 關于一項改進Transformer的工作
關于一項改進Transformer的工作
NAACL2021中,復旦大學大學數據智能與社會計算實驗室(Fudan DISC)和微軟亞洲研究院合作進行了一項改進Transformer的工作,論文的題目為:Mask Attention Networks: Rethinking and Strengthen Transformer,被收錄為長文。
文章摘要
Transformer的每一層都由兩部分構成,分別是自注意力網絡(SAN)和前饋神經網絡(FFN)。當前的大部分研究會拆開這兩份部分來分別進行增強。在我們的研究當中,我們發現SAN和FFN本質上都屬于一類更廣泛的神經網絡結構,遮罩注意力網絡(MANs),并且其中的遮罩矩陣都是靜態的。我們認為這樣的靜態遮罩方式限制了模型對于局部信息的建模的。因此,我們提出了一類新的網絡,動態遮罩注意力網絡(DMAN),通過自身的學習來調整對于局部信息的建模。為了更好地融合各個子網絡(SAN,FFN,DMAN)的優勢,我們提出了一種層疊機制來將三者融合起來。我們在機器翻譯和文本摘要任務上驗證了我們的模型的有效性。
研究背景
目前大家會從SAN或者FFN來對Transformer進行改進,但是這樣的方案忽略了SAN和FFN的內在聯系。
在我們的工作當中,我們使用Mask Attention Network作為分析框架來重新審視SAN和FFN。Mask Attention Networks使用一個遮罩矩陣來和鍵值對的權重矩陣進行對應位置的相乘操作來確定最終的注意力權重。在下圖中,我們分別展示了SAN和FFN的遮罩矩陣。由于對于關系建模沒有任何的限制,SAN更擅長長距離建模來從而可以更好地捕捉全局語意,而FFN因為遮罩矩陣的限制,無法獲取到其他的token的信息,因而更關注自身的信息。
盡管SAN和FFN取得了相當好的效果,但是最近的一些研究結果表明,Transformer在捕捉局部信息的能力上有所欠缺。我們認為這種欠缺是因為是因為注意力矩陣的計算當中都是有靜態遮罩矩陣的參與所導致的。我們發現兩個不相關的token之間的權重可能因為中間詞的關系而錯誤地產生了較大的注意力權重。例如“a black dog jumps to catch the frisbee”, 盡管“catch”和“black”關系不大,但是因為二者都共同的鄰居“dog”的關系很大,進而產生了錯誤了聯系,使得“catch”忽略了自己真正的鄰居。
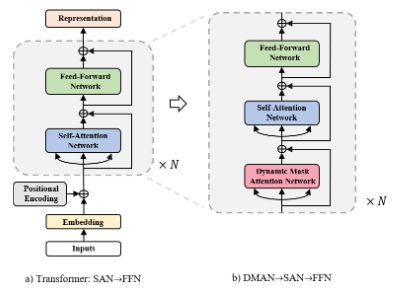
為了強化Transformer在局部建模的能力,我們提出了動態遮罩注意力網絡(DMAN)。在DMAN當中, 在特定距離內的單詞相比于一般的注意力機制會得到更多的注意力權重,進而得到更多的關注。另外,為了更好地融合SAN,FFN和DMAN三者的能力,我們提出使用DMAN-》SAN-》FFN這樣的方式來搭建網絡結構。
方法描述
回顧Transformer
SAN的注意力機制使用下面的公式來將鍵值對映射到新的輸出。
其中是查詢向量組成的有序矩陣,是鍵值對的組合,是的特征維度。
為了進一步增強transformer捕捉不同文本特征的的能力,對于一個文本特征的輸入序列, SAN會使用多頭注意力機制。
在FFN當中,每一個
的計算都是獨立于其他的輸入的。具體來說,它由兩個全連接層組成。
定義一類新網絡: Mask Attention Networks
我們在SAN的注意力函數的基礎上定義帶遮罩的注意力函數。
其中M是一個遮罩矩陣,它既可以是靜態的,也可以是動態的。
在這個新的遮罩矩陣的基礎上,我們定義一類新網絡: Mask Attention Networks(MANs)
其中F是激活函數,M^i是第i個注意力上的遮罩矩陣。
接下來我們來說明SAN和FFN都是MANs當中的特例。
從MANs的視角來看,對于SAN,我們令
這個時候MANs可以寫成下面的形式。這個結果告訴我們SAN是MANs當中固定遮罩矩陣為全1的特例
對于FFN,我們令
那么得到SAN是MANs當中固定遮罩矩陣為單位陣的特例。
SAN和FFN在局部建模上的問題
直觀上來說,因為FFN的遮罩矩陣是一個單位陣,所以FFN只能獲取自身的信息而無法獲知鄰居的信息。對于SAN,每一個token都可以獲取到句子其它的所有token的信息。我們發現不在鄰域當中的單詞也有可能得到一個相當大的注意力得分。因此,SAN可能在語義建模的過程當中引入噪聲,進而忽視了局部當中的有效信號。
動態遮罩注意力網絡
顯然地我們可以通過靜態的遮罩矩陣來使模型只考慮特定鄰域內的單詞,從而達到更好的局部建模的效果。但是這樣的方式欠缺靈活性,考慮到鄰域的大小應該隨著query token來變化,所以我們構建了下面的策略來動態地調節鄰域的大小。
其中是當前的層數,是當前的注意力head, 和分別是兩個和的位置。都是可學習的變量。
組合Mask Attention Networks當中的各類網絡結構
我們采用下圖的方式來組合這三種網絡結構。
實驗
我們的實驗主要分為兩個部分,機器翻譯和文本摘要。
機器翻譯
我們在IWSLT14 De-En和WMT14 En-De上分別對我們的模型進行了驗證。相比于Transformer,我們的模型在base和big的參數大小設定下,分別取得了1.8和2.0的BLEU的提升。
文本摘要
在文本摘要的任務上,我們分別在CNN/Daily Mail和Gigaword這兩個數據集上分別進行了驗證。相比于Transformer,我們的模型在R-avg上分別有1.5和0.7的效果提升。
對比不同的子網絡堆疊方式

我們對比了一些不同的子網絡堆疊方式的結果。從這張表中我們可以發現:
C#5,C#4,C#3》C#1,C#2,這說明DMAN的參與可以提高模型的效果。
C#5,C#4》C#3,C#2,說明DMAN和SAN有各自的優點,它們分別更擅長全局建模和局部建模,所以可以更好地合作來增強彼此。
C#5》C#4,說明先建模局部再全局比相反的順序要更好一些。
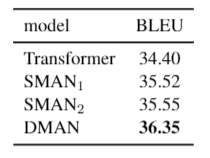
我們比較了兩組不同的靜態遮罩策略。
SMAN1:遮蓋距離超過b的所有單詞,,為句子長度。
SMAN2:b=4。
從結果來看,我們發現DMAN的效果遠遠好于上述兩種靜態遮罩方法,這說明給不同的單詞確實在鄰域的建模上確實存在差異。
結論
在這篇論文當中,我們介紹了遮罩注意力網絡(MANs)來重新審視SAN和FFN,并指出它們是MANs的兩種特殊情況。我們進而分析了兩種網絡在局部建模上的不足,并提出使用動態遮罩的方法來更好地進行局部建模。考慮到SAN,FFN和DMAN不同的優點,我們提出了一種DMAN-》SAN-》FFN的方式來進行建模。我們提出的模型在機器翻譯和文本摘要上都比transformer取得了更好的效果。
原文標題:遮罩注意力網絡:對Transformer的再思考與改進
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
網絡
+關注
關注
14文章
7583瀏覽量
88949 -
Transforme
+關注
關注
0文章
12瀏覽量
8795
原文標題:遮罩注意力網絡:對Transformer的再思考與改進
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AMD獲得一項玻璃基板技術專利
谷歌云宣布一項重要人事任命
蘋果新獲一項投影儀專利
PCB生產,在鉆咀和成品孔徑之間,你會優先滿足哪一項呢
在THS3201的datasheet中,有一項指標noise figure,其值為11dB,這個指標怎么解釋?
蘋果獲得一項突破性智能戒指技術的專利
Transformer能代替圖神經網絡嗎
森林火災監控是一項關系到社會安定,快速發展息息相關的重要工作

使用Tasking編譯器為同一項目手動創建一個makefile,在創建make文件時報錯的原因?
用ST Visual Program燒寫程序,可是打開軟件之后好像少了一項DATA MEMORY這是怎么回事?
NVIDIA和谷歌云宣布開展一項新的合作,加速AI開發
華為公布一項名為“鈉電池復合正極材料及其應用”的發明專利
華為技術近日公開了一項“超聲波指紋”專利







 工商網監
工商網監
評論