 PaddleOCR歷史表現回顧
PaddleOCR歷史表現回顧
一、導讀
OCR方向的工程師,一定需要知道這個OCR開源項目:PaddleOCR
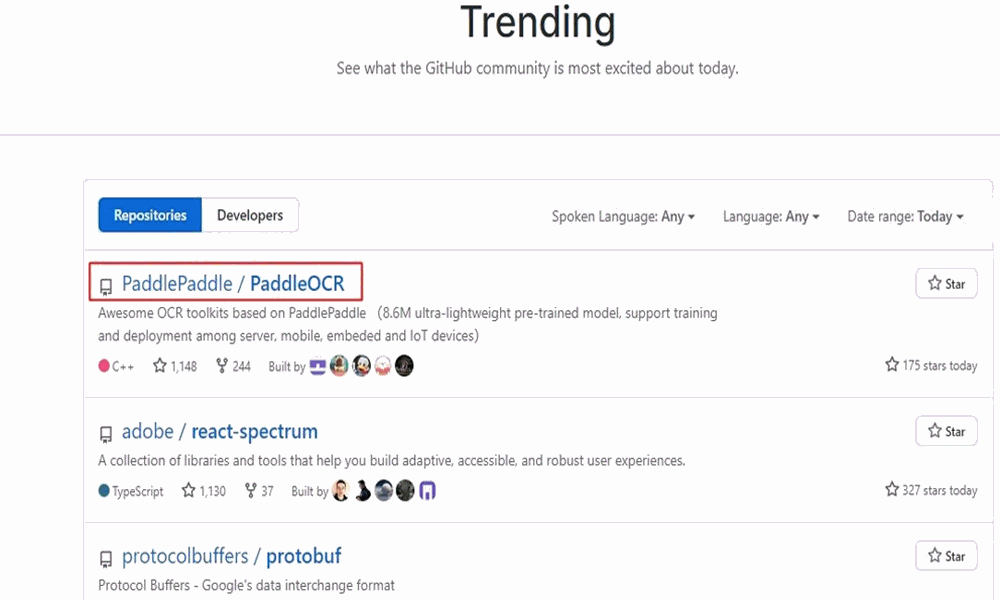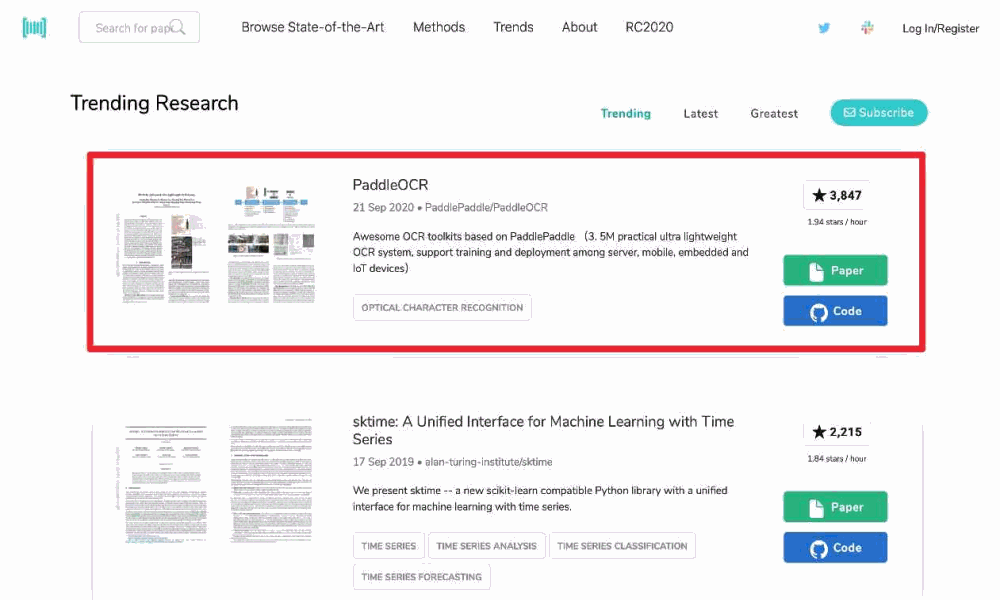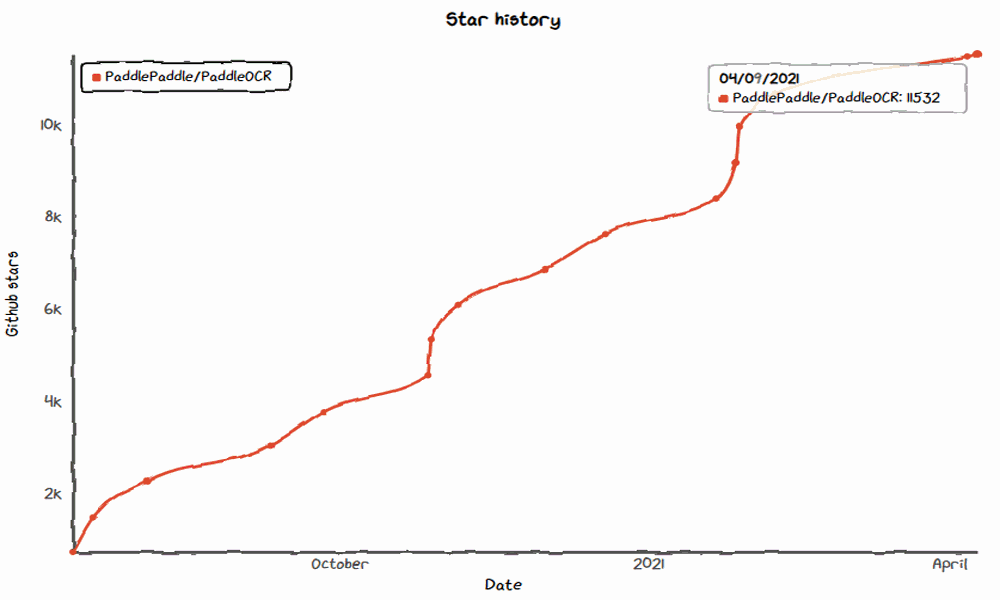
短短半年時間,累計Star數量已超過11.5K,
頻頻登上Github Trending和Paperswithcode 日榜月榜第一,
在《Github 2020數字洞察報告》中被評為中國Github Top20活躍項目。
稱它為 OCR方向目前最火的repo絕對不為過。
最近,它又帶來兩項全新發布:
AAAI 2021 頂會論文開源:PGNet: Real-time Arbitrarily-Shaped Text Spotting with Point Gathering Network 提出了一種簡單且有效的任意方向端到端文本識別模型,在精度可比的基礎上,與之前大火的ABCNet相比,預測速度快了三倍,達到SOTA效果。
多語言支持種類提升至80+種:基本覆蓋國際主流語言種類,在開源測試集MLT2017評估,中文、韓文、日文、拉丁語系、阿拉伯語系,識別效果均顯著優于EasyOCR,開源SOTA效果。
二、PaddleOCR歷史表現回顧
先看下PaddleOCR自去年6月開源以來,短短幾個月在GitHub上的表現:
2020年6月,8.6M超輕量模型發布,GitHub Trending 全球趨勢榜日榜第一。
2020年8月,開源CVPR2020頂會算法,再上GitHub趨勢榜單!
2020年10月,發布PP-OCR算法,開源3.5M超超輕量模型,再下Paperswithcode 趨勢榜第一
2021年1月,發布Style-Text文本合成算法,PPOCRLabel數據標注工具,star數量突破10000+,截至目前已經達到11.5k,在《Github 2020數字洞察報告》中被評為中國Github Top20活躍項目。
這個含金量,廣大的GitHub開發者們自然懂
超輕量模型的效果:火車票、表格、金屬銘牌、翻轉圖片、外語都是妥妥的,

動靜統一的開發體驗
動態圖和靜態圖是深度學習框架常用的兩種模式。在動態圖模式下,代碼編寫運行方式符合Python程序員的習慣,易于調試,但在性能方面, Python執行開銷較大,與C++有一定差距。
相比動態圖,靜態圖在部署方面更具有性能的優勢。靜態圖程序在編譯執行時,預先搭建好的神經網絡可以脫離Python依賴,在C++端被重新解析執行,而且擁有整體網絡結構也能進行一些網絡結構的優化。
飛槳動態圖中新增了動態圖轉靜態圖的功能,支持用戶使用動態圖編寫組網代碼。預測部署時,飛槳會對用戶代碼進行分析,自動轉換為靜態圖網絡結構,兼顧了動態圖易用性和靜態圖部署性能兩方面優勢。
文本合成工具Style-Text效果:相比于傳統的數據合成算法,Style-Text可以實現特殊背景下的圖片風格遷移,只需要少許目標場景圖像,就可以合成大量數據,效果展示如下:

半自動標注工具PPOCRLabel:通過內置高質量的PPOCR中英文超輕量預訓練模型,可以實現OCR數據的高效標注。CPU機器運行也是完全沒問題的。效果演示如下:
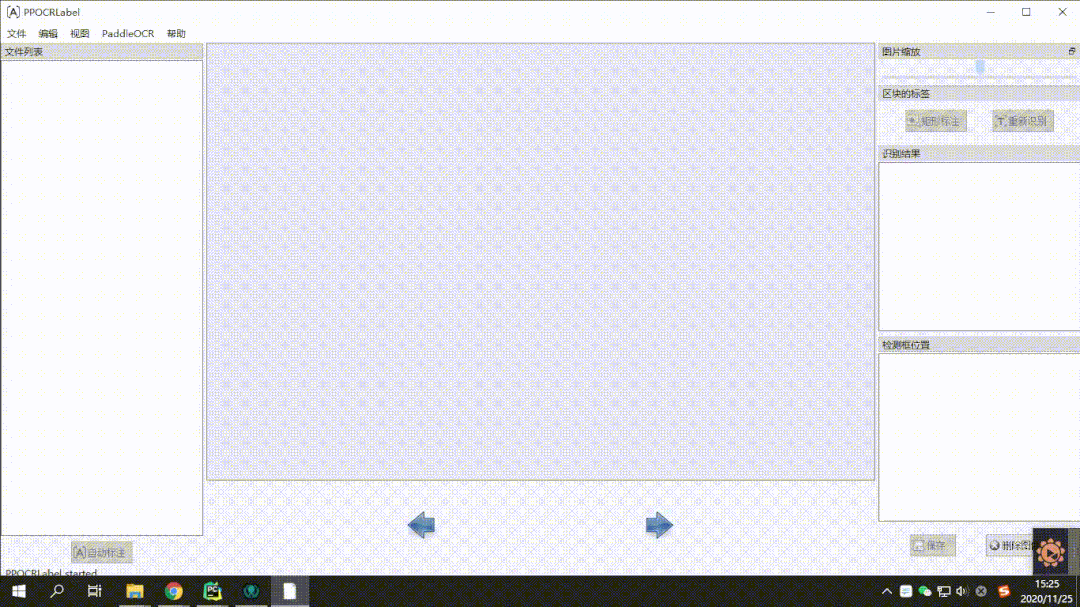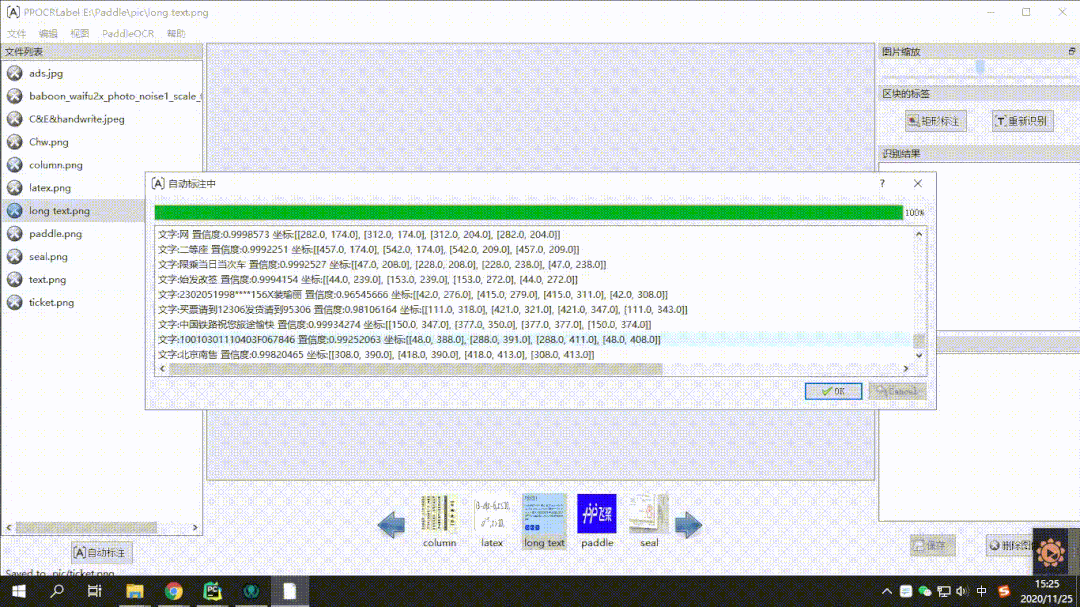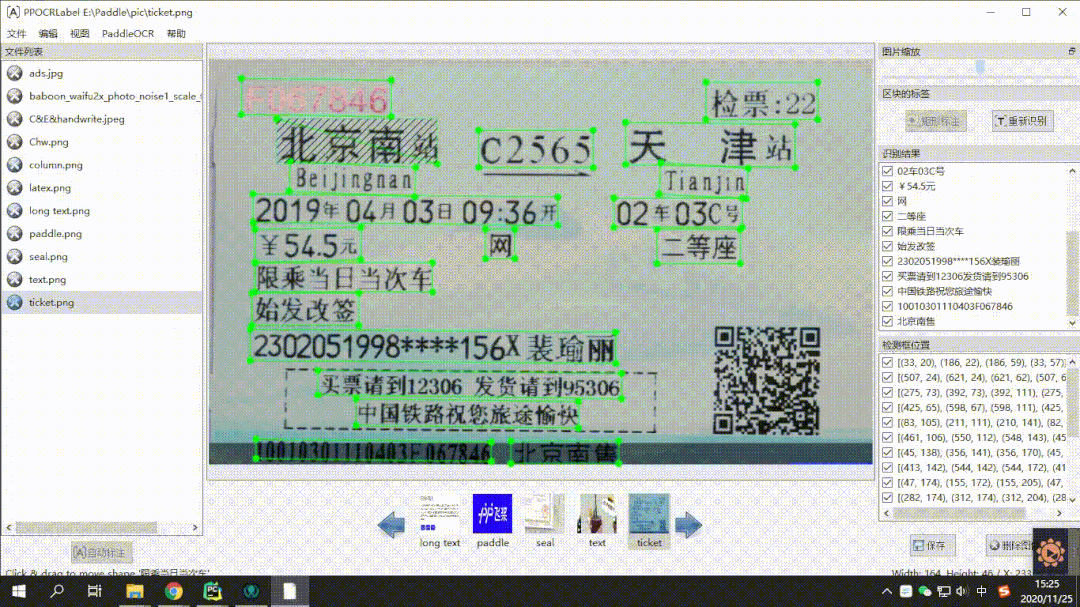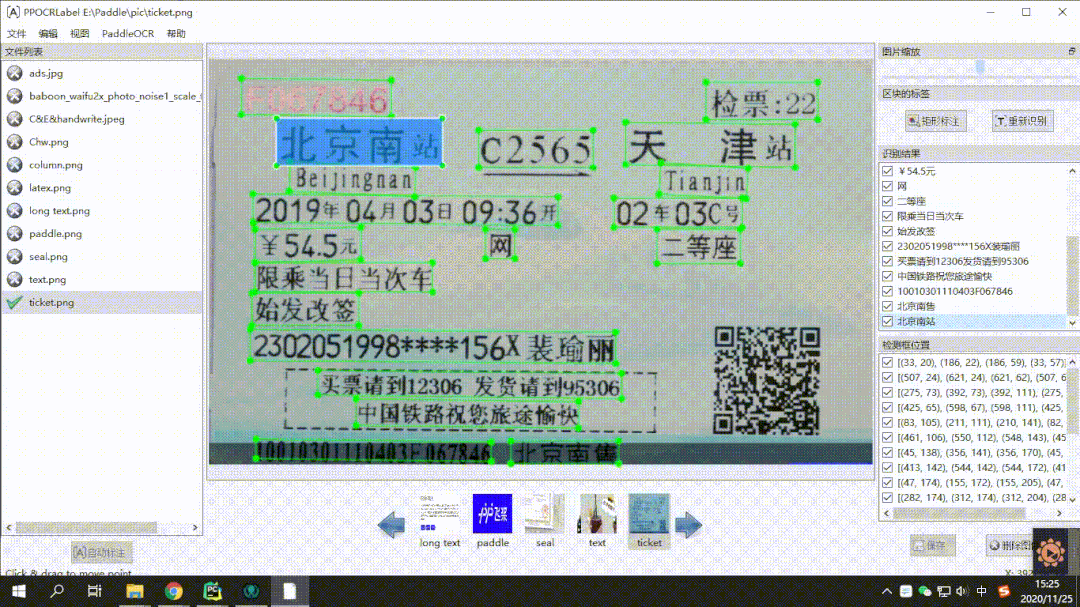
用法也是非常的簡單,標注效率提升60%-80%是妥妥的。
傳送門:
Github:https://github.com/PaddlePaddle/PaddleOCR
那么最近的2021年4月份更新,又給大家帶來哪些驚喜呢?
三、AAAI 2021 頂會論文:端到端SOTA算法PGNet開源:
直接先看指標評測表現:PGNet算法在ICDAR2015數據集上的檢測及端到端性能表現,在精度接近的條件下,速度上與之前大火的ABCNet相比翻了三倍,達到了SOTA的效果。
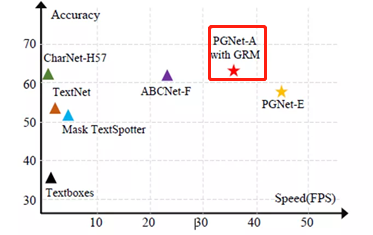
圖1:PGNet模型的速度與精度性能對比
詳細數據指標:
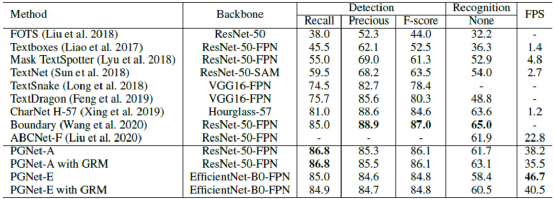
表1:ICDAR2015數據集上的檢測及端到端性能
PGNet提出的方法框架如下圖所示,輸入的圖象經過Backbone網絡得到1/4下采樣特征圖,通過多任務學習,同時回歸四個任務的內容,包括文本邊緣偏移量預測(TBO),文本中心線預測(TCL),文本方向偏移量預測(TDO)以及文本字符分類圖預測(TCC)。其中文本行的檢測結果由TBO以及TCL經過后處理得到,文本行的識別結果由TCL,TDO以及TCC的輸出得到。
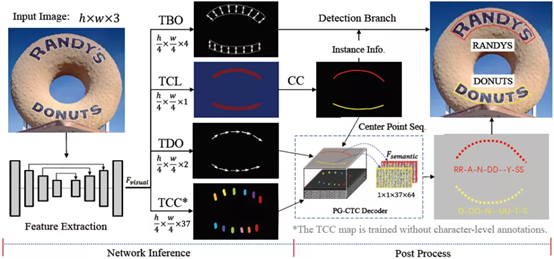
圖2 網絡流程框架
在ICDAR2015以及Total-Text數據集上可以看一下模型效果:

圖3Total-Text及ICDAR2015數據集可視化效果圖
PGNet論文地址:https://www.aaai.org/AAAI21Papers/AAAI-2885.WangP.pdf
【基于頂尖算法,開放拿來即用的成熟印章識別能力】同時,基于PGNet研發的印章識別能力已經在百度AI開放平臺開放,可以有效檢測并識別合同文件或常用票據中的印章,輸出文字內容、印章位置信息以及相關置信度,已支持圓形章、橢圓形章、方形章等常見印章。提供標準化API接口,快速集成,同時支持私有化部署至本地,保障業務數據私密性。
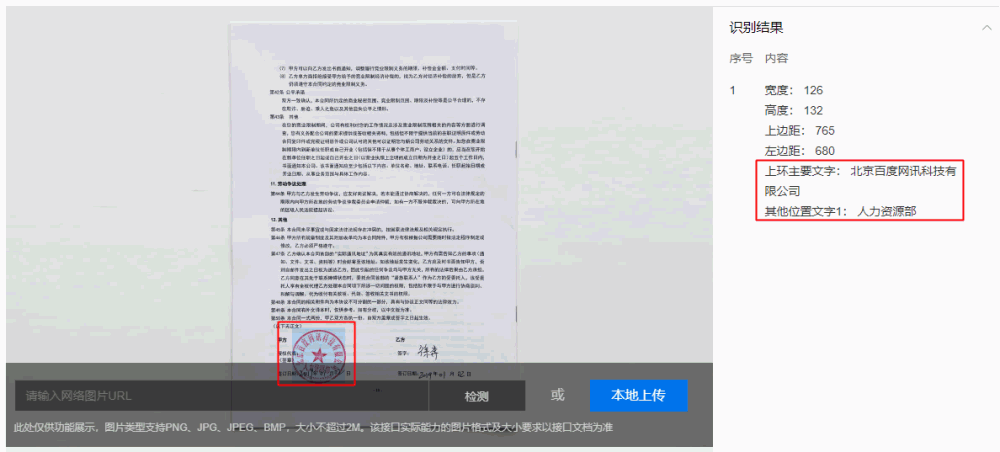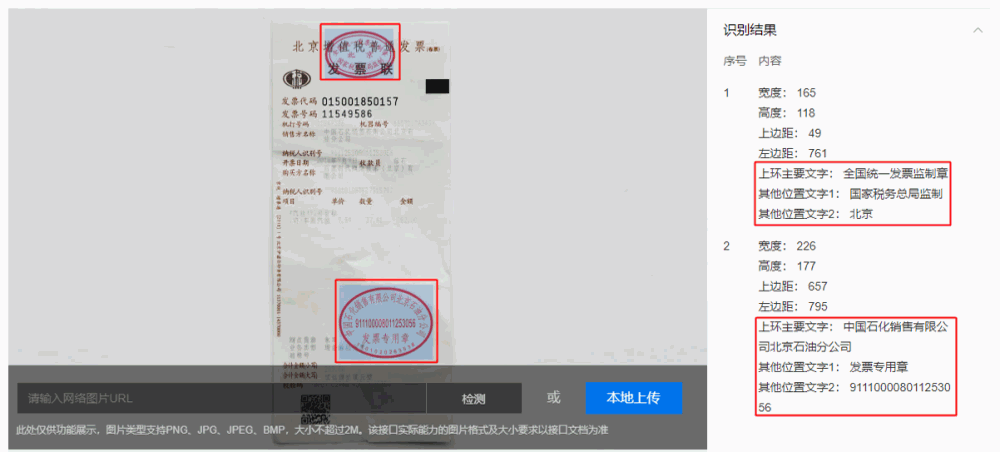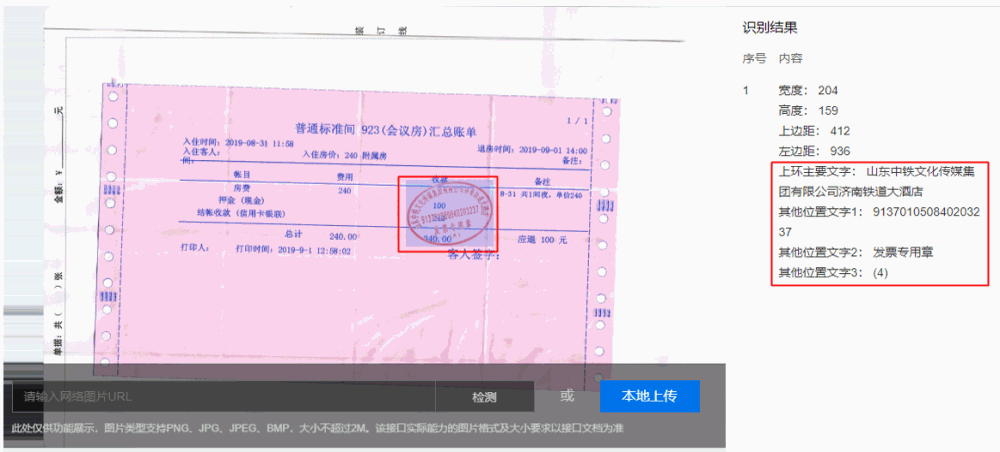
開放能力地址:https://ai.baidu.com/tech/ocr/seal
注:此處非模型直接開源,但可以申請免費試用。
四、豐富的多語言種類支持,目前已經支持全球80+ 語言模型
簡單對比一下目前主流OCR方向開源repo的核心能力:
中英文模型性能及功能對比
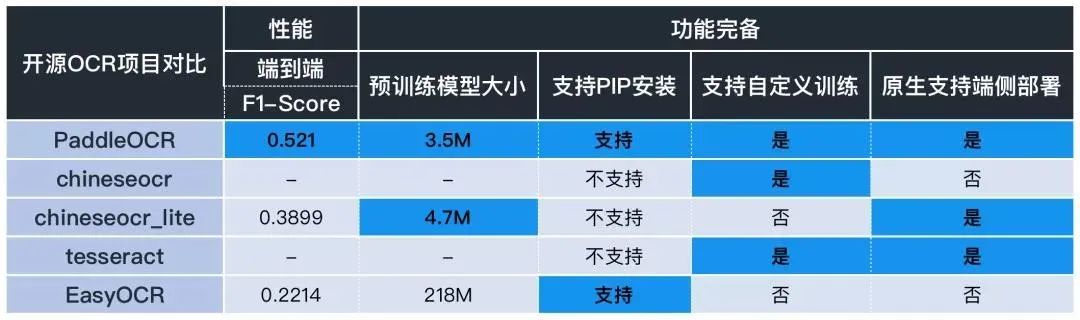
其中,部分多語言模型性能及功能(F1-Score)對比(僅EasyOCR提供)

模型效果

值得一提的是,目前已經有全球開發者通過PR或者issue的方式為PaddleOCR提供多語言的字典和語料,在PaddleOCR上已經完成了全球80+ 主流語言的廣泛覆蓋:包括中文簡體、中文繁體、英文、法文、德文、韓文、日文、意大利文、西班牙文、葡萄牙文、俄羅斯文、阿拉伯文、印地文、維吾爾文、波斯文、烏爾都文、塞爾維亞文(latin)、歐西坦文、馬拉地文、尼泊爾文、塞爾維亞文、保加利亞文、烏克蘭文、白俄羅斯文、泰盧固文、卡納達文、泰米爾文,也歡迎更多開發者可以參與共建。
五、良心出品的中英文文檔教程

別的不需要多說了,大家訪問GitHub點過star之后自己體驗吧:https://github.com/PaddlePaddle/PaddleOCR
責任編輯:lq
-
語言模型
+關注
關注
0文章
524瀏覽量
10277 -
python
+關注
關注
56文章
4797瀏覽量
84689 -
開源項目
+關注
關注
0文章
37瀏覽量
7189
原文標題:Github Star 11.5K項目再發版:AAAI 2021 頂會論文開源,80+多語言模型全新升級
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
臺積電股價創歷史新高,年度表現有望25年最佳
機智云歷史數據導出與排查指南


臺積電第三季度業績超預期,股價創歷史新高
簡述微處理器的發展歷史
圖像處理器的發展歷史
射頻天線的發展歷史
簡述光通信的發展歷史
蘋果股價創歷史新高:iPhone 15與16系列引領市場熱潮
鴻蒙原生應用元服務開發-Web歷史記錄導航
求助,labview數據存儲和歷史數據查詢功能應該如何做課程設計?
帶您回顧端子壓接的歷史






 工商網監
工商網監
評論