 超詳細EMNLP2020 因果推斷
超詳細EMNLP2020 因果推斷
引言
X,Y之間的因果性被定義為操作X,會使得Y發生改變。在很多領域如藥物效果預測、推薦算法有效性,因果性都有著重要作用。然而現實數據中,變量之間還會存在其他的相關關系(confounding)。如何從觀察獲得的數據中發現不同因素之間的因果關系則是統計學、機器學習和人工智能領域具有挑戰性的重要研究問題---統計推斷。
本次Fudan DISC實驗室將分享EMNLP 2020中有關因果推斷的3篇論文,介紹在不同任務下因果推斷方法的應用。
文章概覽
基于因果推理的邏輯相關多任務學習研究
Exploring Logically Dependent Multi-task Learning with Causal Inference
論文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.173
該篇文章從因果推理的角度出發,使用mediation assumption對邏輯依賴的MTL進行了研究。具體模型使用label transfer利用之前的低級邏輯依賴的任務label,以及Gumbel sampling方法來處理級聯錯誤。
腳本知識的因果推理
Causal Inference of Script Knowledge
論文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.612
該篇文章從概念和實踐的角度論證了純粹基于相關性的方法對于腳本知識歸納是不夠的,并提出了一種基于事件干預評估因果效應的腳本歸納方法。
使用因果關系消除偏見的法院意見生成
De-Biased Court’s View Generation with Causality
論文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.56
本文提出了一種新的基于注意力和反事實的自然語言生成方法(AC-NLG),該方法由一個注意力編碼器和一對反事實譯碼器組成。注意力編碼器利用原告的索賠和事實描述來學習索賠感知的編碼表示。反事實譯碼器被用來消除數據中的混淆偏差,并與協同的判決預測模型結合來生成法院意見。
論文細節
1

論文動機
以往的研究表明,分層多任務學習(MTL)可以通過堆疊編碼器和輸出形式的民主MTL來利用任務依賴性。然而,在邏輯相關的任務中,堆疊編碼器只考慮特征表示的依賴性,而忽略了標簽的依賴性。MLT的三種結構如下圖所示
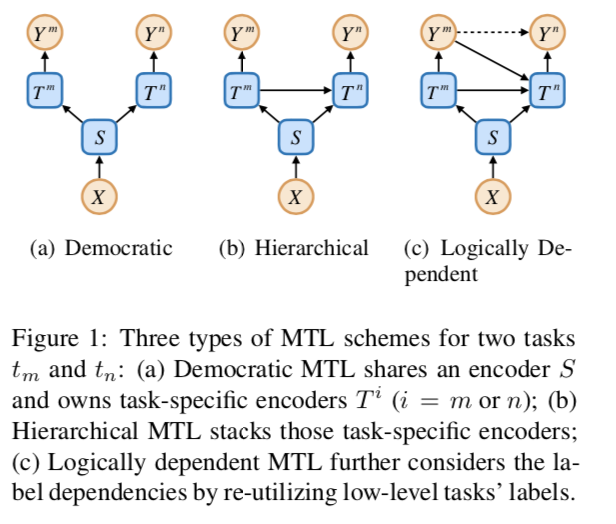
從因果關系的角度來看,前兩個方案假設ym和yn是條件獨立的,而第三個方案假設ym對yn有因果關系。在這篇文章中,作者認為因果關系對于邏輯相關的任務是重要的,并提出了一種稱為標簽轉移(label transfer,LT)的機制,使得一個任務可以利用其所有較低級別任務的標簽。
當使用前任務的標簽時,會引入訓練和測試的分歧問題。也就是說該策略在訓練中使用低水平任務的標注標簽,在測試中則需要使用預測的標簽,這樣會導致任務之間的級聯錯誤。本文使用Gumbel抽樣(GS)來解決這個問題。具體來說,模型從每個任務的預測概率分布中抽取一個標簽,并將其提供給更高級別的任務。抽樣可以看作是一個反事實推理過程,可以估計不同任務標簽之間的因果關系。如果因果效應存在,反向傳播的梯度將懲罰錯誤的預測。
方法
1. Basic Causal Assumptions
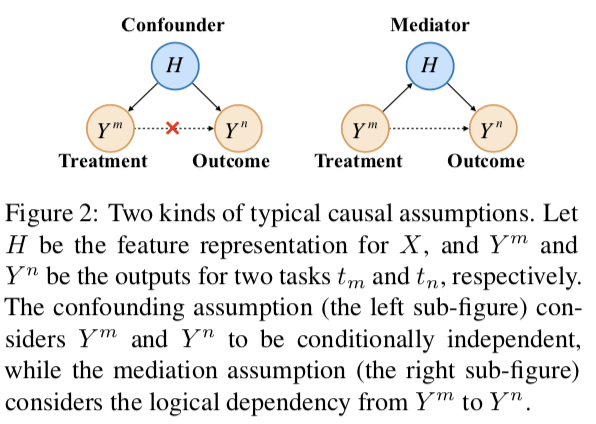
如上圖MTL有兩種可能的因果假設:confounding 和 mediation。confounding假設是,Ym和Yn是條件獨立的,僅由H決定。然而,對于邏輯相關的任務,文章使用mediation假設,即Ym對Yn有因果關系。具體來說,此假設包括Ym和Yn之間的兩條因果路徑。通過媒體H(實線),稱為間接效應。另一個直接鏈接Ym到Yn(虛線),稱為直接效果。一條是通過metiator H(實線)把Ym和Yn聯系起來的,稱為間接效應。另一個直接連接Ym到Yn(虛線),稱為直接效應。
2. Full Causal Graphs
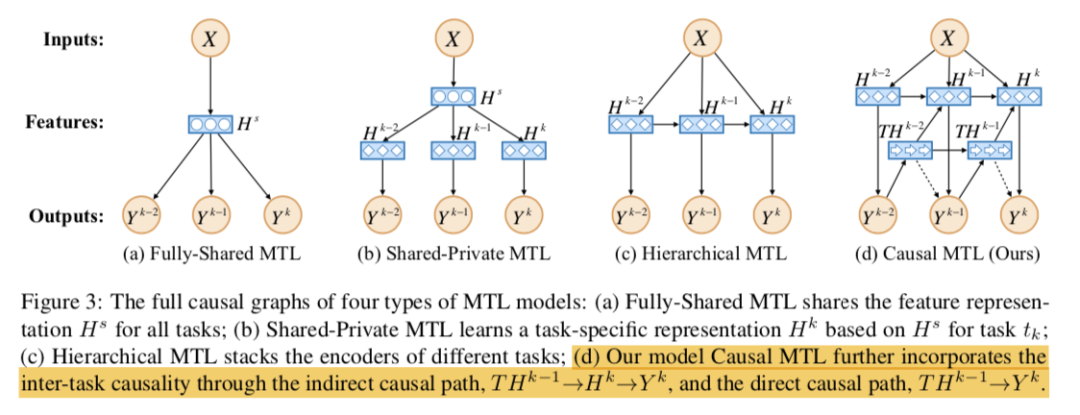
CMTL通過兩條路徑將任務間因果性結合起來。它首先創建一個中間變量傳達之前所有任務的標簽信息。然后該模型考慮了路徑→→的間接因果效應,還包括路徑→的直接因果效應。
3. Model Details
完整模型結構下圖所示。
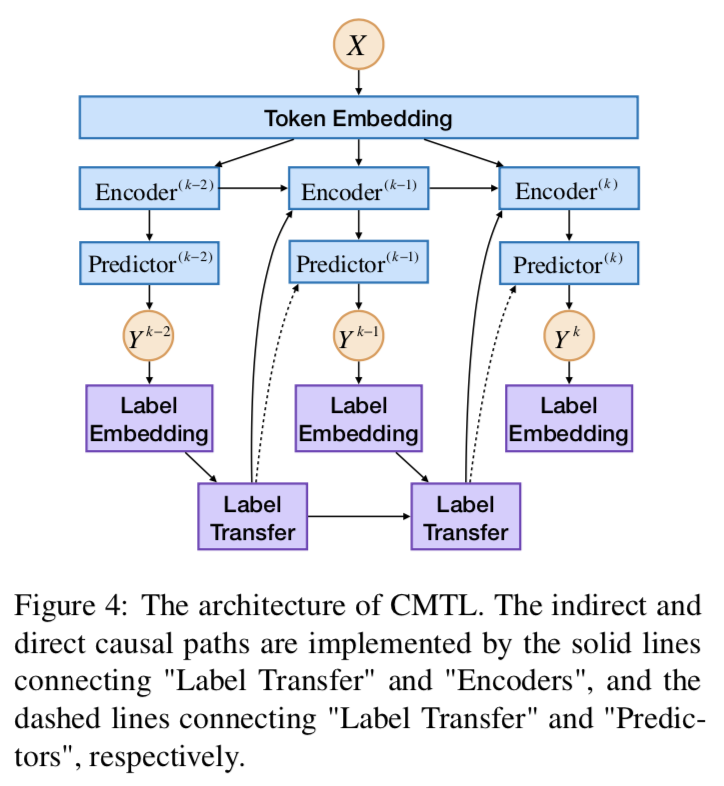
Label Transfer LT使用RNN-LSTM的結構來編碼:
**Encoders ** 然后將被送入編碼器。如圖所示,Encoder^(k) 的輸入包括三個部分:詞嵌入、轉移標簽和k-1層的輸出。輸出可表示為:
¥4f對于JERE和ABSA任務編碼器使用Bi-LSTM。對于LJP任務,先使用CNN編碼句子,隨后使用LSTM編碼標簽嵌入。
Gumbel Sampling GS使用重參數技巧來估計多項抽樣:
其中g符合Gumbel(0,1),是溫度參數。在訓練過程中將使用來代替標注標簽。這樣低水平的任務將有一定的概率抽樣一個反事實的值,如果因果關系確實存在,會從高水平的任務得到反饋。
4. 因果解釋
估計任務tm的標簽對任務tn的標簽的因果效應:
除了估計標簽的因果效應外,還可以檢驗X中n-grams元素的影響。對原始序列進行干預,得到另一個文本序列,其中n-gram 被屏蔽。由于n-gram可能非常稀疏,因此僅對單個因果效應進行了估計:
實驗結果
1. 主要結果
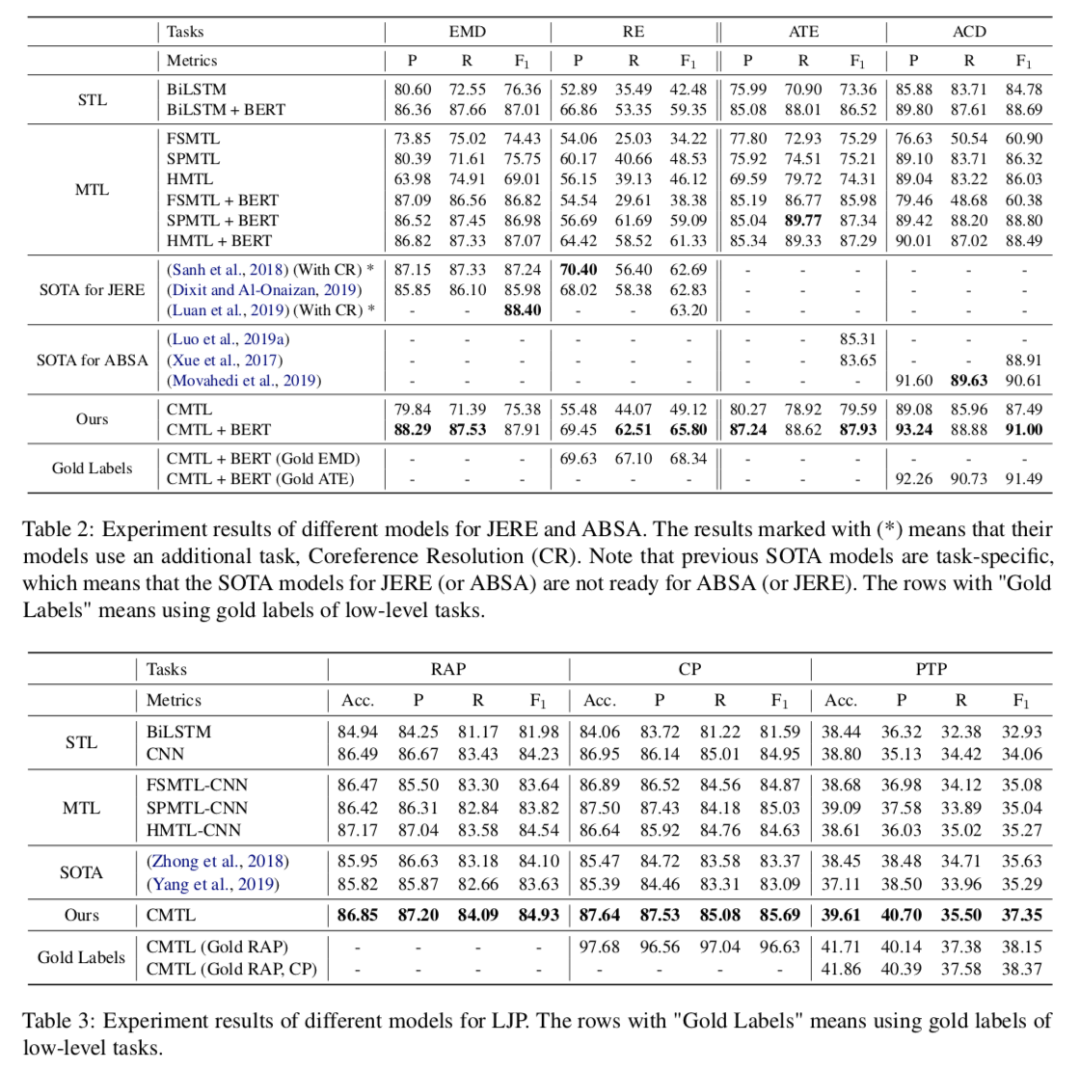
在三個任務上模型都有所提升。
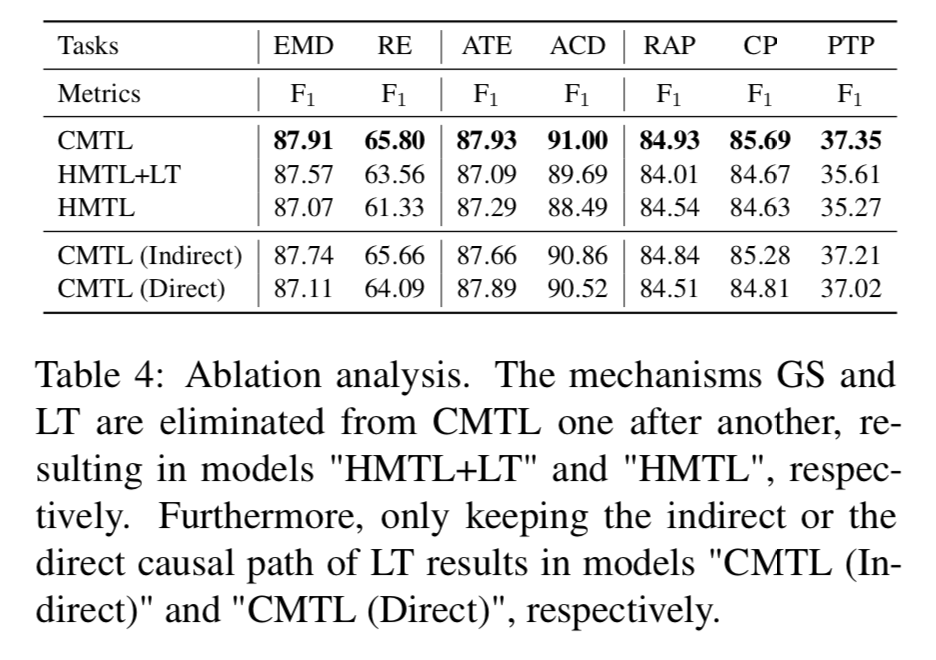
如圖所示,GS和LT對模型都是有影響的,特別是對于高水平的任務。例如,消除GS導致RE的F1得分下降2.24分,消除這兩種機制導致顯著下降4.47分。此外,文章保留了CMTL的間接因果路徑或直接因果路徑,分別記為CMTL(間接)和CMTL(直接)模型。兩種相關模型的性能都略差于CMTL。
2. 案例分析

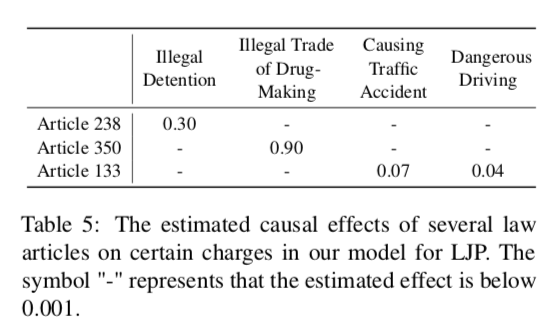
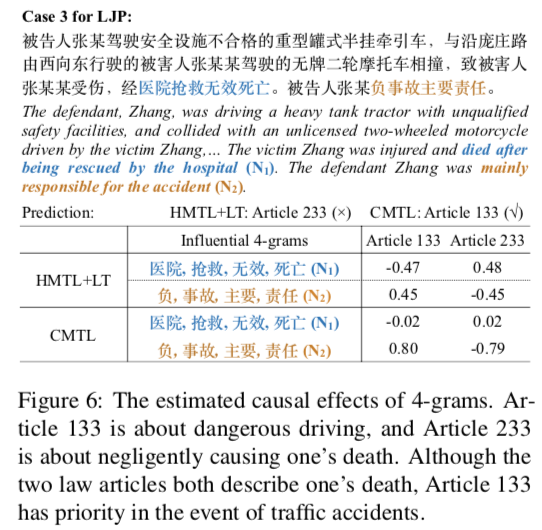
3. 因果效應估計
2

論文動機
長期以來典型事件序列所定義的日常情景的常識性知識,一直被認為在文本理解和理解中起著重要作用。通過數據驅動的方法從文本語料庫中學習這樣的知識需要確定定量度量標準。雖然觀察到的事件之間存在相關性,但相關性并不是決定事件是否形成有意義腳本的唯一因素。這篇文章則提出基于因果關系的方法,用于提取腳本知識。
方法
Step 1: Define a Causal Model
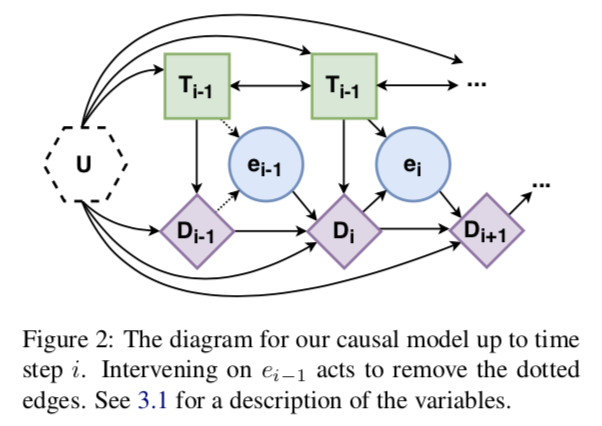
世界,U:生成數據的起點是真實世界,由未測量的變量U顯式表示。這個變量是不可知的,通常是不可測量的:我們不知道它是如何分布的,甚至不知道它是什么類型的變量。這個變量由圖2中的六邊形節點表示。
Text,T:下一種類型的變量是文本。將文本分割成塊T1,…,TN,其中N是文本中事件數。因此,變量Ti是與文本中提到的第i個事件相對應的文本塊。
事件推斷,e:讀取一段文本,并推斷文本中提到的事件類型。這個類型在模型中由變量 表示,其中E是一組可能的原子事件類型。文本直接因果影響推斷的時間類型,所以文本有指向事件的單向箭頭。
語篇表征,D:變量ei表示Ti中部分語義內容的高層次抽象。而文本中發生過事件以及它們之間的因果關系是人類閱讀時的核心部分,這種信息會顯著影響讀者基于事件的推理。因此,引入一個話語表征變量,它本身就是兩個子變量和的組合。
Step 2: Establishing Identifiability
由后門準則知道:
使用蒙特卡洛估計上述期望。
Step 3: Estimation
通過機器學習方法上述中的
Extracting Script Knowledge
令,則腳本相容分數(因果分數)為。
實驗結果
使用人工分別對事件對和事件鏈評分的結果如下:
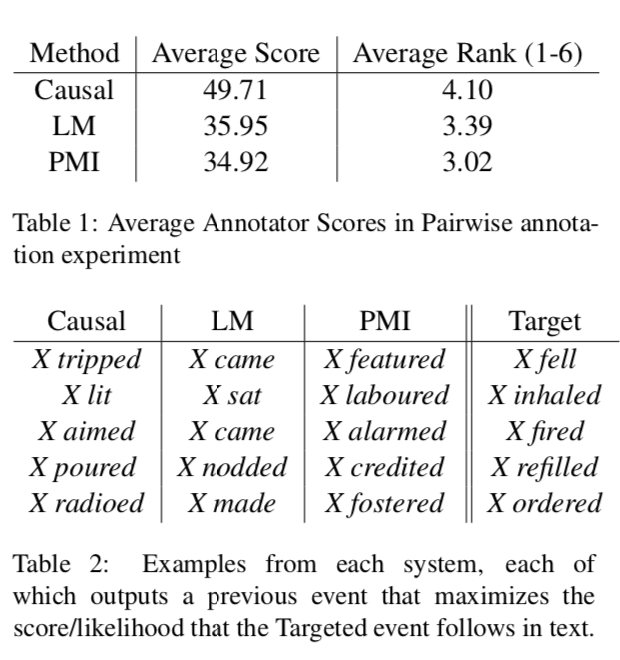
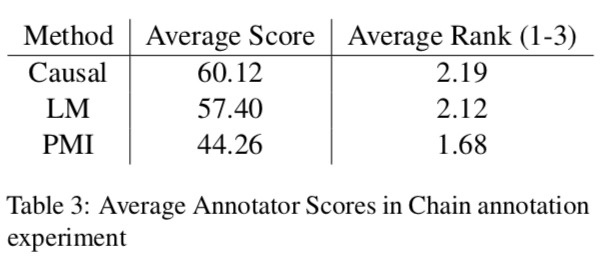
結果表明因果模型的分數更高。
3

論文動機
法院意見生成是法律人工智能的一項新穎而重要的任務,旨在提高判決預測結果的可解釋性,實現法律文書的自動生成。雖然先前的文本到文本的自然語言生成(NLG)方法可以用來解決這個問題,但是他們都忽略了數據生成機制中的混淆偏差,這樣會限制模型的性能,影響學習結果。主要挑戰有:1. 民事法律制度中的“無訴不審”原則,使得判決需要回應原告的索賠;2. 民事案件中判決的不平衡,由于原告只會在有很大把握的前提下提起訴訟,也就導致大部分的判決都是支持的,這樣就形成了數據分布不均。
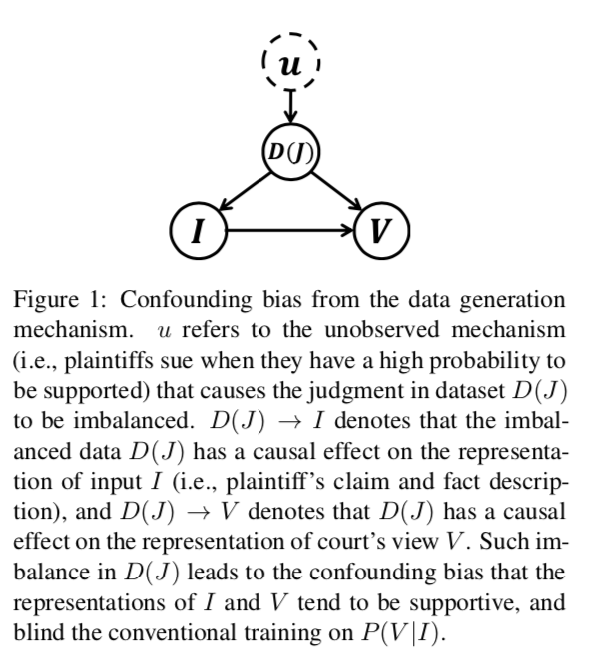
如上因果圖角度看,判決的不平衡揭示了數據生成機制導致的混淆偏見。這種不平衡的數據將導致輸入(索賠和公認事實)和輸出(法院觀點)的學習表示傾向于支持,導致輸入和輸出之間的混淆偏差,并影響傳統NLG模型的訓練。
針對這些問題,文章提出了一種基于注意力和反事實的自然語言生成(AC-NLG)方法,通過聯合優化一個索賠感知編碼器、一對反事實解碼器來生成判決分辨性法院意見和一個協同判決預測模型。
方法
Backdoor Adjustment
對于一般的生成任務,我們需要計算:如果 ,則 退化為 , 將會忽略 時的表示。后門調整是因果推理中的一個消除混淆的技術。后門調整對進行操作,將后驗概率從被動觀察提升到主動干預。后門調整通過計算介入后驗P(V | do(I))和控制混雜因子來解決混雜偏差:。后門調整切斷了和之間的依賴。
Backdoor In Implementation
實現過程中,使用一對反事實解碼器估計,使用判據預測模型估計。
Model Architecture
Claim-aware Encoder:原告的權利要求c和事實描述f是句子形式。因此,編碼器首先將單詞轉換為嵌入詞。然后將嵌入序列反饋給Bi-LSTM,產生兩個隱藏狀態序列hc、hf,分別對應于原告的請求和事實描述。之后,我們使用Claim-aware attention來融合hc和hf。對于hf中的每個隱藏狀態,是其對的注意權重,注意分布計算如下:
隨后產生新的事實描述表示:
經過Bi-LSTM層,得到最終表是。
Judgment Predictor:使用全連接層由h生成判決的概率預測:
Counterfactual Decoder:為了消除數據偏差的影響,使用一對反事實解碼器,其中包含兩個解碼器,一個用于支持的情況,另一個用于不支持的情況。這兩種譯碼器的結構相同,但目的是產生不同判決的法院觀點。運用了注意機制:在每個步驟t,給定編碼器的輸出和解碼狀態,注意力分布的計算方法與相同,但參數不同。上下文向量是h的加權和:
。上下文向量與解碼狀態相連接并送到線性層以產生詞匯分布:
實驗結果
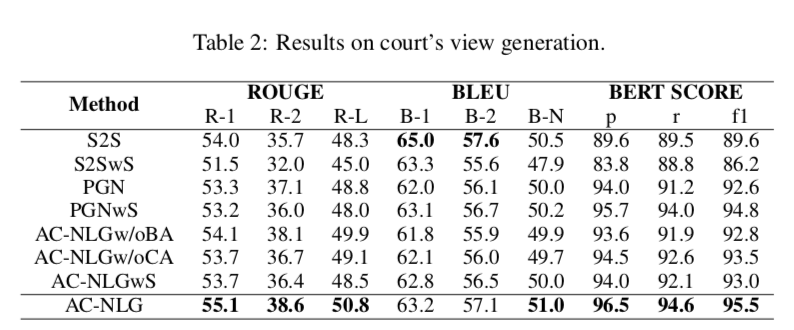
上圖顯示了法院意見生成的一些評估指標:ROUGE, BLEU, 和 BERT SCORE分數。可以得出:
(1)S2S傾向于重復單詞,這使得其BLEU得分較高,而BERT得分較低
(2) 過采樣策略對模型沒有好處,因此,它不能解決混淆偏差
(3) 與基準相比,AC-NLG具有索賠感知編碼器和后門反事實解碼器,在法庭視圖生成方面取得了更好的性能
(4) AC NLGw/oCA和AC-NLG之間的性能差距證明了索賠感知編碼器的有效性,AC NLGw/oBA和AC-NLG之間的差距說明了反事實解碼器的優越性。
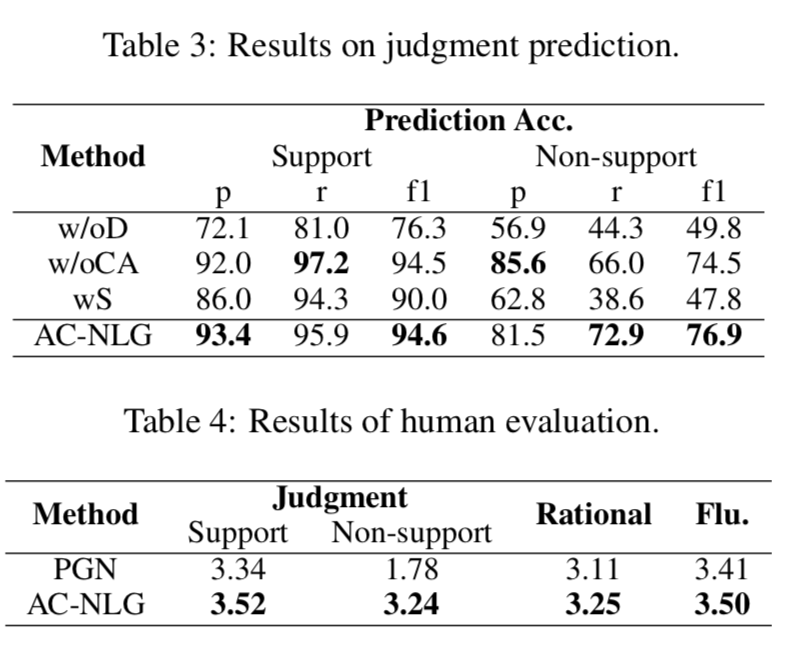
上圖顯示了判決預測準確率以及人類評估結果:
判據預測結果:
(1) 模型中反事實譯碼器可以顯著地消除混淆偏差,從而在不支持的情況下獲得顯著的改進,例如將f1從49.8%提高到76.9%
(2) 提出的索賠感知編碼器是為提高生成質量而設計的,對判決預測的影響有限。
(3) 過采樣并不能給模型帶來任何改進。
人類評估結果:
(1) 由于數據中的混雜偏差,PGN中的判決生成在無支持案例中的表現較差,支持案例和無支持案例之間的表現差距很大(1.56)
(2) 通過使用后門反事實解碼器,AC-NLG大大提高了判決生成的性能,特別是對于不支持的情況,并且在支持和不支持的情況之間實現了較小的性能差距(只有0.28)
(3) AC-NLG使用了一個支持索賠的編碼器,在理性和流暢性方面也取得了更好的性能

上圖展示了不同模型產生的法院觀點。
總結
此次 Fudan DISC 解讀的三篇論文圍繞因果推斷的應用。對于多任務學習,可以考慮任務標簽之間的因果性。對于抽取任務,可以考慮使用因果性評估來篩選想要的抽取內容。對于數據集有偏差的文本生成任務,因果推斷可以幫助消除混淆偏差。
編輯:jq
-
編碼器
+關注
關注
45文章
3648瀏覽量
134743 -
譯碼器
+關注
關注
4文章
311瀏覽量
50381 -
自然語言
+關注
關注
1文章
288瀏覽量
13360
原文標題:EMNLP2020 因果推斷
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種基于因果路徑的層次圖卷積注意力網絡

鑒源實驗室·測試設計方法-因果圖
經緯恒潤功能安全AI 智能體論文成功入選EMNLP 2024!

6a類網線是超6嗎

第19.1 章-星瞳科技 OpenMV視覺循跡功能 超詳細OpenMV與STM32單片機通信

當系統鬧脾氣:用「因果推斷」哄穩技術的心





 工商網監
工商網監
評論