 關于OCR 你想了解的可能都在這兒了
關于OCR 你想了解的可能都在這兒了
導讀
OCR中的研究,工具和挑戰,都在這兒了。
介紹
我喜歡OCR(光學字符識別)。對我來說,它代表了數據科學,尤其是計算機視覺的真正挑戰。這是一個現實世界的問題,它有很多方法,包括計算機視覺,pipeline調整,甚至一些自然語言處理。它也需要大量的工程設計。它概括了數據科學中的許多問題:破壞了強大的基準,過分強調方法的復雜性和“新穎性”,而不是關注現實世界的進步。
兩年前,我發表了一篇關于OCR的文章。像我的大多數文章一樣,這篇文章意在回顧這個領域的研究和實踐,闡明你能做什么,不能做什么,如何做,為什么做,并提供實用的例子。
它的本質是,當時的深度學習OCR是好的,但還不夠好。現在,OCR要好得多。但還是不太好。
但是,考慮到深度學習領域的活力,在我看來,它需要一個更新,甚至是完全重寫。就是這樣。如果你來到這里,你可能對OCR感興趣。你要么是一名學生,要么是一名想要研究這個領域的研究員,要么你有商業興趣。不管怎樣,這篇文章應該能讓你跟上進度。
開始
首先,讓我們理清我們的概念:
OCR- 光學字符識別。這是一個常見的術語,主要指文檔上的結構化文本。
STR- 場景文本識別。大多指的是在野外場景中更具有挑戰性的文本。為了簡單起見,我們將它們都稱為OCR。
如前所述,OCR描述了深度學習和一般數據科學領域的許多成就,但也面臨著挑戰。一方面,這是我們之前的巨大進步。同樣是令人印象深刻的同比進步。然而,OCR仍然沒有解決。
還有一些非常惱人的失敗案例,原因各不相同,大部分都是源于標準深度學習的根本原因 —— 缺乏泛化、易受噪聲影響等。因此,即使模型可以處理許多情況(不同的字體、方向、角度、曲線、背景),也有一些偏差是不能工作的(只要它們不是手動引入到訓練集中):不流行的字體、符號、背景等等。
任意形狀的文本 — 來自ICDAR 2019數據集
此外,還出現了一個偉大而有用的庫Easy OCR:https://github.com/JaidedAI/EasyOCR,它的目標是使最先進的OCR方法在開源中易于訪問和使用。作為額外的好處,這個庫還解決了OCR中的多語言問題(目前包括大約80種語言和更多的語言)和模型的速度(仍處于早期階段)。這個庫并不完美,但它確實是一個很好的解決方案。稍后再詳細介紹。
因此,廢話不多說,讓我們看一下OCR當前的狀態。
值得注意的研究
一如既往,數據科學任務的邊界被研究擴展,而實踐在創新方面落后,但在穩健性方面領先。
在我之前的文章中,我回顧了3種方:
當時流行的經典計算機視覺方法
一般深度學習方法,檢測和識別,效率高,易于使用。
特定的深度學習方法,如CRNN和STN能取得良好的結果,但“太新,不能信任”。
在這篇文章中,我們可以說,特定的深度學習方法已經成熟,并且在研究和實踐中都占據主導地位。
任務
在上一篇文章中,我們使用了一些例子,它們在當前狀態下看起來可能很簡單:車牌識別,驗證碼識別等等。今天的模型更有效,我們可以討論更困難的任務,例如:
解析截圖
解析商業手冊
數字媒體解析
街道文本檢測
Pipeline
在OCR上應用標準的目標檢測和分割方法后,方法開始變得更加具體,并針對文本屬性:
文本是同構的,文本的每個子部分仍然是文本
文本可能在不同的層次上被檢測到,字符,單詞,句子,段落等。
因此,現代的OCR方法“隔離”特定的文本特征,并使用不同模型的“pipeline”來處理它們。
在這里,我們將專注于一個特定的設置,實際上是一個模型pipeline,除了視覺模型(特征提取器),還有一些更有用的組件:
Pipeline的圖
Pipeline的第一個部分是文本檢測。顯然,如果要使用不同的部分的文本,在識別實際字符之前檢測文本的位置可能是個好主意。這部分是與其他部分分開訓練的。
Pipeline的第二個部分是可選的:轉換層。它的目標是處理各種扭曲的文本,并將其轉換為更“常規”的格式(參見pipeline圖)。
第三部分是視覺特征提取器,它可以是你最喜歡的深度模型。
Pipeline的第四個部分是RNN,它的目的是學習重復的文本序列。
第五部分也就是最后一部分是CTC的損失。最近的文章用注意機制取代了它。
該pipeline除了檢測部分外,大多是端到端訓練,以減少復雜性。
Pipeline的問題
Pipeline中有不同的組件是很好的,但是它有一些缺點。每個組件都有它自己的偏差和超參數集,這導致了另一個層次的復雜性。
數據集
眾所周知,所有好的數據科學工作的基礎都是數據集,而在OCR中,數據集是至關重要的:選擇的訓練和測試數據集對結果有重要的影響。多年來,OCR任務在十幾種不同的數據集中進行了磨礪。然而,它們中的大多數并沒有包含超過幾千張帶標注的圖像,這對于擴展來說似乎不夠。另一方面,OCR任務是最容易使用合成數據的任務之一。
讓我們看看有哪些重要的數據集可用:
“真實” 數據集
一些數據集利用了谷歌街景。這些數據集可以被劃分為規則或不規則(扭曲的、有角度的、圓角的)文本。
SVHN— 街景編號,我們在上一篇文章的例子中使用過。
SVT— 街景文字,文字圖像來自谷歌街景。
ICDAR(2003, 2013,2015, 2019) — 為ICDAR和競賽創建的一些數據集,具有不同的重點。例如,2019年的數據集被稱為“任意形狀的文本”,這意味著,無論它變得多么不規則都有可能。
生成數據集
目前流行的合成數據集有兩種,它們在大多數OCR工作中被使用。不一致的使用使得作品之間的比較具有挑戰性。
MJ Synth— 包括相對簡單的單詞組成。數據集本身包括~9M的圖像。
Synthtext— 具有更復雜的機制,它在第一階段應用分割和圖像深度估計,然后在推斷的表面上“種出”文本。數據集本身包含約5.5M的圖像。
DALL-E — 這有點不確定,但是文本圖像生成(可能還有OCR)的未來似乎更加趨向于無監督。
這些合成數據集還擅長生成不同的語言,甚至是比較難的語言,比如漢語、希伯來語和阿拉伯語。
度量
在討論具體的研究論文之前,我們需要確定成功的標準。顯然有不止一種選擇。
首先,讓我們考慮一下文本檢測的方式,它可以使用標準的目標檢測指標,如平均平均精度,甚至標準精度和召回。
現在到了有趣的部分:識別。有兩個主要的指標:單詞級別的準確性和字符級別的準確性。特定的任務可能需要更高的準確性(例如文本塊的準確性)。目前最先進的方法在具有挑戰性的數據集上顯示了80%的準確性(我們將在后面討論)。
字符級別本身用“歸一化編輯距離”來封裝,該距離度量單詞之間相似字符的比例。
研究論文
在這篇文章中,我們關注的是最佳實踐,而不是構想。我建議你去看看篇綜述:https://arxiv.org/pdf/1811.04256.pdf,你會發現有很多方法讓你很難做出選擇。
場景文本識別的問題是什么?
這個工作名字很不一樣,文章https://arxiv.org/abs/1904.01906本身也很出色。這是一種前瞻性的調研,內容有:
定義統一的訓練和測試集(經過一些優化后)。
在數據集上測試基準的最佳實踐。
對方法進行邏輯結構的整理,并“幫助”讀者理解使用什么方法。
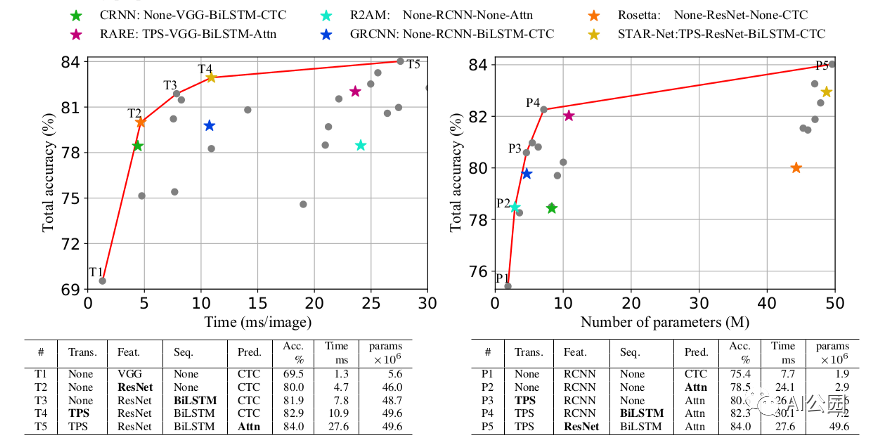
固定測試集上OCR pipeline的分類
所以本文的重點是:
對于OCR來說,訓練數據集(可能被認為是“最好的”)是兩個合成數據集:MJ和Synthtext。此外,重要的特征不是數量而是多樣性(減少數據量不會對模型的性能造成太大的影響,但刪除一個數據集卻會造成太大的影響)
測試數據集約為5個真實世界數據集。
論文論證了隨著每次pipeline的更新,結果逐漸改善。最顯著的改進是從VGG到ResNet特征提取器的改動,精度從60%提高到80%。RNN和歸一化的補充將模型推高到了83%。CTC到注意力更新增加了1%的準確性,但推理時間增加了三倍。

文本檢測
在本文的大部分內容中,我們將討論文本識別,但你可能還記得,pipeline的第一部分是文本檢測。實現當前這一代的文本檢測模型有點棘手。以前,文本檢測作為目標檢測的一個分支。然而,目標檢測有一些設置是通用的目標,如汽車,人臉等。當引入文本檢測時,需要進行一些重要的更新。
其實質是文本既具有同質性,又具有局部性。這意味著,一方面,文本的每個部分都是文本本身,另一方面,文本的子集應該統一到更大的類別上(如把字符統一為單詞)。因此,基于分割的方法比基于目標檢測的方法更適合于文本檢測。
CRAFT
我們最喜歡的目標檢測方法被稱為CRAFT — Character Region Awareness for Text Detection,它也被集成到easy OCR中。該方法應用了一個簡單的分割網絡,很好地使用了真實圖像和合成圖像,以及字符級和單詞級的標注。
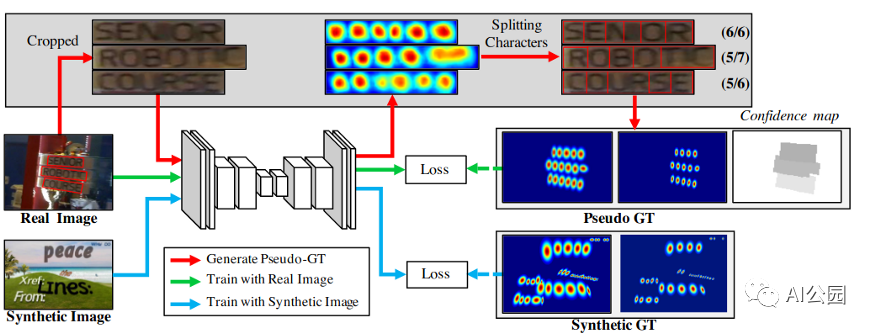
CRAFT模型概要
該模型在P和R上的h均值約為80%,在大多數數據集上也有很好的分詞效果,使模型的識別更加容易。
實際的例子
我們已經到了實際應用的階段。你應該用什么?所以我們已經在前面回答了這個問題(Easy OCR…),但是讓我們查看一些流行的解決方案。
開源
需要注意的一件非常重要的事情是,盡管OCR受到學術界缺乏健壯性的影響,但它卻享受著開源軟件的繁榮,它允許研究人員和實踐者在彼此的工作基礎上進行構建。以前的開源工具(如Tesseract,見下文)在數據收集和從頭開始的開發中遇到了困難。最近的庫,比如Easy OCR,通過一組構建塊,從數據生成到所有pipeline模型上可以有更多的調整。
工具
Tesseract
在很長一段時間里,Tesseract OCR是領先的開源OCR工具(不考慮偶爾與論文相關的庫)。然而,這個工具是作為一個經典的計算機視覺工具構建的,并沒有很好地過渡到深度學習。
APIs
OCR是大型云提供商谷歌、亞馬遜和微軟的一些早期計算機視覺API。這些API并不共享它們的能力基準,所以測試成為了我們的責任。
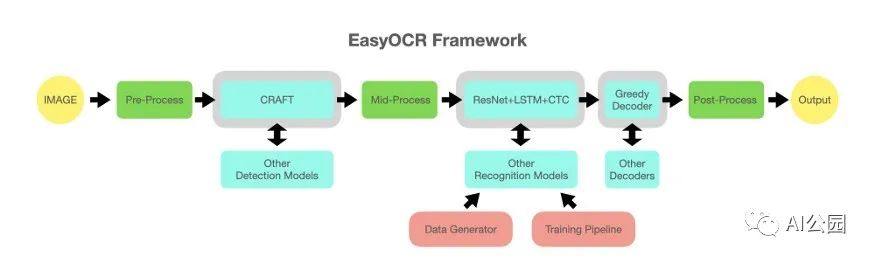
Easy OCR
在某種程度上,Easy OCR包是這篇文章的驅動。從不同的構建塊構建一個開源的、最先進的工具的能力是很厲害的。
下面是它的工作原理:
使用MJ-Synth包生成數據。
用于檢測的CRAFT模型(見上圖)。
根據“what is wrong”的論文(見上文)訓練一個調整后的pipeline,用于文本識別。
其他優化。
多語言:如上所述,OCR包含一些NLP元素。因此,處理不同的語言有不同之處,但我們也可以從工藝模型(可能還有其他檢測模型)的多語言中受益。識別模型是特定于語言的,但訓練過程是相同的。
最后一個問題是性能,這使得它在這個階段成為“go to OCR tech” 。你可以從下面看到,它們甚至比付費API結果還要好。
在Easy OCR中需要改進的一點是調整能力:雖然語言選擇很容易,但是可以根據不同的目的改變模型和再訓練。在下一篇文章中,我們將展示如何做到這一點。
運行時間怎么樣?
OCR的推斷可能會很慢,這并不奇怪。檢測模型是一個標準的深度學習模型,在GPU上運行約1秒(每張圖像),而識別模型需要一遍又一遍的運行檢測。在GPU上,一個包含許多目標的圖像可能需要幾十秒,更不用說CPU了。如果你想在你的手機或PC應用程序上運行OCR,使用較弱的硬件呢?
Easy OCR可以讓你學到:首先,這個庫引入了一些技巧,使推理更快(例如更緊湊的圖像切片形狀用于目標識別)。此外,由于是模塊化的,你可以(目前需要一些代碼調整)集成你自己的模型,這樣就可以更小更快。
代碼樣例
因此,在討論了不同的包和模型之后,是時候見證實際的結果了。這個notebook:https://colab.research.google.com/drive/1kNwHLmAtvwQjesqNZ9BenzRzXT9_S80W嘗試了Easy OCR vs Google OCR vs Tesseract的對比,我選擇了2張圖像:

一種是常見的OCR case —— 來自文檔的標準結構化文本,另一種是具有挑戰性的書籍封面集合:多種字體、背景、朝向(不是很多)等等。
我們將嘗試三種不同的方法:Easy OCR、Google OCR API(在大型技術云API中被認為是最好的)和古老的Tesseract。

在這類文本上,Tesseract和Google OCR的性能是完美的。這是有意義的,因為Google OCR可能在某種程度上基于Tesseract。
注意Google OCR對于這種文本有一個特殊的模式 — DOCUMENT_TEXT_DETECTION,應該用這個,而不是標準的TEXT_DETECTION。
Easy OCR的準確率約為95%。
有挑戰的圖像
左:Google OCR,右:Easy OCR
總體而言,Easy OCR效果最好。具體來說,檢測部分捕獲了大約80%的目標,包括非常具有挑戰性的對角線目標。
Google OCR更糟,大約60%。
在識別方面,他們在字符級別上的識別率約為70%,這使得他們在單詞或書的級別上識別率不高。看起來,Google OCR在單本書上沒有100%正確的,而Easy OCR有一些可以。
我注意到的另外一件事是,Easy OCR在字符級別上表現更好,Google OCR在單詞級別上更好 —— 這讓我認為它可能在后臺使用了字典。
英文原文:https://towardsdatascience.com/ocr-101-all-you-need-to-know-e6a5c5d5875b
編輯:jq
-
Str
+關注
關注
0文章
21瀏覽量
34902 -
OCR
+關注
關注
0文章
145瀏覽量
16395 -
提取器
+關注
關注
0文章
14瀏覽量
8124 -
rnn
+關注
關注
0文章
89瀏覽量
6899
原文標題:OCR:你想要了解的都在這兒了
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

PCB種類大全都在這了,小白速戳!
大研智造廠家面對面 關于激光焊錫機、錫球焊設備高頻問題QA,你想知道的都在這!

關于公路邊坡安全監測,你想知道的都在這里!
PCM能檢測到的最小信號是多少mV?我想了解PCM1863是否能配置待機狀態下做信號檢測

明治案例 | PE編織袋【大視野】【OCR識別】


5問5答!您想了解的數據采集DAQ關鍵指標都在這里了
干貨 購買無人叉車你必須知道的4條建議 都在這兒了
超快恢復二極管MURS120~MURS160

想了解芯片推力測試?點擊這里,了解最新測試方法!
想了解深圳高光譜成像儀的價格,找專業廠家就對了!





 工商網監
工商網監
評論