 迅速了解目標檢測的基本方法并嘗試理解每個模型的技術細節
迅速了解目標檢測的基本方法并嘗試理解每個模型的技術細節
本文將討論目標檢測的基本方法(窮盡搜索、R-CNN、Fast R-CNN和Faster R-CNN),并嘗試理解每個模型的技術細節。為了讓經驗水平各不相同的讀者都能夠理解,文章不會使用任何公式來進行講解。
開啟目標檢測的第一步
這是只鳥還是架飛機?—— 圖像分類
目標檢測(或識別)基于圖像分類。圖像分類是通過上圖所示的像素網格,將圖像分類為一個類類別。目標識別是對圖像中的對象進行識別和分類的過程。
為了使模型能夠學習圖像中對象的類別和位置,目標必須是一個五維標簽(類別,x, y,寬度,長度)。
對象檢測方法的內部工作
一種費機器(奢侈計算)的方法:窮舉搜索
最簡單的目標檢測方法是對圖像的各個子部分使用圖像分類器,讓我們來逐個考慮:
· 首先,選擇想要執行目標檢測的圖像。
· 然后將該圖像分割成不同的部分,或者說“區域”。
· 把每個區域看作一個單獨的圖像。
· 使用經典的圖像分類器對每幅圖像進行分類。
· 最后,將檢測到目標的區域的所有圖像與預測標簽結合。
這種方法存在一個問題,對象可能具有的不同縱橫比和空間位置,這可能導致對大量區域進行不必要的昂貴計算。它在計算時間方面存在太大的瓶頸,從而無法用于解決實際問題。
區域提議方法和選擇性搜索
最近有種方法是將問題分解為兩個任務:首先檢測感興趣的區域,然后進行圖像分類以確定每個對象的類別。
第一步通常是使用區域提議方法。這些方法輸出可能包含感興趣對象的邊界框。如果在一個區域提議中正確地檢測到目標對象,那么分類器也應該檢測到了它。這就是為什么對這些方法而言,快速和高回應率非常重要。重要的是這兩個方法不僅要是快速的,還要有著很高的回應率。
這兩個方法還使用了一種聰明的體系結構,其中目標檢測和分類任務的圖像預處理部分相同,從而使其比簡單地連接兩個算法更快。選擇性搜索是最常用的區域提議方法之一。
它的第一步是應用圖像分割。
從圖像分割輸出中,選擇性搜索將依次進行:
· 從分割部分創建邊界框,然后將其添加到區域建議列表中。
· 根據四種相似度:顏色,紋理,大小和形狀,將幾個相鄰的小片段合并為較大的片段。
· 返回到第一步,直到該部分覆蓋了整個圖像。
在了解了選擇性搜索的工作原理后,接著看一些使用該法最常見的目標檢測算法。
第一目標檢測算法:R-CNN
Ross Girshick等人提出了區域CNN(R-CNN),允許選擇性搜索與CNN結合使用。實際上,對于每個區域方案(如本文中的2000),一個正向傳播會通過CNN生成一個輸出向量。這個向量將被輸入到one-vs-all分類器中。每個類別一個分類器,例如一個分類器設置為如果圖像是狗,則標簽=1,否則為0,另一個分類器設置為如果圖像是貓,標簽= 1,否則為0,以此類推。R-CNN使用的分類算法是SVM。
但如何將該地區標記為提議呢?當然,如果該區域完全匹配真值,可以將其標為1,如果給定的對象根本不存在,這個對象可以被標為0。
如果圖像中存在對象的一部分怎么辦?應該把這個區域標記為0還是1?為了確保訓練分類器的區域是在預測一幅圖像時可以實際獲得的區域(不僅僅是那些完美匹配的區域),來看看選擇性搜索和真值預測的框的并集(IoU)。
IoU是一個度量,用預測的框和真值框的重疊面積除以它們的并集面積來表示。它獎勵成功的像素檢測,懲罰誤報,以防止算法選擇整個圖像。
回到R-CNN方法,如果IoU低于給定的閾值(0.3),那么相對應的標簽將是0。
在對所有區域建議運行分類器后,R-CNN提出使用一個特定類的邊界框(bbox)回歸量來優化邊界框。bbox回歸量可以微調邊界框的邊界位置。例如,如果選擇性搜索已經檢測到一只狗,但只選擇了它的一半,而意識到狗有四條腿的bbox回歸量,將確保狗的整個身體被選中。
也多虧了新的bbox回歸預測,我們可以使用非最大抑制(NMS)舍棄重疊建議。這里的想法是識別并刪除相同對象的重疊框。NMS根據分類分數對每個類的建議進行排序,并計算具有最高概率分數的預測框與所有其他預測框(于同一類)的IoU。如果IoU高于給定的閾值(例如0.5),它就會放棄這些建議。然后對下一個最佳概率重復這一步。
綜上所述,R-CNN遵循以下步驟:
· 根據選擇性搜索創建區域建議(即,對圖像中可能包含對象的部分進行預測)。
· 將這些地區帶入到pre-trained模型,然后運用支持向量機分類子圖像。通過預先訓練的模型運行這些區域,然后通過SVM(支持向量機)對子圖像進行分類。
· 通過邊界框預測來運行正向預測,從而獲得更好的邊界框精度。
· 在預測過程中使用NMS去除重疊的建議。
不過,R-CNN也有一些問題:
· 該方法仍然需要分類所有地區建議,可能導致達到計算瓶頸——不可能將其用于實時用例。
· 在選擇性搜索階段不會學習,可能導致針對某些類型的數據集會提出糟糕的區域建議。
小小的改進:Fast R-CNN(快速R-CNN)
Fast R-CNN,顧名思義,比R-CNN快。它基于R-CNN,但有兩點不同:
· 不再向CNN提供對每個地區的提議,通過對CNN提供整幅圖像來生成一個卷積特性映射(使用一個過濾器將矢量的像素轉換成另一個矢量,能得到一個卷積特性映射)。接下來,建議區域被識別與選擇性搜索,然后利用區域興趣池(RoI pooling)層將它們重塑成固定大小,從而能夠作為全連接層的輸入。
· Fast-RCNN使用更快,精度更高的softmax層而不是SVM來進行區域建議分類。
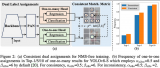
以下是該網絡的架構:
如下所示,Fast R-CNN在訓練和測試方面比R-CNN要快得多。但是,受選擇性搜索方法的影響,該方法仍然存在瓶頸。
Faster R-CNN(更快的R-CNN)
雖然Fast R-CNN比R-CNN快得多,但其瓶頸仍然是選擇性搜索,因為它非常耗時。因此,任少卿等人設計了更快R-CNN來解決這個問題,并提出用一個非常小的卷積網絡區域提議網Region Proposal network(RPN)代替選擇性搜索來尋找感興趣的區域。
簡而言之,RPN是一個直接尋找區域建議的小型網絡。一種簡單的方法是創建一個深度學習模型,輸出x_min、y_min、x_max和x_max來獲得一個區域建議的邊界框(如果我們想要2000個區域,那么就需要8000個輸出)。然而,有兩個基本問題:
· 圖像的大小和比例可能各不相同,所以很難創建一個能正確地預測原始坐標的模型。
· 在預測中有一些坐標排序約束(x_min 《 x_max, y_min 《 y_max)。
為了克服這個問題,我們將使用錨:錨是在圖像上預設好不同比例和比例的框。(錨點是預定義的框,它們具有不同的比例,并在整個圖像上縮放。)
例如,對于給定的中心點,通常從三組大小(例如,64px, 128px, 256px)和三種不同的寬高比(1/1,1/2,2/1)開始。在本例中,對于圖像的給定像素(方框的中心),最終會有9個不同的方框。
那么一張圖片總共有多少個錨點呢?
我們不打算在原始圖像上創建錨點,而是在最后一個卷積層的輸出特征圖上創建錨點,這一點非常重要。例如,對于一個1000*600的輸入圖像,由于每個像素有一個錨點,所以有1000 *600*9=5400000個錨點,這是錯誤的。確實,因為要在特征圖譜上創建它們,所以需要考慮子采樣比率,即由于卷積層的大步移動,輸入和輸出維度之間的因子減少。
在示例中,如果我們將這個比率設為16(像在VGG16中那樣),那么特征圖譜的每個空間位置將有9個錨,因此“只有”大約20000個錨(5400000/ 16^2)。這意味著輸出特征中的兩個連續像素對應于輸入圖像中相距16像素的兩個點。注意,這個下降采樣比率是Faster R-CNN的一個可調參數。
現在剩下的問題是如何從那20000個錨到2000個區域建議(與之前的區域建議數量相同),這是RPN的目標。
如何訓練區域建議網絡
要實現這一點,需要RPN告知框包含的是對象還是背景,以及對象的精確坐標。輸出預測有作為背景的概率,作為前景的概率,以及增量Dx, Dy, Dw, Dh,它們是錨點和最終建議之間的差異。
1.第一,我們將刪除跨邊界錨(即因為圖像邊界而被減去的錨點),這給我們留下了約6000張圖像。
2.如果存在以下兩個條件中的任一,我們需要標簽錨為正:
· 在所有錨中,該錨具有最高的IoU,并帶有真值框。
· 錨點至少有0.7的IoU,并帶有真值框。
3.如果錨的IoU在所有真值框中小于0.3,需要標簽其為負。
4.舍棄所有剩下的錨。
5.訓練二進制分類和邊界框回歸調整。
最后,關于實施的幾點說明:
· 希望正錨和負錨的數量在小批處理中能夠平衡。
· 因為想盡量減少損失而使用了多任務損失,這是有意義的——損失有錯誤預測前景或背景的錯誤,以及方框的準確性的錯誤。
· 使用預先訓練好的模型中的權值來初始化卷積層。
如何使用區域建議網絡
· 所有錨(20000)計入后得到新的邊界框和成為所有邊界框的前景(即成為對象)的概率。
· 使用non-maximum抑制。
· 建議選擇:最后,僅保留按分數排序的前N個建議(當N=2000,回到2000個區域建議)。
像之前的方法一樣,最終獲得了2000個方案。盡管看起來更復雜,這個預測步驟比以前的方法更快更準確。
下一步是使用RPN代替選擇性搜索,創建一個與Fast R-CNN相似的模型(即RoI pooling和一個分類器+bbox回歸器)。然而,不像之前那樣,把這2000個建議進行裁剪,然后通過一個預先訓練好的基礎網絡進行傳遞。而是重用現有的卷積特征圖。實際上,使用RPN作為提案生成器的一個好處是在RPN和主檢測器網絡之間共享權值和CNN。
· 使用預先訓練好的網絡對RPN進行訓練,然后進行微調。
· 使用預先訓練好的網絡對檢測器網絡進行訓練,然后進行微調。使用來自RPN的建議區域。
· 使用來自第二個模型的權重對RPN進行初始化,然后進行微調——這將是最終的RPN模型)。
· 最后,對檢測器網絡進行微調(RPN權值固定)。CNN的特色圖將在兩個網絡之間共享。
綜上所述,Faster R-CNN比之前的方法更準確,比Fast-R-CNN快10倍左右,這是一個很大的進步,也是實時評分的開始。
即便如此,區域建議檢測模型對于嵌入式系統來說還是不夠,因為這些模型太笨重,而且對于大多數實時評分案例來說速度也不夠快——最后一例是大約每秒檢測5張圖像。
編輯:jq
-
嵌入式系統
+關注
關注
41文章
3593瀏覽量
129476 -
分類器
+關注
關注
0文章
152瀏覽量
13183 -
cnn
+關注
關注
3文章
352瀏覽量
22215
原文標題:深入了解目標檢測深度學習算法的技術細節
文章出處:【微信號:lingzhiVision888,微信公眾號:凌智機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI模型部署邊緣設備的奇妙之旅:目標檢測模型
【書籍評測活動NO.52】基于大模型的RAG應用開發與優化
視頻目標跟蹤從0到1,概念與方法

YOLOv10自定義目標檢測之理論+實踐
深入解析Zephyr RTOS的技術細節

探究雙路或四路可選可編程晶體振蕩器SG-8503CA/SG-8504CA的技術細節及其應用
LED顯示屏的換幀頻率與刷新頻率:技術細節與市場發展

大語言模型(LLM)快速理解
無損檢測技術中工業CT檢測與X-RAY射線檢測

【大語言模型:原理與工程實踐】大語言模型的基礎技術
聊聊50G PON的技術細節






 工商網監
工商網監
評論