") AMD或?qū)⑷鎿肀BM,CPU和GPU都要用?
AMD或?qū)⑷鎿肀BM,CPU和GPU都要用?
近期外網(wǎng)爆出傳聞,AMD下一代Zen 4核心的EPYC Genoa處理器可能會配備HBM內(nèi)容,以求與英特爾的下一代服務(wù)器CPU Xeon Sapphire Rapids爭雄。巧合的是,近日Linux內(nèi)核補丁中也透露了消息,AMD下一代基于CDNA 2核心的Instinct MI200 GPU也將用到HBM2e,顯存更是高達128GB。這意味著AMD很可能會在服務(wù)器市場全面擁抱HBM。
已與消費顯卡市場無緣的HBM
HBM作為一種高帶寬存儲器,其實是由AMD最先投入研發(fā)的高性能DRAM。為了實現(xiàn)這一愿景,AMD找來了有3D堆疊工藝生產(chǎn)經(jīng)驗的SK海力士,并借助互聯(lián)和封裝廠商的幫助,聯(lián)合開發(fā)出了HBM存儲器。

AMD也是首個將其引入GPU市場的廠商,并應(yīng)用在其Fiji GPU上。隨后2016年,三星率先開始了HBM2的量產(chǎn),AMD被英偉達搶了風頭,后者率先將這一新標準的存儲器應(yīng)用在其Tesla P100加速卡上。
當時HBM的優(yōu)缺點都十分明顯了,從一開始以來的帶寬優(yōu)勢正在被GDDR6迎頭趕上,設(shè)計難度和成本又是一道難以邁過的坎。雖然高端顯卡上這些成本并不占大頭,但中低端顯卡用到HBM就比較肉疼了。但AMD并沒有因此放棄HBM2,而是在Vega顯卡上繼續(xù)引入了HBM2。
不過,這可能也就是我們最后一次在消費級GPU上見到HBM了,AMD在之后的RDNA架構(gòu)上再也沒有使用HBM,僅僅只有基于CDNA架構(gòu)且用于加速器的GPU上還在使用HBM。
為什么是服務(wù)器市場?
HBM是如何在服務(wù)器市場扎根的呢?這是因為HBM最適合的應(yīng)用場景之一就是功率受限又需要最大帶寬的環(huán)境,完美達到HPC集群中進行人工智能計算,或是大型密集計算的數(shù)據(jù)中心的要求。
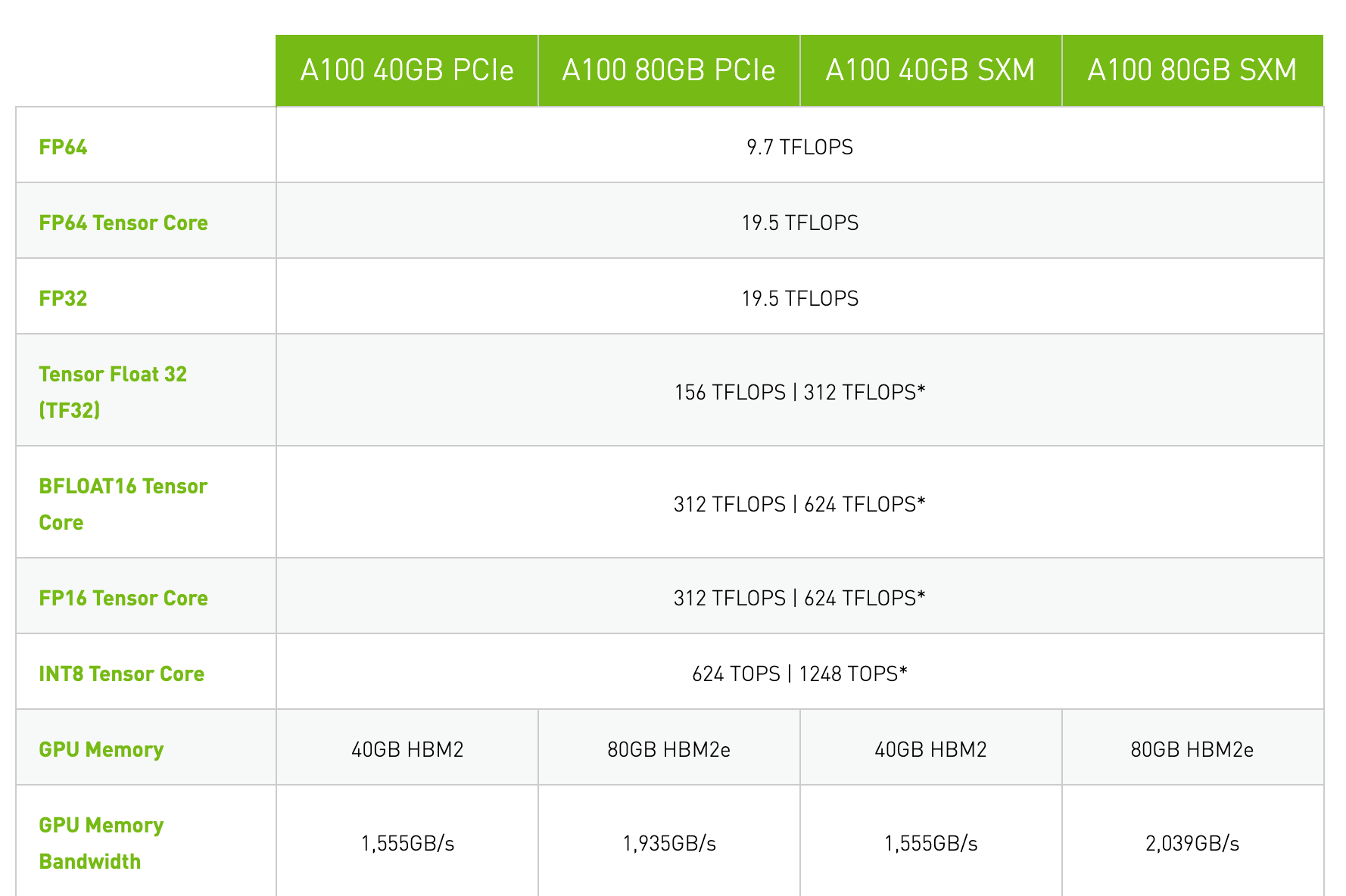
這也就是這些包含數(shù)據(jù)中心業(yè)務(wù)的公司持續(xù)使用HBM的原因,英偉達在性能強大的服務(wù)器GPU A100中依然在使用HBM2和HBM2e,甚至可能會在下一代Hopper結(jié)構(gòu)繼續(xù)沿用下去。據(jù)傳,英特爾尚未面世的Xe-HP和Xe-HPC GPU也將使用HBM。
不過這兩家廠商的消費級GPU都不約而同的避過了HBM,選擇了GDDR6和GDDR6X,可想而知他們都不想走AMD的彎路。
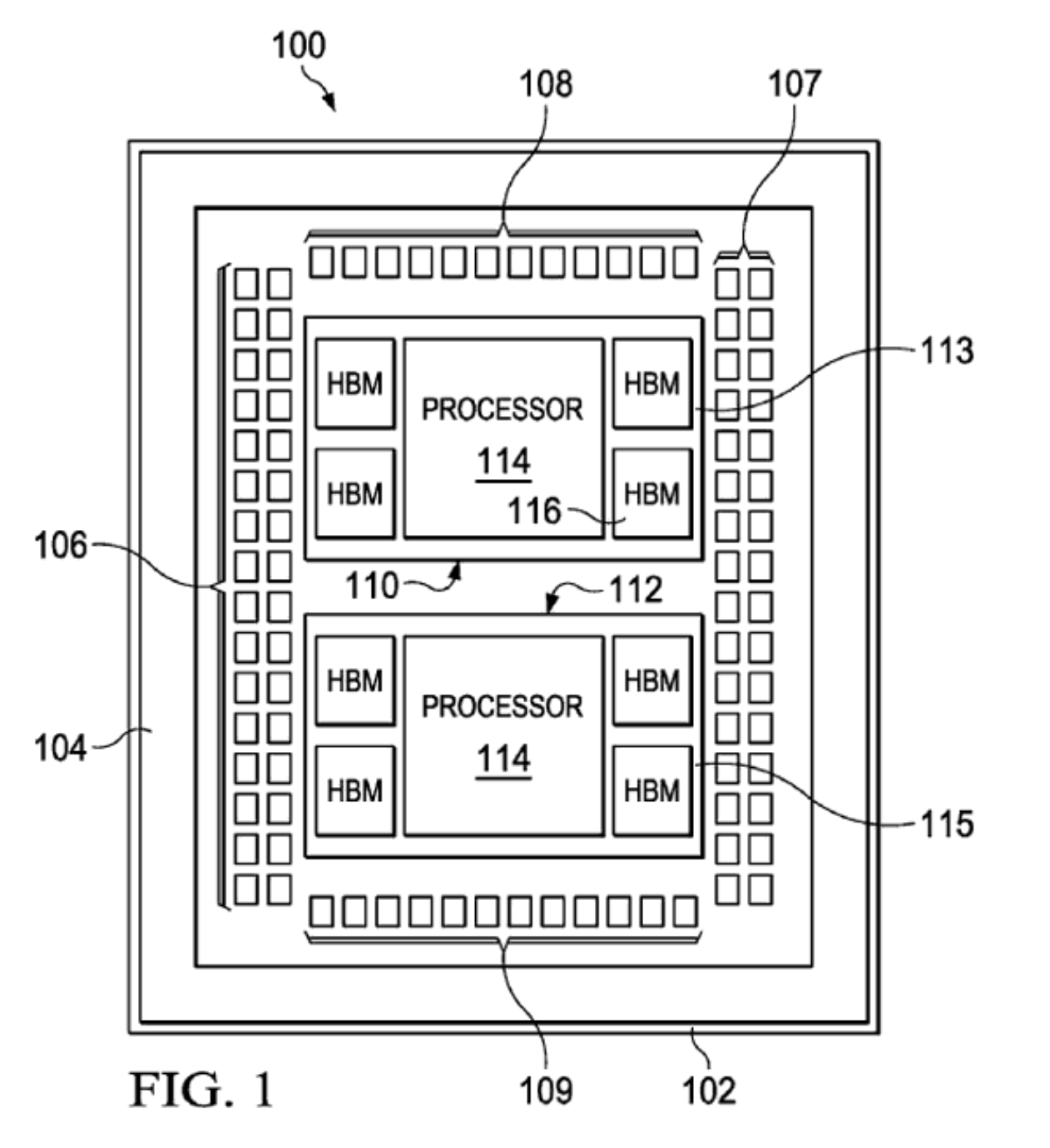
至于AMD在CPU上率先使用HBM也并非空穴來風,在AMD去年公布的一份專利中,就在芯片設(shè)計上出現(xiàn)了HBM。英特爾推出的競品Xeon Sapphire Rapids服務(wù)器CPU也正式宣布將使用HBM,不過量產(chǎn)要等到2023年。這些可以看出HBM在服務(wù)器市場有多“香”,他們都開始將HBM向CPU上發(fā)展。
下一代HBM
雖然制定標準的JEDEC尚未推出HBM3的相關(guān)規(guī)范,但一直在研究下一代HBM的SK海力士在今年6月透露了HBM3的最新情報,HBM將迎來進一步的性能提升。

HBM2E的帶寬可達460GB/s,I/O速率可達3.6Gbps,而HBM3的帶寬可以達到665GB/s以上,I/O速率超過5.2Gbps。這還是只是速率的下限而已,要知道SiFive與OpenFive今年流片的5nm RISC-V SoC也加入了HBM3的IP,最高支持的數(shù)據(jù)傳輸率達到7.2Gbps。
SK海力士能做到如此高的性能提升,很可能得益于去年與Xperi簽訂的專利許可協(xié)議。這些協(xié)議中包含了DBI Ultra 2.5D/3D互聯(lián)技術(shù),可以用于3DS、HBM2、HBM3及后續(xù)DRAM產(chǎn)品的創(chuàng)新開發(fā)。傳統(tǒng)的銅柱互聯(lián)只能做到每平方毫米625個互聯(lián),而DBI Ultra可以在同樣的面積下做到10萬個互聯(lián)。
結(jié)語
從JEDEC2018年宣布HBM2E標準以來,HBM已經(jīng)近3年沒有更新了。三星更是在今年2月宣布開發(fā)帶有人工智能引擎的HBM-PIM,未來HBM3是否能在服務(wù)器領(lǐng)域繼續(xù)稱雄,相信當前幾大廠商規(guī)劃的服務(wù)器產(chǎn)品中HBM占比已經(jīng)給出了答案。
已與消費顯卡市場無緣的HBM
HBM作為一種高帶寬存儲器,其實是由AMD最先投入研發(fā)的高性能DRAM。為了實現(xiàn)這一愿景,AMD找來了有3D堆疊工藝生產(chǎn)經(jīng)驗的SK海力士,并借助互聯(lián)和封裝廠商的幫助,聯(lián)合開發(fā)出了HBM存儲器。
Fiji GPU / AMD
AMD也是首個將其引入GPU市場的廠商,并應(yīng)用在其Fiji GPU上。隨后2016年,三星率先開始了HBM2的量產(chǎn),AMD被英偉達搶了風頭,后者率先將這一新標準的存儲器應(yīng)用在其Tesla P100加速卡上。
當時HBM的優(yōu)缺點都十分明顯了,從一開始以來的帶寬優(yōu)勢正在被GDDR6迎頭趕上,設(shè)計難度和成本又是一道難以邁過的坎。雖然高端顯卡上這些成本并不占大頭,但中低端顯卡用到HBM就比較肉疼了。但AMD并沒有因此放棄HBM2,而是在Vega顯卡上繼續(xù)引入了HBM2。
不過,這可能也就是我們最后一次在消費級GPU上見到HBM了,AMD在之后的RDNA架構(gòu)上再也沒有使用HBM,僅僅只有基于CDNA架構(gòu)且用于加速器的GPU上還在使用HBM。
為什么是服務(wù)器市場?
HBM是如何在服務(wù)器市場扎根的呢?這是因為HBM最適合的應(yīng)用場景之一就是功率受限又需要最大帶寬的環(huán)境,完美達到HPC集群中進行人工智能計算,或是大型密集計算的數(shù)據(jù)中心的要求。
A100不同規(guī)格的顯存對比 / Nvidia
這也就是這些包含數(shù)據(jù)中心業(yè)務(wù)的公司持續(xù)使用HBM的原因,英偉達在性能強大的服務(wù)器GPU A100中依然在使用HBM2和HBM2e,甚至可能會在下一代Hopper結(jié)構(gòu)繼續(xù)沿用下去。據(jù)傳,英特爾尚未面世的Xe-HP和Xe-HPC GPU也將使用HBM。
不過這兩家廠商的消費級GPU都不約而同的避過了HBM,選擇了GDDR6和GDDR6X,可想而知他們都不想走AMD的彎路。
AMD專利 / AMD
至于AMD在CPU上率先使用HBM也并非空穴來風,在AMD去年公布的一份專利中,就在芯片設(shè)計上出現(xiàn)了HBM。英特爾推出的競品Xeon Sapphire Rapids服務(wù)器CPU也正式宣布將使用HBM,不過量產(chǎn)要等到2023年。這些可以看出HBM在服務(wù)器市場有多“香”,他們都開始將HBM向CPU上發(fā)展。
下一代HBM
雖然制定標準的JEDEC尚未推出HBM3的相關(guān)規(guī)范,但一直在研究下一代HBM的SK海力士在今年6月透露了HBM3的最新情報,HBM將迎來進一步的性能提升。
HBM2E和HBM3性能對比 / SK海力士
HBM2E的帶寬可達460GB/s,I/O速率可達3.6Gbps,而HBM3的帶寬可以達到665GB/s以上,I/O速率超過5.2Gbps。這還是只是速率的下限而已,要知道SiFive與OpenFive今年流片的5nm RISC-V SoC也加入了HBM3的IP,最高支持的數(shù)據(jù)傳輸率達到7.2Gbps。
SK海力士能做到如此高的性能提升,很可能得益于去年與Xperi簽訂的專利許可協(xié)議。這些協(xié)議中包含了DBI Ultra 2.5D/3D互聯(lián)技術(shù),可以用于3DS、HBM2、HBM3及后續(xù)DRAM產(chǎn)品的創(chuàng)新開發(fā)。傳統(tǒng)的銅柱互聯(lián)只能做到每平方毫米625個互聯(lián),而DBI Ultra可以在同樣的面積下做到10萬個互聯(lián)。
結(jié)語
從JEDEC2018年宣布HBM2E標準以來,HBM已經(jīng)近3年沒有更新了。三星更是在今年2月宣布開發(fā)帶有人工智能引擎的HBM-PIM,未來HBM3是否能在服務(wù)器領(lǐng)域繼續(xù)稱雄,相信當前幾大廠商規(guī)劃的服務(wù)器產(chǎn)品中HBM占比已經(jīng)給出了答案。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
amd
+關(guān)注
關(guān)注
25文章
5469瀏覽量
134193 -
cpu
+關(guān)注
關(guān)注
68文章
10868瀏覽量
211844 -
gpu
+關(guān)注
關(guān)注
28文章
4741瀏覽量
128963
發(fā)布評論請先 登錄
相關(guān)推薦
《CST Studio Suite 2024 GPU加速計算指南》
的各個方面,包括硬件支持、操作系統(tǒng)支持、許可證、GPU計算的啟用、NVIDIA和AMD GPU的詳細信息以及相關(guān)的使用指南和故障排除等內(nèi)容。
1. 硬件支持
- NVIDIA GPU
發(fā)表于 12-16 14:25
AMD與NVIDIA GPU優(yōu)缺點
在圖形處理單元(GPU)市場,AMD和NVIDIA是兩大主要的競爭者,它們各自推出的產(chǎn)品在性能、功耗、價格等方面都有著不同的特點和優(yōu)勢。 一、性能 GPU的性能是用戶最關(guān)心的指標之一。在高端市場
CPU渲染和GPU渲染優(yōu)劣分析
使用計算機進行渲染時,有兩種流行的系統(tǒng):基于中央處理單元(CPU)或基于圖形處理單元(GPU)。CPU渲染利用計算機的CPU來執(zhí)行場景并將其

聊聊GPU背后的大贏家-HBM
HBM全稱為High Bandwidth Memory,直接翻譯即是高帶寬內(nèi)存,是一款新型的CPU/GPU內(nèi)存芯片。

X-Silicon發(fā)布RISC-V新架構(gòu) 實現(xiàn)CPU/GPU一體化
X-Silicon 的芯片與其他架構(gòu)不同,其設(shè)計將 CPU 和 GPU 的功能整合到單核架構(gòu)中。這與英特爾和 AMD 的典型設(shè)計不同,前者有獨立的
發(fā)表于 04-08 11:34
?587次閱讀
RISC-V芯片新突破:CPU與GPU一體化核心設(shè)計
X-Silicon 的芯片與其他架構(gòu)不同,其設(shè)計將 CPU 和 GPU 的功能結(jié)合到單核架構(gòu)中。這與 Intel 和 AMD 的典型設(shè)計不同,后者有獨立的
發(fā)表于 04-07 10:41
?734次閱讀
FPGA在深度學習應(yīng)用中或將取代GPU
業(yè)可行性方面考慮,自動駕駛汽車等應(yīng)用可能需要多達 7-10 個 GPU(其中大多數(shù)會在不到四年的時間內(nèi)失效),對于大多數(shù)購車者來說,智能或自動駕駛汽車的成本將變得不切實際。”
機器人、醫(yī)療保健和安全
發(fā)表于 03-21 15:19
四川長虹回應(yīng)幫華為代工 HBM芯片備受關(guān)注
的CPU/GPU內(nèi)存芯片因為AI而全面爆發(fā),多家存儲企業(yè)的產(chǎn)能都已經(jīng)跟不上。HBM英文全稱High Bandwidth Memory,翻譯過來即是高帶寬內(nèi)存,
英偉達B100 GPU架構(gòu)披露,B200或配備288GB顯存
XpeaGPU透露,B100 GPU將配備兩枚基于此技術(shù)的芯片,與此同時,還將連通多達8個HBM3e顯存堆棧,總?cè)萘扛哌_192GB。AMD同樣已有提供同量級的產(chǎn)品,并且在Instinc
Nvidia與AMD新芯片,突破PCIe瓶頸
AMD 和 Nvidia 的 GPU 都依賴 PCI 總線與 CPU 進行通信。CPU 和 GPU 有兩個不同的內(nèi)存域,數(shù)據(jù)必須通過 PCI
AMD Instinct MI300新版將采用HBM3e內(nèi)存,競爭英偉達B100
AMD于去年宣布旗下兩款I(lǐng)nstinct MI300加速器,包括基于GPU的MI300X以及基于APU架構(gòu)的MI300A, both配備192GB/128GB的HBM3內(nèi)存,還流傳著一款純粹的
gpu是什么和cpu的區(qū)別
GPU和CPU是兩種常見的計算機處理器,它們在結(jié)構(gòu)和功能上有很大的區(qū)別。在這篇文章中,我們將探討GPU和CPU的區(qū)別,并詳細介紹它們的原理、
AMD將推新GPU,效能媲美英偉達RTX 4080
據(jù)悉,AMD正努力研制新品級GPU,性能堪比英偉達的RTX 4080,而售價卻只有后者的一半。據(jù)多個在線社區(qū)反映,AMD即將發(fā)布的Radeon RX 8000系列GPU效能與NVIDI
為什么GPU比CPU更快?
大規(guī)模數(shù)據(jù)集時比CPU更快的根本原因。內(nèi)存帶寬:GPU的內(nèi)存帶寬比CPU高得多。內(nèi)存帶寬是指數(shù)據(jù)在內(nèi)存之間傳輸?shù)乃俣取?b class='flag-5'>GPU可以更快地將數(shù)據(jù)
CPU與GPU散熱器設(shè)計的異同及其重要性
計算機的穩(wěn)定和性能不受影響,散熱器成為了必要的組件。本文將詳述CPU和GPU散熱器的設(shè)計異同以及其重要性。 一、設(shè)計異同 1. 散熱原理: CPU和





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論