 Linxu系統中文件系統的掛載方法和應用實例
Linxu系統中文件系統的掛載方法和應用實例
1.開場白
環境:處理器架構:arm64內核源碼:linux-5.11ubuntu版本:20.04.1代碼閱讀工具:vim+ctags+cscope
我們知道,Linux系統中我們經常將一個塊設備上的文件系統掛載到某個目錄下才能訪問這個文件系統下的文件,但是你有沒有思考過:為什么塊設備掛載之后才能訪問文件?掛載文件系統Linux內核到底為我們做了哪些事情?是否可以不將文件系統掛載到具體的目錄下也能訪問?下面,本文將詳細講解Linxu系統中,文件系統掛載的奧秘。
注:本文主要講解文件系統掛載核心邏輯,暫不涉及掛載命名空間和綁定掛載等內容(后面的內容可能會涉及),且以ext2磁盤文件系統為例講解掛載。本專題文章分為上下兩篇,上篇主要介紹掛載全貌以及具體文件系統的掛載方法,下篇介紹如何通過掛載實例關聯掛載點和超級塊。
2. vfs 幾個重要對象
在這里我們不介紹整個IO棧,只說明和文件系統相關的vfs和具體文件系統層。我們知道在Linux中通過虛擬文件系統層VFS統一所有具體的文件系統,提取所有具體文件系統的共性,屏蔽具體文件系統的差異。VFS既是向下的接口(所有文件系統都必須實現該接口),同時也是向上的接口(用戶進程通過系統調用最終能夠訪問文件系統功能)。
下面我們來看下,vfs中幾個比較重要的結構體對象:
2.1 file_system_type
這個結構來描述一種文件系統類型,一般具體文件系統會定義這個結構,然后注冊到系統中;定義了具體文件系統的掛載和卸載方法,文件系統掛載時調用其掛載方法構建超級塊、跟dentry等實例。
文件系統分為以下幾種:
1)磁盤文件系統
文件在非易失性存儲介質上(如硬盤,flash),掉電文件不丟失。
如ext2,ext4,xfs
2)內存文件系統
文件在內存上,掉電丟失。
如tmpfs
3)偽文件系統
是假的文件系統,是利用虛擬文件系統的接口(可以對用戶可見如proc、sysfs,也可以對用戶不可見內核可見如sockfs,bdev)。
如proc,sysfs,sockfs,bdev
4)網絡文件系統
這種文件系統允許訪問另一臺計算機上的數據,該計算機通過網絡連接到本地計算機。
如nfs文件系統
結構體定義源碼路徑:include/linux/fs.h +2226
2.2 super_block
超級塊,用于描述塊設備上的一個文件系統總體信息(如文件塊大小,最大文件大小,文件系統魔數等),一個塊設備上的文件系統可以被掛載多次,但是內存中只能有個super_block來描述(至少對于磁盤文件系統來說)。
結構體定義源碼路徑:include/linux/fs.h +1414
2.3 mount
掛載描述符,用于建立超級塊和掛載點等之間的聯系,描述文件系統的一次掛載,一個塊設備上的文件系統可以被掛載多次,每次掛載內存中有一個mount對象描述。
結構體定義源碼路徑:fs/mount.h +39
2.4 inode
索引節點對象,描述磁盤上的一個文件元數據(文件屬性、位置等),有些文件系統需要從塊設備上讀取磁盤上的索引節點,然后在內存中創建vfs的索引節點對象,一般在文件第一次打開時創建。
結構體定義源碼路徑:include/linux/fs.h +610
2.5 dentry
目錄項對象,用于描述文件的層次結構,從而構建文件系統的目錄樹,文件系統將目錄當作文件,目錄的數據由目錄項組成,而每個目錄項存儲一個目錄或文件的名稱和索引節點號等內容。每當進程訪問一個目錄項就會在內存中創建目錄項對象(如ext2路徑名查找中,通過查找父目錄數據塊的目錄項,找到對應文件/目錄的名稱,獲得inode號來找到對應inode)。
結構體定義源碼路徑:include/linux/dcache.h +90
2.6 file
文件對象,描述進程打開的文件,當進程打開文件時會創建文件對象加入到進程的文件打開表,通過文件描述符來索引文件對象,后面讀寫等操作都通過文件描述符進行(一個文件可以被多個進程打開,會由多個文件對象加入到各個進程的文件打開表,但是inode只有一個)。
結構體定義源碼路徑:include/linux/fs.h +915
3. 掛載總體流程
3.1系統調用處理
用戶執行掛載是通過系統調用路徑進入內核處理,拷貝用戶空間傳遞參數到內核,掛載委托do_mount。
//fs/namespace.c
SYSCALL_DEFINE5(mount
參數:
dev_name 要掛載的塊設備
dir_name 掛載點目錄
type 文件系統類型名
flags 掛載標志
data 掛載選項
-》 kernel_type = copy_mount_string(type); //拷貝文件系統類型名到內核空間
-》 kernel_dev = copy_mount_string(dev_name) //拷貝塊設備路徑名到內核空間-》 options = copy_mount_options(data) //拷貝掛載選項到內核空間
-》 do_mount(kernel_dev, dir_name, kernel_type, flags, options) //掛載委托do_mount
3.2 掛載點路徑查找
掛載點路徑查找,掛載委托path_mount
do_mount
-》 user_path_at(AT_FDCWD, dir_name, LOOKUP_FOLLOW, &path) //掛載點路徑查找 查找掛載點目錄的 vfsmount和dentry 存放在 path
-》 path_mount(dev_name, &path, type_page, flags, data_page) //掛載委托path_mount
3.3 參數合法性檢查
參數合法性檢查, 新掛載委托do_new_mount
path_mount
-》 參數合法性檢查
-》 根據掛載標志調用不同函數處理這里講解是默認 do_new_mount
3.4 調用具體文件系統掛載方法
do_new_mount
-》 type = get_fs_type(fstype) //根據傳遞的文件系統名 查找已經注冊的文件系統類型
-》 fc = fs_context_for_mount(type, sb_flags) //為掛載分配文件系統上下文 struct fs_context
-》 alloc_fs_context
-》 分配fs_context fc = kzalloc(sizeof(struct fs_context), GFP_KERNEL)
-》 設置 。..
-》 fc-》fs_type = get_filesystem(fs_type); //賦值相應的文件系統類型
-》 init_fs_context = **fc-》fs_type-》init_fs_context**; //新內核使用fs_type-》init_fs_context接口 來初始化文件系統上下文
if (!init_fs_context) //init_fs_context回掉 主要用于初始化
init_fs_context = **legacy_init_fs_context**; //沒有 fs_type-》init_fs_context接口
-》 init_fs_context(fc) //初始化文件系統上下文 (初始化一些回掉函數,供后續使用)
來看下文件系統類型沒有實現init_fs_context接口的情況:
//fs/fs_context.c
init_fs_context = legacy_init_fs_context
-》 fc-》ops = &legacy_fs_context_ops //設置文件系統上下午操作
-》.get_tree = legacy_get_tree //操作方法的get_tree用于 讀取磁盤超級塊并在內存創建超級塊,創建跟inode, 跟dentry
-》 root = fc-》fs_type-》mount(fc-》fs_type, fc-》sb_flags,
| fc-》source, ctx-》legacy_data) //調用文件系統類型的mount方法來讀取并創建超級塊
-》 fc-》root = root //賦值創建好的跟dentry
有一些文件系統使用原來的接口(fs_type.mount = xxx_mount):如ext2,ext4等
有一些文件系統使用新的接口(fs_type.init_fs_context = xxx_init_fs_context):xfs, proc, sys
無論使用哪一種,都會在xxx_init_fs_contex中實現 fc-》ops = &xxx_context_ops 接口,后面會看的都會調用fc-》ops.get_tree 來讀取創建超級塊實例
繼續往下走:
do_new_mount
-》 。..
-》 fc = fs_context_for_mount(type, sb_flags) //分配 賦值文件系統上下文
-》 parse_monolithic_mount_data(fc, data) //調用fc-》ops-》parse_monolithic 解析掛載選項
-》 mount_capable(fc) //檢查是否有掛載權限
-》 vfs_get_tree(fc) //fs/super.c 掛載重點 調用fc-》ops-》get_tree(fc) 讀取創建超級塊實例
。..
3.5 掛載實例添加到全局文件系統樹
do_new_mount
。..
-》 do_new_mount_fc(fc, path, mnt_flags) //創建mount實例 關聯掛載點和超級塊 添加到命名空間的掛載樹中
下面主要看下vfs_get_tree和do_new_mount_fc:
4.具體文件系統掛載方法
1)vfs_get_tree
//以ext2文件系統為例
vfs_get_tree //fs/namespace.c
-》 fc-》ops-》get_tree(fc)
-》 legacy_get_tree //上面分析過 fs_type-》init_fs_context == NULL使用舊的接口(ext2為NULL)
-》fc-》fs_type-》mount
-》 ext2_mount //fs/ext2/super.c 調用到具體文件系統的掛載方法
來看下ext2對掛載的處理:
啟動階段初始化-》
//fs/ext2/super.c
module_init(init_ext2_fs)
init_ext2_fs
-》init_inodecache //創建ext2_inode_cache 對象緩存
-》register_filesystem(&ext2_fs_type) //注冊ext2的文件系統類型static struct file_system_type ext2_fs_type = {
.owner = THIS_MODULE,
.name = “ext2”,
.mount = ext2_mount, //掛載時調用 用于讀取創建超級塊實例
.kill_sb = kill_block_super, //卸載時調用 用于釋放超級塊
.fs_flags = FS_REQUIRES_DEV, //文件系統標志為 請求塊設備,文件系統在塊設備上
};
掛載時調用-》
// fs/ext2/super.cstatic struct dentry *ext2_mount(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data)
{
return mount_bdev(fs_type, flags, dev_name, data, ext2_fill_super);
}
ext2_mount通過調用mount_bdev來執行實際文件系統的掛載工作,ext2_fill_super的一個函數指針作為參數傳遞給get_sb_bdev。該函數用于填充一個超級塊對象,如果內存中沒有適當的超級塊對象,數據就必須從硬盤讀取。
mount_bdev是個公用的函數,一般磁盤文件系統會使用它來根據具體文件系統的fill_super方法來讀取磁盤上的超級塊并在創建內存超級塊。
我們來看下mount_bdev的實現(**它執行完成之后會創建vfs的三大數據結構 super_block、根inode和根dentry **):
2)mount_bdev源碼分析
//fs/super.c
mount_bdev
-》bdev = blkdev_get_by_path(dev_name, mode, fs_type) //通過要掛載的塊設備路徑名 獲得它的塊設備描述符block_device(會涉及到路徑名查找和通過設備號在bdev文件系統查找block_device,block_device是添加塊設備到系統時創建的)
-》 s = sget(fs_type, test_bdev_super, set_bdev_super, flags | SB_NOSEC,
|bdev); //查找或創建vfs的超級塊 (會首先在文件系統類型的fs_supers鏈表查找是否已經讀取過指定的超級塊,會對比每個超級塊的s_bdev塊設備描述符,沒有創建一個)
-》 if (s-》s_root) { //超級塊的根dentry是否被賦值?
。..
} else { //沒有賦值說明時新創建的sb
。..
-》 sb_set_blocksize(s, block_size(bdev)) //根據塊設備描述符設置文件系統塊大小
-》 fill_super(s, data, flags & SB_SILENT ? 1 : 0) //調用傳遞的具體文件系統的填充超級塊方法讀取填充超級塊等 如ext2_fill_super
-》 bdev-》bd_super = s //塊設備bd_super指向sb
}
-》 return dget(s-》s_root) //返回文件系統的根dentry
可以看到mount_bdev主要是:1.根據要掛載的塊設備文件名查找到對應的塊設備描述符(內核后面操作塊設備都是使用塊設備描述符);2.首先在文件系統類型的fs_supers鏈表查找是否已經讀取過指定的vfs超級塊,會對比每個超級塊的s_bdev塊設備描述符,沒有創建一個vfs超級塊; 3.新創建的vfs超級塊,需要調用具體文件系統的fill_super方法來讀取填充超級塊。
那么下面主要集中在具體文件系統的fill_super方法,這里是ext2_fill_super:
分析重點代碼如下:
3)ext2_fill_super源碼分析
//fs/ext2/super.cstatic int ext2_fill_super(struct super_block *sb, void *data, int silent)
{
struct buffer_head * bh; //緩沖區頭 記錄讀取的磁盤超級塊
struct ext2_sb_info * sbi; //內存的ext2 超級塊信息
struct ext2_super_block * es; //磁盤上的 超級塊信息
。..
sbi = kzalloc(sizeof(*sbi), GFP_KERNEL); //分配 內存的ext2 超級塊信息結構
if (!sbi)
goto failed;
。..
sb-》s_fs_info = sbi; //vfs的超級塊 的s_fs_info指向內存的ext2 超級塊信息結構
sbi-》s_sb_block = sb_block;
if (!(bh = sb_bread(sb, logic_sb_block))) { // 讀取磁盤上的超級塊到內存的 使用buffer_head關聯內存緩沖區和磁盤扇區
ext2_msg(sb, KERN_ERR, “error: unable to read superblock”);
goto failed_sbi;
}
es = (struct ext2_super_block *) (((char *)bh-》b_data) + offset); //轉換為struct ext2_super_block 結構
sbi-》s_es = es; // 內存的ext2 超級塊信息結構的 s_es指向真正的ext2磁盤超級塊信息結構
sb-》s_magic = le16_to_cpu(es-》s_magic); //獲得文件系統魔數 ext2為0xEF53
if (sb-》s_magic != EXT2_SUPER_MAGIC) //驗證 魔數是否正確
blocksize = BLOCK_SIZE 《《 le32_to_cpu(sbi-》s_es-》s_log_block_size); //獲得磁盤讀取的塊大小
/* If the blocksize doesn‘t match, re-read the thing.。 */
if (sb-》s_blocksize != blocksize) { //塊大小不匹配 需要重新讀取超級塊
brelse(bh);
if (!sb_set_blocksize(sb, blocksize)) {
ext2_msg(sb, KERN_ERR,
“error: bad blocksize %d”, blocksize);
goto failed_sbi;
}
logic_sb_block = (sb_block*BLOCK_SIZE) / blocksize;
offset = (sb_block*BLOCK_SIZE) % blocksize;
bh = sb_bread(sb, logic_sb_block); //重新 讀取超級塊
if(!bh) {
ext2_msg(sb, KERN_ERR, “error: couldn’t read”
“superblock on 2nd try”);
goto failed_sbi;
}
es = (struct ext2_super_block *) (((char *)bh-》b_data) + offset);
sbi-》s_es = es;
if (es-》s_magic != cpu_to_le16(EXT2_SUPER_MAGIC)) {
ext2_msg(sb, KERN_ERR, “error: magic mismatch”);
goto failed_mount;
}
}
sb-》s_maxbytes = ext2_max_size(sb-》s_blocksize_bits); //設置最大文件大小
。..
//讀取或設置 inode大小和第一個inode號
if (le32_to_cpu(es-》s_rev_level) == EXT2_GOOD_OLD_REV) {
sbi-》s_inode_size = EXT2_GOOD_OLD_INODE_SIZE;
sbi-》s_first_ino = EXT2_GOOD_OLD_FIRST_INO;
} else {
sbi-》s_inode_size = le16_to_cpu(es-》s_inode_size);
sbi-》s_first_ino = le32_to_cpu(es-》s_first_ino);
。..
}
。..
sbi-》s_blocks_per_group = le32_to_cpu(es-》s_blocks_per_group); //賦值每個塊組 塊個數
sbi-》s_frags_per_group = le32_to_cpu(es-》s_frags_per_group);
sbi-》s_inodes_per_group = le32_to_cpu(es-》s_inodes_per_group); //賦值每個塊組 inode個數
sbi-》s_inodes_per_block = sb-》s_blocksize / EXT2_INODE_SIZE(sb); //賦值每個塊 inode個數
。..
sbi-》s_desc_per_block = sb-》s_blocksize /
sizeof (struct ext2_group_desc); //賦值每個塊 塊組描述符個數
sbi-》s_sbh = bh; //賦值讀取的超級塊緩沖區
sbi-》s_mount_state = le16_to_cpu(es-》s_state); //賦值掛載狀態
。..
if (sb-》s_magic != EXT2_SUPER_MAGIC)
goto cantfind_ext2;
//一些合法性檢查
。..
//計算塊組描述符 個數
sbi-》s_groups_count = ((le32_to_cpu(es-》s_blocks_count) -
le32_to_cpu(es-》s_first_data_block) - 1)
/ EXT2_BLOCKS_PER_GROUP(sb)) + 1;
db_count = (sbi-》s_groups_count + EXT2_DESC_PER_BLOCK(sb) - 1) /
| EXT2_DESC_PER_BLOCK(sb);
sbi-》s_group_desc = kmalloc_array(db_count,
| sizeof(struct buffer_head *),
| GFP_KERNEL); //分配塊組描述符 bh數組
for (i = 0; i 《 db_count; i++) { //讀取塊組描述符
block = descriptor_loc(sb, logic_sb_block, i);
sbi-》s_group_desc[i] = sb_bread(sb, block); //讀取的 塊組描述符緩沖區保存 到sbi-》s_group_desc[i]
if (!sbi-》s_group_desc[i]) {
for (j = 0; j 《 i; j++)
brelse (sbi-》s_group_desc[j]);
ext2_msg(sb, KERN_ERR,
“error: unable to read group descriptors”);
goto failed_mount_group_desc;
}
}
sb-》s_op = &ext2_sops; //賦值超級塊操作
。..
root = ext2_iget(sb, EXT2_ROOT_INO); //讀取根inode (ext2 根根inode號為2)
sb-》s_root = d_make_root(root); //創建根dentry 并建立根inode和根dentry關系
ext2_write_super(sb); //同步超級塊信息到磁盤 如掛載時間等
可以看到ext2_fill_super主要工作為:
1.讀取磁盤上的超級塊;
2.填充并關聯vfs超級塊;
3.讀取塊組描述符;
4.讀取磁盤根inode并建立vfs 根inode;
5.創建根dentry關聯到根inode。
下面給出ext2_fill_super之后ext2相關圖解:
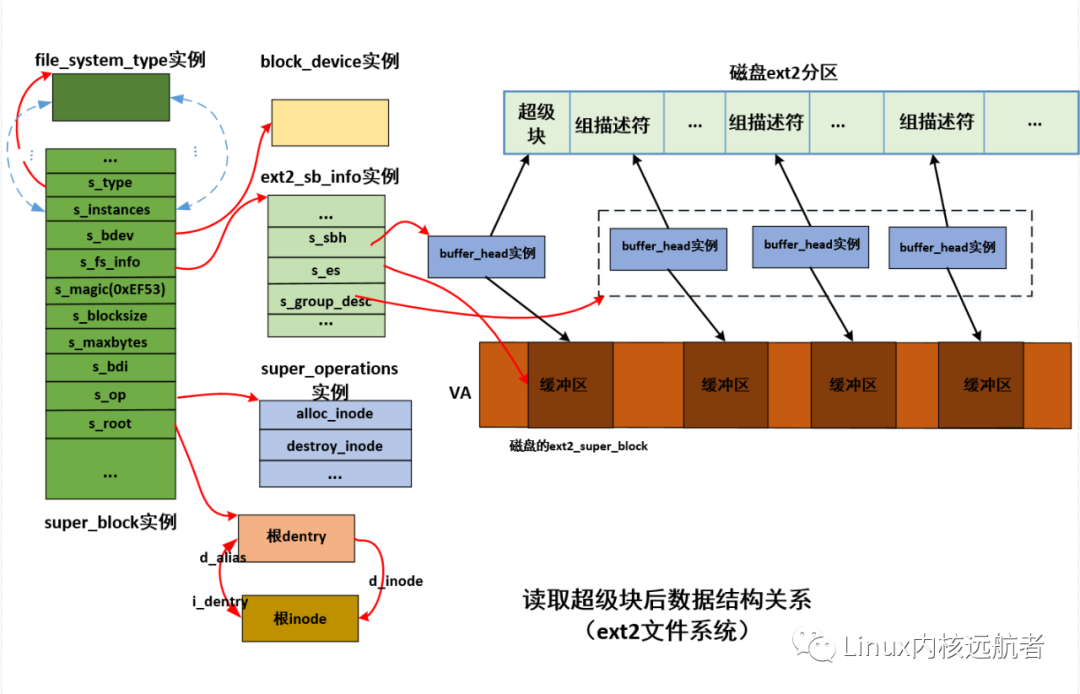
有了這些信息,雖然能夠獲得塊設備上的文件系統全貌,內核也能通過已經建立好的block_device等結構訪問塊設備,但是用戶進程不能真正意義上訪問到,用戶一般會通過open打開一個文件路徑來訪問文件,但是現在并沒有關聯掛載目錄的路徑,需要將文件系統關聯到掛載點,以至于路徑名查找的時候查找到掛載點后,在轉向文件系統的根目錄,而這需要通過do_new_mount_fc來去關聯并加入全局的文件系統樹中,下一篇我們將做詳細講解。
文章出處:【微信公眾號:Linux閱碼場】
責任編輯:gt
-
處理器
+關注
關注
68文章
19384瀏覽量
230511 -
接口
+關注
關注
33文章
8669瀏覽量
151549 -
linxu
+關注
關注
0文章
7瀏覽量
2571
原文標題:深入理解Linux文件系統之文件系統掛載(上)
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
防止根文件系統破壞,OverlayRootfs 讓你的設備更安全

服務器數據恢復—V7000存儲NTFS文件系統數據恢復案例
Linux根文件系統的掛載過程
想提高開發效率,不要忘記文件系統
如何修改buildroot和debian文件系統
linux--sysfs文件系統






 工商網監
工商網監
評論