 關于超低延遲實時流媒體傳輸技術的圖文詳解
關于超低延遲實時流媒體傳輸技術的圖文詳解
現在云游戲,云應用越來越火,所以超低延遲實時流媒體傳輸技術的需求應用場景會越來越多。騰訊專家工程師劉泓昊老師在LiveVideoStackCon 2020北京站的演講中,對超低延遲傳輸技術從傳輸協議的設計選擇到流控算法和采集都分享了自己不同于行業的理解。
類似云游戲這一類場景是實時視頻傳輸領域中最難的場景,今天主要分享一下我們這兩年云游戲場景上做的一些工作和思考,也會提到一些我們不同于行業的觀點。
這兩年云VR,云游戲,云應用重新火起來。很多大公司都在加入這個行業,像云游戲,從全球來看所有巨頭都在做,包括阿里,騰訊,Amazon,Facebook,Google都在做這個領域。其實這些應用早些年并不是沒有,沒有做起來的一個重要原因是網絡能力跟不上。我非常感同身受,幾年前要求幾十兆碼率延時只有幾十毫秒是不可能的,但是隨著整個中國互聯網的發展,家庭都做到光纖入戶百兆起步, WIFI5的大規模普及,已經有越來越多的用戶網絡能滿足應用的要求,未來隨著WIFI6的普及和5G的興起,我相信新的時代快要來了。
從依賴buffer抗抖動到不抖動
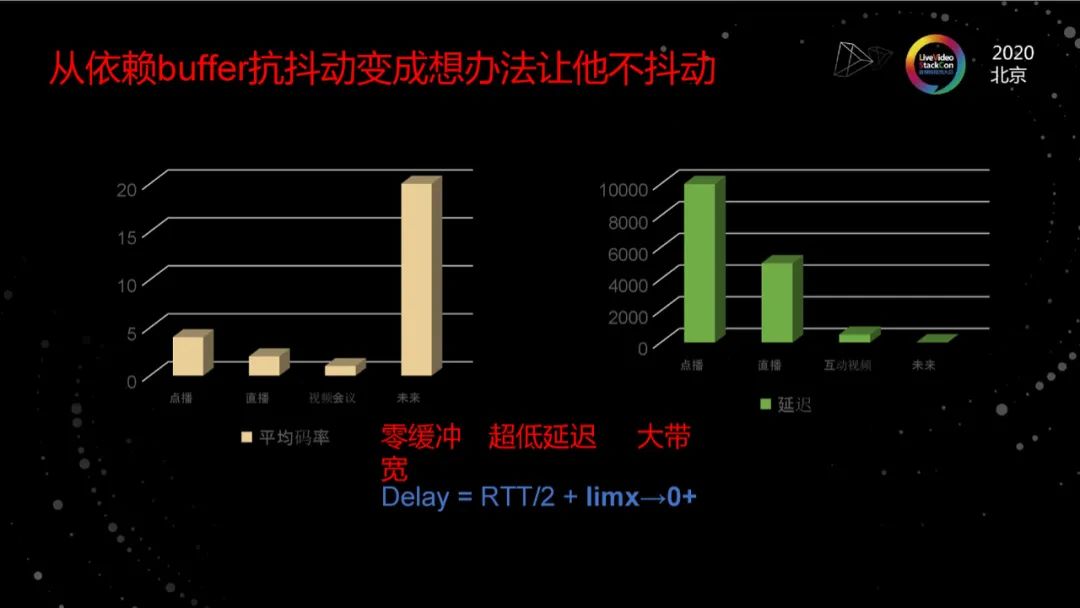
簡單看一下類似場景對網絡的要求,這種場景本質上是內容生產即消費,它們的間隔在十毫秒級。我們要讓用戶得到非常好的視聽感受,需要足夠大的速率來傳輸視頻畫面。以云游戲為例,云游戲想讓用戶的體驗接近于本地游戲,只是就1080P而言,需要碼率在20Mb以上,這還不算未來的4K、8K視頻。云VR可能需要70兆。
簡單用三個詞描述對應用的要求,就是零緩沖,超低延遲,大帶寬。隨著邊緣計算的大規模普及,網絡的物理延遲倒還不是太大的挑戰,關鍵是我們怎么讓軟件的傳輸延遲無限接近于物理延遲,怎么充分利用帶寬、怎么從以前利用buffer來對抗網絡抖動,變成讓網絡不抖動。 我們一直以來的觀點是,網絡傳輸協議設計和優化的本質是端到端的QoS,即結合應用的QoS來設計最合適的協議和算法,因此面向新的應用場景和技術挑戰,我們需要圍繞著零緩沖,超低延遲,大帶寬來設計我們的系統、協議和算法。
我們所有的東西都是基于零緩沖,超低延遲,大帶寬來設計的。
協議設計的關鍵點

今天的內容我主要講三點:
可靠性, 為什么我要強調可靠性,主要有兩點原因:
1. 大碼率場景下,單位吞吐大幅增加,單幀大小大幅增加,導致丟包數大幅增加,尤其是重傳包丟包數大幅增加對我們的丟包處理提出了更高的要求;
2. 低延遲的要求導致我們對于重傳的實時性提出了更好的要求;
流控算法,新的應用場景對單位吞吐和低延遲的要求,對流控算法提出了極高的收斂性和利用率要求,需要我們有顛覆性的算法設計;
最后我會說一下我們對于UDP和TCP的選擇上,有不同于行業的觀點和效果很不錯的實踐。
關于可靠傳輸機制

關于可靠傳輸機制的第一個觀點,雖然視頻流并不是完全不能丟包,但是應用層丟包是應該盡量避免的。所有的數據丟棄應該都是主動丟棄而不是能力不夠導致的,舉個例子,傳一個O幀數據中有個包因為能力不夠丟失了,就得生產一個I幀,平均一個I幀的大小是p幀的6-12倍,因為能力不夠丟失一個數據包導致要生產一個數倍大的數據,這對傳輸延遲的體驗是很糟糕的。所以要盡可能保證所有數據丟失,是我主動丟失的,而不是能力不夠導致的。
類FEC和重傳的關系

接下來我們來說一下FEC和重傳的關系, FEC和重傳的優缺點大家是有共識的,通過FEC可以降低丟包帶來的影響,減小幀延遲,但是FEC會導致帶寬的浪費;重傳不會帶來帶寬的浪費, 但是重傳就意味著延遲的增加。最合適的用法一定是把它們結合起來一起使用,延遲小、丟包率低的時候帶寬優先,延遲大、持續丟包的時候FEC優先。 這個地方我想強調兩點:第一,丟包是可以預測的,通過合理的預測是可以大幅降低FEC的使用的;第二,在使用FEC的情況下,尤其是網絡不好的時候,是有機會去做先驗冗余的。
NACK和SACK的選擇
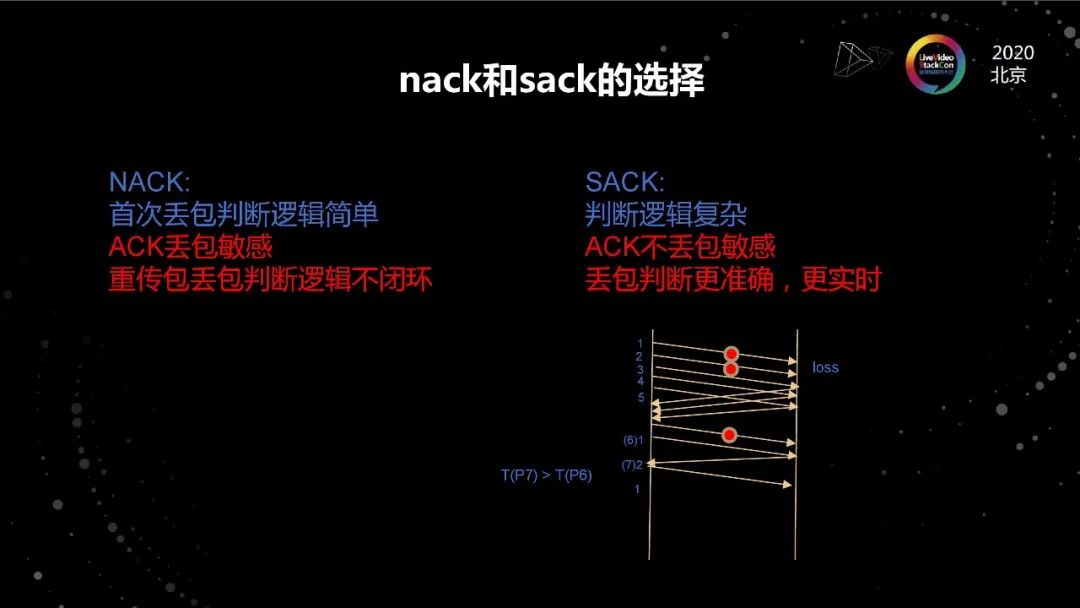
既然重傳一定要有,就看怎么發現丟包,行業有兩種通用做法。第一種做法是NACK 。NACK的優點是丟包判斷邏輯非常簡單,發現客戶端有hole就知道它丟包了,但是如果NACK包丟了,客戶端是不知道的,或者說收到NACK包,重傳包丟了,客戶端也是不知道的,沒有一個邏輯能閉環保證我能知道這個包一定丟了。一旦出現上述情況,就只能靠超時,在超低延遲的場景下,超時是一個非常不好的手段。因為超時有兩種可能性,第一種超時值太大了,超時太大意味著這一幀的延遲和抖動非常大,從用戶感受來說就是卡頓或者手感不好。第二種如果說超時設置很小,會導致生產重復的包,讓擁塞更加嚴重。這個點是很難平衡的,核心原因是NACK沒有一個閉環邏輯能保證所有的丟包判斷邏輯是準確的。
SACK其實是現在做可靠傳輸協議純ALOHA協議的機制里面常用的方法。包括TCP,QUIC也是類似。SACK的缺點是判斷邏輯非常復雜,SACK的優點是ACK丟包不敏感。第一因為SACK是有一串閉合邏輯的,丟掉任何一個包,后續的包能補上,所有丟一個SACK不會影響整體的判斷邏輯。第二因為SACK是個有狀態的,這個狀態能做到丟包判斷更準確,更實時,用一個rtt一定能判斷出來。
展開一下,老的Linux內核里實現里面SACK的邏輯很復雜,是因為它是基于序號序的,整個判斷邏輯是以序號來判斷是否丟包,這會導致整個隊列邏輯判斷非常痛苦。我們在13年做了一個新的方法,我們稱為基于時間序的丟包。如圖所示,我們根據數據包的發送時間來判斷做丟包的判斷,基于這樣一個邏輯,整體判斷邏輯會比傳統內核簡單很多而且更精準,在這個邏輯下只要保證最后一個包不丟,那就能快速判斷出前面的包有沒有丟。如果最后一個包丟了,另一個辦法叫prob包。類似的工作Google在16、17年已經patch到內核里了,QUIC上也有類似的實現方法。
所以,在大帶寬、低延遲的場景下,丟包判斷的邏輯會變得更重要,這個時候SACK是遠比NACK更好的方法,雖然它的實現復雜度要大很多。
關于流控

關于流控我們有三個觀點,第一個觀點是面向超低延遲和大吞吐場景我們需要新的流控目標模型,它跟傳統的TCP的擁塞控制是不一樣的。第二個觀點是我們對延遲要求非常高,就意味著采集周期會變得很關鍵,百毫秒級的采集粒度已經完全滿足不了新應用的要求了。第三個觀點,流控算法的核心是吞吐,不是丟包,不是delay,也不是buffer,基于吞吐模型可以讓我們有更好的收斂性。
流控的新目標
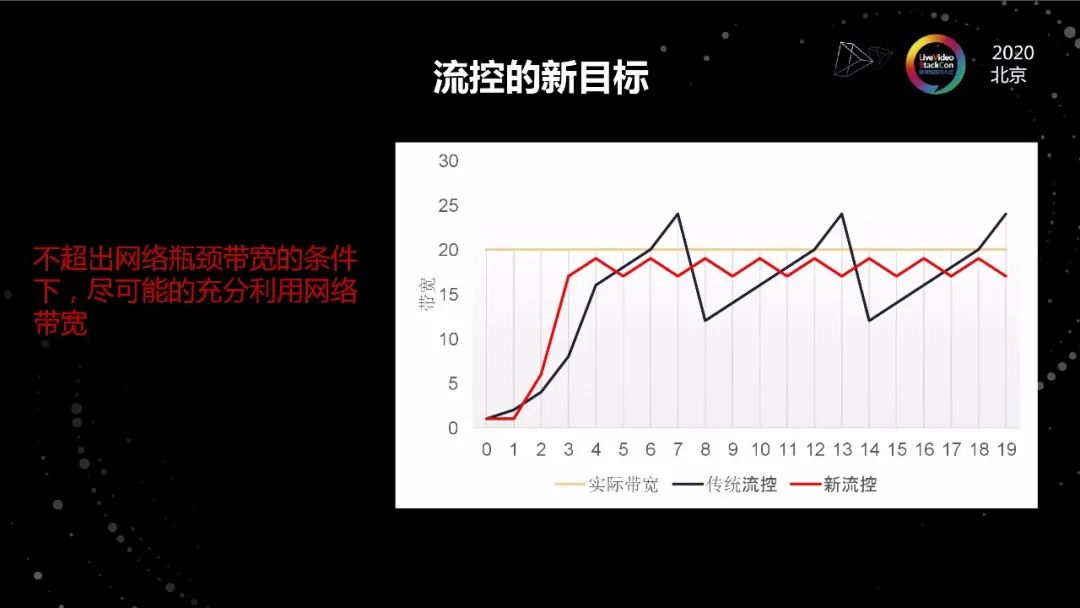
實時視頻流是App Limit,它在宏觀上的上限是受到碼率限制的,在新的場景下,碼率限制被徹底打開了,從實用的角度來說,流控的作用和價值就變得尤其巨大了。
實際上TCP的擁塞控制算法和流控,尤其是沒有buffer的流控還真不是一回事。擁塞控制算法的設計目標是效率、公平、收斂。結合低延遲、零buffer的特性,流控的目標是在不超出網絡瓶頸帶寬的條件下,盡可能的充分利用網絡帶寬。
所以如圖所示的紅線才是我們期望的結果,即碼率不斷在接近目標帶寬的下面徘徊, 如果說傳統的TCP擁塞控制算法目標是帶寬利用率100%的話,我們只要做到90%就可以了。
還有一條,TCP擁塞控制算法其實不太糾結微觀的情況,它關心的是宏觀的收斂性能,但是在流控上微觀的收斂情況,尤其是收斂速度是很重要的。因為對于我們這種沒有緩沖的場景來說,在降速的時候收斂慢就是卡頓。對于視頻流來說,碼率波動大,QoE肯定好不了。
關于采集

第一點,如果希望延遲是幾十毫秒,那網絡波動的時候,采集周期是一百毫秒。等到一百毫秒才知道網絡波動再去做處理,那意味著網絡一波動就卡頓,所以采集的精度一定要足夠細。但是采集精度足夠細帶來的另一個問題是怎么把數據做準,這是一個非常矛盾的點,又需要很小的采集間隔,又需要把數據做準,甚至能反應網絡情況的,這是非常不容易的事。這也是為什么以前系統會把采集間隔放的稍微大一點的原因,這樣采集數據是能真實體現網絡情況的。解決這個問題的方式是幀粒度,因為幀是有邏輯,有狀態的,這些邏輯和狀態是可以梳理清楚并且建模的。幀粒度是目前為止我們能找到的最好的采集間隔和采集方法。
第二點,因為延遲性要求,所以要快速發現。這里面就兩種采集方法一種是在發端采集,一種在收端采集,收端采集有一定時間間隔才能往上報,這樣會導致判斷的時間偏晚,這樣和我們需要的盡可能實時判斷和低延遲又是矛盾的。所以建議數據采集是發端為主,收端為輔。因為發端的采集和計算過程可以在任何一個中間態進行。發端采集數據不準的部分,用收端來補充。
第三點,沒有數據也是數據。沒有數據背后反映很多東西,是很有價值的,這一點在我們做的過程中,效果是非常好的。
流控算法
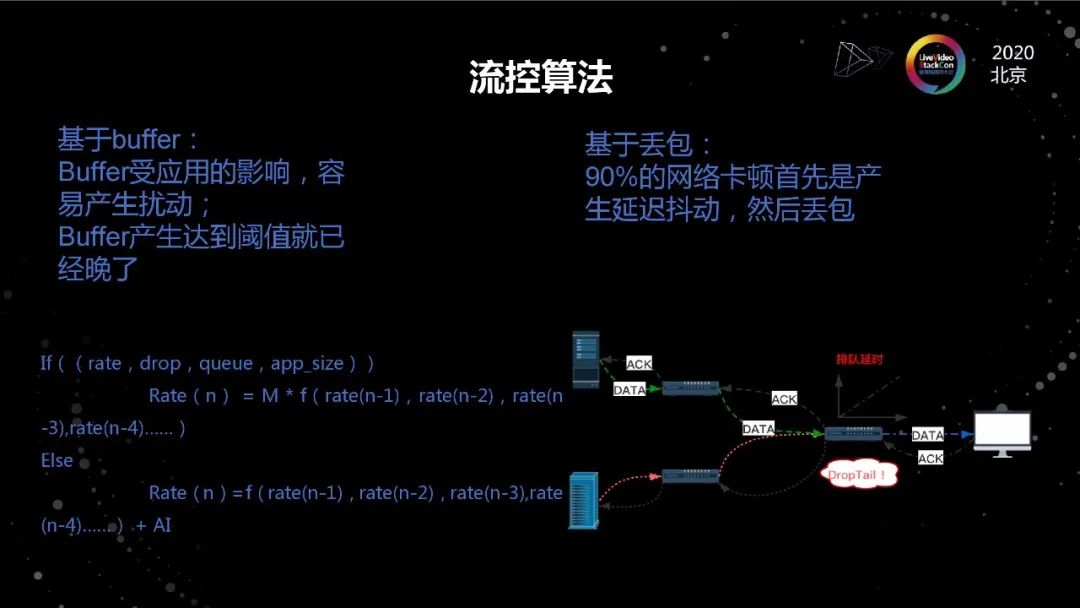
流控的本質是不斷尋找可用帶寬的過程。它在實際實現過程中無非是帶寬沒有用完的時候,通過不斷上探的方法,找到合適的速率。當網絡擁塞或者抖動的時候,快速降低速率以適配當前的網絡情況。這里面就幾個問題,第一個問題是當網絡擁塞的時候依靠什么來發現。通常的方法就兩種,第一種就是丟包,在中國有90%的場景是先rtt先升高再丟包,但是對于低延遲的場景來說,rtt的大幅升高是不可接受的。另外,早年關于TCP的不公平性,定義了兩個場景,一個是rtt的不公平性,即rtt越大,速率越低;一個是多瓶頸鏈路的不公平性,它指的是在非瓶頸鏈路產生的丟包會導致連接的速率偏低,這就是因為我們通常把丟包做為擁塞的判斷依據導致的。因此,丟包一定不是好的判斷依據。
基于buffer來判斷網絡擁塞,有兩個問題,第一,實際雖然我們是App Limit型的,但每幀大小是不一致的,buffer的堆積并不完全是因為網絡的帶寬不匹配導致的;第二, buffer的堆積是以犧牲體驗為代價的,并不是一個好的信號。
從目前我們的探索來看, 速率模型是一個更好的模型,理由有三:
1. 流控的本質是讓發送的帶寬和網絡瓶頸鏈路的接收能力是一致的,接收能力是速率,發送帶寬也是速率,所以基于速率來作為模型更實時的判斷卡頓依據是更好的方法。
2. 接收速率來決定降速到多少,是可以實現降速的快速收斂的。
3. 帶寬的探測過程本質還是預測速率,他背后還是速率模型。
TCP的擁塞控制早年最經典的算法是AIMD,即加性增,乘性減。我個人非常認可AIMD這個思路的,因為AIMD是我目前看到收斂到公平的最好的機制。雖然有很多啟發式的算法,例如MIMD號稱可以收斂的效率很快,但是收斂到公平的能力是很差的。然而今天互聯網音視頻最大的問題不是最快的那個跑的有多快,而是最慢的那個跑的太慢了,這是有人說應用體驗不好的核心原因。這本質上就是收斂到公平的能力,所以收斂到公平都是其中非常重要的因素。
基于此,我們認為AIMD并不是一個過時的方法,問題是我們應用怎么使用。最后說一下基于人工智能的流控,我的觀點是,流控的核心是模型,人工智能是模型之上的補充,不存在完全的人工智能,人工智能是加分項,不是地基,它或許能幫我們做到95分,前提是我們自己能做到80分。
流控流程
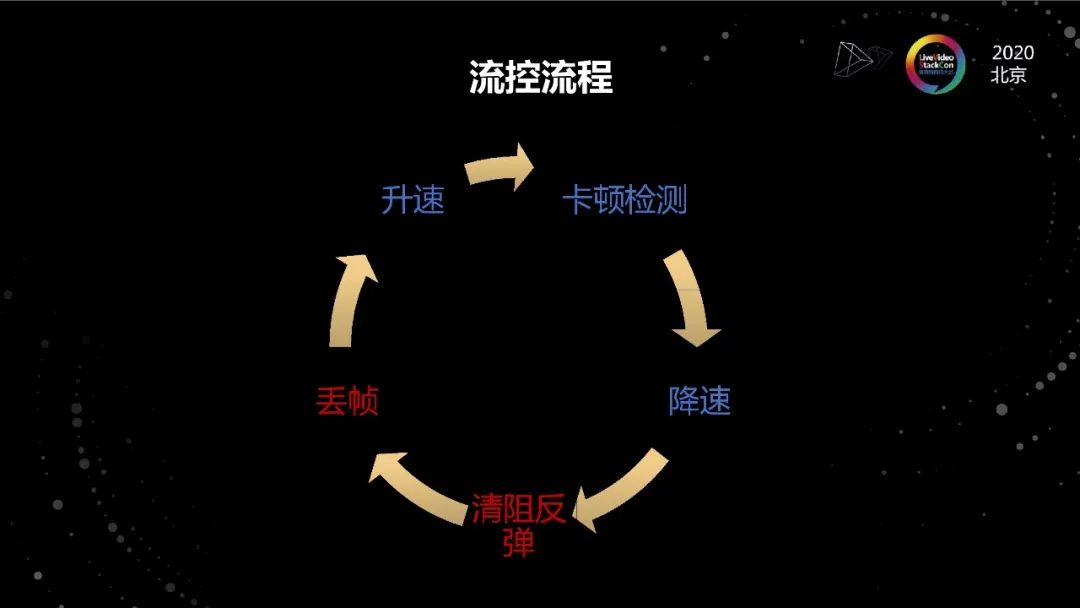
因為做超低延遲的應用,不同于其他場景,為了保證實時性,清阻過程(包括丟幀)是很重要的階段,不能被忽略。
關于網絡傳輸協議

從視頻流來講,很顯然UDP是比TCP更合適的。第一,UDP比TCP更靈活,丟數據更好丟,用TCP的話在底層丟數據是非常不容易的;第二,UDP可以用FEC,但是TCP用不了;第三,如果我們是推流,那手機端內核我們是改不了的,內核改不了用傳統TCP效果肯定是不好的;第四,是內核代碼不好改,相比應用層代碼,Linux內核的學習成本確實不低。但是,從我們的數據來看,在高碼率情況下UDP的丟包率是要高于TCP,而且碼率越高丟包率越高。
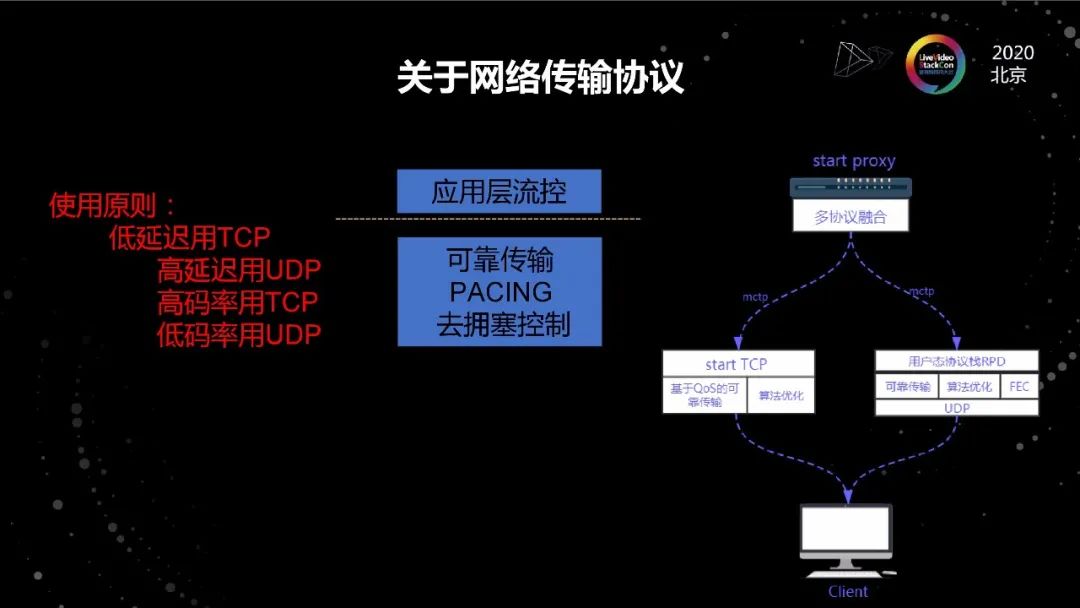
在實踐過程中我們做了一套基于TCP的傳輸體系,在我們體系里面,TCP協議棧主要功能是可靠傳輸和圍觀尺度的PACING,但是不做擁塞控制。實際上,為什么TCP做視頻傳輸做不好,很重要的一個原因是上面有應用層流控,下面又有擁塞控制,他們是互相沖突的。我們改造之后,整體的效果我們還是非常滿意的。我們平均端到端的延遲,即從發送數據到被確認時間已經非常接近物理延遲了,到ACK回來不到二十毫秒,我們在有線網絡上的卡頓情況并不比硬件產生的卡頓更多,我們空口的卡頓率比線上直播要低。
比較理想的方案是既把UDP用上又把TCP低丟包特性用上,所以我們最終的系統是我們會在一個會話里跑兩個連接,一個TCP一個UDP,當我延遲小丟包率低碼率高的時候我會用TCP,當我網絡不好延遲高丟包率高碼率上不去的時候用UDP。低延遲用TCP高延遲用UDP,高碼率用TCP低碼率用UDP 。
我們這里說的UDP指的是基于UDP實現的具備重傳和FEC能力的應用層可靠傳輸協議,我們目前使用的是我們自研的可靠傳輸協議RPD 在可靠傳輸協議之上我們還需要實現一個協議實現多個連接跑在同一個會話上,讓兩個連接能做到無縫實時切換。

我們現在面臨的最大的問題并不是匹配不了用戶帶寬,而是所使用鏈路根本不具備傳輸超低延遲的這個能力。我們發現很多用戶的wifi上連兩兆速率的穩定傳輸都做不到。這個問題在wifi 2.4GHZ頻段上非常明顯,在wifi 5GHZ頻段上就好很多。我相信隨著wifi6的出現,未來會更好 。但是無論如何空口傳輸的穩定性,它們都是比不過有線網絡的。我們的觀點是,我們要做兩件事:第一我們要深耕產業鏈,我們要把整個產業鏈打通,讓空口的能力適配低延遲的要求。第二是空口很大一部分的問題是概率,如果能把兩個獨立的信道疊加起來,如果有兩個信道的話就等于把兩個獨立的概率事件疊加起來,2個9有機會變成4個9。所以未來在不可靠的無線鏈路上,用多鏈路實現高可靠是有很大機會的。用現在大部分手機都能支持wifi/4g雙通道了,我們判斷wifi/5G 、wifi/wifi、5G/5G雙通道一定是未來保證超低延遲的基礎手段。而且這種手段不止在超低延遲的場景下使用,當前主流的直播、點播應用上都有很大的應用價值。
我們相信,多通道技術一定是未來網絡傳輸系統發展的趨勢。

首先Sack是更好的重傳發現機制;第二點是幀粒度的采集是合適的采集方法;第三點是速率模型做流控;第四是TCP和UDP混用在超低延遲場景效果很好,最后未來是多鏈路的。
編輯:lyn
-
傳輸技術
+關注
關注
2文章
59瀏覽量
13874 -
vr
+關注
關注
34文章
9641瀏覽量
150520 -
wifi6
+關注
關注
4文章
503瀏覽量
38290
原文標題:超低延遲實時流媒體傳輸技術
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
流媒體后視鏡市場份額連續6年稱霸全國,新產品即將上市

北京君正X2000新品案例:流媒體音樂接收器
遠峰科技:流媒體后視鏡市場份額連續6年稱霸全國,新產品即將上市

傳感器技術在構建實時監控系統中有什么作用
ElfBoard技術貼|如何在ELF 1開發板上搭建流媒體服務器

谷歌宣布對Android設備流媒體服務進行重大擴展
貿澤開售AMD / Xilinx Alveo MA35D媒體加速器 為流媒體、游戲、遠程醫療和在線學習應用提供支持
亞馬遜擬收購印度流媒體MX Player部分資產
【RTC程序設計:實時音視頻權威指南】信令與媒體協商
Deltacast借助AMD器件推出實時低時延視頻采集與流媒體卡
車載智能后視鏡_流媒體云鏡_行車記錄儀主板方案定制

高清視頻編碼器與流媒體平臺的完美結合





 工商網監
工商網監
評論