 圖的邏輯結構是怎樣的?如何去實現它?
圖的邏輯結構是怎樣的?如何去實現它?
經常有讀者問我「圖」這種數據結構,因為我們公眾號什么數據結構和算法都寫過了,唯獨沒有專門介紹「圖」。
其實在學習數據結構和算法的框架思維中說過,雖然圖可以玩出更多的算法,解決更復雜的問題,但本質上圖可以認為是多叉樹的延伸。
面試筆試很少出現圖相關的問題,就算有,大多也是簡單的遍歷問題,基本上可以完全照搬多叉樹的遍歷。
至于最小生成樹,Dijkstra,網絡流這些算法問題,他們當然很牛逼,但是,就算法筆試來說,學習的成本高但收益低,沒什么性價比,不如多刷幾道動態規劃,真的。
那么,本文依然秉持我們號的風格,只講「圖」最實用的,離我們最近的部分,讓你心里對圖有個直觀的認識。
圖的邏輯結構和具體實現
一幅圖是由節點和邊構成的,邏輯結構如下:
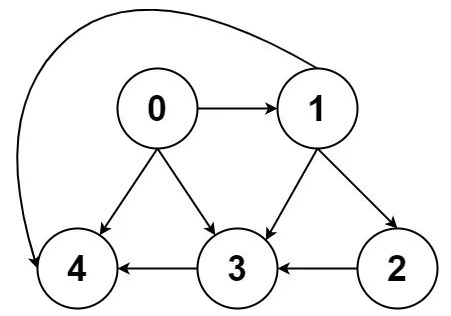
什么叫「邏輯結構」?就是說為了方便研究,我們把圖抽象成這個樣子。
根據這個邏輯結構,我們可以認為每個節點的實現如下:
/* 圖節點的邏輯結構 */class Vertex {
int id;
Vertex[] neighbors;
}
看到這個實現,你有沒有很熟悉?它和我們之前說的多叉樹節點幾乎完全一樣:
/* 基本的 N 叉樹節點 */class TreeNode {
int val;
TreeNode[] children;
}
所以說,圖真的沒啥高深的,就是高級點的多叉樹而已。
不過呢,上面的這種實現是「邏輯上的」,實際上我們很少用這個Vertex類實現圖,而是用常說的鄰接表和鄰接矩陣來實現。
比如還是剛才那幅圖:
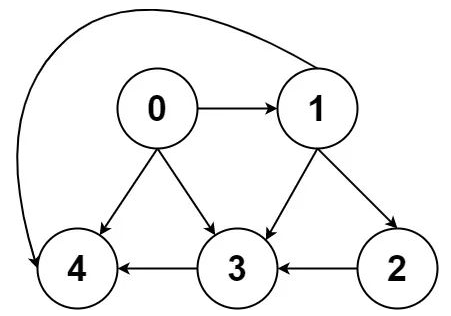
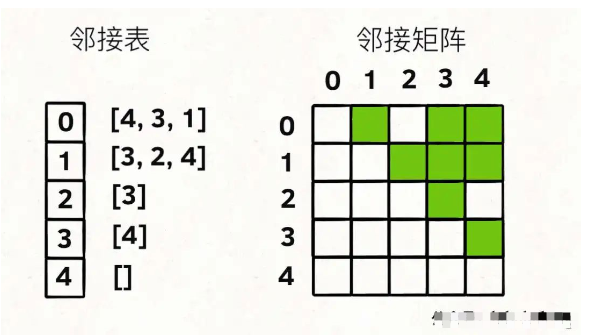
用鄰接表和鄰接矩陣的存儲方式如下:
鄰接表很直觀,我把每個節點x的鄰居都存到一個列表里,然后把x和這個列表關聯起來,這樣就可以通過一個節點x找到它的所有相鄰節點。
鄰接矩陣則是一個二維布爾數組,我們權且成為matrix,如果節點x和y是相連的,那么就把matrix[x][y]設為true。如果想找節點x的鄰居,去掃一圈matrix[x][。。]就行了。
那么,為什么有這兩種存儲圖的方式呢?肯定是因為他們各有優劣。
對于鄰接表,好處是占用的空間少。
你看鄰接矩陣里面空著那么多位置,肯定需要更多的存儲空間。
但是,鄰接表無法快速判斷兩個節點是否相鄰。
比如說我想判斷節點1是否和節點3相鄰,我要去鄰接表里1對應的鄰居列表里查找3是否存在。但對于鄰接矩陣就簡單了,只要看看matrix[1][3]就知道了,效率高。
所以說,使用哪一種方式實現圖,要看具體情況。
好了,對于「圖」這種數據結構,能看懂上面這些就綽綽夠用了。
那你可能會問,我們這個圖的模型僅僅是「有向無權圖」,不是還有什么加權圖,無向圖,等等……
其實,這些更復雜的模型都是基于這個最簡單的圖衍生出來的。
有向加權圖怎么實現?很簡單呀:
如果是鄰接表,我們不僅僅存儲某個節點x的所有鄰居節點,還存儲x到每個鄰居的權重,不就實現加權有向圖了嗎?
如果是鄰接矩陣,matrix[x][y]不再是布爾值,而是一個 int 值,0 表示沒有連接,其他值表示權重,不就變成加權有向圖了嗎?
無向圖怎么實現?也很簡單,所謂的「無向」,是不是等同于「雙向」?
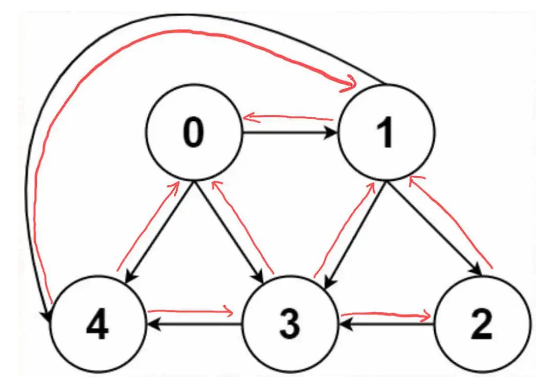
如果連接無向圖中的節點x和y,把matrix[x][y]和matrix[y][x]都變成true不就行了;鄰接表也是類似的操作。
把上面的技巧合起來,就變成了無向加權圖……
好了,關于圖的基本介紹就到這里,現在不管來什么亂七八糟的圖,你心里應該都有底了。
下面來看看所有數據結構都逃不過的問題:遍歷。
圖的遍歷
圖怎么遍歷?還是那句話,參考多叉樹,多叉樹的遍歷框架如下:
/* 多叉樹遍歷框架 */void traverse(TreeNode root) {
if (root == null) return;
for (TreeNode child : root.children)
traverse(child);
}
圖和多叉樹最大的區別是,圖是可能包含環的,你從圖的某一個節點開始遍歷,有可能走了一圈又回到這個節點。
所以,如果圖包含環,遍歷框架就要一個visited數組進行輔助:
Graph graph;
boolean[] visited;
/* 圖遍歷框架 */void traverse(Graph graph, int s) {
if (visited[s]) return;
// 經過節點 s
visited[s] = true;
for (TreeNode neighbor : graph.neighbors(s))
traverse(neighbor);
// 離開節點 s
visited[s] = false;
}
好吧,看到這個框架,你是不是又想到了 回溯算法核心套路 中的回溯算法框架?
這個visited數組的操作很像回溯算法做「做選擇」和「撤銷選擇」,區別在于位置,回溯算法的「做選擇」和「撤銷選擇」在 for 循環里面,而對visited數組的操作在 for 循環外面。
在 for 循環里面和外面唯一的區別就是對根節點的處理。
比如下面兩種多叉樹的遍歷:
void traverse(TreeNode root) {
if (root == null) return;
System.out.println(“enter: ” + root.val);
for (TreeNode child : root.children) {
traverse(child);
}
System.out.println(“leave: ” + root.val);
}
void traverse(TreeNode root) {
if (root == null) return;
for (TreeNode child : root.children) {
System.out.println(“enter: ” + child.val);
traverse(child);
System.out.println(“leave: ” + child.val);
}
}
前者會正確打印所有節點的進入和離開信息,而后者唯獨會少打印整棵樹根節點的進入和離開信息。
為什么回溯算法框架會用后者?因為回溯算法關注的不是節點,而是樹枝,不信你看 回溯算法核心套路 里面的圖,它可以忽略根節點。
顯然,對于這里「圖」的遍歷,我們應該把visited的操作放到 for 循環外面,否則會漏掉起始點的遍歷。
當然,當有向圖含有環的時候才需要visited數組輔助,如果不含環,連visited數組都省了,基本就是多叉樹的遍歷。
題目實踐
下面我們來看力扣第 797 題「所有可能路徑」,函數簽名如下:
List《List《Integer》》 allPathsSourceTarget(int[][] graph);
題目輸入一幅有向無環圖,這個圖包含n個節點,標號為0, 1, 2,。。。, n - 1,請你計算所有從節點0到節點n - 1的路徑。
輸入的這個graph其實就是「鄰接表」表示的一幅圖,graph[i]存儲這節點i的所有鄰居節點。
比如輸入graph = [[1,2],[3],[3],[]],就代表下面這幅圖:
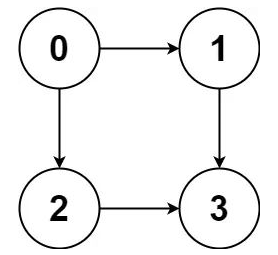
算法應該返回[[0,1,3],[0,2,3]],即0到3的所有路徑。
解法很簡單,以0為起點遍歷圖,同時記錄遍歷過的路徑,當遍歷到終點時將路徑記錄下來即可。
既然輸入的圖是無環的,我們就不需要visited數組輔助了,直接套用圖的遍歷框架:
// 記錄所有路徑
List《List《Integer》》 res = new LinkedList《》();
public List《List《Integer》》 allPathsSourceTarget(int[][] graph) {
LinkedList《Integer》 path = new LinkedList《》();
traverse(graph, 0, path);
return res;
}
/* 圖的遍歷框架 */void traverse(int[][] graph, int s, LinkedList《Integer》 path) {
// 添加節點 s 到路徑
path.addLast(s);
int n = graph.length;
if (s == n - 1) {
// 到達終點
res.add(new LinkedList《》(path));
path.removeLast();
return;
}
// 遞歸每個相鄰節點
for (int v : graph[s]) {
traverse(graph, v, path);
}
// 從路徑移出節點 s
path.removeLast();
}
這道題就這樣解決了。
最后總結一下,圖的存儲方式主要有鄰接表和鄰接矩陣,無論什么花里胡哨的圖,都可以用這兩種方式存儲。
在筆試中,最常考的算法是圖的遍歷,和多叉樹的遍歷框架是非常類似的。
當然,圖還會有很多其他的有趣算法,比如二分圖判定呀,環檢測呀(編譯器循環引用檢測就是類似的算法)等等,以后有機會再講吧,本文就到這了。
責任編輯:lq6
-
算法
+關注
關注
23文章
4625瀏覽量
93141 -
節點
+關注
關注
0文章
220瀏覽量
24471 -
數據結構
+關注
關注
3文章
573瀏覽量
40183
原文標題:為什么我沒寫過「圖」相關的算法?
文章出處:【微信號:TheAlgorithm,微信公眾號:算法與數據結構】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
LMH7322怎樣去改善輸出波形呢 ?
時序邏輯電路有哪些結構特點呢
數字邏輯怎么把邏輯圖畫成電路圖
邏輯電路與時序邏輯電路的區別
組合邏輯控制器是什么設備
組合邏輯控制器的基本概念、實現原理及設計方法
基于圖撲 HT for Web 實現拓撲關系圖
如何實現PLC的自動化控制邏輯
深入理解 FPGA 的基礎結構
STM32f3在main里面應該怎樣調用HAL庫實現帶PEC的基本傳輸?
SPWM調制方式是怎樣實現變壓功能的?又是怎樣實現變頻功能的?
通用陣列邏輯(GAL)電路結構設計分析






 工商網監
工商網監
評論