") 如何使用TensorFlow進(jìn)行大規(guī)模和分布式的QML模擬
如何使用TensorFlow進(jìn)行大規(guī)模和分布式的QML模擬
發(fā)布人:Google 團(tuán)隊 Cheng Xing 和 Michael Broughton
訓(xùn)練大型機(jī)器學(xué)習(xí)模型是 TensorFlow 的核心能力。多年來,訓(xùn)練規(guī)模已成為 NLP、圖像識別和藥物研發(fā)等眾多現(xiàn)代機(jī)器學(xué)習(xí)系統(tǒng)的重要特征。利用多臺機(jī)器來提高計算能力和吞吐量為機(jī)器學(xué)習(xí)領(lǐng)域帶來巨大進(jìn)步。同樣,在量子計算和量子機(jī)器學(xué)習(xí)領(lǐng)域,更多可用的機(jī)器資源可以加速對更大的量子態(tài)和更加復(fù)雜系統(tǒng)的模擬。在本文中,我們將逐步帶您了解如何使用 TensorFlow 和 TensorFlow Quantum 進(jìn)行大規(guī)模和分布式的 QML 模擬。以更大的 FLOP/s 計數(shù)運(yùn)行規(guī)模更大的模擬,可以為研究工作帶來小規(guī)模模擬無法實(shí)現(xiàn)的全新可能性。在下方的圖表中,我們大致描繪了量子模擬中幾種不同硬件設(shè)置的近似擴(kuò)縮能力。
運(yùn)行分布式工作負(fù)載時基礎(chǔ)架構(gòu)往往都很復(fù)雜,不過我們可以用 Kubernetes 來簡化這一過程。Kubernetes 是一個開源的容器編排系統(tǒng),同樣也是能夠有效管理大規(guī)模工作負(fù)載的可靠平臺。盡管我們可以用物理集群或虛擬機(jī)集群來設(shè)置多個 worker ,但 Kubernetes 能夠提供出諸多優(yōu)勢,其中包括:
服務(wù)發(fā)現(xiàn) - Worker 可以通過熟知的 DNS 名稱輕松識別其他 worker,無需手動配置 IP 目的地。
自動裝箱 - Kubernetes 會根據(jù)資源需求和當(dāng)前的消耗量,將工作負(fù)載自動調(diào)度到不同的機(jī)器上。
自動發(fā)布和回滾 - Kubernetes 會通過更改配置來改變 worker 副本的數(shù)量,同時還會在響應(yīng)和調(diào)度可用的機(jī)器時自動添加/刪除 worker 資源。
本教程將指導(dǎo)您使用 Google Cloud 產(chǎn)品(包括 Kubernetes 托管平臺 Google Kubernetes Engine)來完成 TensorFlow Quantum 多個 worker 設(shè)置。您將有機(jī)會學(xué)習(xí) TensorFlow Quantum 中的單 worker 量子卷積神經(jīng)網(wǎng)絡(luò) (QCNN) 教程,并將其拓展到多 worker 的訓(xùn)練中。
從我們對多 worker 設(shè)置的實(shí)驗來看,如果我們用 1000 個訓(xùn)練示例訓(xùn)練 23 量子位的 QCNN(相當(dāng)于使用全狀態(tài)向量模擬大約 3000 個電路),在 32 個節(jié)點(diǎn) (512 vCPU) 的集群上平均每個周期會花費(fèi) 5 分鐘,這一過程需要花費(fèi)數(shù)美元。相比之下,如果我們在單 worker 上完成同樣的訓(xùn)練作業(yè),平均每個周期會花費(fèi)約 4 小時。將規(guī)模進(jìn)一步擴(kuò)大來看,數(shù)十萬個 30 量子位的電路可以使用超過 10000 個虛擬 CPU 在數(shù)小時內(nèi)完成運(yùn)行,而在單 worker 設(shè)置下運(yùn)行則可能需要花費(fèi)數(shù)周時間。實(shí)際性能和成本可能會因虛擬機(jī)機(jī)器類型和集群總運(yùn)行時等 Cloud 設(shè)置而異。在進(jìn)行大規(guī)模實(shí)驗之前,我們建議您先通過類似本教程中用到的小集群進(jìn)行實(shí)驗。
本教程的所有源代碼均可在 TensorFlow Quantum GitHub 代碼庫中找到。README.md 中包含能夠讓您快速上手并運(yùn)行本教程的便捷方法。本教程將側(cè)重于詳細(xì)介紹每個操作步驟,從而幫助您理解基本概念,并將這些概念集成到您的項目中。現(xiàn)在就開始吧!
在 Google Cloud 中
設(shè)置基礎(chǔ)架構(gòu)
首先我們需要在 Google Cloud 中創(chuàng)建基礎(chǔ)架構(gòu)資源。如果您有現(xiàn)有的 Google Cloud 環(huán)境,則具體操作步驟可能會有所不同,例如組織政策限制條件導(dǎo)致的不同。本文包括一些最常見的必要步驟。值得注意的是,您需要為創(chuàng)建的 Google Cloud 資源付費(fèi),點(diǎn)擊此處了解本教程中使用的計費(fèi)資源摘要。如果您是 Google Cloud 新用戶,那么您可以獲得 300 美元贈金。如果您是學(xué)術(shù)機(jī)構(gòu)成員,那么您可以獲得 Google Cloud 研究贈金。
此處
https://github.com/tensorflow/quantum/blob/2a24b979467445f6d8e7156796f34ce81af147fa/qcnn_multiworker/README.md#billable-resources
在本教程中,您將會運(yùn)行數(shù)個 shell 命令。為此,您可以使用計算機(jī)上的本地 Unix shell,也可以使用 Cloud Shell,后者包含我們會在后面提到的許多工具。
Cloud Shell
https://cloud.google.com/shell/docs/using-cloud-shell
您可以利用 setup.sh 中的腳本自動實(shí)現(xiàn)以下步驟。在本節(jié)中,我們將為大家詳細(xì)介紹每個步驟,如果這是您第一次使用 Google Cloud,我們建議您仔細(xì)閱讀整個章節(jié)。如果您希望自動化 Google Cloud 設(shè)置過程,請?zhí)^本章節(jié):
打開 setup.sh 并配置其中的參數(shù)值。
運(yùn)行 。/setup.sh infra 。
setup.sh
https://github.com/tensorflow/quantum/blob/2a24b979467445f6d8e7156796f34ce81af147fa/qcnn_multiworker/setup.sh
在本教程中,您將會用到以下幾個 Google Cloud 產(chǎn)品:
Kubernetes Engine (GKE)。這是本教程中主要負(fù)責(zé)執(zhí)行 QCNN 作業(yè)的基礎(chǔ)架構(gòu)平臺。
Cloud Storage,用于存儲來自 QCNN 作業(yè)的數(shù)據(jù)。
Container Registry,用于存儲容器鏡像。
為準(zhǔn)備好 Cloud 環(huán)境,請首先遵循以下快速入門指南:
Container Registry 快速入門
https://cloud.google.com/container-registry/docs/quickstart
Kubernetes Engine 快速入門
https://cloud.google.com/kubernetes-engine/docs/quickstart
在本教程中,您可以在瀏覽到創(chuàng)建集群的說明時停止閱讀 Kubernetes Engine 快速入門。此外,請安裝 Cloud Storage 命令行工具 gsutil(如果您使用的是 Cloud Shell,則系統(tǒng)已安裝好 gsutil):
gcloud components install gsutil
作為參考信息,本教程中的 shell 命令將會引用以下這些變量。部分變量在結(jié)合本教程之后會提到的每個命令的上下文后,會更容易理解。
${CLUSTER_NAME:您在 Google Kubernetes Engine 上的首選 Kubernetes 集群名稱。
${PROJECT}:您的 Google Cloud 項目 ID。
${NUM_NODES}:集群中虛擬機(jī)的數(shù)量。
${MACHINE_TYPE}:虛擬機(jī)的機(jī)器類型。該變量可控制每個虛擬機(jī)中 CPU 和內(nèi)存資源的數(shù)量。
${SERVICE_ACCOUNT_NAME}:Google Cloud IAM 服務(wù)帳號和關(guān)聯(lián)的 Kubernetes 服務(wù)帳號的名稱。
${ZONE}:Kubernetes 集群的 Google Cloud 區(qū)域
${BUCKET_REGION}:Google Cloud Storage 存儲分區(qū)的 Google Cloud 地區(qū)。
${BUCKET_NAME}:用于存儲訓(xùn)練輸出的 Google Cloud Storage 存儲分區(qū)的名稱。
為確保您擁有運(yùn)行本教程其余章節(jié)的 Cloud 操作的權(quán)限,請確保您擁有 owner 的 IAM 角色或以下所有角色:
container.admin
iam.serviceAccountAdmin
Storage.adminIAM 角色
https://cloud.google.com/iam/docs/understanding-roles
如要查看您的角色,請運(yùn)行以下命令:
gcloud projects get-iam-policy ${PROJECT}
并加上您的 Google Cloud 項目 ID,然后搜索您的用戶帳號。
在您完成快速入門指南后,請運(yùn)行以下命令創(chuàng)建 Kubernetes 集群:
gcloud container clusters create ${CLUSTER_NAME} --workload-pool=${PROJECT}.svc.id.goog --num-nodes=${NUM_NODES} --machine-type=${MACHINE_TYPE} --zone=${ZONE} --preemptible
并加上您的 Google Cloud 項目 ID 和首選的集群名稱。
--num-nodes 為支持 Kubernetes 集群的 Compute Engine 虛擬機(jī)的數(shù)量。這不必與您希望 QCNN 作業(yè)擁有的 worker 副本數(shù)量相同,因為 Kubernetes 能夠在同一節(jié)點(diǎn)上調(diào)度多個副本,不過前提是該節(jié)點(diǎn)有足夠的 CPU 和內(nèi)存資源。如果您是首次嘗試本教程,我們建議您使用 2 個節(jié)點(diǎn)。
--machine-type 可指定虛擬機(jī)的機(jī)器類型。如果您是首次嘗試本教程,我們建議您使用具備 2 個 vCPU 和 7.5GB 內(nèi)存的“n1-standard-2”。
機(jī)器類型
https://cloud.google.com/compute/docs/machine-types
--zone 是您希望集群運(yùn)行所處的 Google Cloud 區(qū)域(例如“us-west1-a”)。
--workload-pool 可以啟用 GKE Workload Identity 功能,從而將 Kubernetes 服務(wù)帳號和 Google Cloud IAM 服務(wù)帳號關(guān)聯(lián)在一起。為實(shí)現(xiàn)精細(xì)訪問權(quán)限控制,建議您使用 IAM 服務(wù)帳號來訪問各種 Google Cloud 產(chǎn)品。在此您將可以創(chuàng)建一個用于 QCNN 作業(yè)的服務(wù)帳號。Kubernetes 服務(wù)帳號是一種機(jī)制,可以將 IAM 服務(wù)帳號的憑據(jù)注入 worker 容器中。
Workload Identity
https://cloud.google.com/kubernetes-engine/docs/how-to/workload-identity
Google Cloud IAM 服務(wù)帳號
https://cloud.google.com/iam/docs/service-accounts
--preemptible 使用 Compute Engine 搶占式虛擬機(jī)來支持 Kubernetes 集群。與普通的虛擬機(jī)相比,搶占式虛擬機(jī)在成本上降低了 80%,不過其代價是虛擬機(jī)隨時都可能會被搶占,進(jìn)而導(dǎo)致訓(xùn)練過程終止。這種虛擬機(jī)非常適合在短時間內(nèi)訓(xùn)練大量集群。
然后您可以創(chuàng)建一個 IAM 服務(wù)帳號:
gcloud iam service-accounts create ${SERVICE_ACCOUNT_NAME}
并將其與 Workload Identity 集成:
gcloud iam service-accounts add-iam-policy-binding --role roles/iam.workloadIdentityUser --member “serviceAccount:${PROJECT}.svc.id.goog[default/${SERVICE_ACCOUNT_NAME}]” ${SERVICE_ACCOUNT_NAME}@${PROJECT}.iam.gserviceaccount.com
現(xiàn)在創(chuàng)建一個存儲分區(qū),這是存儲數(shù)據(jù)的基本容器:
gsutil mb -p ${PROJECT} -l ${BUCKET_REGION} -b on gs://${BUCKET_NAME}
并使用您首選的存儲分區(qū)名稱。存儲分區(qū)名稱為全局唯一,因此我們建議您在存儲分區(qū)名稱中加入項目名稱。我們建議您將存儲分區(qū)地區(qū)設(shè)為包含您集群區(qū)域的地區(qū)。區(qū)域的地區(qū),即區(qū)域名稱去掉最后一個連字符之后的部分。例如,區(qū)域“us-west1-a”的地區(qū)為“us-west1”。
要讓 QCNN 作業(yè)能夠訪問 Cloud Storage 數(shù)據(jù),請為您的 IAM 服務(wù)帳號授予相應(yīng)權(quán)限:
gsutil iam ch serviceAccount:${SERVICE_ACCOUNT_NAME}@${PROJECT}.iam.gserviceaccount.com:roles/storage.admin gs://${BUCKET_NAME}
準(zhǔn)備 Kubernetes 集群
設(shè)置好 Cloud 環(huán)境后,現(xiàn)在您可以將必要的 Kubernetes 工具安裝到集群中。您需要 KubeFlow 中的 tf-operator 組件。KubeFlow 是用于在 Kubernetes 上運(yùn)行機(jī)器學(xué)習(xí)工作負(fù)載的工具包,子組件 tf-operator 可簡化 TensorFlow 作業(yè)的管理。tf-operator 可以單獨(dú)進(jìn)行安裝,無需安裝規(guī)模更大的 KubeFlow。
tf-operator
https://github.com/kubeflow/tf-operator
如要安裝 tf-operator ,請運(yùn)行以下命令:
docker pull k8s.gcr.io/kustomize/kustomize:v3.10.0
docker run k8s.gcr.io/kustomize/kustomize:v3.10.0 build “github.com/kubeflow/tf-operator.git/manifests/overlays/standalone?ref=v1.1.0” | kubectl apply -f -
(注意 tf-operator 會使用 Kustomize 來管理其部署文件,所以在此我們也需要安裝 Kustomize)
使用 MultiWorkerMirroredStrategy
進(jìn)行訓(xùn)練
現(xiàn)在您可以使用 TensorFlow Quantum 研究分支中的 QCNN 代碼,并將其準(zhǔn)備好,以便以分布式方式運(yùn)行這些代碼。首先復(fù)制源代碼:
git clone https://github.com/tensorflow/quantum.git && cd quantum && git checkout origin/research && cd qcnn_multiworker
或者,如果您使用的是向 GitHub 進(jìn)行身份驗證的 SSH 密鑰:
git clone git@github.com:tensorflow/quantum.git && cd quantum && git checkout origin/research && cd qcnn_multiworker
向 GitHub 進(jìn)行身份驗證的 SSH 密鑰
https://docs.github.com/en/github/getting-started-with-github/quickstart/set-up-git#next-steps-authenticating-with-github-from-git
代碼設(shè)置
training 目錄中包含執(zhí)行 QCNN 分布式訓(xùn)練的必備組件。training/qcnn.py 和 common/qcnn_common.py 的組合與 TensorFlow Quantum 中的混合 QCNN 示例相同,但在功能上有所增加:
借助 tf.distribute.MultiWorkerMirroredStrategy ,您現(xiàn)在可以選擇利用多臺機(jī)器進(jìn)行訓(xùn)練。
TensorBoard 集成,我們將在下一節(jié)中詳細(xì)為您講解。
TensorBoard
https://tensorflow.google.cn/tensorboard
MultiWorkerMirroredStrategy 是一種可執(zhí)行同步分布式訓(xùn)練的 TensorFlow 機(jī)制。我們在您的現(xiàn)有模型中增加了幾行代碼,以便針對分布式訓(xùn)練進(jìn)行增強(qiáng)。
MultiWorkerMirroredStrategy
https://tensorflow.google.cn/guide/distributed_training#multiworkermirroredstrategy
在 training/qcnn.py 文件的開頭,我們對 MultiWorkerMirroredStrategy 進(jìn)行設(shè)置:
strategy = tf.distribute.MultiWorkerMirroredStrategy()
training/qcnn.py
https://github.com/tensorflow/quantum/blob/2a24b979467445f6d8e7156796f34ce81af147fa/qcnn_multiworker/training/qcnn.py
然后在模型準(zhǔn)備階段,我們將此策略以參數(shù)的形式傳入:
。.. = qcnn_common.prepare_model(strategy)
每個 QCNN 分布式訓(xùn)練作業(yè)的 worker 都會運(yùn)行以上 Python 代碼的副本。每個 worker 都需要知道其他所有 worker 的網(wǎng)絡(luò)端點(diǎn)。通常,我們會將 TF_CONFIG 環(huán)境變量用于此目的。但在本例中,tf-operator 會自動在后臺將變量注入。
模型訓(xùn)練完成后,權(quán)重會上傳至您的 Cloud Storage 存儲分區(qū),隨后推理作業(yè)會對其進(jìn)行訪問。
if task_type == ‘worker’and task_id == 0:
qcnn_weights_path=‘/tmp/qcnn_weights.h5’
qcnn_model.save_weights(qcnn_weights_path)
upload_blob(args.weights_gcs_bucket, qcnn_weights_path, f‘qcnn_weights.h5’)
Kubernetes 部署設(shè)置
在繼續(xù)完成 Kubernetes 部署設(shè)置和啟動 worker 之前,您需要針對您自己的設(shè)置在教程源代碼中配置幾個參數(shù)。此處提供的腳本 setup.sh 可以用于簡化該過程。
setup.sh
https://github.com/tensorflow/quantum/blob/2a24b979467445f6d8e7156796f34ce81af147fa/qcnn_multiworker/setup.sh
如果您在之前的步驟中尚未完成此操作,請打開 setup.sh 并配置其中的參數(shù)值。然后運(yùn)行以下命令:
。/setup.sh param
至此,本節(jié)剩余的步驟可通過以下這行命令來執(zhí)行:
make training
我們將在本節(jié)剩余部分中為您詳細(xì)講解 Kubernetes 的設(shè)置過程。
首先我們需要用 Docker 將 QCNN 作業(yè)包裝為容器映像,并將其上傳至 Container Registry,然后才能在 Kubernetes 中以容器的形式運(yùn)行作業(yè)。Dockerfile 中包含映像規(guī)范。如要構(gòu)建和上傳映像,請運(yùn)行以下命令:
docker build -t gcr.io/${PROJECT}/qcnn 。
docker push gcr.io/${PROJECT}/qcnn
接下來,您將通過 common/sa.yaml 創(chuàng)建 Kubernetes 服務(wù)帳號,從而完成 Workload Identity 設(shè)置。該服務(wù)帳號將會由 QCNN 容器使用。
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
iam.gke.io/gcp-service-account: ${SERVICE_ACCOUNT_NAME}@${PROJECT}.iam.gserviceaccount.com
name: ${SERVICE_ACCOUNT_NAME}
該注釋會向 GKE 表明,此 Kubernetes 服務(wù)帳號應(yīng)與您之前創(chuàng)建的 IAM 服務(wù)帳號綁定。我們首先創(chuàng)建服務(wù)帳號:
kubectl apply -f common/sa.yaml
最后一步便是創(chuàng)建分布式訓(xùn)練作業(yè)。 ttraining/qcnn.yaml 中包含 Kubernetes 作業(yè)規(guī)范。在 Kubernetes 中,我們會將多個具有相關(guān)函數(shù)的容器分組成名為 pod 的單一實(shí)體,這是您可以進(jìn)行調(diào)度的最基礎(chǔ)的工作單元。通常來說,用戶會利用 Deployment 和 Job 等現(xiàn)有資源類型來創(chuàng)建和管理工作負(fù)載。而您將改為使用 TFJob (該信息在“kind”字段中指定),這不是 Kubernetes 內(nèi)置的資源類型,而是由 tf-operator 提供的自定義資源,可用于輕松處理 TensorFlow 工作負(fù)載。
值得注意的是,TFJob 規(guī)范中包含 tfReplicaSpecs.Worker 字段,您可通過該字段配置 MultiWorkerMirroredStrategy worker。PS(參數(shù)服務(wù)器)、Chief 和 Evaluator 的值同樣也支持異步和其他形式的分布式訓(xùn)練。 tf-operator 會在后臺為每個 worker 副本創(chuàng)建兩個 Kubernetes 資源:
一個是使用 tfReplicaSpecs.Worker.template 中 pod 規(guī)范模板的 pod 對象。該資源可運(yùn)行您之前在 Kubernetes 上創(chuàng)建的容器。
另一個是 Service 對象,它能夠在 Kubernetes 集群中公開顯示已知的網(wǎng)絡(luò)端點(diǎn),從而授予對 worker gRPC 訓(xùn)練服務(wù)器的訪問權(quán)限。其他 worker 可以僅通過指向 《service_name》:《port》 (也是 《service_name》。《service_namespace》.svc:《port》 工作的替代形式)來與服務(wù)器通信。
TFJob 會為每個 worker 副本生成一個 Service 和一個 pod。TFJob 更新后,相應(yīng)的更改將反映在底層 Service 和 pod 中。Worker 狀態(tài)也會在 TFJob 中報告顯示
Service 會向集群的其余部分公開 worker 服務(wù)器。每個 worker 在與其他 worker 通信時都會使用目標(biāo) worker 的 Service 名稱作為 DNS 名稱
Worker 規(guī)范中有幾個重要的字段:
Replicas:worker 副本的數(shù)量。我們可以在同一節(jié)點(diǎn)上調(diào)度多個副本,因此副本的數(shù)量不會受到節(jié)點(diǎn)數(shù)量的限制。
Template:每個 worker 副本的 pod 規(guī)范模板
serviceAccountName:該字段可為 pod 提供訪問 Kubernetes 服務(wù)帳號的權(quán)限。
container:
image:指向您之前構(gòu)建的 Container Registry 映像。
command:容器的入口點(diǎn)命令。
arg:命令行參數(shù)。
Ports:開放兩個端口,其中一個用于 worker 間互相通信,另一個用于分析用途。
affinity:該字段會向 Kubernetes 表明,您希望在不同的節(jié)點(diǎn)上盡可能多地調(diào)度 worker pod,以最大限度地利用資源。
如要創(chuàng)建 TFJob,請運(yùn)行以下命令:
kubectl apply -f training/qcnn.yaml
檢查部署
恭喜!您的分布式訓(xùn)練正在進(jìn)行中。如要查看作業(yè)狀態(tài),請多次運(yùn)行 kubectl get pods (或添加 -w 以流式顯示輸出)。最終您應(yīng)該能夠看到 qcnn-worker 的數(shù)量和 replicas 參數(shù)中的數(shù)量相同,且狀態(tài)均為 Running:
NAME READY STATUS RESTARTS
qcnn-worker-01/1 Running 0
qcnn-worker-11/1 Running 0
如要訪問 worker 的日志輸出,請運(yùn)行以下命令:
kubectl logs 《worker_pod_name》
或添加 -f 以流式顯示輸出。qcnn-worker-0 的輸出結(jié)果如下所示:
…
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:411] Started server with target: grpc:/
/qcnn-worker-0.default.svc:2222
…
I tensorflow/core/profiler/rpc/profiler_server.cc:46] Profiler server listening on [::]:2223 selecte
d port:2223
…
Epoch 1/50
…
4/4 [==============================] - 7s 940ms/step - loss: 0.9387 - accuracy: 0.0000e+00 - val_loss: 0.7432 - val_accuracy: 0.0000e+00
…
I tensorflow/core/profiler/lib/profiler_session.cc:71] Profiler session collecting data.
I tensorflow/core/profiler/lib/profiler_session.cc:172] Profiler session tear down.
…
Epoch 50/504/4 [==============================] - 1s 222ms/step - loss: 0.1468 - accuracy: 0.4101 - val_loss: 0.2043 - val_accuracy: 0.4583
File /tmp/qcnn_weights.h5 uploaded to qcnn_weights.h5.
qcnn-worker-1 的輸出結(jié)果與上述結(jié)果類似,區(qū)別是沒有最后一行。主 worker (worker 0) 負(fù)責(zé)保存整個模型的權(quán)重。
您也可以訪問 Cloud Console 中的 Storage 瀏覽器,通過瀏覽之前創(chuàng)建的存儲分區(qū)來驗證模型權(quán)重。
Cloud Console 中的 Storage 瀏覽器
https://console.cloud.google.com/storage/browser
如要刪除訓(xùn)練作業(yè),請運(yùn)行以下命令:
kubectl delete -f training/qcnn.yaml
借助 TensorBoard 了解訓(xùn)練性能
TensorBoard 是 TensorFlow 的可視化工具包。通過將 TensorFlow Quantum 模型與 TensorBoard 進(jìn)行集成,您將獲得許多開箱可用的模型可視化數(shù)據(jù),例如訓(xùn)練損失和準(zhǔn)確性、可視化模型圖和程序分析。
代碼設(shè)置
如要在作業(yè)中啟用 TensorBoard,請創(chuàng)建 TensorBoard 回調(diào)并將其傳入 model.fit():
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=args.logdir,
histogram_freq=1,
update_freq=1,
profile_batch=‘10, 20’)
…
history = qcnn_model.fit(x=train_excitations,
y=train_labels,
batch_size=32,
epochs=50,
verbose=1,
validation_data=(test_excitations, test_labels),
callbacks=[tensorboard_callback])
profile_batch 參數(shù)可在程序化模式下啟用 TensorFlow 性能剖析器,從而在您于此處指定的訓(xùn)練步驟范圍內(nèi)對程序進(jìn)行采樣。您也可以啟用采樣模式。
tf.profiler.experimental.server.start(args.profiler_port)
該模式允許由不同程序或通過 TensorBoard 界面發(fā)起按需分析。
TensorBoard 功能
在這里我們將重點(diǎn)介紹本教程中使用的部分 TensorBoard 的強(qiáng)大功能。請查看 TensorBoard 指南以了解詳情。
TensorBoard 指南
https://tensorflow.google.cn/tensorboard/get_started
損失和準(zhǔn)確性
損失是模型在訓(xùn)練過程中力求最小化的數(shù)量,可通過損失函數(shù)計算得出。準(zhǔn)確性是指在訓(xùn)練過程中,預(yù)測結(jié)果與標(biāo)簽匹配的樣本的比例。默認(rèn)情況下系統(tǒng)會導(dǎo)出損失指標(biāo)。如要啟用準(zhǔn)確性指標(biāo),請將以下命令添加到model.compile() 步驟中:
qcnn_model.compile(。.., metrics=[‘a(chǎn)ccuracy’])
自定義指標(biāo)
除了損失指標(biāo)和準(zhǔn)確性指標(biāo)以外,TensorBoard 同樣還支持自定義指標(biāo)。例如,教程代碼將 QCNN 讀出張量以直方圖的形式導(dǎo)出。
自定義指標(biāo)
https://tensorflow.google.cn/tensorboard/scalars_and_keras#logging_custom_scalars
性能剖析器
TensorFlow 性能剖析器是一款十分有用的工具,該工具可助您在模型訓(xùn)練作業(yè)中調(diào)試性能瓶頸。在本教程中,我們同時采用了程序化模式(在預(yù)定義的訓(xùn)練步驟范圍內(nèi)進(jìn)行分析)和采樣模式(按需進(jìn)行分析)。如果是 MultiWorkerMirroredStrategy 的設(shè)置,則目前的程序化模式僅會輸出來自主 worker (worker 0) 的分析數(shù)據(jù),而采樣模式能夠?qū)λ?worker 進(jìn)行分析。
TensorFlow 性能剖析器
https://tensorflow.google.cn/guide/profiler
當(dāng)您第一次打開性能剖析器時,顯示的數(shù)據(jù)均來自程序化模式。您可通過概覽頁面了解到每個訓(xùn)練步驟所需時長。無論是擴(kuò)縮基礎(chǔ)架構(gòu)(向集群中添加更多的虛擬機(jī)、使用配備更多 CPU 和更大內(nèi)存的虛擬機(jī)、與硬件加速器集成)還是提高代碼效率,當(dāng)您嘗試用不同的方法來提升訓(xùn)練性能時,均可以此為參考。
Trace Viewer 會將所有后臺訓(xùn)練指令耗費(fèi)的時間在詳細(xì)視圖中分別列出,以便您確定執(zhí)行時間瓶頸。
Kubernetes 部署設(shè)置
如要查看 TensorBoard 界面,您可以在 Kubernetes 中創(chuàng)建 TensorBoard 實(shí)例。Kubernetes 設(shè)置位于 training/tensorboard.yaml。該文件包含 2 個對象:
一個是 Deployment 對象,其中包含帶有相同 worker 容器映像的 pod 副本,不同的是要用 TensorBoard 命令來運(yùn)行:tensorboard --logdir=gs://${BUCKET_NAME}/${LOGDIR_NAME} --port=5001 --bind_all
一個是可以創(chuàng)建網(wǎng)絡(luò)負(fù)載平衡器的 Service 對象,能夠?qū)崿F(xiàn)通過互聯(lián)網(wǎng)訪問 TensorBoard 界面,這樣您就可以在瀏覽器中查看該界面。
您也可以通過將 --logdir 指向相同的 Cloud Storage 存儲分區(qū),以在工作站上運(yùn)行 TensorBoard 本地實(shí)例,不過這需要額外的 IAM 權(quán)限設(shè)置。
創(chuàng)建 Kubernetes 設(shè)置:
kubectl apply -f training/tensorboard.yaml
在 kubectl get pods 的輸出結(jié)果中,您應(yīng)該可以看到一個前綴為 qcnn-tensorboard的 pod,其最終會處于運(yùn)行狀態(tài)。如要獲得 TensorBoard 實(shí)例的 IP 地址,請運(yùn)行以下命令:
kubectl get svc tensorboard-service -w
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
tensorboard-service LoadBalancer 10.123.240.9 《pending》 5001:32200/TCP
負(fù)載平衡器需要花費(fèi)一些時間來進(jìn)行預(yù)配,所以您可能不會馬上看到 IP 地址。預(yù)配完成后,請在瀏覽器中轉(zhuǎn)到 《ip》:5001 以訪問 TensorBoard 界面。
借助 TensorFlow 2.4 及更高版本,我們可以在采樣模式下分析多個 worker:在訓(xùn)練作業(yè)運(yùn)行期間,您可通過點(diǎn)擊 Tensorboard 性能剖析器中的“捕獲性能剖析文件”,并將“性能剖析文件服務(wù)網(wǎng)址”設(shè)為 qcnn-worker-《replica_id》:2223 來分析 worker 。要啟用此功能,worker 服務(wù)需要公開性能剖析器端口。教程源代碼中提供的腳本能夠修補(bǔ)所有由 TFJob 生成的 worker Service,為其設(shè)置性能剖析器端口。運(yùn)行以下命令即可:
training/apply_profiler_ports.sh
請注意,手動修補(bǔ) Service 只是臨時解決方案,目前我們正在計劃對 tf-operator 進(jìn)行修改,以支持在 TFJob 中指定其他端口。
運(yùn)行推理
在完成分布式訓(xùn)練作業(yè)后,模型權(quán)重會存儲在您的 Cloud Storage 存儲分區(qū)中。然后您可以使用這些權(quán)重來構(gòu)建推理程序,進(jìn)而在 Kubernetes 集群中創(chuàng)建推理作業(yè)。您也可以在本地工作站上運(yùn)行推理程序,不過這需要額外的 IAM 權(quán)限來向 Cloud Storage 授予訪問權(quán)限。
代碼設(shè)置
inference/ 目錄中提供了推理源代碼。主文件 qcnn_inference.py 基本上是重用 common/qcnn_common.py 中的模型構(gòu)建代碼,但是會改為從 Cloud Storage 存儲分區(qū)中加載模型權(quán)重:
qcnn_weights_path = ‘/tmp/qcnn_weights.h5’
download_blob(args.weights_gcs_bucket, args.weights_gcs_path, qcnn_weights_path)
qcnn_model.load_weights(qcnn_weights_path)
然后主文件會將模型應(yīng)用于測試集,并計算均方誤差。
results = qcnn_model(test_excitations).numpy().flatten()
loss = tf.keras.losses.mean_squared_error(test_labels, results)
Kubernetes 部署設(shè)置
本節(jié)中剩余的步驟可通過以下這行命令來執(zhí)行:
make inference
由于您已經(jīng)在訓(xùn)練步驟中將推理程序內(nèi)置到 Docker 映像中,所以在這一步中,您無需構(gòu)建新的映像。推理作業(yè)規(guī)范 inference/inference.yaml 中存在一個 Job,其 pod 規(guī)范指向映像,但會改為執(zhí)行 qcnn_inference.py。運(yùn)行 kubectl apply -f inference/inference.yaml 以創(chuàng)建作業(yè)。
前綴為 inference-qcnn的 pod 最終應(yīng)處于運(yùn)行狀態(tài) (kubectl get pods)。在推理 pod (kubectl logs 《pod_name》) 的日志輸出中,均方誤差應(yīng)接近于 TensorBoard 界面中顯示的最終損失。
…
Blob qcnn_weights.h5 downloaded to /tmp/qcnn_weights.h5.
[-0.82200970.40201923-0.828569770.46476707-1.12814780.233174860.005841821.33518550.35139582-0.099580481.2205497-1.30386961.4065738-1.1120421-0.010213521.4553616-0.70309246-0.05183951.4699622-1.3712595-0.018703521.29395891.28658020.8472030.31496051.1705848-1.00516761.2537074-0.2943283-1.3489063-1.47278831.45662761.34179120.91234220.2942805-0.7918621.2984066-1.11394041.4648925-1.6311806-0.175303760.70148027-1.00840270.098989160.41216150.62743163-1.4237025-0.6296255 ]
Test Labels
[-11-11-11111-11-11-111-1-11-1-111111-11-1-1-1111-1-11-11-1-11-1111-1-1]
Mean squared error: tf.Tensor(0.29677835, shape=(), dtype=float32)
清理
我們的分布式訓(xùn)練之旅到此圓滿結(jié)束!在您對照著本教程實(shí)驗完畢后,我們將在本節(jié)中逐步為您講解如何清理 Google Cloud 資源。
首先移除 Kubernetes 部署。運(yùn)行以下命令:
make delete-inference
kubectl delete -f training/tensorboard.yaml
如果您尚未進(jìn)行此操作,請運(yùn)行以下命令:
make delete-training
然后刪除 GKE 集群。此操作也將刪除底層虛擬機(jī)。
gcloud container clusters delete ${CLUSTER_NAME} --zone=${ZONE}
接下來,刪除 Google Cloud Storage 中的訓(xùn)練數(shù)據(jù)。
gsutil rm -r gs://${BUCKET_NAME}
最后,按照 Cloud Console 使用說明從 Container Registry 中移除 worker 容器映像。查找名為 qcnn 的映像。
Cloud Console 使用說明
https://cloud.google.com/container-registry/docs/managing#deleting_images
后續(xù)工作
現(xiàn)在,您已嘗試過多 worker 設(shè)置,那么不妨在您的項目中試著設(shè)置吧!由于本教程中提到的工具會不斷更新迭代,訓(xùn)練多 worker 的最佳做法也會隨時間發(fā)生變化。請定期查看 TensorFlow Quantum GitHub 代碼庫中的教程目錄,以獲取更新內(nèi)容!
責(zé)任編輯:haq
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8418瀏覽量
132646 -
nlp
+關(guān)注
關(guān)注
1文章
488瀏覽量
22038
原文標(biāo)題:使用 TensorFlow Quantum 訓(xùn)練多個 Worker
文章出處:【微信號:yingjiansanrenxing,微信公眾號:硬件三人行】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
HarmonyOS Next 應(yīng)用元服務(wù)開發(fā)-分布式數(shù)據(jù)對象遷移數(shù)據(jù)權(quán)限與基礎(chǔ)數(shù)據(jù)

淺談分布式電源和電動汽車的配電網(wǎng)可靠性評估

分布式IO模擬量模塊:多領(lǐng)域應(yīng)用的高效能解決方案
分布式光纖測溫是什么?應(yīng)用領(lǐng)域是?
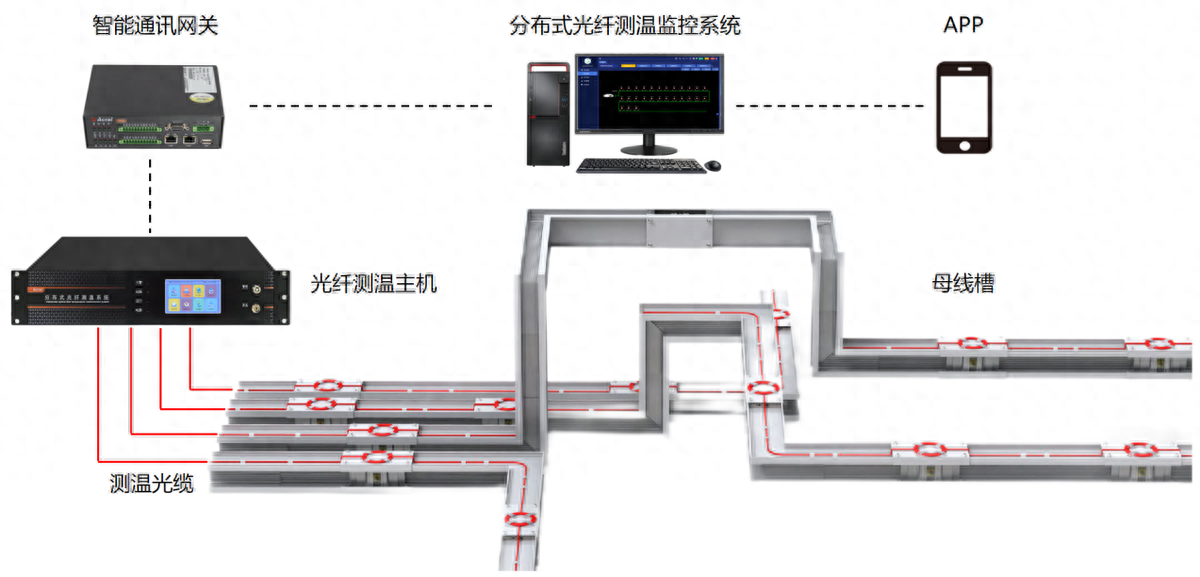
分布式光纖聲波傳感技術(shù)的工作原理
基于分布式計算的AR光波導(dǎo)中測試圖像的仿真
分布式光伏發(fā)電對低壓電網(wǎng)的影響與對策
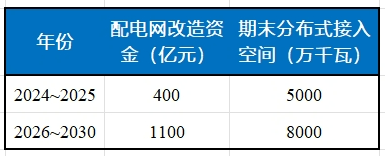
安科瑞分布式光伏系統(tǒng)在某重工企業(yè)18MW分布式光伏中應(yīng)用
TensorFlow是什么?TensorFlow怎么用?
鴻蒙開發(fā)接口數(shù)據(jù)管理:【@ohos.data.distributedData (分布式數(shù)據(jù)管理)】

HarmonyOS實(shí)戰(zhàn)案例:【分布式賬本】
鴻蒙OS 分布式任務(wù)調(diào)度
什么是分布式架構(gòu)?
分布式節(jié)點(diǎn)服務(wù)器是什么?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論