的提升。同時特斯拉也宣布針對 Hardware 3.0 重寫自動駕駛軟件,從而在 2020 年 10 月推出了 FSD beta,這是唯一不受場地限制、大規模測試的自動駕駛方案。
特斯拉革命性技術的重構與 MAPS背后體現的理念有相通之處:提升物理算力(HW 3.0 提升 3 倍)、提升利用率(提升近 2 倍),找到最佳的速度和準確率提升(重寫自動駕駛軟件),使得特斯拉從簡單場景的 NOA 一步步突破到不受限的自動駕駛。而地平線在芯片設計之中一直貫徹 MAPS 背后的技術理念,關注提升物理算力的同時關注利用率的提升,并且不斷把算法發展趨勢,使得軟硬件可以協同共振,發揮最高效能。
為了助力汽車廠商突破“特斯拉困境”,實現高級別自動駕駛的落地。地平線即將推出的征程 5 MAPS 整體跑分高達 3020 FPS,其中 MAPS@COCO (檢測任務COCO MAPS) 跑分可高達 116,而 Nvidia Xavier MAPS@COCO 為 41 FPS (GPU&DLA@32W mode ),如此高的性能將助力車廠加速實現自動駕駛方案的落地。
驅動新基建數字底座,需要有算力也要有效率。自成立以來,地平線便致力于兼備算力與效率的高性能芯片。未來,地平線將推出性能更強大的征程6,其不僅在功耗、面積優化的基礎上,同時在MAPS上繼續提升一個數量級,助力全行業共同努力進一步大幅提升自動駕駛的安全性。
原文標題:不看算力看效率,更高級別的自動駕駛需要多少 “FPS”?
文章出處:【微信公眾號:地平線HorizonRobotics】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
特斯拉
+關注
關注
66文章
6322瀏覽量
126704 -
AI
+關注
關注
87文章
31432瀏覽量
269832 -
自動駕駛
+關注
關注
784文章
13918瀏覽量
166793
原文標題:不看算力看效率,更高級別的自動駕駛需要多少 “FPS”?
文章出處:【微信號:horizonrobotics,微信公眾號:地平線HorizonRobotics】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
2.5D/3D封裝技術升級,拉高AI芯片性能天花板

AI跑分超8000,天璣9400憑實力碾壓一眾旗艦芯片
賽昉聯合國芯推出高性能AI MCU芯片,實現RISC-V+AI新應用

多通道負載測試和性能評估?
如何評估AI大模型的效果
光學透過率測量儀的技術原理和應用場景
3D DRAM內嵌AI芯片,AI計算性能暴增

知存科技助力AI應用落地:WTMDK2101-ZT1評估板實地評測與性能揭秘
risc-v多核芯片在AI方面的應用






 工商網監
工商網監
評論