 你真的了解Zynq的學習嗎?
你真的了解Zynq的學習嗎?
一、簡介部分
Zynq是由兩個主要部分組成的:一個是由雙核 ARM CortexA9 構成的處理系統 (PS),另一個是等價于一片 FPGA 的可編程邏輯 (PL)。它還具有集成的存儲器、各種外設和高速通信接口。這個架構實現了工業標準的 AXI 接口,在芯片的兩個部分之間實現了高帶寬、低延遲的連接。
PL 部分用來實現高速邏輯、算術和數據流子系統是很理想的,而 PS 支持軟件程序或操作系統,具有固定的架構,承載了處理器和系統存儲區。這就意味著任何被設計的系統的整個功能可以恰當地在硬件和軟件之間做出劃分。
PL 和 PS 之間的鏈接采用了工業標準的高級可擴展接口(Advanced eXtensible Interface,AXI)連接方式。這兩部分可以單獨使用,也可以合起來用,而且實際上供電電路被設計成獨立給每個部分供電,這樣 PS 或 PL 部分不被使用的話就可以被斷電。
二、處理器系統部分(PS)
作為處理器系統的基礎,所有的芯片都包含了一顆雙核 ARM Cortex-A9 處理器。這是一顆“ 硬 ”處理器 —— 它是芯片上專用而且優化過的硅片元件。Xilinx 的MicroBlaze這樣的“軟” 處理器,是由可編程邏輯部分的單元組合而成的。
也就是說,一個軟處理器的實現和部署在 FPGA 的邏輯結構里的任何其他 IP 核是等價的。一般來說,軟處理器的優勢是處理器實例的數量和精確實現是靈活的。從另一方面來說,硬處理器可以獲得相對較高的性能,Zynq 的 ARM 處理器正是如此。
Zynq 的處理器系統里并非只有 ARM 處理器,還有一組相關的處理資源,形成了一個應用處理器單元 (Application Processing Unit,APU) ,另外還有擴展外設接口、cache 存儲器、存儲器接口、互聯接口和時鐘發生電路 。下圖是 PS 部分架構框圖,其中高亮的部分就是 APU。
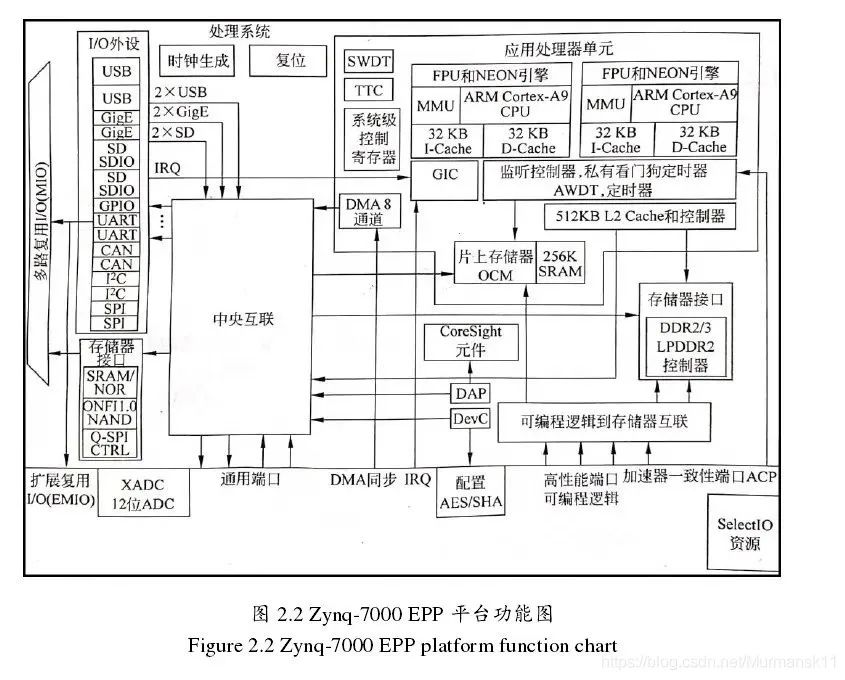
2.1 應用處理單元(APU)
APU 主要是由兩個 ARM 處理核組成的:最高工作頻率1GHz;
一個 NEONTM 媒體處理引擎(Media Processing Engine,MPE)和浮點單元 (Floating Point Unit,FPU);
一個內存管理單元 (MemoryManagement Unit,MMU);在虛擬地址和物理地址之間做翻譯;
一個一級 cache 存儲器(分為指令和數據兩個部分)APU 里還有一個二級 cache 存儲器;高速緩沖,在CPU與內存儲器之間;
片上存儲器 (On Chip Memory,OCM);
一致性控制單元 (Snoop Control Unit,SCU);在ARM和二級cache,OCM之間形成橋連接;
2.2 處理器系統外部接口
Zynq PS 實現了眾多接口,既有 PS 和 PL 之間的,也有 PS 和外部部件之間的。
(1)PS和外部接口之間的通信
PS 和外部接口之間的通信主要是通過復用的輸入 / 輸出( Multiplexed Input/Output,MIO)實現的,它提供了可以做靈活配置的 54 個引腳,這表明外部設備和引腳之間的映射是可以按需定義的。
三、可編程邏輯部分(PL)
Zynq 架構的第二個主要部分是可編程邏輯。這是基于 Artix-7 和 Kintex-7的 FPGA 組件的。
3.1 邏輯部分
PL 主要是由通用 FPGA 邏輯部分組成的,這個 FPGA 是由邏輯片(slice)和可配置邏輯塊 (Configurable Logic Block,CLB)組成的,另外還有用于接口的輸入/輸出塊 (Input/ Output Block,IOB)
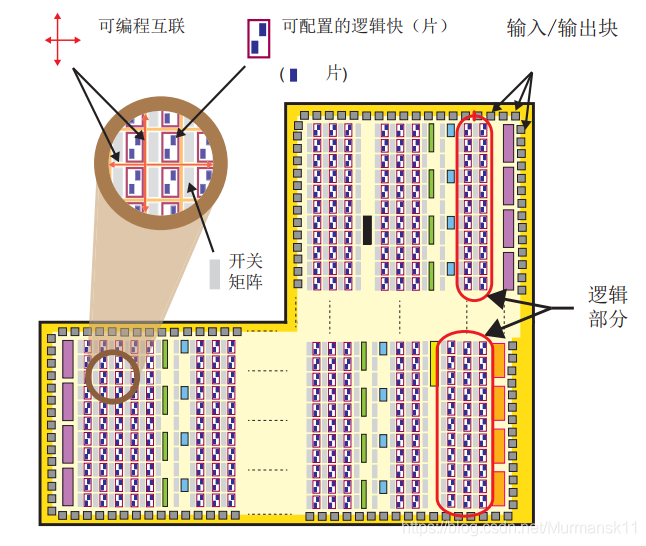
? 可配置邏輯塊 (CLB) — CLB 是邏輯單元的小規模、普通編組,在 PL 中排列為一個二維陣列,通過可編程互聯連接到其他類似的資源。每個 CLB 里包含兩個邏輯片(slicem或slicel),并且緊鄰一個開關矩陣。
? 片 (Slice) — CLB 里的一個子單元,里面有實現組合和時序邏輯電路的資源。Zynq 的片是由 4 個查找表、8 個觸發器和其他一些邏輯所組成的。
? 查找表 (Lookup Table,LUT) — 一個靈活的資源,可以實現: 1.至多 6個輸入的邏輯函數;2.一小片只讀存儲器 (ROM);3.一小片隨機訪問存儲器 (RAM);4.一個移位寄存器。LUT 可以按需組合起來形成更大的邏輯函數、存儲器或移位寄存器。
? 觸發器(Flip-flop,FF) — 一個實現 1 位寄存的時序電路,帶有復位功能。FF 的一種用處是實現鎖存。
? 開關矩陣 (Switch Matrix) — 每個 CLB 旁都有一個開關矩陣,實現靈活的布線功能來1.連接 CLB 內的單元;2.把一個 CLB 與 PL 內的其他資源連接起來。
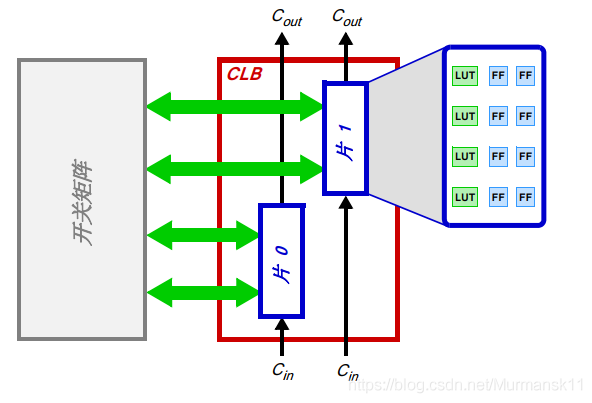
? 進位邏輯 (Carry Logic) — 算術電路需要在相鄰的片之間傳遞信號,這就是通過進位邏輯來實現的。進位邏輯把布線和復用器組成鏈條來連接一個垂直列上的片。
? 輸入 / 輸出塊 (Input/Output Blocks,IOB) — IOB 實現了 PL 邏輯資源之間的對接,并且提供物理設備 “ 焊盤 ” 來連接外部電路。每個 IOB 可以處理一位的輸入或輸出信號。IOB 通常位于芯片的周邊。
盡管邏輯部分的內部結構知識對于設計者是有用的,但是大多數情況下并不需要專門地指定這些資源 ——Xilinx 工具會自動根據設計來安排所需的 LUT、 FF、IOB 等,然后做好相應的映射。但我還是覺得對底層的電路結構有一個清楚的認識,對以后的學習會有很大的幫助。
3.2 特殊資源:DSP48E1和塊RAM
除了通用的部分,還有兩個特殊用途的部件:滿足密集存儲需要的塊 RAM 和用于高速算術的 DSP48E1 片。這兩個資源都按列排列集成在邏輯陣列中,嵌入在邏輯部分中,而且往往彼此靠近 (因為密集計算和在內存中存儲數據往往是緊密聯系的運算)。
每個塊 RAM 可以存儲最多 36KB 的信息,并且可以被配置為一個 36KB 的 RAM 或兩個獨立的 18KB RAM。默認的字寬是 18 位,這樣的配置下每個 RAM 含有 2048 個存儲單元2Kx18位。RAM 還可以被 “ 重塑 ” 來包含更多更小的單元(比如 4096 個單元 x9 位,或 8192x位),或是另外做成更少更長的單元(如 1024 單元 x36 位,512x72 位) 。把兩個或多個塊 RAM 組合起來可以形成更大的存儲容量。它們可實現 RAM、ROM 和先入先出 (First In First Out,FIFO)緩沖器,同時還支持糾錯編碼 (Error Correction Coding,ECC)塊 RAM 往往還能用芯片所支持的最高時鐘頻率來工作。
分布式 RAM (Distributed RAM) ,這是用邏輯部分里的 LUT 來搭建的。用分布式 RAM 實現小存儲器往往是有優勢的,既是因為資源利用率,也是因為這樣的布局更靈活 (分布式存儲可以靠近與之相互作用的部件,這樣也就能有更快的時序性能)。
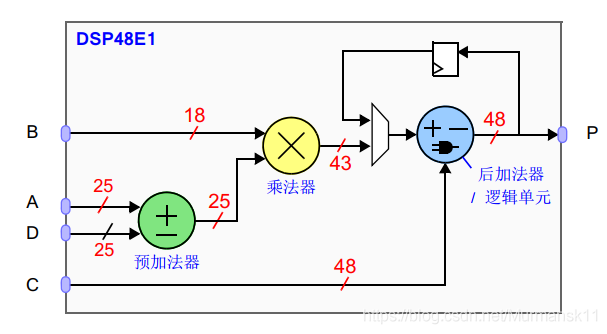
(2)DSP48E1
邏輯部分里的 LUT 可以用來實現任意長度的算術運算,但是最合適的是做短字長的算術運算 (長字長的算術電路會在邏輯片中占據較大的空間,這樣的布局和布線因素會使得時鐘頻率是次優的)。
DSP48E1是專門用于實現對長字長信號的高速算術運算的邏輯片。這些都是專用的硅片資源,并且在邏輯單元內主要包含了預加法器/減法器乘法器和后加法器/減法器。
四、處理器系統與可編程邏輯的接口
Zynq 的表現不僅僅依賴于它的兩個組成部分 PS 和 PL 的特性,還在于能把兩者協同起來形成完整、集成的系統的能力。這其中起關鍵作用的,是一組高度定制的 AXI 互聯和接口用來在兩個部分之間形成橋梁。
4.1 AXI標準
AXI 表示的是高級可擴展接口 (Advanced eXtensible Interface)AXI 總線可以靈活使用,而且一般情況下是用來在一個嵌入式系統中連接處理器和其他 IP 核的。實際上有三類 AXI4,每一類代表了一種不同的總線協議,下面會有總結。對于一個特定的連接選擇哪個 AXI 總線協議是基于那個連接所需的特性的。
? AXI4 — 用于存儲映射鏈接,它支持最高的性能:通過一簇高達 256 個數據字 (或 “ 數據拍 (data beats)”)的數據傳輸來給定一個地址。
? AXI4-Lite — 一種簡化了的鏈接,只支持每次連接傳輸一個數據(非批量) 。AXI4-Lite也是存儲映射的:這種協議下每次傳輸一個地址和單個數據。
? AXI4-Stream — 用于高速流數據,支持批量傳輸無限大小的數據。沒有地址機制,這種總線類型最適合源和目的地之間的直接數據流 (非存儲器映射)
4.2 AXI互聯接口
在 PS 和 PL 之間的主要連接是通過一組 9 個 AXI 接口,每個接口有多個通道組成。這些形成了 PS 內部的互聯以及與 PL 的連接。
? 互聯(Interconnect) — 互聯實際上是一個開關,管理并直接傳遞所連接的AXI 接口之間的通信。在 PS 內有幾個互聯, 其中有些還直接連接到 PL ,而另一些是只用于內部連接的。這些互聯之間的連接也是用 AXI 接口所構成的。
? 接口 (Interface) — 用于在系統內的主機和從機之間傳遞數據、地址和握手信號的點對點連接。
? 通用 AXI(General Purpose AXI) — 一條 32 位數據總線,適合 PL 和 PS 之間的中低速通信。接口是透傳的不帶緩沖。總共有四個通用接口:兩個 PS 做主機,另兩個 PL 做主機。在PS-PL Configuration中的GP Master/Slave AXI Interface中可以啟用該接口
? 加速器一致性端口(Accelerator Coherency Port) — 在 PL 和 APU 內的 SCU之間的單個異步連接,總線寬度為 64 位。這個端口用來實現 APU cache 和 PL的單元之間的一致性。PL 是做主機的。ACP接口允許對PL主機進行低延遲訪問,帶有可選的coherency和L1、L2緩存。從系統角度來看,ACP接口具有與APU CPU類似的連通性,因此ACP可以直接在APU塊爭取資源。在PS-PL Configuration中的ACP Slave AXI Interface中可以啟用該接口
? 高性能端口(High Performance Ports) — 四個高性能 AXI 接口,帶有 FIFO緩沖來提供 “ 批量 ” 讀寫操作,并支持 PL 和 PS 中的存儲器單元的高速率通信。數據寬度是 32 或 64 位,在所有四個接口中 PL 都是做主機的。4個AXI_HP接口為PL總線主程序提供了到DDR和OCM內存的高帶寬數據通道,每個接口有兩個用于讀寫通信的FIFO緩沖區。內存互連的PL將高速AXI_HP端口布線到兩個DDR內存端口或OCM。AXI_HP接口也可以用作AXI_FIFO接口,利用其緩沖能力。簡而言之,這種接口為PL主機和PS內存(DDR或OCM)之間提供了一種高吞吐量數據通道。在PS-PL Configuration中的HP Slave AXI Interface中可以啟用這些接口。
本文轉自:
https://blog.csdn.net/Murmansk11?type=blog
編輯:jq
-
FPGA
+關注
關注
1630文章
21783瀏覽量
605004 -
芯片
+關注
關注
456文章
51090瀏覽量
425932 -
ARM
+關注
關注
134文章
9150瀏覽量
368455 -
Zynq
+關注
關注
10文章
610瀏覽量
47240
原文標題:Zynq的學習
文章出處:【微信號:zhuyandz,微信公眾號:FPGA之家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ZYNQ基礎---AXI DMA使用
基于PYNQ和機器學習探索MPSOC筆記
ZYNQ核心板學習筆記

科普課堂 | OSI模型,你真的了解嗎?

如何學習ARM?
正點原子ZYNQ7015開發板!ZYNQ 7000系列、雙核ARM、PCIe2.0、SFPX2,性能強悍,資料豐富!
[XILINX] 正點原子ZYNQ7035/7045/7100開發板發布、ZYNQ 7000系列、雙核ARM、PCIe2.0、SFPX2!



你真的了解駐波比嗎?到底什么是電壓駐波比?





 工商網監
工商網監
評論