 golang并發機制和其他語言在實現上有什么不同
golang并發機制和其他語言在實現上有什么不同
golang 并發機制和其他語言在實現上有什么不同?為什么能做到高效快速?本文做了詳細介紹。
由于對普通語法的介紹網上資源極多,Go 官方的上手指南 A Tour of Go: https://tour.golang.org/ (請自備梯子)就是極好的例子,我不再打算就語法細節進行詳述。這次,讓我們直切肯綮,從 Go 最大的賣點入手——并發 (Concurrency)。
func Hello() {
fmt.Println(“I‘m B”) // Output A
}
go Hello()
fmt.Println(“I’m A”) // Output B
如果在雙核(及以上)的機器編譯運行上述 Go 代碼,我們能觀測到 A/B 輸出的順序隨著運行次數的不同而不同,也就是說,僅依靠 5 行代碼,我們就創建了兩線并發的程序。
相較于 C/C++/Java/Python 等語言為了創建一個并發執行環境所需要的調用 POSIX-API/定義繼承類等繁瑣步驟,Golang 簡單一句 go func()的確給人眼前一亮的感覺。當然了,僅憑語法上的簡潔顯然不足以成為一個編程語言拿來吹噓的資本,下文我們將對在這幾行語句下 Golang 的并發機制和實現進行詳細探索。
一等公民-Goroutine
Goroutine 是 Go 的并發機制中絕對的主角。它代表了指令流及其執行環境,也是被調度的基本單位。宏觀來看,goroutine 類似操作系統中線程的概念(注意這里的類比并不嚴格,下文將會對兩者做出詳細比較):不同線程間共享同一個內存空間,但不共享棧且各自并發執行;同樣地,goroutine 也同內存不同棧,并發運行。
如上圖所示,上文代碼片段第四行的 go Hello()會創建一個新的 goroutine(綠色線條),并開始執行 Hello()函數。需要注意的是,由于主 goroutine(藍色線條)和新創建的 goroutine 擁有并發性,且主 goroutine 在執行 go Hello()時并不會等待被調用函數執行結束,故“I‘m A”(主 goroutine 輸出)和“I’m B”(新 goroutine 輸出)可能以任何順序交錯展現。
為何不用線程 (pThread)?
直到現在,我們并不能從 goroutine 中看到任何有別于 thread、從而促成 Golang 編寫者拋棄傳統的線程模型自己造輪子的地方。那么操作系統層面的線程 (pThread) 有什么問題呢?
生命周期開銷太高
線程的創建、銷毀和切換都需要一系列系統調用,而每一個系統調用意味著觸發軟中斷、進入內核態、將寄存器的值全部存入內存、維護相關數據結構、恢復寄存器、返回用戶態等一系列組合拳。這一輪操作不僅十分耗時、還可能讓內存緩存的加速效果大幅度下滑。所以,避免頻繁創建、銷毀線程作為高性能并發的必要條件這一點已成為程序員的共識。
以線程為并發模型的 C/C++/Java 采用線程池的方法來降低線程昂貴的生命周期開銷。既然線程創建/死亡代價高昂,我們何不讓創建的線程永不死亡呢?具體來說,對于每個已經創建但已經完成工作的線程,我們令其休眠,并放進一個資源池中,在下次需要新的線程的時候,我們直接將線程池中休眠的線程拿出來喚醒使用而非新建線程。
這樣一來,絕大部分的線程創建/銷毀需求都成功地被線程池吸收了。進一步,通過規定線程池的最大容量,我們可以將花費在線程創建和銷毀上的開銷控制在固定值,例如,常見的 Java Web 應用會設立一個 30~50 大小的線程池來處理 HTTP 請求,并取得非常好的并發效果。
不必要的線程切換
即使線程池很好地砍掉了線程生命周期開銷,操作系統層面的線程依然存在不足:線程的語義在于并行,當線程數超出 CPU 核心數時,操作系統會定時給每個 CPU 核心切換不同的線程,讓他們“看上去”是同時在進行的。當然,這樣的切換同樣需要付出若干中斷、系統調用,以及當前線程的工作集從緩存中被新線程完全抹去的代價。
乍一聽上去這樣的代價是必不可少的,實則不然。由于在絕大部分時候我們的應用都是 I/O 和計算混合的,即,一段時間與硬盤/網絡交互(I/O)、一段時間進行相對密集的內存訪問和計算,而等待 I/O 完成期間該線程處于休眠狀態。
CPU 已經會切換到其他線程,即使操作系統不強行打斷并切換處于計算密集期的線程,應用在宏觀上依然顯示出一定并發性。而通過去掉計算密集期的線程切換,整體 CPU 效率得到了有效提升——NodeJS 就是在這樣的哲學下誕生的:單一線程、全異步的 I/O、事件驅動、非搶占式調度(當某一個函數單純進行計算和內存訪問時不會被打斷)。
在進行 I/O 密集型工作(如網站后臺)時通過將單一 CPU 利用率逼到 100%的方式在效率上力挫幾乎其他所有能利用多線程多核腳本語言。這簡直是本來就特立獨行的 Javascript 對整個編程語言界的同僚豎起的又一根中指。當然了,僅僅能利用單核處理能力的 NodeJS 在處理對計算要求更高的工作上顯然會力不從心,但其給我們的啟示值得注意。
較高的切換開銷
在鎖競爭、協程同步等情況下,頻繁進入內核態的線程模型會放大自身在切換開銷上的劣勢。而用戶態的調度器(如 goroutine 調度器)則可以在用戶態處理這一切,省時省力。另外,由于編程語言能夠更好地對自己語言中的同步原語進行分析,編程語言自己的調度器能夠更好地根據語義對調度進行優化。
Goroutine 調度模型
Go 使用用戶態的調度器對 goroutine 的執行進行控制,從而避免了大部分內核開銷。具體而言,Golang 的調度模型由三部分組成:執行環境 (Executor)、調度器 (Scheduler) 和 goroutine。
執行環境,顧名思義,用來執行代碼。盡管其在抽象概念上應該對應一個 CPU 核心,但由于在用戶態不能接觸硬件資源,故 Go 將其具體實現為線程。當線程數等于 CPU 核心數時,既最大化了 CPU 核心利用率,又最小化了線程切換的開銷,是最理想的情況(當然,實際情況下操作系統還會運行、切換來自其他進程的線程,但這已經超出一個普通程序的控制范疇)。
故默認情況下,用于指定執行環境個數的運行時變量 GOMAXPROCS等于 CPU 核心數目。當然,開發者可以根據自己的需求更改該值,當 GOMAXPROCS=1時,Go 的執行模型幾乎等同于 NodeJS。
調度器則是調度模型的核心,它決定了每個執行環境(核)在什么時候執行什么樣的 goroutine。Go 采用任務隊列的方式對 goroutine 進行調度:
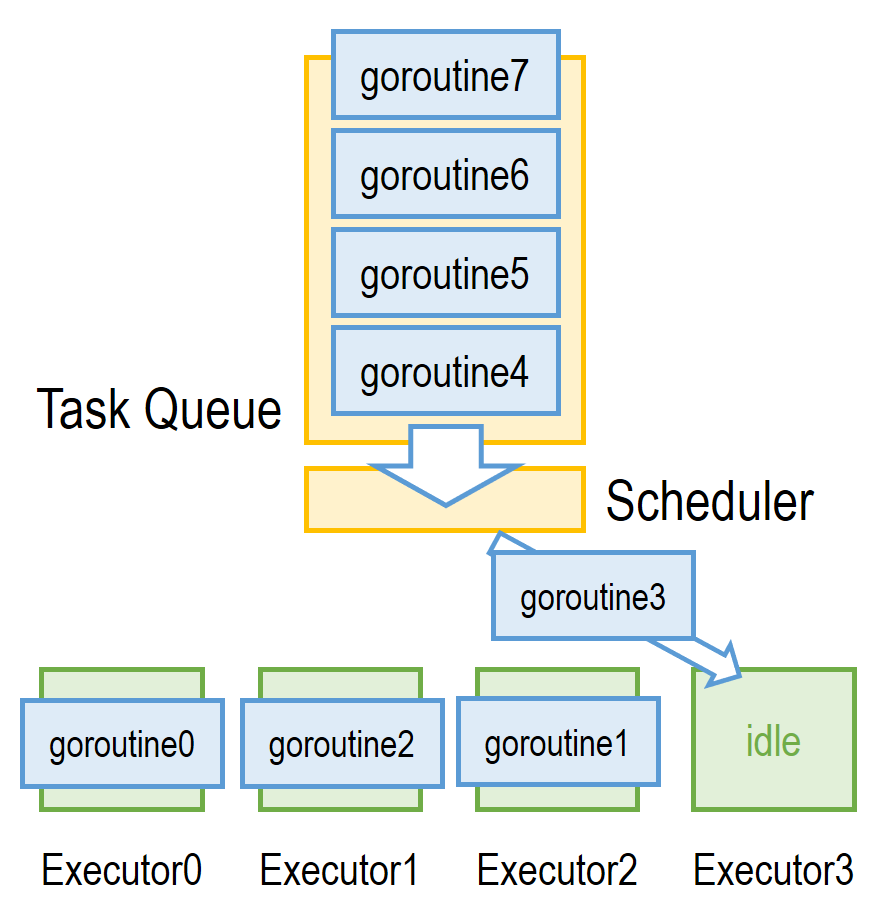
如上圖所示,所有 goroutine 作為任務排在任務隊列中,而 scheduler 所做的則是在 executor 空閑時從隊首拿出下一個 goroutine 給其執行。每個任務 (goroutine) 會被 executor 執行到完成或阻塞(如發起 I/O 請求、系統調用、請求一個正在被其他人使用的鎖或自行 yield 計算資源等)。
在第二種情況下,該 goroutine 既不在 executor 也不在隊列中,而是處于阻塞態被 Scheduler 監視直到阻塞結束重新入隊。值得注意的是,這里與上文提到的“去掉計算密集期的線程切換”的聯系:由于調度器對任務采用非搶占式調度,即在正常計算和內存訪問的情況下 executor 不會放棄當前 goroutine,故多余的 goroutine 切換代價得以被去除。
這樣的任務隊列模型仍然存在不小的問題:由于任務隊列只有一個,為了保證出入隊的原子性,任務分配/加入時需要對整個隊列加互斥鎖,當 goroutine 執行時間短時,頻繁給大量 executor 分配新任務會讓單一隊列成為并行的性能瓶頸。為了解決該問題,Go 采用了多任務隊列的方式進行任務調度:
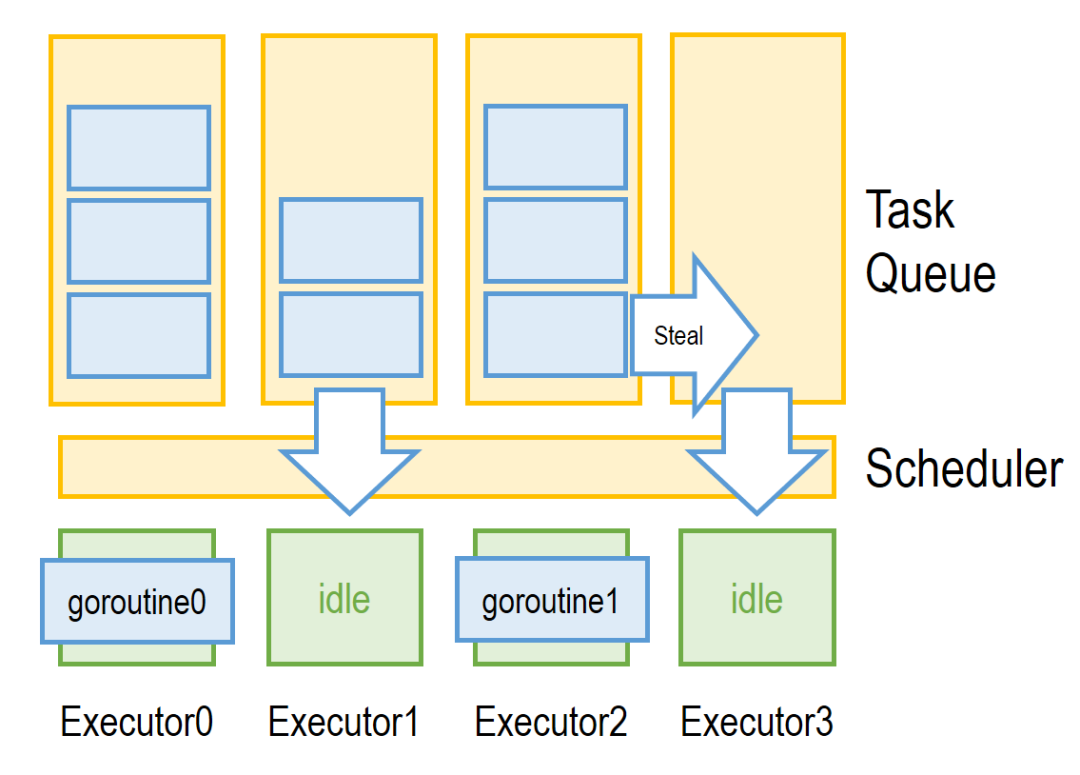
如上圖所示,在多任務調度模型中,每個 executor 均有一個自己對應的任務隊列。在正常情況下,每個 executor 從自己的隊列中拿 goroutine,并將生成的新 goroutine 放進自己隊列隊尾。分布式結構可能帶來的問題是顯而易見的:
如果任務在隊列的分布不均勻會導致計算資源的浪費,如上圖中的 executor3,如果缺乏其他措施,該核會因為對應隊列沒有任務而空閑。對于該問題,Go 的解決方法是引入“偷任務”機制:當 Scheduler 發現某隊列無任務可用時,會從其他隊列里“偷”一部分任務過來。由于偷任務的代價較高(需要鎖兩個隊列),Scheduler 會爭取一次性偷足夠多的任務以降低未來偷任務的頻率。
而對于處于阻塞狀態的 goroutine,Scheduler 需要監視其脫離阻塞狀態并重新入隊。Goroutine 被阻塞的原因大體分兩種:
阻塞 I/O 或系統調用。由于底層實現限制,該類阻塞需要一個線程顯式執行相應的 syscall 并等待調用返回。在這種情況下,Scheduler 會新建一個線程執行該 syscall,并在返回后通知 Scheduler。
同樣地,為了節省開銷,該線程被維護在線程池中。值得注意的是,該類線程由于整個生命周期都幾乎在等待阻塞(阻塞結束后立即通知 Scheduler 而后結束),而阻塞的線程是不參與操作系統線程切換的,故其并不會帶來太大的線程切換開銷。
當然,如果借鑒 NodeJS、盡可能用異步版本 api 替換同步版,則可以省去線程池操作,進一步優化性能(Go 是否采用該優化尚存疑)。
內部同步機制,Goroutine 因為調用了 Go 內部同步機制(channel、互斥鎖、wait group、conditional variable 等)而阻塞。對于此類阻塞,由于同步機制的語義是 Go 定義從而對 Scheduler 透明的,Scheduler 可以分析出阻塞依賴,從而將監視該阻塞狀態的任務交給其依賴的 goroutine。
例如,goroutine A 請求了一個正被 goroutine B 獲取了的互斥鎖,從而陷入阻塞,那么 Scheduler 可以在 goroutine B 釋放該鎖時由對應的 executor 將 goroutine A 喚醒并加入隊列。在這整個過程中不需要引入新的線程。
以上便是 Golang Scheduler 的大致工作邏輯,在各個組件的相互配合下,一個高性能、支持調度成千上萬 goroutine 的并發環境就此搭建起來。
總結和啟發
從 Golang 的并發機制中我們可以得到如下幾點啟發:
系統調用和內核態是昂貴的,用戶態的調度器擁有更好的性能。
由于頻繁進行不必要的切換,線程并不是合適的并發執行基本單位;相反,將線程作為執行資源 (CPU) 的抽象、為一個 CPU 核心建立一個線程作為執行器則是一個很不錯的主意。
單一任務隊列在任務短而多時劣勢明顯,分布式隊列+任務偷取能夠較好的解決問題。
可以說,Golang 的并發機制是 NodeJS 的普適版,擁有能夠更好利用多核計算力的優勢;和 采用 OS 線程、阻塞 I/O、GIL 的 Python 并發模式 相比則更是云泥之別。正是更為精巧的并發機制和簡單的并發原語,使得 Concurrency 成為 Go 語言最大的賣點。
需要指出的是,Go 所采用的一切技術都并非原創—— go func()的同步原語與 Cilk 十分類似,分布式任務隊列也多少有模仿 Cilk/OpenMP 的意味,如果非要說不同之處,大概在于 Go 是一個原生支持該功能的完整編程語言,而另外兩者只是 C/C++的語法擴展插件吧。
文章轉載:Go開發大全
(版權歸原作者所有,侵刪)
編輯:jq
-
語言
+關注
關注
1文章
97瀏覽量
24242
原文標題:Golang 學習之并發機制
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是LLM?LLM在自然語言處理中的應用
Golang配置代理方法

C語言與其他編程語言的比較
Llama 3 模型與其他AI工具對比
go語言如何解決并發問題

鴻蒙原生應用元服務開發-初識倉頡開發語言
三十分鐘入門基礎Go Java小子版





 工商網監
工商網監
評論