 淺析Linux netdevice子系統
淺析Linux netdevice子系統
1. 前言
在繼續分析 dev_queue_xmit 發送數據包之前,我們需要了解以下重要概念。
Linux 支持流量控制(traffic control)的功能,此功能允許系統管理員控制數據包如何從機器發送出去。流量控制系統包含幾組不同的 queue system,每種有不同的排隊特征。各個排隊系統通常稱為 qdisc,也稱為排隊規則。可以將 qdisc 視為調度程序, qdisc 決定數據包的發送時間和方式。
Linux 上每個 device 都有一個與之關聯的默認 qdisc。對于僅支持單發送隊列的網卡,使用默認的 qdisc pfifo_fast。支持多個發送隊列的網卡使用 mq 的默認 qdisc。可以運行 tc qdisc 來查看系統 qdisc 信息。某些設備支持硬件流量控制,這允許管理員將流量控制 offload 到網絡硬件,節省系統的 CPU 資源。
現在我們從 net/core/dev.c 繼續分析 dev_queue_xmit。
2. dev_queue_xmit and __dev_queue_xmit
dev_queue_xmit 簡單封裝了__dev_queue_xmit:
int dev_queue_xmit(struct sk_buff *skb)
{
return __dev_queue_xmit(skb, NULL);
}
EXPORT_SYMBOL(dev_queue_xmit);
__dev_queue_xmit 才是干臟活累活的地方,我們一點一點來看:
static int __dev_queue_xmit(struct sk_buff *skb, void *accel_priv)
{
struct net_device *dev = skb-》dev;
struct netdev_queue *txq;
struct Qdisc *q;
int rc = -ENOMEM;
skb_reset_mac_header(skb);
/* Disable soft irqs for various locks below. Also
* stops preemption for RCU.
*/
rcu_read_lock_bh();
skb_update_prio(skb);
開始的邏輯:
聲明變量
調用 skb_reset_mac_header,準備發送 skb。這會重置 skb 內部的指針,使得 ether 頭可以被訪問
調用 rcu_read_lock_bh,為接下來的讀操作加鎖
調用 skb_update_prio,如果啟用了網絡優先級 cgroups,這會設置 skb 的優先級
現在,我們來看更復雜的部分:
txq = netdev_pick_tx(dev, skb, accel_priv);
這會選擇發送隊列。
2.1 netdev_pick_tx
netdev_pick_tx 定義在net/core/flow_dissector.c
struct netdev_queue *netdev_pick_tx(struct net_device *dev,
struct sk_buff *skb,
void *accel_priv)
{
int queue_index = 0;
if (dev-》real_num_tx_queues != 1) {
const struct net_device_ops *ops = dev-》netdev_ops;
if (ops-》ndo_select_queue)
queue_index = ops-》ndo_select_queue(dev, skb,
accel_priv);
else
queue_index = __netdev_pick_tx(dev, skb);
if (!accel_priv)
queue_index = dev_cap_txqueue(dev, queue_index);
}
skb_set_queue_mapping(skb, queue_index);
return netdev_get_tx_queue(dev, queue_index);
}
如上所示,如果網絡設備僅支持單個 TX 隊列,則會跳過復雜的代碼,直接返回單個 TX 隊列。大多高端服務器上使用的設備都有多個 TX 隊列。具有多個 TX 隊列的設備有兩種情況:
驅動程序實現 ndo_select_queue,以硬件或 feature-specific 的方式更智能地選擇 TX 隊列
驅動程序沒有實現 ndo_select_queue,這種情況需要內核自己選擇設備
從 3.13 內核開始,沒有多少驅動程序實現 ndo_select_queue。bnx2x 和 ixgbe 驅動程序實現了此功能,但僅用于以太網光纖通道FCoE。鑒于此,我們假設網絡設備沒有實現 ndo_select_queue 和沒有使用 FCoE。在這種情況下,內核將使用__netdev_pick_tx 選擇 tx 隊列。
一旦__netdev_pick_tx 確定了隊列號,skb_set_queue_mapping 將緩存該值(稍后將在流量控制代碼中使用),netdev_get_tx_queue 將查找并返回指向該隊列的指針。讓我們 看一下__netdev_pick_tx 在返回__dev_queue_xmit 之前的工作原理。
2.2 __netdev_pick_tx
我們來看內核如何選擇 TX 隊列。net/core/flow_dissector.c:
u16 __netdev_pick_tx(struct net_device *dev, struct sk_buff *skb)
{
struct sock *sk = skb-》sk;
int queue_index = sk_tx_queue_get(sk);
if (queue_index 《 0 || skb-》ooo_okay ||
queue_index 》= dev-》real_num_tx_queues) {
int new_index = get_xps_queue(dev, skb);
if (new_index 《 0)
new_index = skb_tx_hash(dev, skb);
if (queue_index != new_index && sk &&
rcu_access_pointer(sk-》sk_dst_cache))
sk_tx_queue_set(sk, new_index);
queue_index = new_index;
}
return queue_index;
}
代碼首先調用 sk_tx_queue_get 檢查發送隊列是否已經緩存在 socket 上,如果尚未緩存, 則返回-1。
下一個 if 語句檢查是否滿足以下任一條件:
queue_index 《 0:表示尚未設置 TX queue 的情況
ooo_okay 標志是否非零:如果不為 0,則表示現在允許無序(out of order)數據包。協議層必須正確地設置此標志。當 flow 的所有 outstanding(需要確認的)數據包都已確認時,TCP 協議層將設置此標志。當發生這種情況時,內核可以為此數據包選擇不同的 TX 隊列。UDP 協議層不設置此標志 ,因此 UDP 數據包永遠不會將 ooo_okay 設置為非零值。
TX queue index 大于 TX queue 數量:如果用戶最近通過 ethtool 更改了設備上的隊列數, 則會發生這種情況。
以上任何一種情況,都表示沒有找到合適的 TX queue,因此接下來代碼會進入慢路徑以繼續尋找合適的發送隊列。首先調用 get_xps_queue,它會使用一個由用戶配置的 TX queue 到 CPU 的映射,這稱為 XPS(Transmit Packet Steering ,發送數據包控制)。
如果內核不支持 XPS,或者系統管理員未配置 XPS,或者配置的映射引用了無效隊列, get_xps_queue 返回-1,則代碼將繼續調用 skb_tx_hash。
一旦 XPS 或內核使用 skb_tx_hash 自動選擇了發送隊列,sk_tx_queue_set 會將隊列緩存 在 socket 對象上,然后返回。讓我們看看 XPS,以及 skb_tx_hash 在繼續調用 dev_queue_xmit 之前是如何工作的。
2.2.1 Transmit Packet Steering (XPS)
發送數據包控制(XPS)是一項功能,允許系統管理員配置哪些 CPU 可以處理網卡的哪些發送 隊列。XPS 的主要目的是避免處理發送請求時的鎖競爭。使用 XPS 還可以減少緩存驅逐, 避免NUMA機器上的遠程內存訪問等。
上面代碼中,get_xps_queue 將查詢這個用戶指定的映射,以確定應使用哪個發送 隊列。如果 get_xps_queue 返回-1,則將改為使用 skb_tx_hash。
2.2.2 skb_tx_hash
如果 XPS 未包含在內核中,或 XPS 未配置,或配置的隊列不可用(可能因為用戶調整了隊列數 ),skb_tx_hash 將接管以確定應在哪個隊列上發送數據。準確理解 skb_tx_hash 的工作原理非常重要,具體取決于你的發送負載。include/linux/netdevice.h:
/*
* Returns a Tx hash for the given packet when dev-》real_num_tx_queues is used
* as a distribution range limit for the returned value.
*/
static inline u16 skb_tx_hash(const struct net_device *dev,
const struct sk_buff *skb)
{
return __skb_tx_hash(dev, skb, dev-》real_num_tx_queues);
}
直接調用了__skb_tx_hash, net/core/flow_dissector.c:
/*
* Returns a Tx hash based on the given packet descriptor a Tx queues‘ number
* to be used as a distribution range.
*/
u16 __skb_tx_hash(const struct net_device *dev, const struct sk_buff *skb,
unsigned int num_tx_queues)
{
u32 hash;
u16 qoffset = 0;
u16 qcount = num_tx_queues;
if (skb_rx_queue_recorded(skb)) {
hash = skb_get_rx_queue(skb);
while (unlikely(hash 》= num_tx_queues))
hash -= num_tx_queues;
return hash;
}
這個函數中的第一個 if 是一個有趣的短路,函數名 skb_rx_queue_recorded 有點誤導。skb 有一個 queue_mapping 字段,rx 和 tx 都會用到這個字段。無論如何,如果系統正在接收數據包并將其轉發到其他地方,則此 if 語句都為 true。否則,代碼將繼續向下:
if (dev-》num_tc) {
u8 tc = netdev_get_prio_tc_map(dev, skb-》priority);
qoffset = dev-》tc_to_txq[tc].offset;
qcount = dev-》tc_to_txq[tc].count;
}
要理解這段代碼,首先要知道,程序可以設置 socket 上發送的數據的優先級。這可以通過 setsockopt 帶 SOL_SOCKET 和 SO_PRIORITY 選項來完成。
如果使用 setsockopt 帶 IP_TOS 選項來設置在 socket 上發送的 IP 包的 TOS 標志( 或者作為輔助消息傳遞給 sendmsg,在數據包級別設置),內核會將其轉換為 skb-》priority。
如前所述,一些網絡設備支持基于硬件的流量控制系統。如果 num_tc 不為零,則表示此設 備支持基于硬件的流量控制。這種情況下,將查詢一個packet priority 到該硬件支持 的流量控制的映射,根據此映射選擇適當的流量類型(traffic class)。
接下來,將計算出該 traffic class 的 TX queue 的范圍,它將用于確定發送隊列。如果 num_tc 為零(網絡設備不支持硬件流量控制),則 qcount 和 qoffset 變量分 別設置為發送隊列數和 0。
使用 qcount 和 qoffset,將計算發送隊列的 index:
if (skb-》sk && skb-》sk-》sk_hash)
hash = skb-》sk-》sk_hash;
else
hash = (__force u16) skb-》protocol;
hash = __flow_hash_1word(hash);
return (u16) (((u64) hash * qcount) 》》 32) + qoffset;
}
EXPORT_SYMBOL(__skb_tx_hash);
最后,通過__netdev_pick_tx 返回選出的 TX queue index。
3. 繼續__dev_queue_xmit
至此已經選到了合適的發送隊列,繼續__dev_queue_xmit:
q = rcu_dereference_bh(txq-》qdisc);
#ifdef CONFIG_NET_CLS_ACT
skb-》tc_verd = SET_TC_AT(skb-》tc_verd, AT_EGRESS);
#endif
trace_net_dev_queue(skb);
if (q-》enqueue) {
rc = __dev_xmit_skb(skb, q, dev, txq);
goto out;
}
首先獲取與此隊列關聯的 qdisc。之前我們看到單發送隊列設備的默認類型是 pfifo_fast qdisc,而對于多隊列設備,默認類型是 mq qdisc。
接下來,如果內核中已啟用數據包分類 API,則代碼會為 packet 分配 traffic class。接下來,檢查 disc 是否有合適的隊列來存放 packet。像 noqueue 這樣的 qdisc 沒有隊列。如果有隊列,則代碼調用__dev_xmit_skb 繼續處理數據,然后跳轉到此函數的末尾。我們很快 就會看到__dev_xmit_skb。現在,讓我們看看如果沒有隊列會發生什么,從一個非常有用的注釋開始:
/* The device has no queue. Common case for software devices:
loopback, all the sorts of tunnels.。。
Really, it is unlikely that netif_tx_lock protection is necessary
here. (f.e. loopback and IP tunnels are clean ignoring statistics
However, it is possible, that they rely on protection
made by us here.
Check this and shot the lock. It is not prone from deadlocks.
Either shot noqueue qdisc, it is even simpler 8)
*/
if (dev-》flags & IFF_UP) {
int cpu = smp_processor_id(); /* ok because BHs are off */
正如注釋所示,唯一可以擁有”沒有隊列的 qdisc”的設備是環回設備和隧道設備。如果設備當前處于運行狀態,則獲取當前 CPU,然后判斷此設備隊列上的發送鎖是否由此 CPU 擁有 :
if (txq-》xmit_lock_owner != cpu) {
if (__this_cpu_read(xmit_recursion) 》 RECURSION_LIMIT)
goto recursion_alert;
如果發送鎖不由此 CPU 擁有,則在此處檢查 per-CPU 計數器變量 xmit_recursion,判斷其是 否超過 RECURSION_LIMIT。一個程序可能會在這段代碼這里持續發送數據,然后被搶占, 調度程序選擇另一個程序來運行。第二個程序也可能駐留在此持續發送數據。因此, xmit_recursion 計數器用于確保在此處競爭發送數據的程序不超過 RECURSION_LIMIT 個 。
我們繼續:
HARD_TX_LOCK(dev, txq, cpu);
if (!netif_xmit_stopped(txq)) {
__this_cpu_inc(xmit_recursion);
rc = dev_hard_start_xmit(skb, dev, txq);
__this_cpu_dec(xmit_recursion);
if (dev_xmit_complete(rc)) {
HARD_TX_UNLOCK(dev, txq);
goto out;
}
}
HARD_TX_UNLOCK(dev, txq);
net_crit_ratelimited(“Virtual device %s asks to queue packet!
”,
dev-》name);
} else {
/* Recursion is detected! It is possible,
* unfortunately
*/
recursion_alert:
net_crit_ratelimited(“Dead loop on virtual device %s, fix it urgently!
”,
dev-》name);
}
}
接下來的代碼首先嘗試獲取發送鎖,然后檢查要使用的設備的發送隊列是否被停用。如果沒有停用,則更新 xmit_recursion 計數,然后將數據向下傳遞到更靠近發送的設備。或者,如果當前 CPU 是發送鎖定的擁有者,或者如果 RECURSION_LIMIT 被命中,則不進行發送,而會打印告警日志。函數剩余部分的代碼設置錯誤碼并返回。
由于我們對真正的以太網設備感興趣,讓我們來看一下之前就需要跟進去的 __dev_xmit_skb 函數,這是發送主線上的函數。
4. __dev_xmit_skb
現在我們帶著排隊規則 qdisc、網絡設備 dev 和發送隊列 txq 三個變量來到 __dev_xmit_skb,net/core/dev.c:
static inline int __dev_xmit_skb(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev,
struct netdev_queue *txq)
{
spinlock_t *root_lock = qdisc_lock(q);
bool contended;
int rc;
qdisc_pkt_len_init(skb);
qdisc_calculate_pkt_len(skb, q);
/*
* Heuristic to force contended enqueues to serialize on a
* separate lock before trying to get qdisc main lock.
* This permits __QDISC_STATE_RUNNING owner to get the lock more often
* and dequeue packets faster.
*/
contended = qdisc_is_running(q);
if (unlikely(contended))
spin_lock(&q-》busylock);
代碼首先使用 qdisc_pkt_len_init 和 qdisc_calculate_pkt_len 來計算數據的準確長度 ,稍后 qdisc 會用到該值。對于硬件 offload(例如 UFO)這是必需的,因為添加的額外的頭 信息,硬件 offload 的時候回用到。
接下來,使用另一個鎖來幫助減少 qdisc 主鎖上的競爭(我們稍后會看到這第二個鎖)。如 果 qdisc 當前正在運行,那么試圖發送的其他程序將在 qdisc 的 busylock 上競爭。這允許 運行 qdisc 的程序在處理數據包的同時,與較少量的程序競爭第二個主鎖。隨著競爭者數量 的減少,這種技巧增加了吞吐量。接下來是主鎖:
spin_lock(root_lock);
接下來處理 3 種可能情況:
如果 qdisc 已停用
如果 qdisc 允許數據包 bypass 排隊系統,并且沒有其他包要發送,并且 qdisc 當前沒有運 行。允許包 bypass 所謂的 work-conserving qdisc 那些用于流量整形(traffic reshaping)目的并且不會引起發送延遲的 qdisc
所有其他情況
讓我們來看看每種情況下發生什么,從 qdisc 停用開始:
if (unlikely(test_bit(__QDISC_STATE_DEACTIVATED, &q-》state))) {
kfree_skb(skb);
rc = NET_XMIT_DROP;
如果 qdisc 停用,則釋放數據并將返回代碼設置為 NET_XMIT_DROP。接下來,如果 qdisc 允許數據包 bypass,并且沒有其他包要發送,并且 qdisc 當前沒有運行:
} else if ((q-》flags & TCQ_F_CAN_BYPASS) && !qdisc_qlen(q) &&
qdisc_run_begin(q)) {
/*
* This is a work-conserving queue; there are no old skbs
* waiting to be sent out; and the qdisc is not running -
* xmit the skb directly.
*/
if (!(dev-》priv_flags & IFF_XMIT_DST_RELEASE))
skb_dst_force(skb);
qdisc_bstats_update(q, skb);
if (sch_direct_xmit(skb, q, dev, txq, root_lock)) {
if (unlikely(contended)) {
spin_unlock(&q-》busylock);
contended = false;
}
__qdisc_run(q);
} else
qdisc_run_end(q);
rc = NET_XMIT_SUCCESS;
這個 if 語句有點復雜,如果滿足以下所有條件,則整個語句的計算結果為 true:
q-》 flags&TCQ_F_CAN_BYPASS:qdisc 允許數據包繞過排隊系統。對于所謂的“ work-conserving” qdiscs 這會是 true;即,允許 packet bypass 流量整形 qdisc。 pfifo_fast qdisc 允許數據包 bypass
!qdisc_qlen(q):qdisc 的隊列中沒有待發送的數據
qdisc_run_begin(p):如果 qdisc 未運行,此函數將設置 qdisc 的狀態為“running”并返 回 true,如果 qdisc 已在運行,則返回 false
如果以上三個條件都為 true,那么:
檢查 IFF_XMIT_DST_RELEASE 標志,此標志允許內核釋放 skb 的目標緩存。如果標志已禁用,將強制對 skb 進行引用計數
調用 qdisc_bstats_update 更新 qdisc 發送的字節數和包數統計
調用 sch_direct_xmit 用于發送數據包。我們將很快深入研究 sch_direct_xmit,因為慢路徑也會調用到它
sch_direct_xmit 的返回值有兩種情況:
隊列不為空(返回》 0)。在這種情況下,busylock 將被釋放,然后調用__qdisc_run 重新啟動 qdisc 處理
隊列為空(返回 0)。在這種情況下,qdisc_run_end 用于關閉 qdisc 處理
在任何一種情況下,都會返回 NET_XMIT_SUCCESS。
檢查最后一種情況:
} else {
skb_dst_force(skb);
rc = q-》enqueue(skb, q) & NET_XMIT_MASK;
if (qdisc_run_begin(q)) {
if (unlikely(contended)) {
spin_unlock(&q-》busylock);
contended = false;
}
__qdisc_run(q);
}
}
在所有其他情況下:
調用 skb_dst_force 強制對 skb 的目標緩存進行引用計數
調用 qdisc 的 enqueue 方法將數據入隊,保存函數返回值
調用 qdisc_run_begin(p)將 qdisc 標記為正在運行。如果它尚未運行(contended == false),則釋放 busylock,然后調用__qdisc_run(p)啟動 qdisc 處理
函數最后釋放相應的鎖,并返回狀態碼:
spin_unlock(root_lock);
if (unlikely(contended))
spin_unlock(&q-》busylock);
return rc;
5. 調優: Transmit Packet Steering (XPS)
使用 XPS 需要在內核配置中啟用它,并提供一個位掩碼,用于描述CPU 和 TX queue 的對應關系,這些位掩碼類似于 RPS位掩碼,簡而言之,要修改的位掩碼位于以下位置:
/sys/class/net/DEVICE_NAME/queues/QUEUE/xps_cpus
因此,對于 eth0 和 TX queue 0,需要使用十六進制數修改文件: /sys/class/net/eth0/queues/tx-0/xps_cpus,制定哪些 CPU 應處理來自 eth0 的發送隊列 0 的發送過程。另外,內核文檔Documentation/networking/scaling.txt#L412-L422 指出,在某些配置中可能不需要 XPS。
Reference:
https://blog.packagecloud.io/eng/2017/02/06/monitoring-tuning-linux-networking-stack-sending-data
編輯:jq
-
LINUX內核
+關注
關注
1文章
316瀏覽量
21651
原文標題:Linux內核網絡UDP數據包發送(四)——Linux netdevice 子系統
文章出處:【微信號:gh_6fde77c41971,微信公眾號:FPGA干貨】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Linux下輸入子系統上報觸摸屏坐標
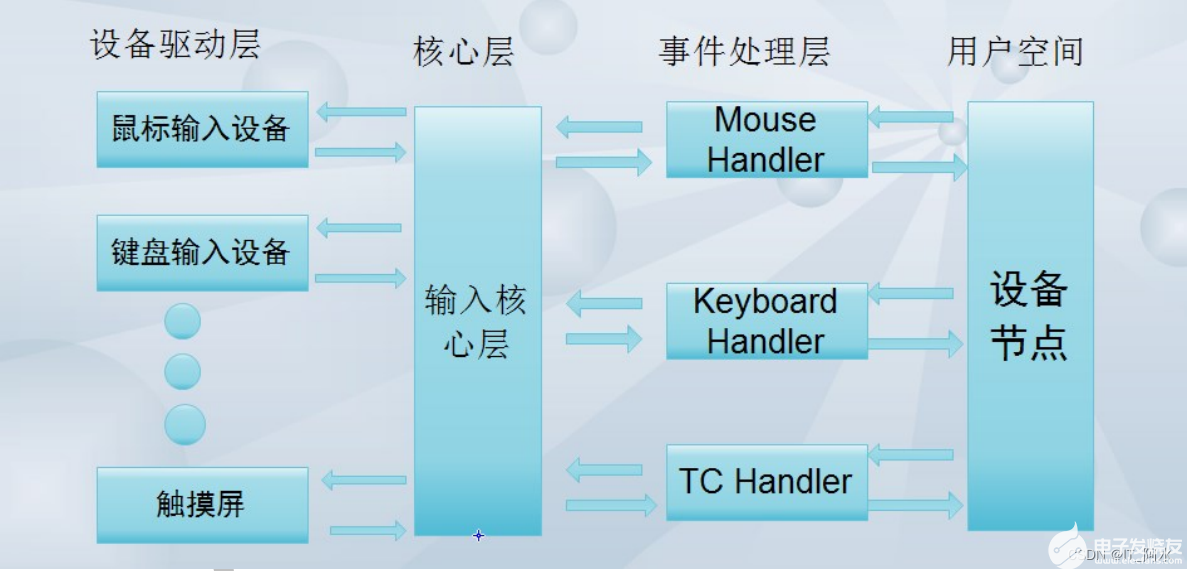
如何使用Linux內核中的input子系統
淺析Linux netdevice子系統
淺析input輸入子系統框架嵌入式Linux驅動
基于Linux內核輸入子系統的驅動研究
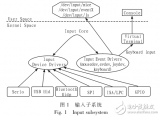
詳細了解Linux設備模型中的input子系統
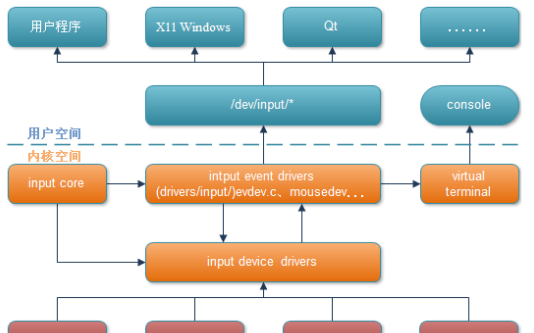
Linux系統中NFC子系統架構分析
Linux內核之LED子系統(一)
Linux reset子系統有什么功能
Linux clock子系統是什么





 工商網監
工商網監
評論